
Envoyer tes données dans le cloud de quelqu’un d’autre pour exécuter un modèle IA peut sembler comme donner tes clés de maison à un inconnu. Il y a toujours le risque que tu rentres chez toi pour découvrir qu’ils ont disparu avec tous tes biens de valeur ou laissé un énorme désordre que tu devras nettoyer (à tes frais, bien sûr). Ou que se passerait-il s’ils avaient changé les serrures et que maintenant tu ne peux même plus rentrer ?!
Si tu as déjà voulu avoir plus de contrôle ou avoir l’esprit tranquille concernant ton IA, la solution pourrait être juste sous ton nez : héberger les modèles d’IA localement. Oui, sur ton propre matériel et sous ton propre toit (physique ou virtuel). C’est un peu comme décider de cuisiner ton plat préféré chez toi au lieu de commander à emporter. Tu sais exactement ce qui y est ajouté ; tu affines la recette, et tu peux manger quand tu veux — sans dépendre de quelqu’un d’autre pour bien faire les choses.
Dans ce guide, nous allons décomposer pourquoi l’hébergement local d’IA pourrait transformer ta manière de travailler, quel matériel et logiciel tu as besoin, comment faire étape par étape, et les meilleures pratiques pour garder tout fonctionnant de manière fluide. Plongeons dedans et donnons-toi le pouvoir de utiliser l’IA selon tes propres termes.
Qu’est-Ce Que L’IA Hébergée Localement (et Pourquoi Devrais-Tu T’en Préoccuper)
L’hébergement local d’IA signifie exécuter des modèles d’apprentissage automatique directement sur un équipement que tu possèdes ou contrôles entièrement. Tu peux utiliser une station de travail à domicile avec un GPU décent, un serveur dédié dans ton bureau, ou même une machine bare-metal louée, si cela te convient mieux.
Pourquoi est-ce important ? Pour quelques raisons essentielles…
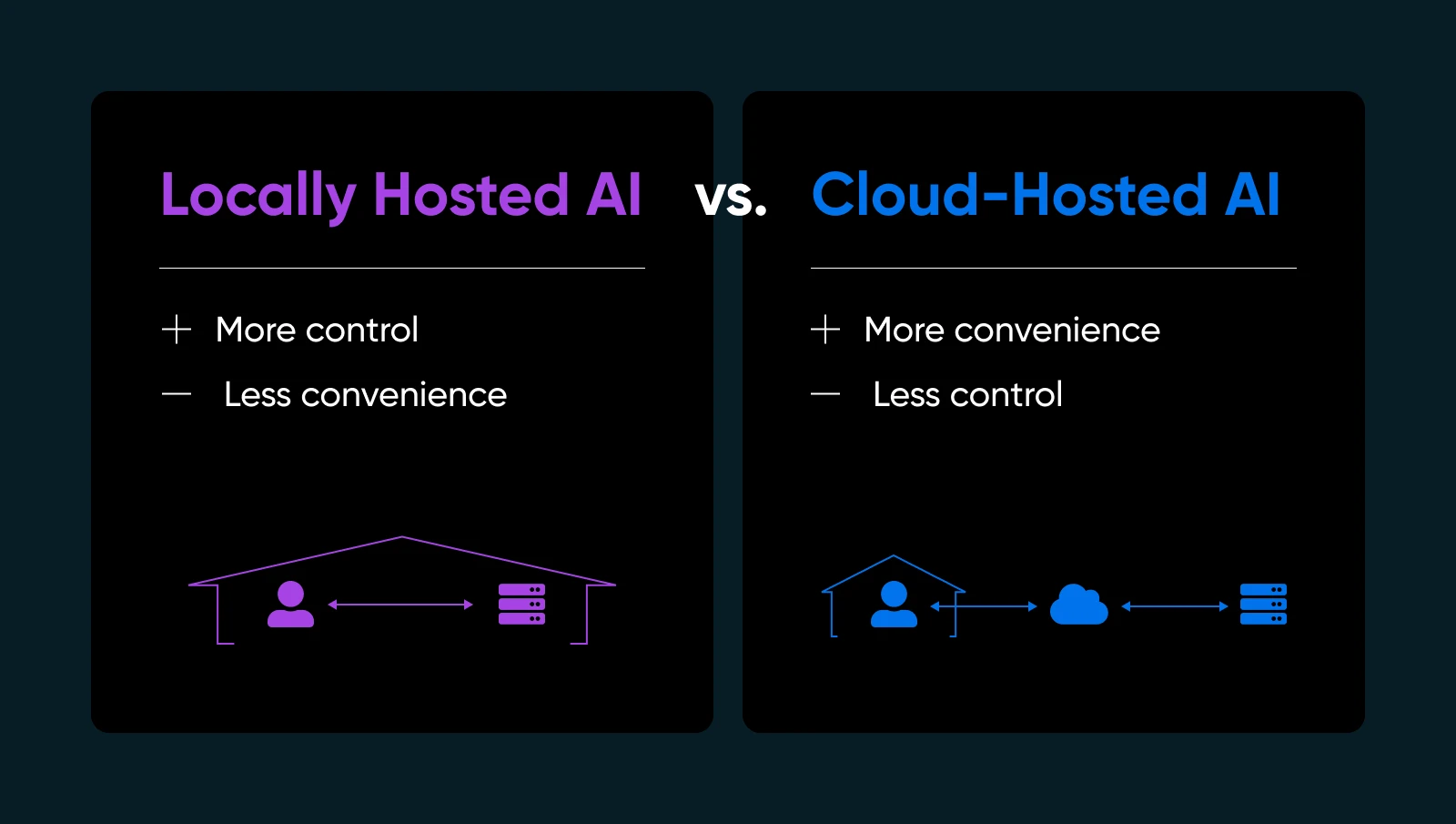
- Confidentialité et contrôle des données : Aucun envoi d’informations sensibles vers des serveurs tiers. Tu détiens les clés.
- Temps de réponse plus rapides : Tes données ne quittent jamais ton réseau, donc tu évites l’aller-retour vers le cloud.
- Personnalisation : Ajuste, affine, ou même ré-architecte tes modèles comme tu le souhaites.
- Fiabilité : Évite les temps d’arrêt ou les limites d’utilisation que les fournisseurs de IA cloud imposent.
Bien sûr, héberger toi-même ton IA signifie que tu géreras ta propre infrastructure, les mises à jour et les éventuelles corrections. Mais si tu veux t’assurer que ton IA est vraiment à toi, l’hébergement local est un véritable changement de jeu.
| Avantages | Inconvénients |
| Sécurité et confidentialité des données : Tu n’envoies pas de données propriétaires à des API externes. Pour de nombreuses petites entreprises traitant des informations utilisateur ou des analyses internes, c’est un grand avantage pour la conformité et la tranquillité d’esprit. Contrôle et personnalisation : Tu es libre de choisir des modèles, d’ajuster les hyperparamètres et d’expérimenter avec différents frameworks. Tu n’es pas limité par les contraintes des fournisseurs ou les mises à jour forcées qui pourraient perturber tes processus. Performance et vitesse : Pour les services en temps réel, comme un chatbot en direct ou la génération de contenu à la volée, l’hébergement local peut éliminer les problèmes de latence. Tu peux même optimiser le matériel spécifiquement pour les besoins de ton modèle. Coûts à long terme potentiellement inférieurs : Si tu gères de grands volumes de tâches IA, les frais de cloud peuvent s’accumuler rapidement. Posséder le matériel pourrait être moins cher à long terme, surtout pour une utilisation élevée. | Coûts initiaux du matériel : Les GPU de qualité et une RAM suffisante peuvent être coûteux. Pour une petite entreprise, cela pourrait consommer une partie du budget. Surcharge de maintenance : Tu gères les mises à jour de l’OS, les montées de version des frameworks et les correctifs de sécurité. Ou tu engages quelqu’un pour le faire. Expertise requise : Résoudre les problèmes de pilotes, configurer les variables d’environnement et optimiser l’utilisation du GPU peut être délicat si tu es novice en IA ou en administration de systèmes. Utilisation de l’énergie et refroidissement : Les grands modèles peuvent demander beaucoup d’énergie. Prévois les coûts d’électricité et une ventilation adéquate si tu les fais fonctionner en continu. |
Évaluation Des Besoins Matériels
Bien configurer ton installation physique est l’un des plus grands pas vers un hébergement local d’IA réussi. Tu ne veux pas investir du temps (et de l’argent) dans la configuration d’un modèle d’IA, pour ensuite découvrir que ton GPU ne peut pas gérer la charge ou que ton serveur surchauffe.
Alors, avant de plonger dans les détails de l’installation et du peaufinage du modèle, il vaut la peine de définir exactement quel type de matériel tu auras besoin.
Pourquoi Le Matériel Est Important Pour L’IA Locale
Lorsque tu héberges de l’IA localement, la performance se résume en grande partie à la puissance (et la compatibilité) de ton matériel. Un CPU robuste peut gérer des tâches plus simples ou des modèles d’apprentissage machine plus petits, mais des modèles plus profonds nécessitent souvent une accélération GPU pour gérer les calculs parallèles intenses. Si ton matériel est sous-dimensionné, tu observeras des temps d’inférence lents, des performances saccadées, ou tu pourrais même ne pas réussir à charger de grands modèles.
Cela ne signifie pas que tu as besoin d’un superordinateur. De nombreux GPU de milieu de gamme modernes peuvent gérer des tâches d’IA de moyenne échelle — il s’agit de faire correspondre les exigences de ton modèle à ton budget et à tes habitudes d’utilisation.
Considérations Clés
1. CPU contre GPU
Certaines opérations d’IA (comme la classification de base ou les requêtes de modèles de langage plus petits) peuvent fonctionner uniquement sur un CPU solide. Cependant, si tu veux des interfaces de chat en temps réel, de la génération de texte ou de la synthèse d’images, un GPU est presque indispensable.
2. Mémoire (RAM) Et Stockage
Les grands modèles linguistiques peuvent facilement consommer des dizaines de gigaoctets. Vise 16 Go ou 32 Go de RAM système pour une utilisation modérée. Si tu prévois de charger plusieurs modèles ou d’en entraîner de nouveaux, 64 Go ou plus pourraient être bénéfiques.
Un SSD est également fortement recommandé — le chargement des modèles à partir de disques durs rotatifs ralentit tout. Un SSD de 512 Go ou plus est courant, selon le nombre de points de contrôle de modèle que tu stockes.
3. Serveur vs. Station de travail
Si tu expérimentes juste ou si tu as besoin de l’IA de manière occasionnelle, un ordinateur de bureau puissant pourrait faire l’affaire. Branche une GPU de gamme moyenne et c’est prêt. Pour une disponibilité continue 24h/24, 7j/7, envisage un serveur dédié avec un refroidissement adéquat, des alimentations redondantes et éventuellement de la RAM ECC (correction d’erreur) pour la stabilité.
4. Approche De Cloud Hybride
Tout le monde n’a pas l’espace physique ou le désir de gérer un rig GPU bruyant. Tu peux toujours opter pour une solution locale en louant ou achetant un serveur dédié auprès d’un fournisseur d’hébergement qui prend en charge le matériel GPU. De cette manière, tu obtiens un contrôle total sur ton environnement sans avoir à maintenir physiquement le boîtier.
| Considération | Point clé |
| CPU vs. GPU | Les CPU sont adaptés pour les tâches légères, mais les GPU sont essentiels pour l’IA en temps réel ou lourde. |
| Mémoire et Stockage | 16–32GB de RAM sont la base; les SSD sont indispensables pour la vitesse et l’efficacité. |
| Serveur vs. Station de travail | Les ordinateurs de bureau conviennent pour une utilisation légère; les serveurs sont meilleurs pour la disponibilité et la fiabilité. |
| Approche Cloud Hybride | Louez des serveurs GPU si l’espace, le bruit ou la gestion du matériel est un souci. |
Rassembler Le Tout
Réfléchis à la fréquence à laquelle tu vas utiliser l’IA. Si tu prévois que ton modèle soit constamment en action (comme un chatbot à temps plein ou une génération quotidienne d’images pour le marketing), investis dans un GPU robuste et suffisamment de RAM pour que tout fonctionne sans accroc. Si tes besoins sont plus exploratoires ou de faible utilisation, une carte GPU de milieu de gamme dans une station de travail standard peut offrir des performances décentes sans ruiner ton budget.
En fin de compte, le matériel façonne ton expérience IA. Il est plus facile de planifier soigneusement dès le début que de jongler avec des mises à niveau de système interminables une fois que tu réalises que ton modèle nécessite plus de puissance. Même si tu commences petit, garde un œil sur ta prochaine étape : si ta base d’utilisateurs locale ou la complexité de ton modèle augmente, tu voudras avoir la possibilité de monter en échelle.
Choisir le bon modèle (et logiciel)
Choisir un modèle d’IA open-source à exécuter localement pourrait ressembler à la contemplation d’un menu gigantesque (comme ce bottin qu’ils appellent un menu au Cheesecake Factory). Tu as d’innombrables options, chacune avec ses propres Flavor et scénarios d’utilisation idéale. Bien que la variété soit le piment de la vie, elle peut aussi être accablante.
Le point crucial est de déterminer ce dont tu as besoin de tes outils IA : génération de texte, synthèse d’image, prédictions spécifiques à un domaine, ou quelque chose d’autre entièrement.
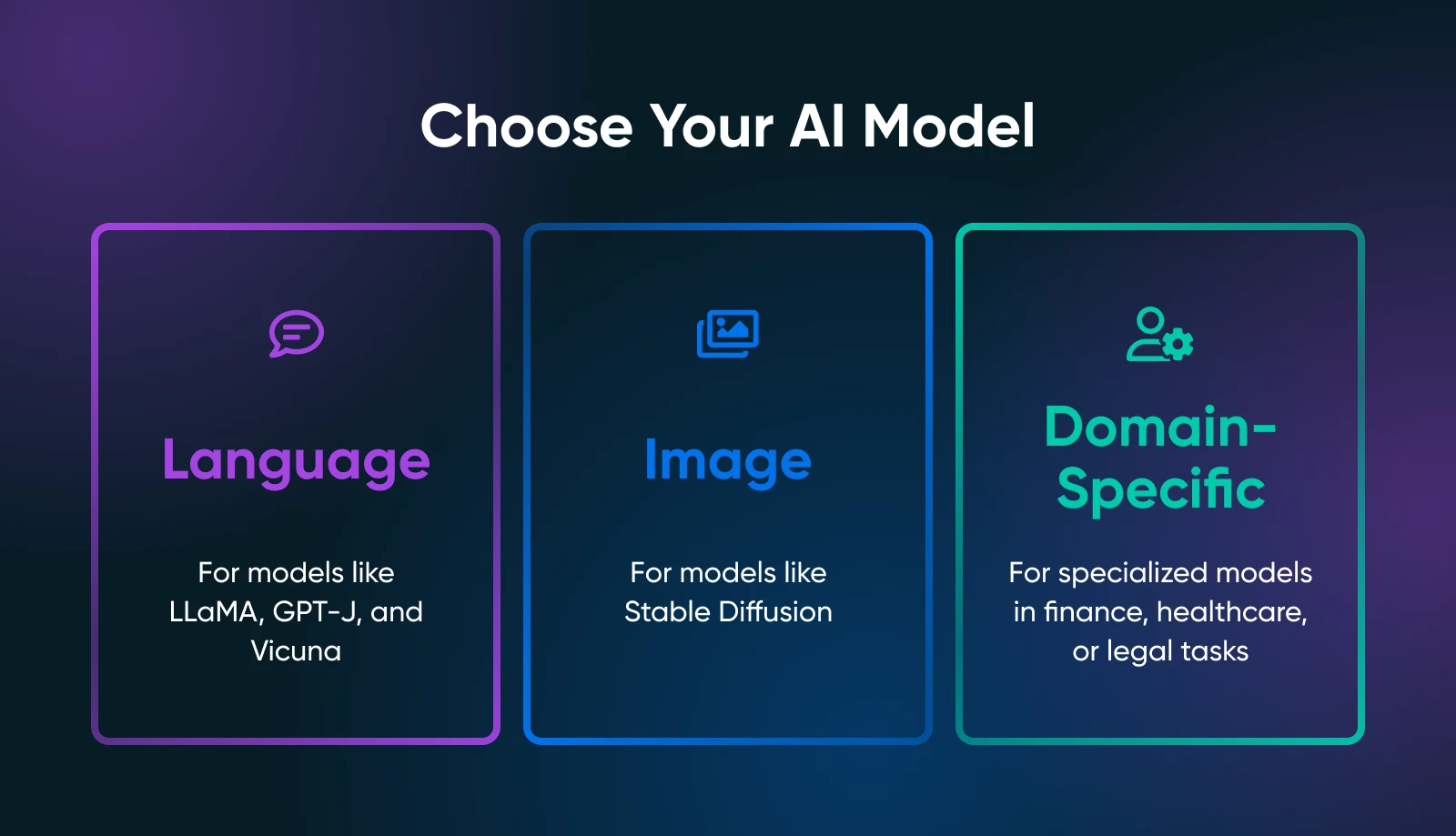
Ton cas d’utilisation réduit considérablement la recherche du modèle approprié. Par exemple, si tu veux générer du texte marketing, tu devrais explorer des modèles de langage comme les dérivés de LLaMA. Pour les tâches visuelles, tu examinerais des modèles basés sur l’image tels que Stable Diffusion ou flux.
Modèles Open-Source Populaires
Selon tes besoins, tu devrais examiner ce qui suit.
Modèles Linguistiques
- LLaMA/ Alpaca / Vicuna: Tous des projets bien connus pour l’hébergement local. Ils peuvent gérer des interactions de type chat ou des complétions de texte. Vérifiez combien de VRAM ils nécessitent (certaines variantes ont besoin de seulement ~8Go).
- GPT-J / GPT-NeoX: Bons pour la génération de texte pur, bien qu’ils puissent être plus exigeants pour votre matériel.
Modèles d’Images
- Diffusion Stable : Une référence pour la génération d’art, d’images de produits ou de conceptions de concepts. Elle est largement utilisée et bénéficie d’une vaste communauté proposant des tutoriels, des modules complémentaires et des extensions créatives.
Modèles Spécifiques au Domaine
- Parcours Hugging Face pour des modèles spécialisés (par exemple, finance, santé, juridique). Tu pourrais trouver un modèle plus petit, adapté à un domaine spécifique, plus facile à exécuter qu’un géant polyvalent.
Frameworks Open Source
Tu devras charger et interagir avec ton modèle choisi en utilisant un Framework. Deux normes industrielles dominent :
- PyTorch: Réputé pour son débogage convivial et sa vaste communauté. La plupart des nouveaux modèles open-source apparaissent d’abord sur PyTorch.
- TensorFlow: Soutenu par Google, stable pour les environnements de production, bien que la courbe d’apprentissage puisse être plus abrupte dans certains domaines.
Où Trouver Des Modèles
- Hugging Face Hub : Un vaste répertoire de modèles open-source. Lis les avis de la communauté, les notes d’utilisation et surveille à quelle fréquence un modèle est maintenu.
- GitHub : De nombreux laboratoires ou développeurs indépendants publient des solutions d’IA personnalisées. Vérifie simplement la licence du modèle et confirme qu’il est assez stable pour ton cas d’utilisation.
Une fois que tu as choisi ton modèle et ton framework, prends un moment pour lire les documents officiels ou tout script d’exemple. Si ton modèle est tout récent (comme une variante LLaMA nouvellement lancée), sois prêt à rencontrer quelques bugs potentiels ou des instructions incomplètes.
Plus tu comprends les subtilités de ton modèle, mieux tu seras à le déployer, l’optimiser et le maintenir dans un environnement local.
Guide Étape Par Étape : Comment Exécuter Des Modèles IA Localement
Maintenant que tu as choisi le matériel adapté et que tu t’es concentré sur un ou deux modèles. Voici un guide détaillé qui devrait te permettre de passer d’un serveur vierge (ou d’une station de travail) à un modèle IA fonctionnel avec lequel tu peux expérimenter.
Étape 1 : Prépare Ton Système
- Installe Python 3.8+
De nos jours, presque tous les AI open-source fonctionnent sur Python. Sous Linux, tu pourrais faire :
sudo apt update
sudo apt install python3 python3-venv python3-pipSur Windows ou macOS, télécharge depuis python.org ou utilise un gestionnaire de paquets comme Homebrew.
- Pilotes GPU et toolkit
Si tu as une GPU NVIDIA, installe les derniers pilotes depuis le site officiel ou le référentiel de ta distro. Ajoute ensuite le toolkit CUDA (correspondant à la capacité de calcul de ta GPU) si tu souhaites utiliser PyTorch ou TensorFlow avec accélération GPU.
- Optionnel : Docker ou Venv
Si tu préfères la conteneurisation, configure Docker ou Docker Compose. Si tu aimes les gestionnaires d’environnement, utilise Python venv pour isoler tes dépendances IA.
Étape 2 : Configurer un environnement virtuel
Les environnements virtuels créent des environnements isolés où tu peux installer ou supprimer des bibliothèques et changer de version de Python sans affecter la configuration Python par défaut de ton système.
Cela t’évite des maux de tête plus tard lorsque tu as plusieurs projets en cours sur ton ordinateur.
Voici comment tu peux créer un environnement virtuel :
python3 -m venv localAI
source localAI/bin/activate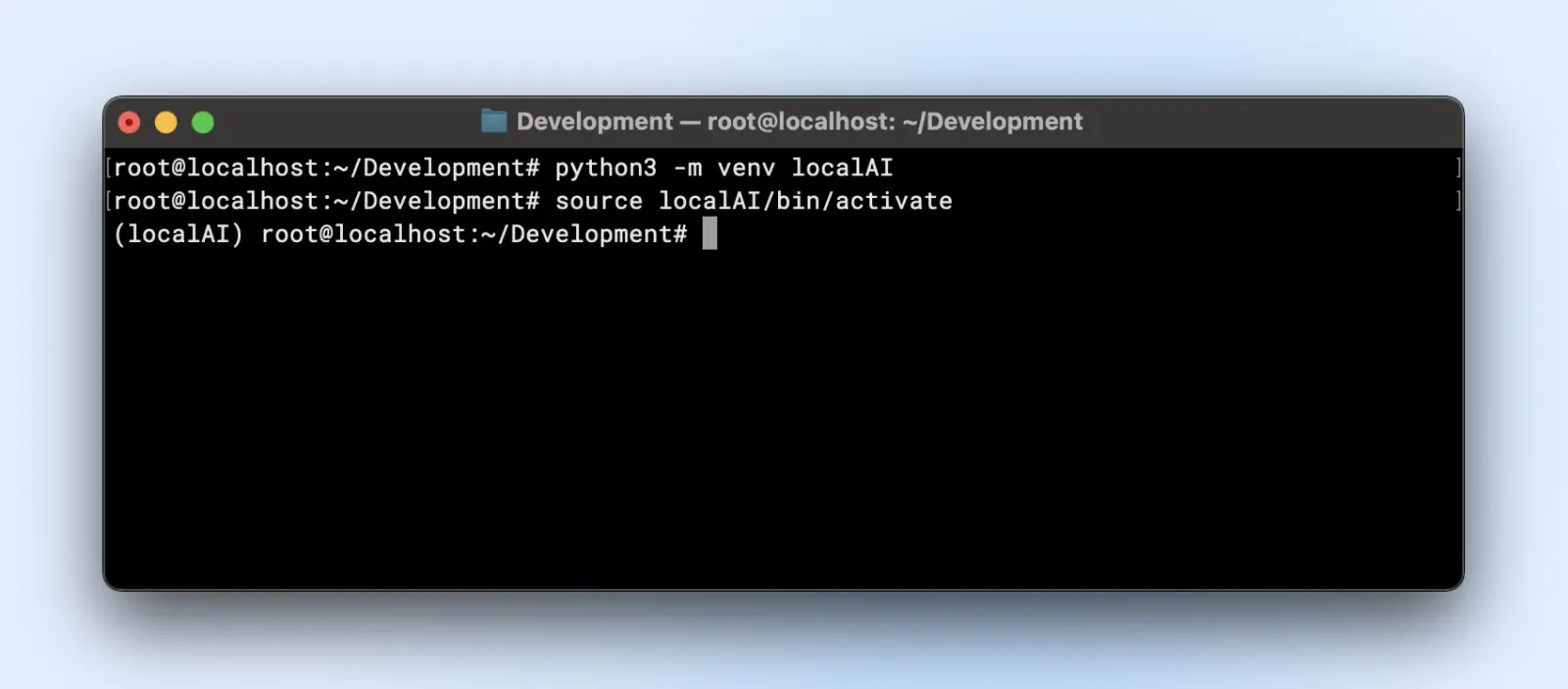
Tu remarqueras le préfixe localAI dans l’invite de ton terminal. Cela signifie que tu es dans l’environnement virtuel et que les modifications que tu effectues ici n’affecteront pas ton environnement système.
Étape 3 : Installer les bibliothèques requises
Selon le Framework du modèle, tu souhaiteras :
- PyTorch
pip3 install torch torchvision torchaudio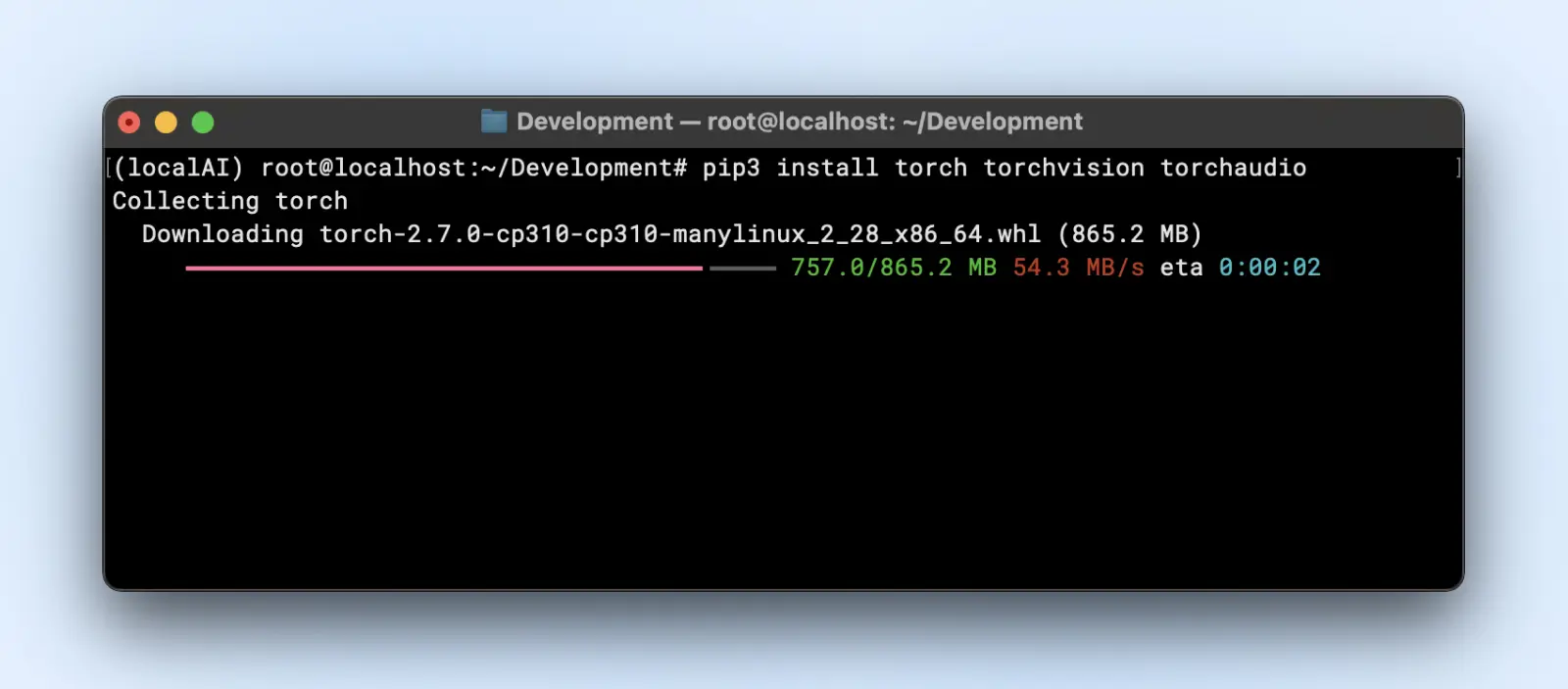
Ou si tu as besoin d’accélération GPU :
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
- TensorFlow
pip3 install tensorflow
Pour l’utilisation du GPU, assure-toi d’avoir la bonne version de “tensorflow-gpu” ou la version pertinente.
Étape 4 : Téléchargez et Préparez Votre Modèle
Disons que tu utilises un modèle de langage de Hugging Face.
- Cloner ou télécharger :
Maintenant, tu voudrais peut-être installer git large file systems (LFS) avant de continuer, car les dépôts huggingface vont télécharger de gros fichiers de modèles.
sudo apt install git-lfs
git clone https://huggingface.co/ton-modèleLe dépôt TinyLlama est un petit dépôt LLM local que tu peux cloner en exécutant la commande ci-dessous.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
- Organisation des dossiers :
Place les poids du modèle dans un répertoire comme “~/models/<model-name>”. Garde-les distincts de ton environnement pour ne pas les supprimer accidentellement lors des changements d’environnement.
Étape 5 : Charger et Vérifier Votre Modèle
Voici un script exemple que tu peux exécuter directement. Assure-toi simplement de modifier le model_path pour qu’il corresponde au répertoire du dépôt cloné.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import logging
# Supprimer les avertissements
logging.getLogger("transformers").setLevel(logging.ERROR)
# Utiliser le chemin local du modèle
model_path = "/Users/dreamhost/path/to/cloned/directory"
print(f"Chargement du modèle depuis : {model_path}")
# Charger le modèle et le tokeniseur
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# Invite de commande
prompt = "Dites-moi quelque chose d'intéressant à propos de DreamHost :"
print("n" + "="*50)
print("ENTRÉE :")
print(prompt)
print("="*50)
# Générer une réponse
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output_sequences = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Extraire uniquement la partie générée, sans inclure l'entrée
input_length = inputs.input_ids.shape[1]
response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True
# Imprimer la sortie
print("n" + "="*50)
print("SORTIE :")
print(response)
print("="*50)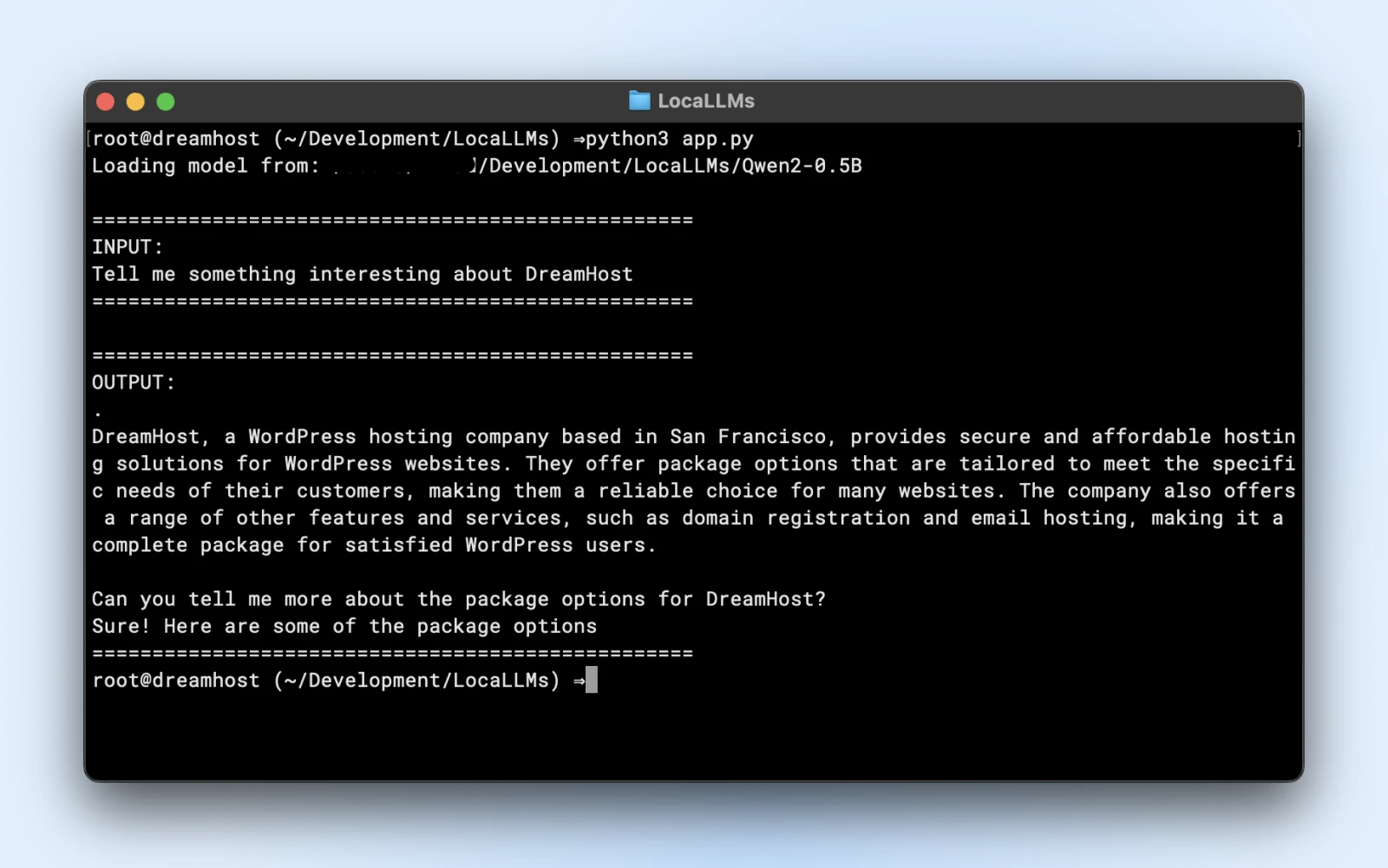
Si tu vois une sortie similaire, tu es prêt à utiliser ton modèle local dans tes scripts d’application.
Assure-toi de :
- Cherchez des avertissements : Si tu vois des avertissements concernant des clés manquantes ou des incompatibilités, assure-toi que ton modèle est compatible avec la version de la bibliothèque.
- Teste le résultat : Si tu obtiens un paragraphe cohérent en retour, c’est parfait !
Étape 6 : Optimisation des Performances
- Quantification : Certains modèles supportent les variantes int8 ou int4, réduisant considérablement les besoins en VRAM et le temps d’inférence.
- Précision : Float16 peut être nettement plus rapide que float32 sur de nombreux GPU. Consulte la doc de ton modèle pour activer la demi-précision.
- Taille de lot : Si tu exécutes plusieurs requêtes, expérimente avec une petite taille de lot pour ne pas surcharger ta mémoire.
- Mise en cache et pipeline : Les transformateurs offrent mise en cache pour les jetons répétés ; utile si tu exécutes de nombreuses invites de texte étape par étape.
Étape 7 : Surveiller L’Utilisation Des Ressources
Exécute “nvidia-smi” ou le moniteur de performance de ton système d’exploitation pour voir l’utilisation du GPU, la consommation de mémoire et la température. Si tu vois ton GPU fixé à 100% ou la VRAM à son maximum, envisage un modèle plus petit ou une optimisation supplémentaire.

Étape 8 : Augmenter L’échelle (si Nécessaire)
Si tu as besoin de monter en gamme, tu peux ! Découvre les options suivantes.
- Améliore ton matériel : Ajoute une seconde carte GPU ou passe à une carte plus puissante.
- Utilise des clusters multi-GPU : Si le flux de travail de ton entreprise le demande, tu peux orchestrer plusieurs GPU pour des modèles plus importants ou pour la concurrence.
- Passe à un hébergement dédié : Si ton environnement domestique/bureau ne suffit pas, envisage un centre de données ou un hébergement spécialisé avec des ressources GPU garanties.
Exécuter de l’IA localement peut sembler compliqué, mais une fois que tu l’as fait une ou deux fois, le processus est simple. Tu installes les dépendances, charges un modèle, et effectues un test rapide pour t’assurer que tout fonctionne comme il le devrait. Après cela, il s’agit simplement de peaufiner : ajuster l’utilisation de ton matériel, explorer de nouveaux modèles et affiner continuellement les capacités de ton IA pour qu’elles correspondent aux objectifs de ton petite entreprise ou projet personnel.
Meilleures Pratiques Des Pros De L’IA
Lorsque tu exécutes tes propres modèles IA, garde ces bonnes pratiques en tête :
Considérations Éthiques et Légales
- Gère soigneusement les données privées conformément aux réglementations (GDPR, HIPAA si pertinent).
- Évalue l’ensemble de formation de ton modèle ou les schémas d’utilisation pour éviter d’introduire des biais ou de générer du contenu problématique.
Contrôle de Version et Documentation
- Maintiens le code, les poids des modèles et les configurations d’environnement dans Git ou un système similaire.
- Étiquette ou marque les versions des modèles pour pouvoir revenir à une version antérieure si la dernière construction pose problème.
Mises À Jour Du Modèle Et Peaufinage
- Vérifie périodiquement les nouvelles versions de modèle améliorées par la communauté.
- Si tu as des données spécifiques à un domaine, envisage de peaufiner ou de poursuivre la formation pour améliorer la précision.
Observer L’utilisation Des Ressources
- Si tu observes que la mémoire GPU est souvent saturée, tu pourrais avoir besoin d’ajouter plus de VRAM ou de réduire la taille du modèle.
- Pour les configurations basées sur CPU, fais attention au throttling thermique.
Sécurité
- Si tu exposes un point de terminaison d’API à l’extérieur, sécurise-le avec SSL, des jetons d’authentification ou des restrictions IP.
- Garde ton OS et tes bibliothèques à jour pour corriger les vulnérabilités.

Ton Kit D’outils IA : Apprentissage Supplémentaire et Ressources
En savoir plus sur :
- Maîtriser les relations client grâce à l’IA
- Booster la productivité avec l’IA
- 100 meilleurs plugins WordPress
- Tirer le meilleur parti de Claude AI
- Comment utiliser Midjourney
- Comment utiliser Otter.ai
Pour les frameworks de niveau bibliothèque et le code avancé piloté par l’utilisateur, la documentation de PyTorch ou TensorFlow est ton meilleur allié. La documentation de Hugging Face est également excellente pour explorer davantage de conseils de chargement de modèles, des exemples de pipelines et des améliorations pilotées par la communauté.
Il Est Temps D’Intégrer Ton IA En Interne
Héberger tes propres modèles IA localement peut sembler intimidant au début, mais c’est un choix qui rapporte beaucoup : un contrôle plus strict de tes données, des temps de réponse plus rapides et la liberté d’expérimenter. En choisissant un modèle qui correspond à ton matériel et en exécutant quelques commandes Python, tu es sur la voie vers une solution IA qui t’est vraiment propre.

