
Je gegevens naar de cloud van iemand anders sturen om een AI-model te draaien, kan voelen alsof je je huissleutels aan een vreemde geeft. Er is altijd een kans dat je thuiskomt en ontdekt dat ze met al je waardevolle spullen zijn vandoor gegaan of een enorme puinhoop hebben achtergelaten die jij moet opruimen (natuurlijk op jouw kosten). Of wat als ze de sloten hebben veranderd en je er nu niet meer in kunt?!
Als je ooit meer controle of gemoedsrust wilde over jouw AI, dan zou de oplossing wel eens vlak onder je neus kunnen liggen: AI-modellen lokaal hosten. Ja, op je eigen hardware en onder je eigen dak (fysiek of virtueel). Het is een beetje alsof je besluit om je favoriete gerecht thuis te koken in plaats van afhaalmaaltijden te bestellen. Je weet precies wat erin gaat; je stemt het recept fijn af, en je kunt eten wanneer je maar wilt – zonder afhankelijk te zijn van iemand anders om het goed te krijgen.
In deze gids leggen we uit waarom lokale AI-hosting de manier waarop je werkt kan transformeren, welke hardware en software je nodig hebt, hoe je dit stap voor stap doet en de beste praktijken om alles soepel te laten verlopen. Laten we erin duiken en jou de kracht geven om AI uit te voeren op jouw eigen voorwaarden.
Wat Is Lokaal Gehoste AI (en Waarom Het Je Aangaat)
Lokaal gehoste AI betekent het uitvoeren van machine learning-modellen rechtstreeks op apparatuur die je bezit of volledig beheert. Je kunt een thuiswerkstation met een fatsoenlijke GPU gebruiken, een dedicated server op je kantoor, of zelfs een gehuurde kale machine, als dat beter bij je past.
Waarom doet dit ertoe? Een paar belangrijke redenen…
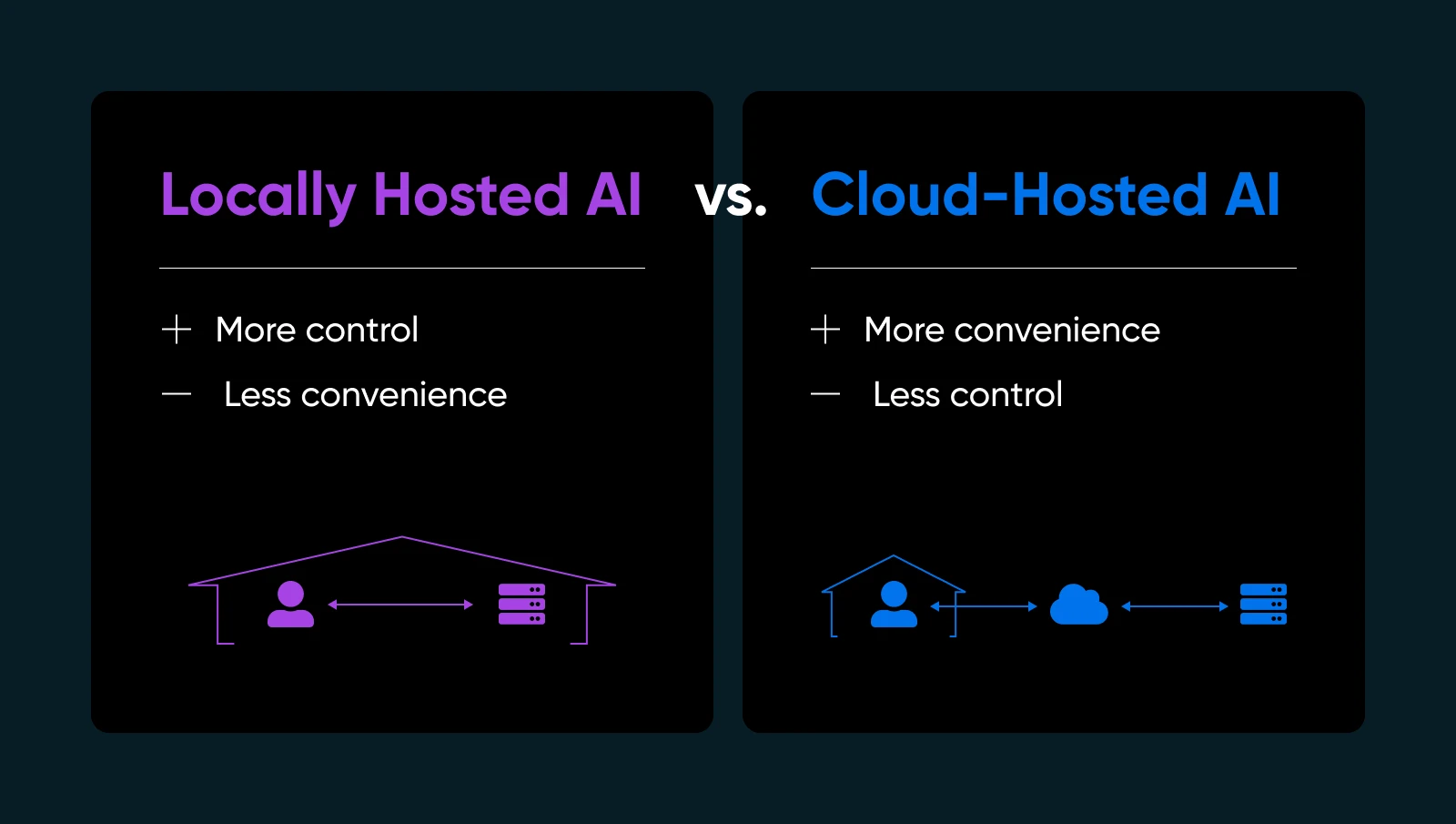
- Privacy en gegevensbeheer: Geen gevoelige informatie naar servers van derden verzenden. Jij houdt de sleutels.
- Snellere reactietijden: Je gegevens verlaten je netwerk niet, dus je vermijdt de reis heen en terug naar de cloud.
- Aanpassing: Pas aan, verfijn of herontwerp je modellen naar eigen inzicht.
- Betrouwbaarheid: Vermijd downtime of gebruikslimieten die cloud AI-providers opleggen.
Natuurlijk betekent het zelf hosten van AI dat je je eigen infrastructuur, updates en mogelijke oplossingen beheert. Maar als je er zeker van wilt zijn dat je AI echt van jou is, is lokale hosting een game-changer.
| Voordelen | Nadelen |
| Beveiliging en gegevensprivacy: Je stuurt geen eigen gegevens naar externe API’s. Voor veel kleine bedrijven die met gebruikersinformatie of interne analyses werken, is dat een groot voordeel voor naleving en gemoedsrust. Controle en aanpassing: Je bent vrij om modellen te kiezen, hyperparameters aan te passen en te experimenteren met verschillende frameworks. Je bent niet gebonden aan leveranciersbeperkingen of gedwongen updates die je workflows kunnen verstoren. Prestaties en snelheid: Voor real-time diensten, zoals een live chatbot of on-the-fly contentgeneratie, kan lokale hosting latency problemen elimineren. Je kunt zelfs hardware specifiek voor de behoeften van je model optimaliseren. Potentieel lagere kosten op lange termijn: Als je grote hoeveelheden AI-taken verwerkt, kunnen cloudkosten snel oplopen. Het bezitten van de hardware kan op termijn goedkoper zijn, vooral bij hoog gebruik. | Initiële hardwarekosten: Kwalitatieve GPU’s en voldoende RAM kunnen prijzig zijn. Voor een klein bedrijf kan dat een deel van het budget opslokken. Onderhoudsoverhead: Je beheert OS-updates, framework-upgrades en beveiligingspatches. Of je huurt iemand in om dit te doen. Vereiste expertise: Problemen met drivers oplossen, omgevingsvariabelen configureren en GPU-gebruik optimaliseren kan lastig zijn als je nieuw bent in AI of systeembeheer. Energieverbruik en koeling: Grote modellen kunnen veel stroom vereisen. Plan voor elektriciteitskosten en geschikte ventilatie als je ze continu draait. |
Hardwarevereisten Beoordelen
Het juist instellen van je fysieke opstelling is een van de grootste stappen naar succesvolle lokale AI-hosting. Je wilt geen tijd (en geld) investeren in het configureren van een AI-model, om er vervolgens achter te komen dat je GPU de belasting niet aankan of dat je server oververhit raakt.
Dus, voordat je in de details van de installatie en het finetunen van het model duikt, is het de moeite waard om precies in kaart te brengen welke hardware je nodig zult hebben.
Waarom Hardware Belangrijk Is Voor Lokale AI
Wanneer je AI lokaal host, komt de prestatie grotendeels neer op hoe krachtig (en compatibel) je hardware is. Een robuuste CPU kan eenvoudigere taken of kleinere machine learning-modellen aan, maar diepere modellen hebben vaak GPU-versnelling nodig om de intensieve parallelle berekeningen te kunnen verwerken. Als je hardware niet krachtig genoeg is, zul je trage inferentietijden, schokkerige prestaties zien, of je kunt grote modellen misschien helemaal niet laden.
Dat betekent niet dat je een supercomputer nodig hebt. Veel moderne GPU’s van gemiddeld bereik kunnen middelgrote AI-taken aan — het gaat erom dat je de eisen van je model afstemt op je budget en gebruikspatronen.
Belangrijke Overwegingen
1. CPU vs. GPU
Sommige AI-operaties (zoals basisclassificatie of kleinere taalmodelquery’s) kunnen alleen op een solide CPU draaien. Echter, als je real-time chatinterfaces, tekstgeneratie of beeldsynthese wilt, is een GPU bijna noodzakelijk.
2. Geheugen (RAM) en Opslag
Grote taalmodellen kunnen gemakkelijk tientallen gigabytes verbruiken. Richt je op 16GB of 32GB systeem RAM voor gematigd gebruik. Als je van plan bent meerdere modellen te laden of nieuwe te trainen, kan 64GB+ voordelig zijn.
Een SSD wordt ook sterk aanbevolen — het laden van modellen vanaf draaiende HDD’s vertraagt alles. Een SSD van 512GB of groter is gebruikelijk, afhankelijk van hoeveel modelcontrolepunten je opslaat.
3. Server vs. Werkstation
Als je alleen experimenteert of slechts af en toe AI nodig hebt, kan een krachtige desktop volstaan. Sluit een mid-range GPU aan en je bent klaar. Overweeg voor 24/7 uptime een dedicated server met de juiste koeling, redundante stroomvoorzieningen en mogelijk ECC (foutcorrigerend) RAM voor stabiliteit.
4. Hybride Cloud Benadering
Niet iedereen heeft de fysieke ruimte of de wens om een luidruchtige GPU-rig te beheren. Je kunt nog steeds “lokaal gaan” door een dedicated server te huren of te kopen bij een hostingprovider die GPU-hardware ondersteunt. Op die manier heb je volledige controle over je omgeving zonder de box fysiek te onderhouden.
| Overweging | Belangrijkste Les |
| CPU vs. GPU | CPU’s werken voor lichte taken, maar GPU’s zijn essentieel voor real-time of zware AI. |
| Geheugen en Opslag | 16-32GB RAM is de basis; SSD’s zijn een must voor snelheid en efficiëntie. |
| Server vs. Werkstation | Desktops zijn prima voor licht gebruik; servers zijn beter voor uptime en betrouwbaarheid. |
| Hybride Cloud Aanpak | Huur GPU-servers als ruimte, geluid of hardwarebeheer een zorg is. |
Alles Samenvoegen
Denk na over hoe intensief je AI zult gebruiken. Als je merkt dat je model constant actief is (zoals een fulltime chatbot of dagelijkse beeldgeneratie voor marketing), investeer dan in een krachtige GPU en voldoende RAM om alles soepel te laten verlopen. Als je behoeften meer verkennend zijn of je gebruikt het licht, kan een mid-tier GPU-kaart in een standaard werkstation fatsoenlijke prestaties leveren zonder je budget te ruïneren.
Uiteindelijk bepaalt de hardware je AI-ervaring. Het is gemakkelijker om zorgvuldig van tevoren te plannen dan om eindeloze systeemupgrades te jongleren zodra je beseft dat je model meer kracht nodig heeft. Zelfs als je klein begint, houd dan je volgende stap in de gaten: als je lokale gebruikersbasis of modelcomplexiteit groeit, wil je ruimte hebben om te schalen.
Het Juiste Model (en Software) Kiezen
Het kiezen van een open-source AI-model om lokaal te draaien, kan aanvoelen alsof je naar een enorm menu staart (zoals dat telefoonboek dat ze een menu noemen bij Cheesecake Factory). Je hebt eindeloze opties, elk met zijn eigen smaken en beste gebruiksscenario’s. Hoewel variatie is de specerij van het leven, kan het ook overweldigend zijn.
Het is belangrijk om precies vast te stellen wat jij nodig hebt van je AI-tools: tekstgeneratie, beeldsynthese, domeinspecifieke voorspellingen, of iets geheel anders.
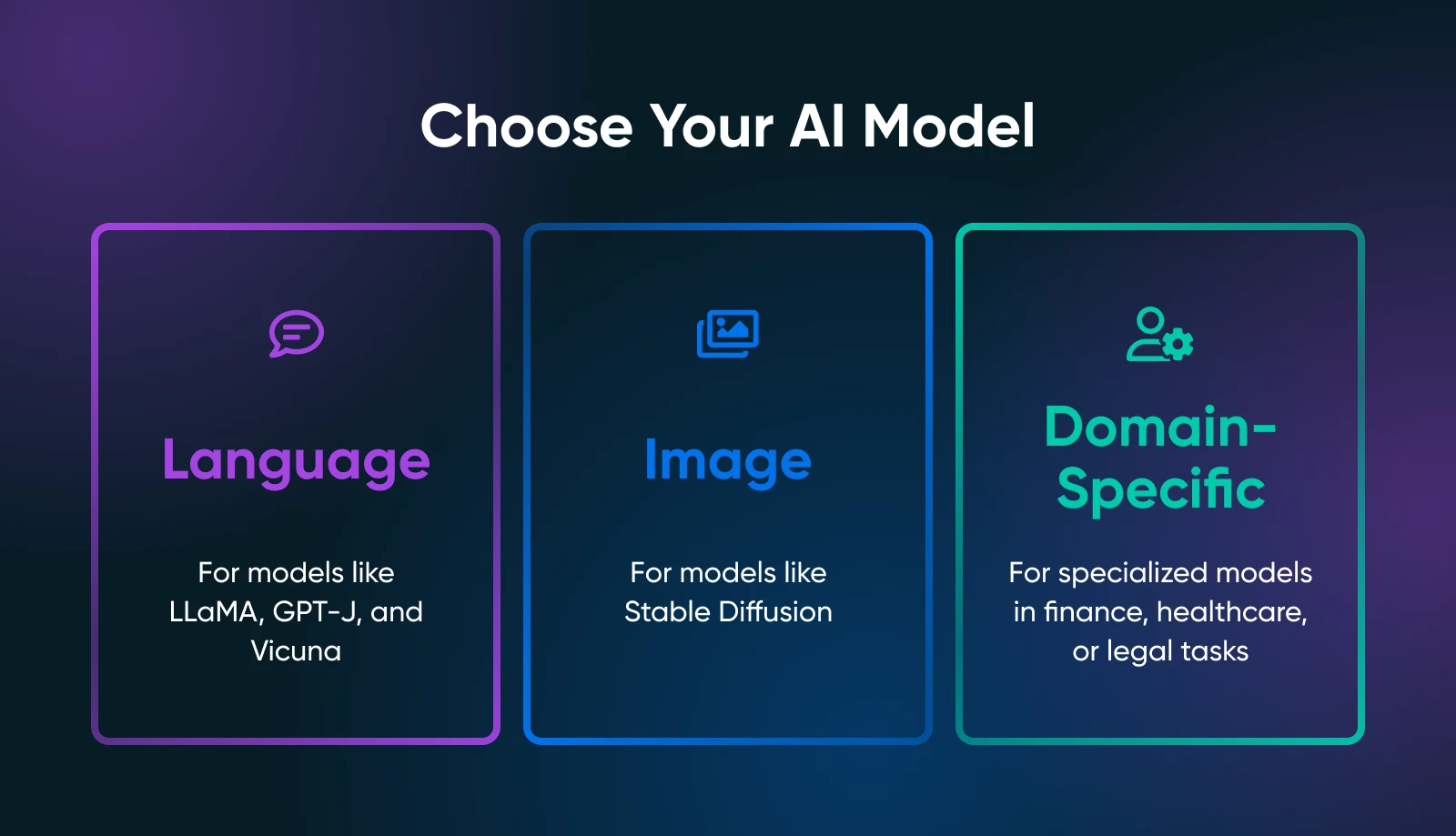
Jouw gebruiksscenario beperkt de zoektocht naar het juiste model aanzienlijk. Als je bijvoorbeeld marketingteksten wilt genereren, zou je taalmodellen verkennen zoals LLaMA-derivaten. Voor visuele taken zou je kijken naar beeldgebaseerde modellen zoals Stable Diffusion of flux.
Populaire Open-Source Modellen
Afhankelijk van je behoeften, moet je het volgende bekijken.
Taalmodellen
- LLaMA/ Alpaca / Vicuna: Alle bekende projecten voor lokale hosting. Ze kunnen chat-achtige interacties of tekstvoltooiing aan. Controleer hoeveel VRAM ze nodig hebben (sommige varianten hebben slechts ongeveer 8GB nodig).
- GPT-J / GPT-NeoX: Goed voor pure tekstgeneratie, hoewel ze veeleisender kunnen zijn voor je hardware.
Beeldmodellen
- Stable Diffusion: Een veelgebruikte tool voor het genereren van kunst, productafbeeldingen of conceptontwerpen. Het wordt veel gebruikt en heeft een grote gemeenschap die tutorials, Add-ons en creatieve uitbreidingen biedt.
Domeinspecifieke Modellen
- Blader door Hugging Face voor gespecialiseerde modellen (bijv. financiën, gezondheidszorg, juridisch). Je kunt een kleiner, domein-afgestemd model vinden dat makkelijker te gebruiken is dan een algemeen groot model.
Open Source Frameworks
Je moet je gekozen model laden en ermee interageren met behulp van een Framework. Er domineren twee industriestandaarden:
- PyTorch: Beroemd om gebruiksvriendelijke debugging en een grote gemeenschap. De meeste nieuwe open-source modellen verschijnen eerst in PyTorch.
- TensorFlow: Ondersteund door Google, stabiel voor productieomgevingen, hoewel de leercurve op sommige gebieden steiler kan zijn.
Waar Je Modellen Kunt Vinden
- Hugging Face Hub: Een enorme opslagplaats van open-source modellen. Lees gemeenschapsbeoordelingen, gebruiksaanwijzingen en let op hoe actief een model wordt onderhouden.
- GitHub: Vele laboratoria of indie ontwikkelaars plaatsen aangepaste AI-oplossingen. Verifieer gewoon de licentie van het model en bevestig dat het stabiel genoeg is voor jouw gebruikssituatie.
Nadat je jouw model en Framework hebt gekozen, neem even de tijd om de officiële documenten of eventuele voorbeeldscripts te lezen. Als jouw model gloednieuw is (zoals een pas uitgebrachte LLaMA-variant), wees dan voorbereid op enkele mogelijke bugs of onvolledige instructies.
Hoe beter je de nuances van je model begrijpt, hoe beter je in staat bent om het te implementeren, optimaliseren en onderhouden in een lokale omgeving.
Stap-Voor-Stap Handleiding: Hoe AI Modellen Lokaal Te Draaien
Nu heb je geschikte hardware gekozen en je gericht op één of twee modellen. Hieronder volgt een gedetailleerde handleiding die je van een lege server (of werkstation) naar een functionerend AI-model moet brengen waarmee je kunt spelen.
Stap 1: Bereid Je Systeem Voor
- Installeer Python 3.8+
Vrijwel alle open-source AI draait tegenwoordig op Python. Op Linux zou je kunnen doen:
sudo apt update
sudo apt install python3 python3-venv python3-pipOp Windows of macOS, download van python.org of gebruik een pakketbeheerder zoals Homebrew.
- GPU-stuurprogramma’s en toolkit
Als je een NVIDIA GPU hebt, installeer dan de nieuwste drivers van de officiële site of de distributie van je repository. Voeg vervolgens de CUDA toolkit toe (die overeenkomt met de rekenkracht van je GPU) als je GPU-versnelde PyTorch of TensorFlow wilt gebruiken.
- Optioneel: Docker of Venv
Als je containerisatie verkiest, stel Docker of Docker Compose in. Als je van omgevingsbeheerders houdt, gebruik Python venv om je AI-afhankelijkheden te isoleren.
Stap 2: Stel Een Virtuele Omgeving In
Virtuele omgevingen creëren geïsoleerde omgevingen waar je bibliotheken kunt installeren of verwijderen en de Python-versie kunt wijzigen zonder de standaard Python-configuratie van je systeem te beïnvloeden.
Dit bespaart je hoofdpijn verderop wanneer je meerdere projecten op je computer hebt draaien.
Hier is hoe je een virtuele omgeving kunt creëren:
python3 -m venv localAI
source localAI/bin/activate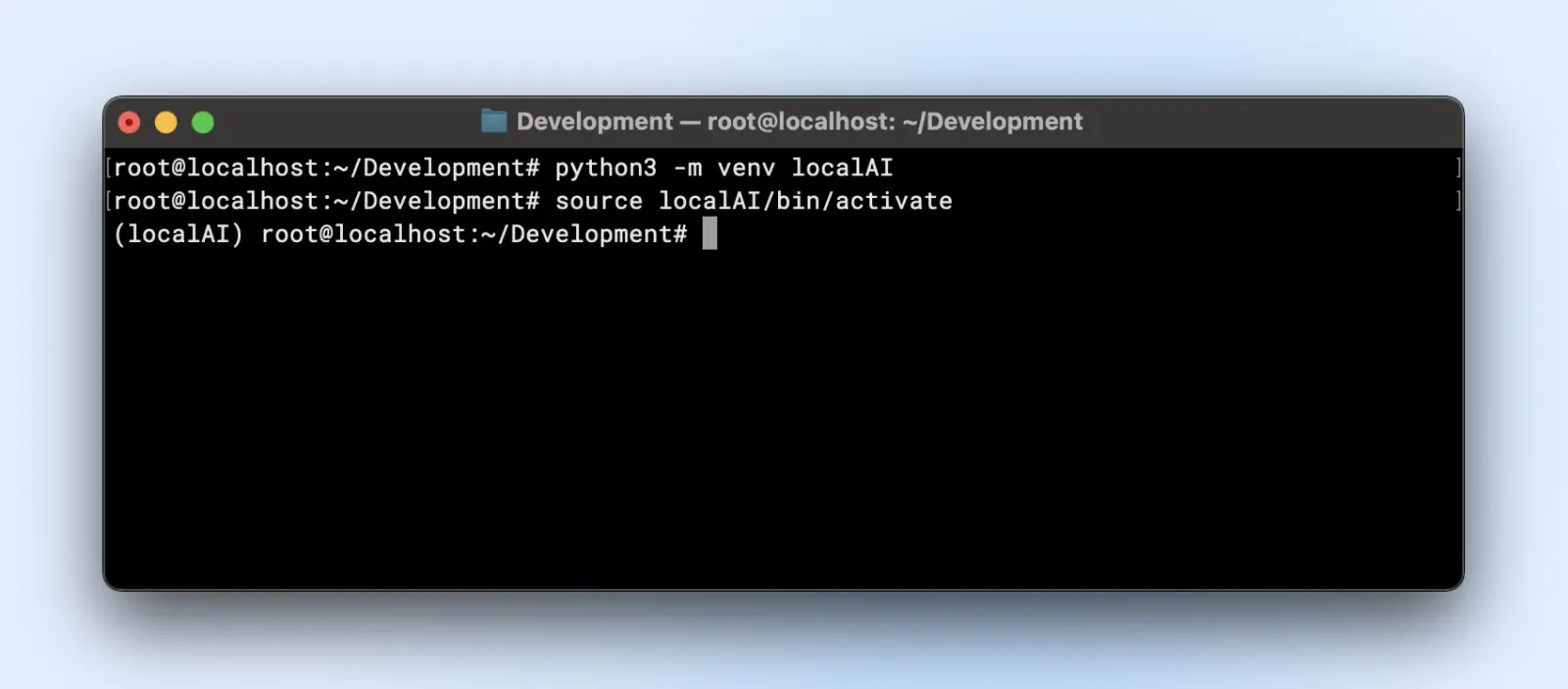
Je zult de localAI prefix in je terminalprompt opmerken. Dat betekent dat je je in de virtuele omgeving bevindt en eventuele wijzigingen die je hier aanbrengt geen invloed hebben op je systeemomgeving.
Stap 3: Installeer Vereiste Bibliotheken
Afhankelijk van het raamwerk van het model, wil je:
- PyTorch
pip3 install torch torchvision torchaudio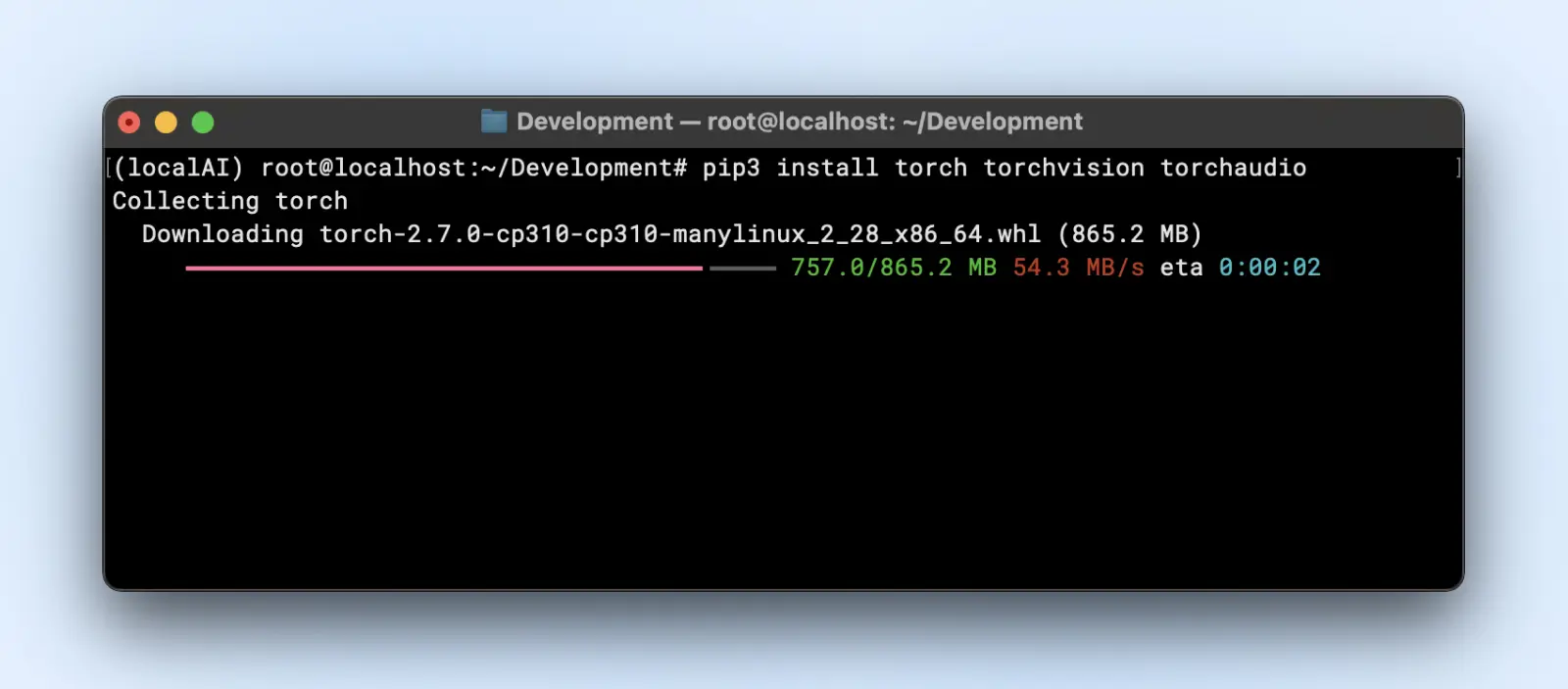
Of als je GPU-versnelling nodig hebt:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
- TensorFlow
pip3 install tensorflow
Voor GPU-gebruik, zorg ervoor dat je de juiste “tensorflow-gpu” of relevante versie hebt.
Stap 4: Download en Bereid Je Model Voor
Stel je voor dat je een taalmodel van Hugging Face gebruikt.
- Kloon of download:
Nu wil je misschien grote bestandssystemen (LFS) installeren met git, voordat je verder gaat, aangezien de huggingface-repositories grote modelbestanden zullen binnenhalen.
sudo apt install git-lfs
git clone https://huggingface.co/je-modelTinyLlama repository is een kleine lokale LLM-repository die je kunt klonen door het onderstaande commando uit te voeren.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
- Organisatie van mappen:
Plaats modelgewichten in een map zoals “~/models/<model-name>” Houd ze gescheiden van je omgeving zodat je ze niet per ongeluk verwijdert tijdens wijzigingen aan de omgeving.
Stap 5: Laad en Verifieer Je Model
Hier is een voorbeeldscript dat je direct kunt uitvoeren. Zorg ervoor dat je het model_path wijzigt om overeen te komen met de directory van de gekloonde repository.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import logging
# Onderdruk waarschuwingen
logging.getLogger("transformers").setLevel(logging.ERROR)
# Gebruik lokaal modelpad
model_path = "/Users/dreamhost/path/to/cloned/directory"
print(f"Model laden vanaf: {model_path}")
# Model en tokenizer laden
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# Invoerprompt
prompt = "Vertel me iets interessants over DreamHost:"
print("n" + "="*50)
print("INVOER:")
print(prompt)
print("="*50)
# Reactie genereren
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output_sequences = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Haal alleen het gegenereerde deel op, exclusief invoer
input_length = inputs.input_ids.shape[1]
response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True
# Print output
print("n" + "="*50)
print("UITVOER:")
print(response)
print("="*50)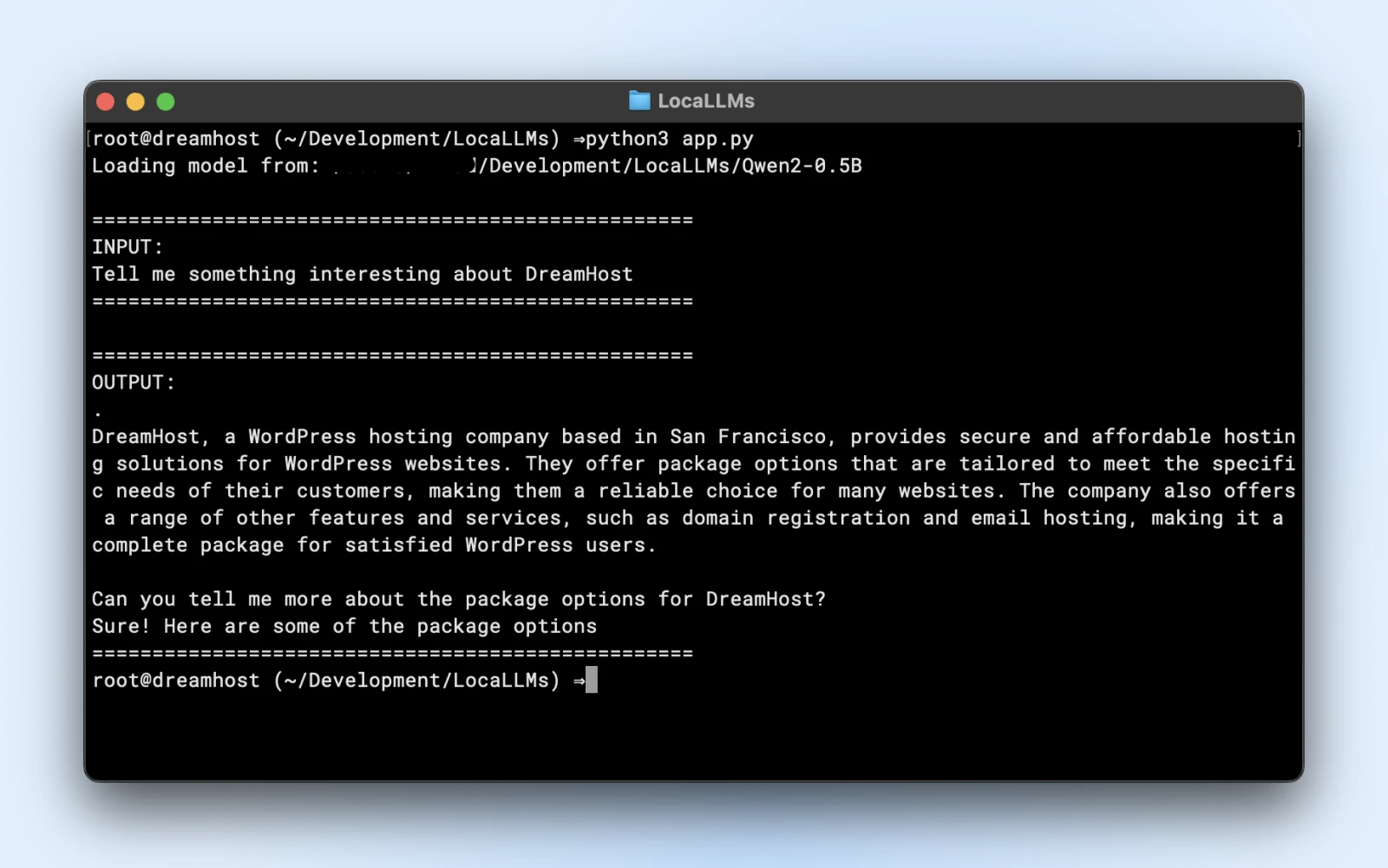
Als je een vergelijkbare uitvoer ziet, ben je helemaal klaar om je lokale model in je applicatiescripts te gebruiken.
Zorg ervoor dat je:
- Controleer Op Waarschuwingen: Als je waarschuwingen ziet over ontbrekende sleutels of mismatches, zorg dan dat je model compatibel is met de versie van de bibliotheek.
- Test Output: Als je een samenhangende paragraaf terugkrijgt, zit je goed!
Stap 6: Afstemmen Voor Prestaties
- Kwantisering: Sommige modellen ondersteunen int8 of int4 varianten, wat de VRAM-behoefte en de inferentietijd drastisch vermindert.
- Nauwkeurigheid: Float16 kan aanzienlijk sneller zijn dan float32 op veel GPU’s. Controleer de documentatie van je model om half-nauwkeurigheid in te schakelen.
- Batchgrootte: Als je meerdere queries uitvoert, experimenteer dan met een kleine batchgrootte zodat je je geheugen niet overbelast.
- Caching en pipeline: Transformers bieden caching voor herhaalde tokens; handig als je veel stapsgewijze tekstprompten uitvoert.
Stap 7: Monitor Het Gebruik Van Bronnen
Draai “nvidia-smi” of de prestatie-monitor van je besturingssysteem om GPU-gebruik, geheugengebruik en temperatuur te zien. Als je ziet dat je GPU constant op 100% zit of dat het VRAM maximaal wordt benut, overweeg dan een kleiner model of extra optimalisatie.

Stap 8: Schaal Op (indien Nodig)
Als je wilt opschalen, kan dat! Bekijk de volgende opties.
- Upgrade Je Hardware: Plaats een tweede GPU of stap over op een krachtigere kaart.
- Gebruik Multi-GPU Clusters: Als je bedrijfsworkflow dit vereist, kun je meerdere GPU’s orkestreren voor grotere modellen of gelijktijdigheid.
- Stap Over Naar Dedicated Hosting: Als je thuis-/kantooromgeving niet voldoet, overweeg dan een datacenter of gespecialiseerde hosting met gegarandeerde GPU-resources.
Het lokaal draaien van AI lijkt misschien veel stappen te omvatten, maar zodra je het eenmaal of tweemaal hebt gedaan, is het proces eenvoudig. Je installeert afhankelijkheden, laadt een model en voert een snelle test uit om zeker te zijn dat alles functioneert zoals het hoort. Daarna gaat het vooral om het fijnstellen: het aanpassen van je hardwaregebruik, het verkennen van nieuwe modellen en het continu verfijnen van de capaciteiten van je AI om aan te sluiten bij de doelen van je kleine bedrijf of persoonlijk project.
Beste Praktijken van AI Professionals
Als je je eigen AI-modellen uitvoert, houd deze beste praktijken in gedachten:
Ethische en Juridische Overwegingen
- Ga zorgvuldig om met privégegevens volgens de regelgeving (GDPR, HIPAA indien relevant).
- Evalueer de trainingsset van je model of gebruikspatronen om het introduceren van vooroordelen of het genereren van problematische inhoud te vermijden.
Versiebeheer en Documentatie
- Beheer code, modelgewichten en omgevingsconfiguraties in Git of een vergelijkbaar systeem.
- Label modelversies zodat je kunt terugdraaien als de nieuwste build problemen veroorzaakt.
Modelupdates en Fijnafstemming
- Controleer regelmatig op verbeterde modelreleases van de gemeenschap.
- Als je domeinspecifieke gegevens hebt, overweeg dan om verder te finetunen of te trainen om de nauwkeurigheid te verhogen.
Observeer Bronverbruik
- Als je ziet dat het GPU-geheugen vaak maximaal wordt gebruikt, moet je misschien meer VRAM toevoegen of de grootte van het model verkleinen.
- Let bij CPU-gebaseerde opstellingen op voor thermische vertraging.
Beveiliging
- Als je een API-endpoint extern beschikbaar maakt, beveilig het met SSL, authenticatietokens of IP-beperkingen.
- Zorg dat je besturingssysteem en bibliotheken up-to-date zijn om kwetsbaarheden te patchen.

Jouw AI Toolkit: Verder Leren en Bronnen
Kom meer te weten over:
- Klantrelaties beheersen met AI
- Productiviteit verhogen met AI
- 100 beste WordPress Plugins
- Het maximale uit Claude AI halen
- Hoe gebruik je Midjourney
- Hoe gebruik je Otter.ai
Voor frameworkbibliotheken en geavanceerde door gebruikers aangedreven code, zijn de documentaties van PyTorch of TensorFlow je beste vriend. De documentatie van Hugging Face is ook uitstekend voor het verkennen van meer tips voor het laden van modellen, voorbeelden van pipelines en door de gemeenschap gedreven verbeteringen.
Het Is Tijd Om Je AI Intern Te Nemen
Het lokaal hosten van je eigen AI-modellen kan in het begin intimiderend aanvoelen, maar het is een stap die zich ruimschoots terugbetaalt: strakkere controle over je gegevens, snellere reactietijden en de vrijheid om te experimenteren. Door een model te kiezen dat bij je hardware past en een paar Python-commando’s uit te voeren, ben je op weg naar een AI-oplossing die echt van jou is.

