
Les systèmes de gestion de bases de données relationnelles (RDBMS) comme PostgreSQL et MySQL sont essentiels pour stocker, organiser et accéder aux données pour les applications et les analyses. PostgreSQL et MySQL sont des bases de données open-source populaires avec de longues histoires et des ensembles de fonctionnalités riches.
Base de Données
Une base de données est une collection d’informations accessibles aux ordinateurs. Les bases de données sont utilisées pour stocker des informations telles que les dossiers clients, les catalogues de produits et les transactions financières.
En savoir plusCependant, PostgreSQL et MySQL diffèrent dans leur architecture technique et leur philosophie de conception. Si tu hésites entre choisir une base de données pour ton application, ce guide est pour toi.
Nous examinons les différences techniques, pratiques et stratégiques entre PostgreSQL et MySQL. Commençons.
Un Bref Aperçu Sur PostgreSQL Et MySQL
Avant de plonger dans les comparaisons, présentons brièvement PostgreSQL et MySQL.
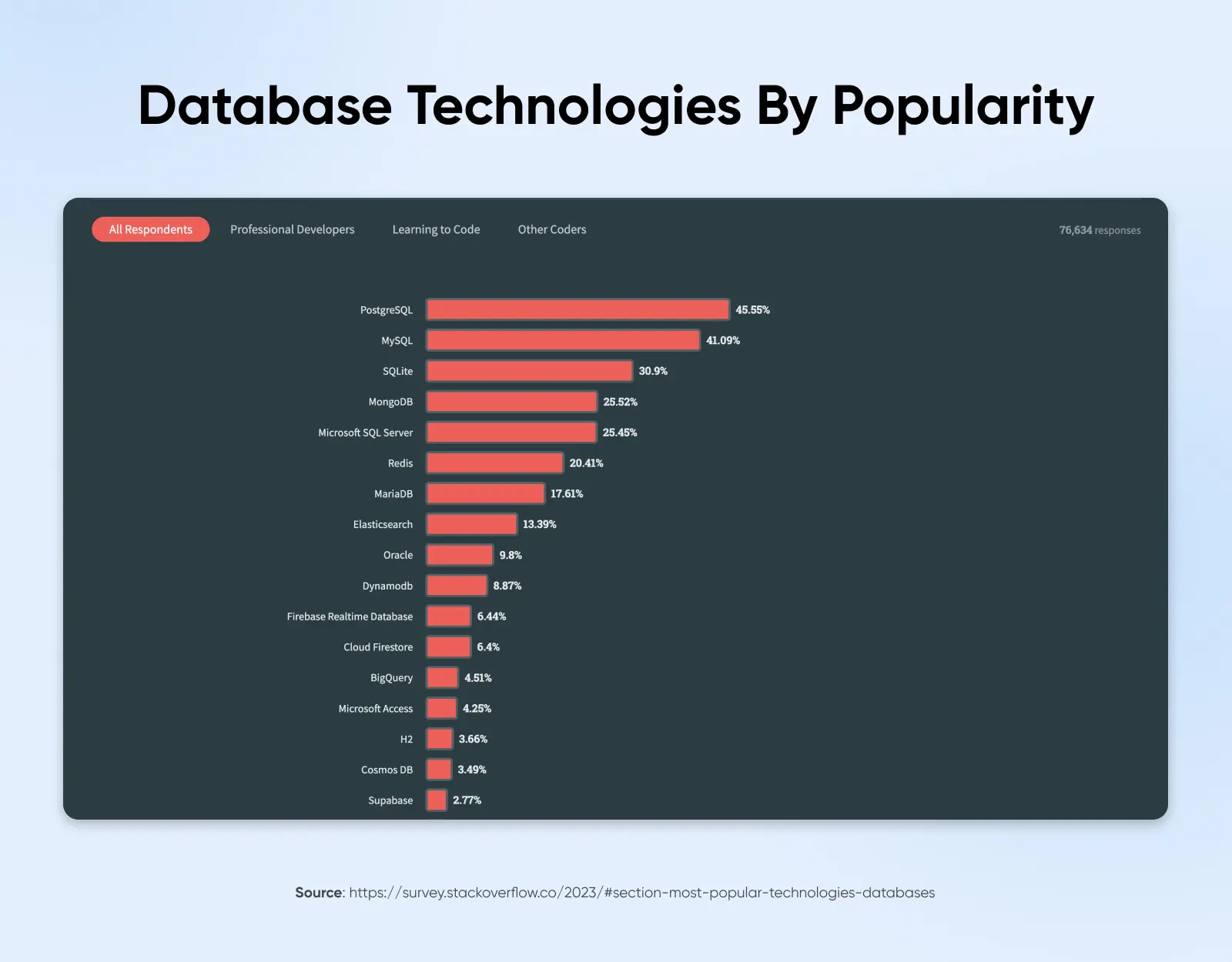
PostgreSQL est une base de données relationnelle open-source de niveau entreprise. Utilisée par plus de 45% des 76 000 répondants dans l’enquête récente des développeurs de StackOverflow, PostgreSQL a dépassé MySQL pour devenir la base de données la plus populaire en 2024.
PostgreSQL met l’accent sur la conformité aux normes, l’extensibilité et des architectures éprouvées. Le projet PostgreSQL a commencé en 1986 à l’Université de Californie à Berkeley, et a développé des fonctionnalités axées sur la fiabilité, la robustesse, l’intégrité des données et la correction.
Postgres utilise un système à cinq niveaux :
- Instance (aussi appelée cluster)
- Base de données
- Schéma
- Table
- Colonne
Voici un exemple de création d’une table utilisateurs simple dans PostgreSQL et d’insertion de quelques lignes :
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
INSERT INTO users (name, email) VALUES
('John Doe', 'john@email.com'),
('Jane Smith', 'jane@email.com');
MySQL est un SGBDR open-source lancé par la société suédoise MySQL AB en 1995, qui a été par la suite acquis par Oracle. Il a traditionnellement privilégié la vitesse, la simplicité et la facilité d’utilisation pour le développement d’applications web et embarquées. La conception de MySQL met l’accent sur des performances rapides en lecture et écriture.
MySQL utilise un système à quatre niveaux :
- Instance
- Base de données
- Table
- Colonne
Voici comment tu peux créer la table des utilisateurs dans MySQL :
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
INSERT INTO users (name, email) VALUES
('John Doe', 'john@email.com'),
('Jane Smith', 'jane@email.com');
Comme tu peux le remarquer, les deux requêtes sont similaires sauf pour le changement de INT AUTO_INCREMENT en SERIAL.
Anecdote amusante : PostgreSQL prend en charge le mot-clé « allballs » de la NASA (signifiant « tous les zéros ») comme une autre manière d’exprimer l’heure à minuit (heure locale et UTC) :
postgres=# SELECT 'allballs'::TIME;
time
----------
00:00:00
(1 row)
Alors, comment ces deux titans de base de données open-source se comparent-ils ? Explorons plus loin.
PostgreSQL Contre MySQL : Comparaison Des Performances
Aussi bien PostgreSQL que MySQL peuvent offrir d’excellentes performances, mais il n’y a pas de vainqueur clair entre eux.
Si tu testes la vitesse de lecture/écriture, tu remarqueras qu’il n’y a pas de cohérence dans la manière dont PostgreSQL et MySQL se comportent. Cela est dû au fait que la performance de la base de données dépend fortement du type de charge de travail spécifique, de la configuration matérielle, du schéma de la base de données et des index, et surtout du réglage de la configuration de la base de données. En gros, la performance dépend grandement de la charge de travail et des configurations de ton application.
Il existe cinq catégories générales de charges de travail :
- CRUD : Simples opérations de LIRE, ÉCRIRE, METTRE À JOUR et SUPPRIMER.
- OLTP : Opérations transactionnelles et complexes de traitement des données.
- OLAP : Processus par lots analytiques.
- HTAP : Traitement hybride transactionnel et analytique.
- Time-Series : Données en séries temporelles avec des modèles d’accès très simples, mais à haute fréquence.
Lorsque tu travailles avec l’un de ces flux de travail, tu remarqueras que :

PostgreSQL est reconnu pour gérer les charges de travail OLAP et OLTP assez efficacement. Ces charges de travail impliquent des requêtes extrêmement complexes et de longue durée qui analysent des ensembles de données massifs — par exemple, des requêtes d’intelligence commerciale ou des analyses géospatiales.
« Postgres me permet de voir une estimation du plan “avant l’exécution de la requête” ainsi qu’un plan “après exécution”. Ce dernier me donne des informations détaillées sur la manière dont la requête a réellement été exécutée, combien de temps chaque étape spécifique de la requête a pris, les index utilisés, et combien de mémoire chaque étape a consommée. »
MySQL est généralement bon pour les charges de travail CRUD et OLTP plus simples impliquant des lectures et des écritures plus rapides, comme les applications web ou mobiles.
Les deux bases de données peuvent exceller selon la configuration du serveur et votre schéma pour les charges de travail hybrides avec un mélange de besoins en requêtes OLTP et OLAP.
Requête
Dans les bases de données, les requêtes sont des demandes pour des ensembles spécifiques d’informations. Les requêtes peuvent également être des questions ouvertes pour des données qui correspondent à tes paramètres définis.
Lire la suiteLorsqu’il s’agit de puissance brute sur du matériel optimisé, PostgreSQL évolue généralement mieux pour utiliser la mémoire élevée, les processeurs plus rapides et les cœurs supplémentaires disponibles sur le matériel.
Performance de Lecture
MySQL a généralement des temps de lecture plus rapides pour les applications que les opérations d’écriture. Cependant, après les mises à jour récentes de PostgreSQL, il a rattrapé les différences de vitesse de lecture.
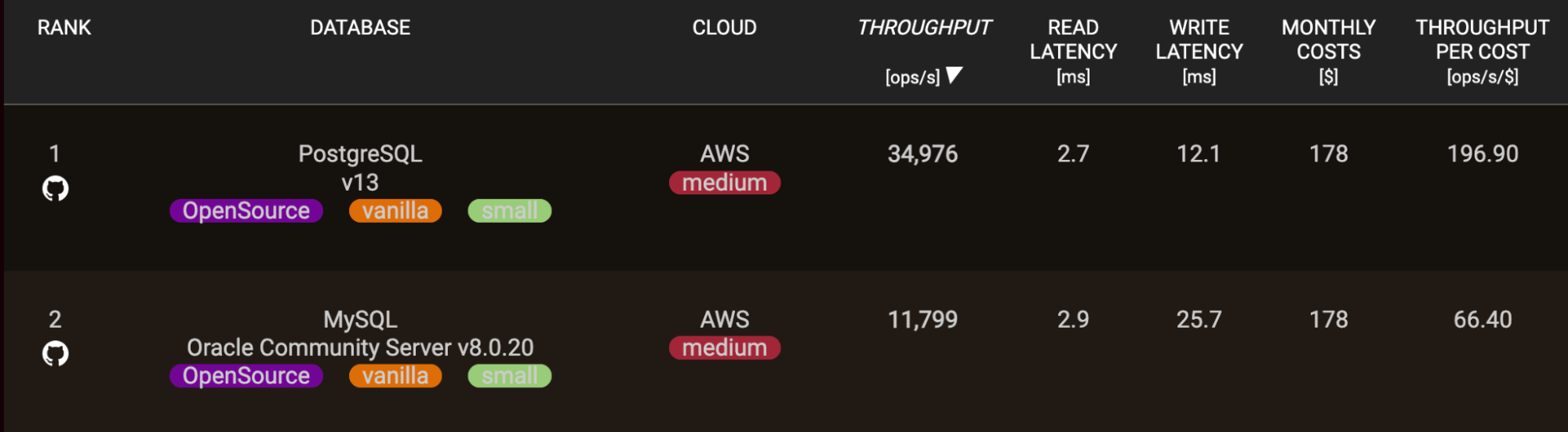
Cet avantage de performance en lecture découle des différences dans la façon dont les deux systèmes sont architecturés — les moteurs de stockage de MySQL sont hautement optimisés pour un accès séquentiel rapide mono-thread.
Bien sûr, avec un réglage personnalisé et des schémas, PostgreSQL peut également offrir d’excellentes performances de lecture pour de nombreuses applications. Mais dès le départ, MySQL a souvent un avantage.
Performances D’écriture
Quand il s’agit de performance d’écriture, y compris les chargements en masse et les requêtes complexes qui modifient les données, le consensus général est que PostgreSQL fonctionne mieux.
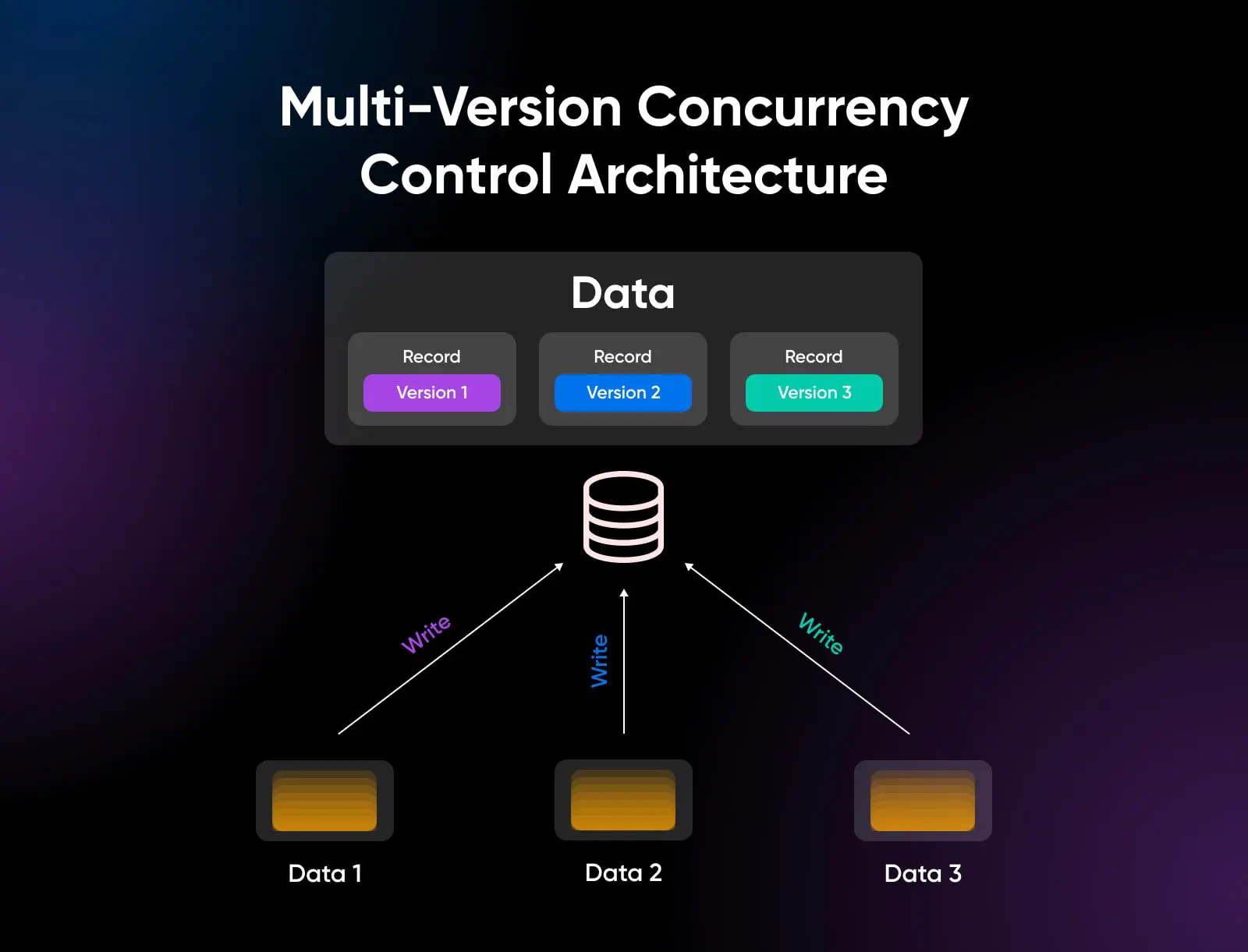
Son architecture de contrôle de concurrence multi-version (MVCC) confère à PostgreSQL un avantage majeur en permettant à plusieurs sessions de mettre à jour les données avec un verrouillage minimal simultanément.
Si ton application doit supporter de nombreux utilisateurs concurrents modifiant des données, le débit d’écriture de PostgreSQL peut dépasser ce que MySQL peut réaliser.
Performance des Requêtes Complexes
Pour les requêtes analytiques avancées qui effectuent de grands balayages de tables, des tris, ou des fonctions analytiques, PostgreSQL surpasse également MySQL dans de nombreux cas — et ce, avec une marge significative.
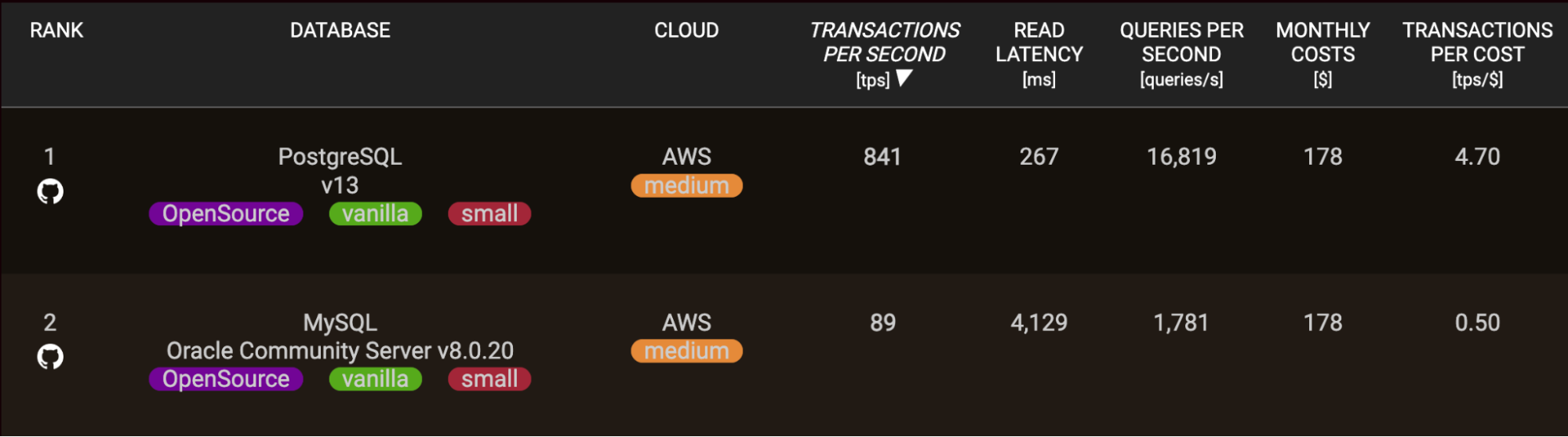
L’optimiseur de requêtes SQL mature de PostgreSQL et le support pour une syntaxe SQL avancée lui confèrent un avantage dans l’exécution rapide de requêtes analytiques complexes. MySQL s’est considérablement amélioré récemment mais dépend davantage du réglage manuel des requêtes.
Alors, pour les besoins en intelligence d’affaires ou en entreposage de données où la performance SQL complexe multi-tables est importante, PostgreSQL excelle souvent.
La Configuration Impacte La Performance
Bien sûr, les bases de données peuvent être configurées et optimisées pour s’adapter à différents types de charges de travail. Ainsi, pour tout cas d’utilisation, le système “meilleur” dépend encore considérablement du matériel serveur sous-jacent, du système d’exploitation, du sous-système de stockage, de la configuration de la base de données et de la conception du schéma.
BenchANT fait un excellent travail pour montrer comment différents serveurs peuvent impacter la performance d’une base de données.
De plus, la configuration matérielle a également un impact significatif sur les performances de ta base de données. Par exemple, si tu utilises un VPS avec un stockage NVMe, le stockage sous-jacent est beaucoup plus rapide qu’un disque dur classique, donc tes opérations de base de données seront extrêmement rapides.
Cependant, il n’y a pas de système universellement le plus rapide – tes résultats varieront selon ton environnement et ton ajustement.
« La gestion des connexions est le meilleur argument pour MySQL. Néanmoins, il n’y a réellement aucune raison de ne pas utiliser PostgreSQL dans n’importe quel cas d’usage relationnel. Cela est particulièrement vrai si l’on considère les développements des trois dernières années. PostgreSQL est des années en avance sur n’importe quel concurrent en matière de bases de données relationnelles et même au-delà. La communauté assidue, le code source incroyablement organisé, et une documentation presque divine sont seulement trois des arguments gagnants. »
Quand Envisager MySQL
MySQL dépasse souvent PostgreSQL, utilisant moins de ressources système pour les schémas simples et les applications dominées par l’accès rapide en lecture de clés-valeurs. Les applications web et mobiles ayant des besoins plus importants en termes d’évolutivité, de disponibilité et de lectures distribuées peuvent bénéficier des points forts de MySQL.
Quand Envisager PostgreSQL
Les avantages architecturaux de PostgreSQL le rendent digne d’intérêt pour les charges de travail nécessitant des modèles d’accès en écriture complexes, des requêtes analytiques commerciales ou une flexibilité dans les types de données. Si tu as des administrateurs de bases de données disponibles pour la configuration et l’optimisation des requêtes, PostgreSQL offre une base compétente.
PostgreSQL Contre MySQL: Comparaison Des Fonctionnalités
Les deux bases de données sont complètes, mais présentent des différences considérables en termes de types de données pris en charge, de fonctions et d’ensembles de fonctionnalités globales.
Support de Type de Données
| Fonctionnalité | PostgreSQL | MySQL |
| Types de données | Support intégré robuste pour JSON, XML, tableaux, géospatial, réseau, etc. | Il repose davantage sur les extensions JSON |
| Langages fonctionnels | SQL, C, Python, JavaScript | Principalement SQL |
| Support GIS | Excellent via l’extension spatiale PostGIS | Limité, nécessite souvent des modules complémentaires |
PostgreSQL prend en charge un ensemble plus large de types de données natifs, offrant plus de flexibilité dans vos schémas de base de données :
- Types géométriques pour les systèmes GIS
- Types d’adresses réseau comme IPV4/IPV6
- JSON natif et JSONB – JSON binaire optimisé
- Documents XML
- Types de tableaux
- Colonnes de types de données multiples
« Postgres gère bien les tableaux. Ainsi, tu peux stocker des types de tableaux tels que des tableaux d’entiers ou des tableaux de varchars dans ta table. Il existe également diverses fonctions et opérateurs de tableaux pour lire les tableaux, les manipuler, etc. »
— Utilisateur Reddit, mwdb
MySQL dispose de types de données plus basiques – principalement numériques, de date/heure et de chaînes de caractères, mais peut atteindre une flexibilité similaire via des colonnes JSON ou des extensions spatiales.
Langages Fonctionnels
PostgreSQL permet de rédiger des fonctions et des procédures stockées dans divers langages — SQL, C, Python, JavaScript, et plus encore — pour une plus grande flexibilité.
En revanche, les routines stockées MySQL doivent être codées en SQL, tandis que tu peux toujours écrire la logique de l’application dans divers langages de programmation généraux.
Donc, si tu as besoin d’incorporer une logique d’application ou des calculs complexes directement dans des procédures de base de données, PostgreSQL offre beaucoup plus de flexibilité.
Support GIS
Pour les ensembles de données spatiales utilisés dans les applications de cartographie/géographiques, PostgreSQL offre une excellente fonctionnalité intégrée grâce à son extension PostGIS. Les requêtes de localisation, points à l’intérieur des polygones et les calculs de proximité fonctionnent tous directement.
Le support spatial de MySQL est plus limité à moins que tu adoptes un moteur spatial tiers comme MySQL Spatial ou Integration MySOL. Pour les systèmes GIS, PostgreSQL avec PostGIS est généralement une solution plus simple et plus capable.
Réplication
Les deux bases de données proposent une réplication, permettant la synchronisation des modifications de la base de données sur l’instance. Par défaut, la réplication PostgreSQL repose sur les fichiers WAL (Write Ahead Log), ce qui permet d’agrandir les sites web pour intégrer autant de serveurs de bases de données que tu le souhaites.
Donc, PostgreSQL facilite la mise à l’échelle des répliques de lecture finement synchronisées avec des portions de données spécifiques qui changent. Pour MySQL, des outils tiers peuvent être nécessaires.
Architecture Et Scalabilité
PostgreSQL et MySQL diffèrent considérablement dans leurs architectures globales, ce qui impacte leurs profils de scalabilité et de performance.
Le Modèle Objet-Relationnel de PostgreSQL
Une caractéristique architecturale clé de PostgreSQL est son adhésion au modèle relationnel-objet, ce qui signifie que les données peuvent adopter des caractéristiques similaires à des objets dans la programmation orientée objet. Par exemple :
- Les tables peuvent hériter des propriétés d’autres tables.
- Les types de données peuvent avoir des comportements spécialisés.
- Les fonctions sont des caractéristiques des types de données.
Cette structure objet-relationnelle permet de modéliser des données réelles complexes plus proches des objets et des entités de l’application. Cependant, cela a un coût — des systèmes internes plus élaborés sont nécessaires pour suivre des relations de données plus riches.
Les extensions objet-relationnelles offrent ainsi une excellente flexibilité, entraînant un surcoût de performance par rapport à un système strictement relationnel.
Le Modèle Relationnel Pur de MySQL
En revanche, MySQL suit un modèle purement relationnel centré autour d’un schéma de table de données simple et de relations via des clés étrangères. Ce modèle plus simple se traduit par de bonnes performances pour les charges de travail transactionnelles pilotées par des sites web.
L’utilisation avancée de MySQL avec des opérations JOIN étendues ou une logique commerciale localisée est mieux gérée via le code d’application plutôt que par des personnalisations de base de données. MySQL privilégie la simplicité à la flexibilité dans son architecture de base.
Contrairement à PostgreSQL, MySQL est une base de données purement relationnelle sans fonctionnalités orientées objet. Chaque base de données est constituée de tables individuelles sans héritage ni types personnalisés. JSON a récemment apporté une certaine flexibilité de base de données documentaire.
Cependant, en évitant les fonctionnalités d’objet, MySQL atteint une performance supérieure dès le départ dans de nombreux travaux, mais il manque les capacités de modélisation plus profondes de PostgreSQL.
Donc, MySQL est plus rapide pour les données simples, tandis que PostgreSQL s’adapte mieux à la complexité. Choisis en fonction de tes besoins d’accès aux données et de mise à l’échelle.
Écriture Mise À L’échelle Avec Contrôle De Concomitance Multiversion (MVCC)
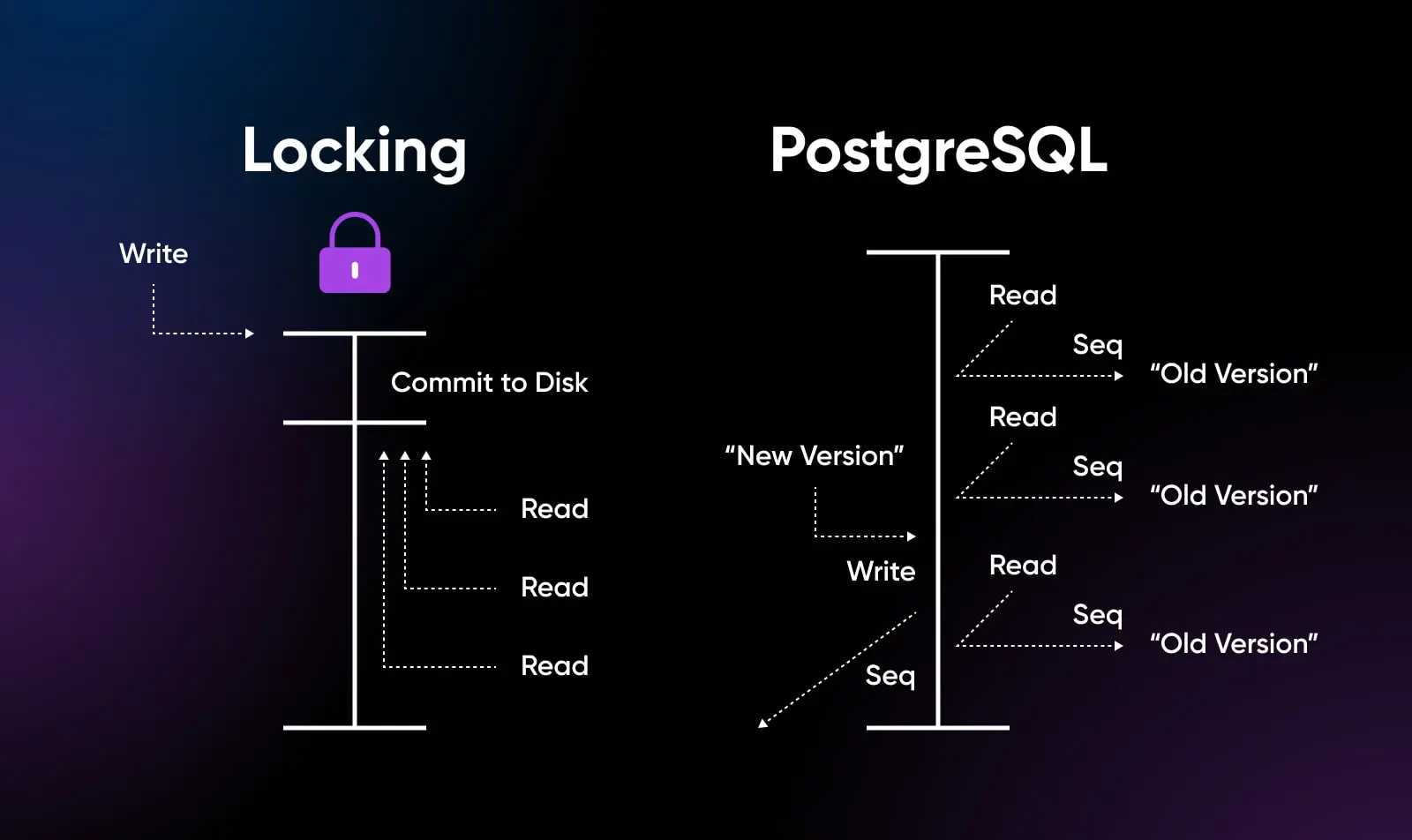
Un domaine où PostgreSQL excelle particulièrement est l’extension horizontale en écriture, permettant à de nombreuses sessions concurrentes de modifier des données sur des serveurs distribués en utilisant le modèle MVCC.
Ce modèle MVCC signifie une excellente concurrence même pour les charges de travail en lecture-écriture mixtes, permettant aux bases de données PostgreSQL de gérer un très grand débit grâce à la réplication. Les écritures se déroulent en parallèle, puis se synchronisent ensuite.
MySQL InnoDB obtient une concurrence similaire en utilisant le verrouillage au niveau des lignes plutôt que MVCC. mais l’architecture de PostgreSQL s’est avérée plus évolutive sous de fortes charges d’écriture lors des tests.
Essentiellement, PostgreSQL prend finalement en charge une plus grande échelle d’écriture, bien qu’avec plus de surcharge serveur. MySQL est plus léger pour l’échelle de lecture.
PostgreSQL Vs. MySQL : Fiabilité Et Protection Des Données
PostgreSQL et MySQL offrent des protections de sécurité robustes et des mécanismes de fiabilité – bien que PostgreSQL mette l’accent sur la durabilité tandis que MySQL se concentre sur la haute disponibilité.
Contrôle D’accès Et Chiffrement
PostgreSQL et MySQL offrent également des contrôles de compte utilisateur, une administration des privilèges et des capacités de chiffrement réseau pour la sécurité. Des éléments critiques tels que les connexions SSL, les politiques de mot de passe et la sécurité des lignes basée sur les rôles s’appliquent de manière similaire.
Cependant, il existe quelques différences concernant le cryptage :
- Chiffrement natif des données au repos : PostgreSQL 13 a ajouté le module pgcrypto pour le chiffrement transparent des tablespaces au niveau du système de fichiers. MySQL ne dispose pas de chiffrement natif mais supporte les plugins.
- Politiques d’accès aux lignes légères : PostgreSQL dispose de RLS et MASK pour les rôles afin de gérer la visibilité des lignes jusqu’aux domaines de données à travers des politiques. MySQL peut utiliser des vues pour obtenir un résultat similaire, mais ce n’est pas aussi robuste.
Alors que les systèmes RDBMS protègent les données sensibles via un chiffrement SSL/TLS pour les connexions clients, PostgreSQL offre légèrement plus d’algorithmes de chiffrement, de surveillance des activités et d’options de contrôle d’accès intégrées que MySQL.
Fiabilité de PostgreSQL via le WAL
PostgreSQL utilise la journalisation anticipée (WAL), où les modifications des données sont enregistrées dans le journal avant que les modifications réelles des données ne se produisent.
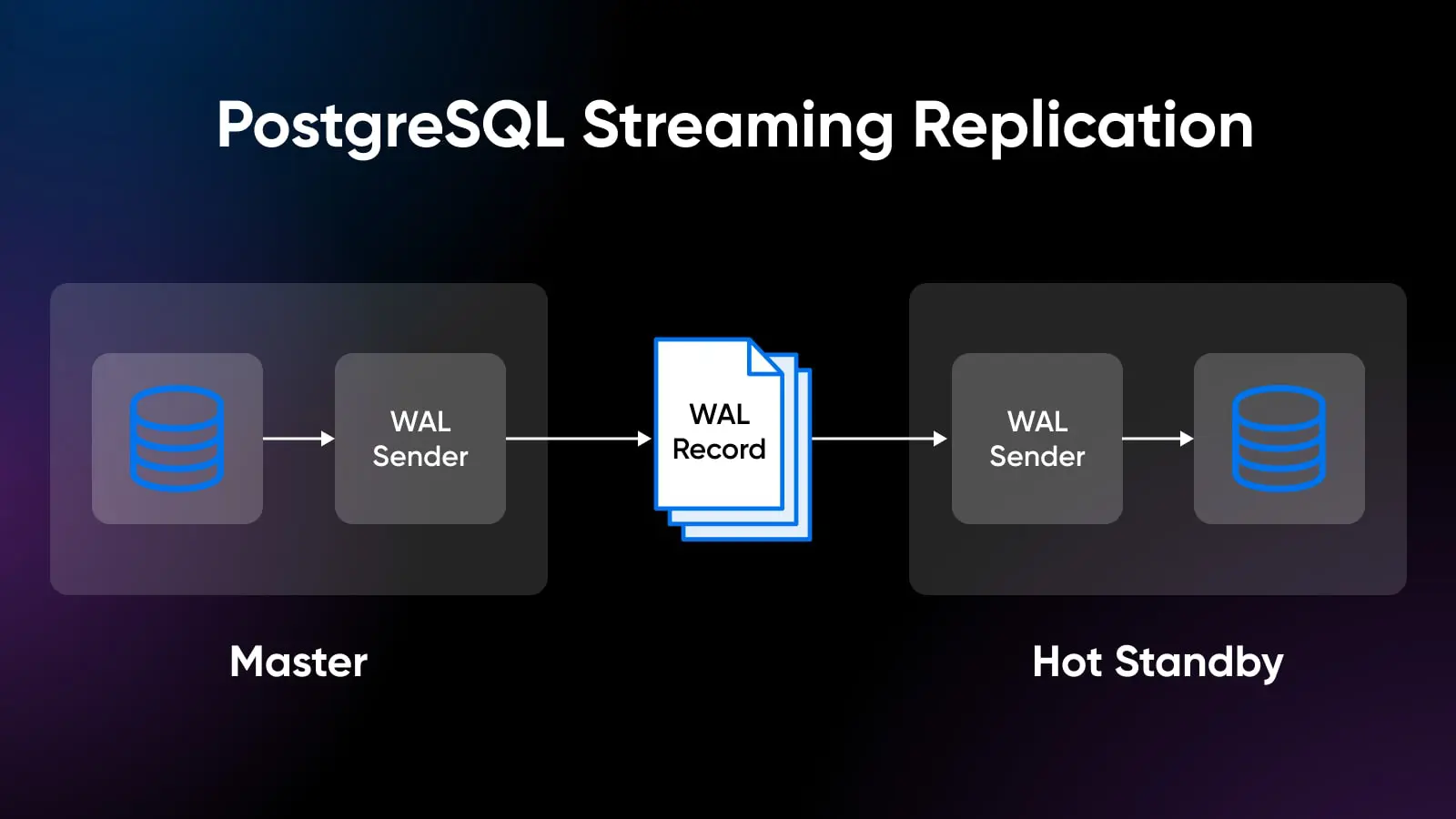
Cela protège contre la perte de données, même en cas de crashs ou de pannes de courant, prévenant la corruption de la base de données.
Les journaux WAL dans PostgreSQL maintiennent une chaîne cohérente de modifications mises en file d’attente à travers les transactions qui peuvent rapidement rejouer et récupérer les données.
Ce mécanisme alimente des fonctionnalités telles que la réplication en streaming, les requêtes parallèles et la récupération à un instant donné (PITR) à des états antérieurs dans le temps sans nécessiter de sauvegardes complètes.
Globalement, le WAL aide à maintenir les garanties de durabilité des données et améliore les performances pour la récupération après crash et la réplication.
Disponibilité Élevée MySQL
Pour minimiser le temps d’arrêt, MySQL offre un clustering haute disponibilité robuste qui bascule automatiquement en cas de panne d’un seul serveur – avec une interruption minimale. La promotion automatique des répliques et la resynchronisation rapide rendent les pannes un scénario rare.
Alors que MySQL 5.7 n’incluait pas de haute disponibilité intégrée, MySQL 8 a introduit le cluster InnoDB pour le basculement automatique entre les nœuds.
PostgreSQL atteint également une haute disponibilité grâce à des outils de réplication comme Slony, Londiste, ou pgpool-II, qui offrent une bascule sur incident basée sur des déclencheurs ou un intergiciel. Cependant, PostgreSQL manque de l’intégration native de clustering de MySQL, même si tu peux atteindre une haute disponibilité.
Donc, si ton application exige une disponibilité du serveur de 100% sans intervention manuelle, les capacités de clustering natives de MySQL peuvent mieux servir. C’est aussi l’une des raisons pour lesquelles WordPress, un système de gestion de contenu qui alimente 43% de l’internet, continue d’utiliser MySQL.
Support Communautaire Et Bibliothèques
Étant donné les longues histoires et les grandes bases d’utilisateurs des deux bases de données, PostgreSQL et MySQL offrent des forums utiles, des bibliothèques de documentation et des outils tiers. Cependant, certaines différences se démarquent.
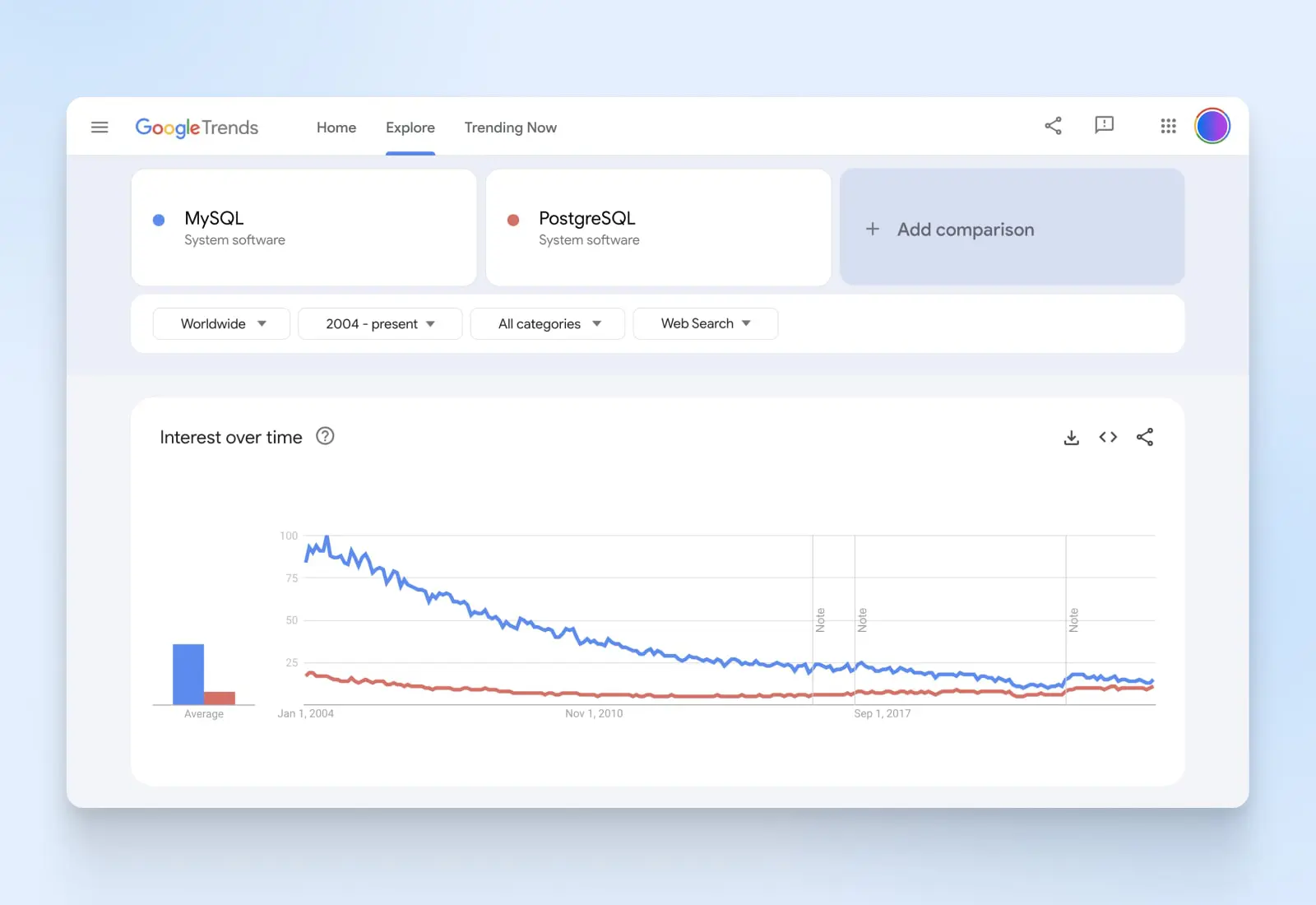
Selon Google Trends, l’intérêt pour MySQL a considérablement diminué, se rapprochant de PostgreSQL. Cependant, les deux bases de données conservent encore un solide suivi et une base d’utilisateurs, leur assurant un bon soutien communautaire.
Communauté PostgreSQL
Le développement de PostgreSQL est géré par le Groupe de développement mondial de PostgreSQL – une équipe de développeurs de la communauté ouverte collaborant à l’échelle mondiale. Des milliers d’utilisateurs et de contributeurs participent aux listes de courriels, aux canaux IRC, aux blogs et aux événements.
Ils organisent également des conférences telles que PGConf, réunissant périodiquement la communauté Postgres. Dans l’ensemble, un écosystème de support robuste et compétent permet à PostgreSQL de progresser.
Communauté MySQL
En tant que base de données open-source extrêmement populaire, MySQL bénéficie également du soutien de la communauté en ligne. La Zone Développeur MySQL offre une documentation riche et des forums pour le dépannage et les étapes suivantes. De grandes conférences telles que Percona Live discutent des meilleures pratiques récentes utilisant MySQL.
L’acquisition de MySQL par Oracle lui a également permis d’obtenir les investissements nécessaires pour de nouvelles versions et des offres de support commercial pour ceux qui ont besoin d’une aide supplémentaire. Bien que pas aussi communautaire que PostgreSQL, les utilisateurs de MySQL disposent de grandes ressources communautaires.
Comparaison de la Profondeur du Support
Les deux bases de données bénéficient également d’excellents réseaux de support communautaire. PostgreSQL fournit des conseils techniques plus avancés et une excellente documentation, compte tenu de la complexité inhérente de la base de données. Leur documentation est également un peu impertinente, contrairement à la plupart des autres documents techniques. Voici un extrait :
« Le premier siècle commence le 0001-01-01 à 00:00:00 AD, bien qu’ils ne le savaient pas à l’époque. Cette définition s’applique à tous les pays utilisant le calendrier grégorien. Il n’y a pas de numéro de siècle 0, on passe du siècle -1 au siècle 1. Si vous n’êtes pas d’accord avec cela, veuillez écrire votre plainte à : Pape, Cathédrale Saint-Pierre de Rome, Vatican. »
— Documentation PostgreSQL sur EXTRACT, date_part
La communauté de MySQL offre une expérience plus large, perfectionnant les cas d’utilisation pour débutants tels que les applications web.
Mais pour n’importe quelle base de données, attends-toi à des communautés d’utilisateurs engagés et attentionnés prêts à aider à guider l’utilisation et la croissance.
Cas D’utilisation Typiques
Étant donné les différences mises en évidence jusqu’à présent, PostgreSQL et MySQL tendent vers des cas d’utilisation distincts. Cependant, les deux systèmes RDBMS fonctionnent souvent parfaitement bien pour les applications web qui lisent et écrivent des lignes de données.
Cas d’utilisation de PostgreSQL
PostgreSQL excelle dans des charges de travail analytiques très lourdes en données telles que :
- Intelligence commerciale avec des requêtes agrégées complexes exécutées sur des millions de lignes.
- Entrepôt de données et rapports sur de nombreuses jointures de tables et conditions.
- Science des données et apprentissage automatique nécessitent les tableaux de PostgreSQL, hstore, JSON, et des types de données personnalisés.
- Analyse géospatiale et multidimensionnelle via PostGIS et traitement spécialisé. Les exemples incluent les données de localisation en temps réel, les images satellitaires, les données climatiques et la manipulation de géométries.
Ces éléments tirent parti de la flexibilité de PostgreSQL.
Des cas d’utilisation verticaux spécifiques abondent dans les secteurs juridique, médical, de recherche, d’assurance, gouvernemental et financier se dirigeant vers l’analyse de grandes données.
Des exemples concrets incluent Reddit, Apple, Instagram, le système de recherche en génétique de l’hôpital Johns Hopkins, les analyses publicitaires du New York Times, le suivi des clients du rail Amtrak, le système de planification des employés de Gap, les enregistrements de détails d’appels de Skype, etc.
Cas d’utilisation de MySQL
MySQL se concentre sur la pure vitesse, la simplicité de développement et l’évolutivité facile inhérente aux applications web et mobiles. Ses points forts particuliers ressortent pour :
- Traitement des transactions en ligne haute performance (OLTP) pour les sites e-commerce et les applications web nécessitant un débit extrême en lecture et écriture touchant de nombreuses tables distinctes par ligne. Pense à des sites matures à l’échelle d’Airbnb, Twitter, Facebook et Uber.
- Jeux en ligne massivement multijoueurs (MMO) avec une énorme base de joueurs à supporter simultanément en temps quasi réel.
- Applications mobiles et l’Internet des Objets (IoT) nécessitent des bases de données compactes à intégrer localement ou à embarquer dans des dispositifs de bord avec synchronisation occasionnelle vers des centres de données.
- Logiciel en tant que service (SaaS) plateformes multi-locataires échelonnant rapidement les bases de données à la demande tout en gardant les données séparées.
Ces applications privilégient la disponibilité et la vitesse de lecture/écriture à l’échelle du web plutôt que les capacités d’analyse approfondie ou les outils de science des données. En 2016, Uber a également repassé de PostgreSQL à MySQL, ce qui a fait de cette transition un sujet de conversation dans la communauté technologique pendant un moment.
De nombreuses grandes entreprises utilisent MySQL, y compris WordPress, Wikipedia, Facebook, Google AdWords, Zendesk, Mint, Uber, Square, Pinterest, Github, la navigation de films Netflix, les métadonnées de vidéos YouTube, etc.
Migration De MySQL Vers PostgreSQL Ou Inversement
Étant donné la popularité des deux bases de données, de nombreux développeurs peuvent migrer entre MySQL et PostgreSQL. À quoi doivent-ils s’attendre pendant ce processus de migration de base de données ?
En général, la migration de bases de données relationnelles pleinement fonctionnelles entre MySQL et PostgreSQL se déroule assez bien dans la plupart des cas, grâce aux excellents outils de migration disponibles. Il y a beaucoup plus de chevauchements que de différences dans la syntaxe et les fonctions SQL. Les types de données se traduisent généralement bien, bien que faire des conversions d’essai soit utile.
Explorons quelques défis clés à relever :
Gestion Des Changements De Type De Données
Lors de la migration de schémas de MySQL vers PostgreSQL ou vice versa, prête une attention particulière aux incompatibilités de types de données :
- Les colonnes AUTO_INCREMENT de MySQL deviennent SERIAL dans PostgreSQL.
- Les tableaux PostgreSQL nécessitent des changements de syntaxe supplémentaires car il n’existe pas de type de données similaire dans MySQL.
- Vérifie les conversions de données date/heure.
Teste les migrations sur des copies des données de production pour valider la fidélité. Les incompatibilités de types de données peuvent facilement casser les applications si elles ne sont pas résolues.
Migration de procédure stockée
Si tu relies fortement sur des procédures stockées pour la logique métier, les migrer entre MySQL et PostgreSQL nécessite de réécrire le code.
Les différences clés dans leurs langages procéduraux, comme la syntaxe des délimiteurs, brisent souvent la portabilité du code. Confirme également que les permissions restent intactes pour les procédures de production.
Valide donc ta migration minutieusement et ne présume pas que les fonctions se transfèrent proprement entre les plateformes.
Compatibilité Client
Les applications dépendant des bibliothèques clientes PostgreSQL et MySQL nécessitent également une reconfiguration lors du changement d’environnements :
- Mettre à jour les chaînes de connexion.
- Remplacer l’utilisation de la bibliothèque client.
- Rediriger les appels API vers une nouvelle plateforme.
Modifier la base de données sous-jacente nécessite également des changements dans l’application. Intègre la connectivité mise à jour dans ta liste de vérification des tests de migration.
Modifications de Schéma à Partir des Fonctionnalités RDBMS
Évalue PostgreSQL en ce qui concerne l’héritage des tables, la sécurité au niveau des lignes et les permissions utilisateur précises par rapport aux vues et déclencheurs de MySQL pour voir si la logique devrait passer à de nouvelles constructions améliorées disponibles dans chaque base de données. Les fonctionnalités affectant la fonctionnalité ont tendance à migrer de manière plus propre, en restant plus proches des normes SQL.
Modifications du Code d’Application
Mets à jour les chaînes de connexion et les pilotes utilisés, bien sûr. De plus, optimise les forces de performance de chaque base de données. MySQL peut tirer parti de davantage de jointures côté application et de logique de présentation, qui est maintenant purement en SQL sur PostgreSQL. D’autre part, PostgreSQL peut maintenant mettre en œuvre des approches de règles commerciales qui n’étaient auparavant possibles que via les déclencheurs et les procédures stockées de MySQL.
Heureusement, de nombreux cadres d’accès aux données comme Hibernate masquent certaines différences aux développeurs en limitant la syntaxe propriétaire exposée. Évalue si des modifications ORM ou client sont également judicieuses.
Une planification adéquate, des évaluations de l’impact des changements et des environnements de préproduction minimisent le stress de la migration pour exploiter avec succès le meilleur de chaque base de données.
Utilise Les Outils De Migration
Heureusement, certains outils aident à transférer les schémas et les données entre MySQL et PostgreSQL plus facilement :
- pgLoader : Utilitaire de migration de données populaire pour le passage à PostgreSQL.
- AWS SCT : Convertisseur de bases de données pour les migrations homogènes.
Ces derniers lissent automatiquement de nombreux problèmes de compatibilité OS/environnement tout en garantissant des données identiques à travers les systèmes.
Donc réserve-toi du temps pour la conversion/les tests, mais utilise des outils automatisés pour échanger les bases de données.
Quelle Est La Bonne Base De Données Pour Toi ?
Choisir entre PostgreSQL et MySQL dépend largement de tes besoins spécifiques en termes d’application et des compétences de ton équipe, mais quelques questions clés peuvent guider ta décision :
Quels types de données vas-tu stocker ? Si tu as besoin de travailler avec des données plus complexes et interconnectées, les types de données flexibles et le modèle relationnel-objet de PostgreSQL rendent cela beaucoup plus simple.
À quel point la performance des requêtes et la scalabilité sont-elles critiques pour la mission ? MySQL gère mieux le débit pour les applications web à fort trafic qui exigent des lectures plus rapides. Mais PostgreSQL s’est montré plus performant pour les charges de travail mixtes en lecture-écriture à l’échelle de l’entreprise.
Quelles compétences en administration ton équipe possède-t-elle ? PostgreSQL récompense une expertise avancée en bases de données, étant donné sa grande configurabilité. MySQL est plus simple pour les administrateurs sans compétences SQL excellentes à utiliser de manière productive.
Des plateformes comme DreamHost facilitent et rendent simple l’hébergement de serveurs de bases de données avec VPS, serveurs dédiés, et Cloud Hosting. DreamHost gère la sécurité et les sauvegardes automatiques pour optimiser les opérations afin que tu puisses te concentrer sur l’utilisation des données pour les insights commerciaux.
Alors, laisse l’équipe DBA de DreamHost gérer le déploiement et la gestion pendant que tu conçois la plateforme de données idéale pour ta croissance. PostgreSQL et MySQL offrent une économie open-source avec une fiabilité d’entreprise, alimentés par des experts cloud éprouvés. La meilleure base de données pour ton application t’attend probablement – essaie aujourd’hui !

