
If you’ve noticed your favorite illustrator suddenly vanish from Instagram, or that one parent friend quietly scrubbing every photo of their kid from Facebook, you’re not imagining it. In the last few years, people have removed content from the web over concerns about generative AI.
That can look like a lot of different things: artists pulling their portfolios offline after discovering AI models spitting out paintings in their own style, parents deleting family photos over fears their kids’ faces could end up in a deepfake, or businesses blocking AI crawlers from accessing their website entirely.
Based on an analysis of DreamHost customers, we found that approximately 5,000 total websites using our hosting services are actively blocking some or all AI web crawlers.
In other words, there’s a real and measurable concern about how AI tools access, understand, and ingest the content we all put online.
It’s not that these worries are new.
The internet has always been a messy place for consent, privacy, and ownership. What’s changed is that AI has forced everyone: creators, families, and small business owners alike, to finally confront just how little control they have over what they put online.
At DreamHost, we’ve always believed the open web thrives when creators control what they share and how it’s used. The web works best when ownership sits with the people who built it — not just the platforms that profit from it.
And that brings us to the heart of the matter. The real question isn’t what AI can do — it’s who gets to decide.
The Real AI Ethics Problem Isn’t the Tech — It’s the Loss of Choice
AI isn’t the villain here. The real threat is “platform paternalism,” or companies that make “ethical” choices on behalf of everyone else. For example, in 2024, several major content delivery networks (CDNs) and network providers began blocking AI crawlers by default, claiming their goal was to “protect creators.” The result was millions of site owners woke up to find decisions about their content already made for them.
It’s like your landlord locking your door for your safety, but without giving you the right keys. So what started as a convenience quickly turns into a loss of agency. When gatekeepers decide what “protection” looks like, individual autonomy shrinks.
The open web was built on permissionless innovation, meaning anyone could create, share, and iterate without asking for approval. Intermediaries deciding which bots or tools can access content may rewind that freedom by decades.
That’s why DreamHost advocates for infrastructure independence: when you host your own content, no one can rewrite your rules. Owning your stack means owning your policies, whether you welcome AI crawlers or shut them out entirely. The ethics don’t come from code; they come from choice.

“AI Needs Your Data” and Other Myths
So what keeps creators from reclaiming control? Oftentimes, misinformation, like these pervasive myths surrounding AI. These myths are popular because AI use has proliferated around the internet and the tools we use every day.
Myth #1: “AI Needs Your Data To Progress”
No one owes for-profit AI companies their work. Licensed and consent-based models exist; for example, Adobe Firefly trains licensed content with permission and public domain works without copyright. The future of AI doesn’t need to depend on stealing. It can depend on consent instead.
Myth #2: “If You Opt Out, You’ll Disappear”
Opting out may limit your appearance in AI-generated summaries or search snippets, but it won’t erase you from the web. Think of it like opting out of Google in 2005. You’d lose reach, not relevance, especially if your audience still seeks you directly.
While it may not be practical for anyone who depends on reach to grow their audience or customer base (though we still don’t have great data on how much organic traffic actually comes from GEO), for some creators, visibility isn’t worth involuntary use. The key is that they get to decide.
Myth #3: “AI Scraping Is Just How the Internet Works”
Indexing for discovery and appropriating for training aren’t the same thing.
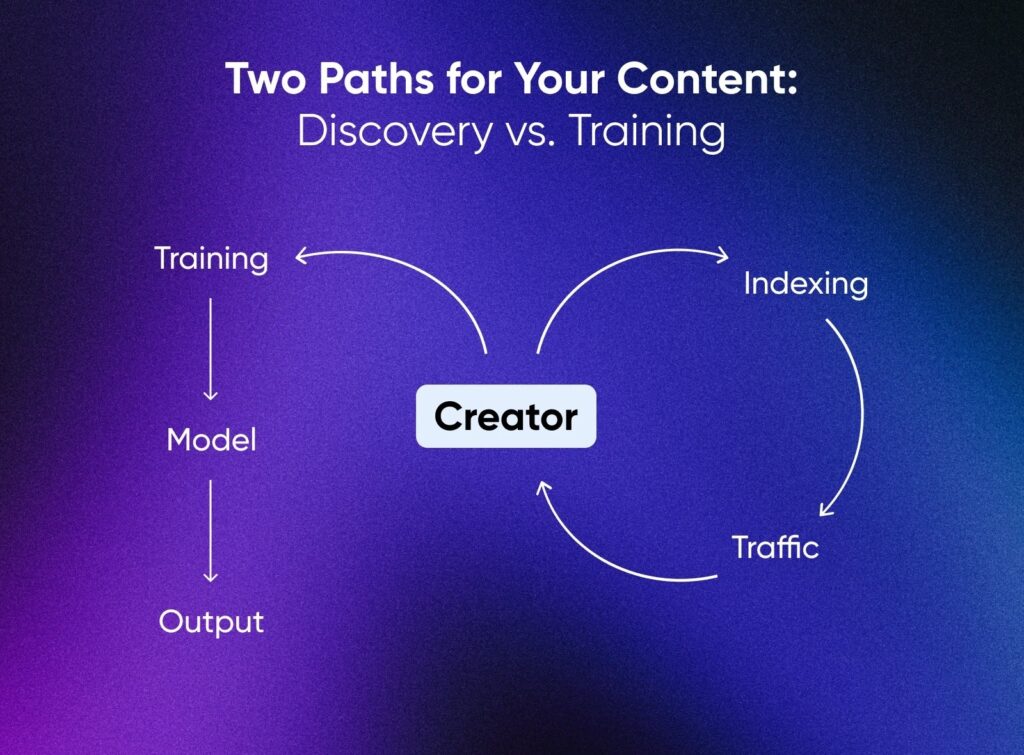
Indexing drives people to your site. Training replaces you with a statistical copy. Publishers like the Associated Press and Axel Springer are proving there’s a middle ground by licensing their content for model training with credit and compensation.
Even good intentions can backfire. The bottom line is that balanced ethics require informed consent.
Opting Out vs. Staying Open: The Real Trade-Offs
Every AI stance — from full openness to total opt-out — comes with real opportunity costs. Deciding where you stand depends on what you value most, from visibility to control to sustainability to autonomy.
DreamHost’s internal data shows that about 71.5% of all web traffic now comes from bots, not humans. That means most of the requests hitting your site are automated: some beneficial (like search indexing or uptime monitoring), others less so. Managing which crawlers you allow and which you block is ethical sustainability in action.
Below are four common approaches creators take to AI access and training and how each impacts different open web factors, so you can visualize the trade-offs before locking in your stance.
| Fully Open | Selective Licensing | Block AI Training | Fully Opted Out of AI | |
| Visibility and Reach | Highest; AI summaries and search engines can surface your work everywhere. | Moderate; exposure limited to partners who license content. | Low; excluded from AI results but still appears in traditional search. | None; blocked from both AI and many discovery crawlers. |
| Control and Consent | Minimal; platforms decide for you. | High; governed by explicit licensing terms. | Strong; you define permissions via robots.txt and HTTP headers. | Absolute; all automated access is prohibited. |
| Attribution | Low; most AI models don’t cite sources. | High; attribution and royalties built into contracts. | Medium; compliant crawlers may still credit you. | None; content is never referenced. |
| Environmental Impact | Moderate; contributes to broad model training and indexing load. | Moderate; limited, licensed use reduces duplicate training. | Moderate-low; fewer heavy crawlers, more targeted traffic. | Low; least external requests and data transfers. |
| Risk of Misuse or Copying | High; style or text may be replicated freely. | Moderate; legal recourse via license terms. | Low; compliant bots deterred, rogue bots still possible. | Very low; minimal surface area to scrape. |
Each path has merit. Marketers and small business owners often depend on visibility to grow their audiences, while illustrators, journalists, and educators may prioritize ownership and consent above all else. The web thrives on diversity, and ethical AI participation should reflect that diversity of goals.
There’s no universal right answer: only informed trade-offs that align with your principles and how you earn a living online. The right stance isn’t one-size-fits-all, but you should form your stance consciously, and back it up with action. Whatever path you choose, make it intentional.
How To Decide Your AI Stance
Ethics only matter when they’re practiced. Here’s how to turn theory into action and define how AI interacts with your work.
Step 1: Clarify Your Goals
Start by ranking what matters most to you: visibility, revenue, sustainability, control.
A small business chasing reach may tolerate broader AI use, while an illustrator guarding originality may not. Different goals = different boundaries.

Step 2: Audit Your Digital Footprint
List where your content lives: WordPress sites, GitHub repos, social media, cloud storage. Platforms apply their own AI policies, so hosting independence gives you the freedom to set rules per site instead of accepting blanket defaults set by the platforms you use (without your input).
Step 3: Apply Technical Controls
Use your robots.txt file to signal AI bots how to behave:
User-agent: GPTBot |
Add headers (like X-Robots-Tag: noai, noimageai) for extra clarity. Just remember, compliance is voluntary. These tags signal your wishes, but they don’t enforce them.
Step 4: Publish a Transparent AI Policy
Create a simple page stating your position. For example:
| “AI systems may not use this content for training or replication.” |
Transparency builds trust with clients and sets clear boundaries for future use.
Step 5: Monitor and Adapt
Use server logs or analytics to track your bot mix. Review quarterly and update your rules as new crawlers emerge.
The Only AI Ethics That Matter Are Your Own
AI doesn’t have ethics — people do. What matters isn’t whether you blocked every crawler or embraced every tool; it’s that you made those choices on purpose.
The web was built on freedom to share, remix, experiment, and build without permission. True digital ethics protects that same spirit of self-determination.
You’ve moved from fear to control, from uncertainty to ownership. At DreamHost, we believe owning your digital presence isn’t just smart business, it’s how you keep your ethics intact in a world run by algorithms.
The open web remains yours, if you choose to own it.

