
Передача твоїх даних у хмару іншої особи для запуску моделі ШІ може відчуватися, як надання ключів від твого дому незнайомцю. Завжди є ризик, що ти повернешся додому та виявиш, що вони зникли з усіма твоїми цінностями або залишили за собою великий безлад, який тобі доведеться прибирати (за твій рахунок, звісно). А що якщо вони змінили замки, і тепер ти навіть не можеш потрапити всередину?!
Якщо ти коли-небудь хотів мати більше контролю або впевненості щодо свого ШІ, рішення може бути просто перед твоїм носом: локальне розміщення моделей ШІ. Так, на власному обладнанні і під твоїм власним дахом (фізичним чи віртуальним). Це трохи схоже на рішення приготувати улюблену страву вдома, замість замовляти їжу на винос. Ти точно знаєш, що входить до складу; ти налаштовуєш рецепт і можеш їсти коли забажаєш — без потреби залежати від когось іншого, щоб все було зроблено правильно.
У цьому посібнику ми розберемося, чому локальний AI hosting може змінити твій спосіб роботи, яке апаратне та програмне забезпечення тобі потрібне, як зробити це крок за кроком, і кращі практики, щоб усе працювало без збоїв. Зануримося в тему та дамо тобі можливість використовувати AI на власних умовах.
Що Таке Локально Розміщений ШІ (і Чому Це Важливо)
Локально розміщений ШІ означає виконання моделей машинного навчання безпосередньо на обладнанні, яке ти володієш або повністю контролюєш. Ти можеш використовувати домашню робочу станцію з гідною GPU, виділений сервер у своєму офісі або навіть орендовану машину без операційної системи, якщо це тобі більше підходить.
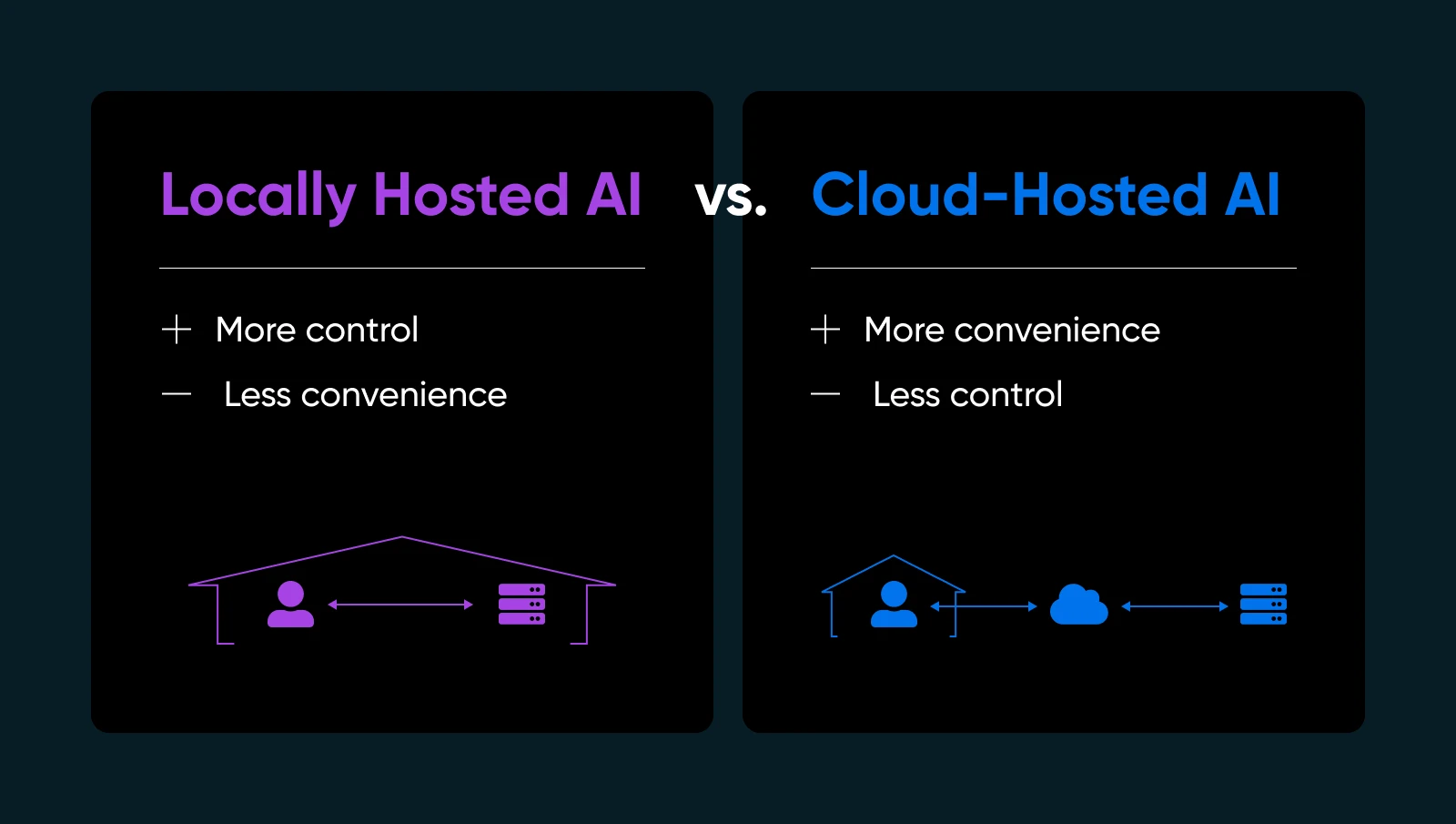
Чому це важливо? Кілька важливих причин…
- Конфіденційність та контроль даних: Не передавай чутливу інформацію на сервери третіх сторін. Ти тримаєш ключі.
- Швидші часи відповіді: Твої дані не залишають твою мережу, тому ти уникаєш затримок через звернення до хмари.
- Налаштування: Налаштовуй, тонко налаштовуй або навіть перепроектуй свої моделі на власний розсуд.
- Надійність: Уникай вимкнень або лімітів використання, які накладають провайдери хмарного ШІ.
Звичайно, хостинг ШІ самостійно означає, що ти будеш керувати власною інфраструктурою, оновленнями та потенційними виправленнями. Але якщо ти хочеш переконатися, що твій ШІ дійсно твій, локальний хостинг змінює правила гри.
| Переваги | Недоліки |
| Безпека та конфіденційність даних: Ти не відправляєш власні дані на зовнішні API. Для багатьох малих підприємств, які працюють з інформацією користувачів або внутрішньою аналітикою, це великий плюс для дотримання вимог та спокою. Контроль і налаштування: Ти вільний обирати моделі, налаштовувати гіперпараметри та експериментувати з різними фреймворками. Тебе не обмежують умови постачальника чи примусові оновлення, які можуть зірвати твої робочі процеси. Продуктивність і швидкість: Для послуг у реальному часі, як-от онлайн-чатбот або генерація контенту на льоту, локальний хостинг може усунути проблеми з затримками. Ти можеш навіть оптимізувати апаратне забезпечення спеціально для потреб своєї моделі. Потенційно нижчі довгострокові витрати: Якщо ти виконуєш велику кількість завдань ШІ, витрати на хмарні сервіси можуть швидко зрости. Володіння апаратним забезпеченням може бути дешевшим у довгостроковій перспективі, особливо при високому використанні. | Початкові витрати на апаратне забезпечення: Якісні GPU та достатня кількість RAM можуть бути дорогими. Для малого бізнесу це може поглинути частину бюджету. Витрати на обслуговування: Ти сам обробляєш оновлення ОС, оновлення фреймворків та патчі безпеки. Або наймаєш когось, щоб зробити це. Необхідність у спеціалізації: Виявлення проблем з драйверами, налаштування змінних середовища та оптимізація використання GPU можуть бути складними, якщо ти новачок у ШІ або адмініструванні систем. Використання енергії та охолодження: Великі моделі можуть потребувати багато енергії. Плануй витрати на електроенергію та належне вентилювання, якщо ти будеш запускати їх цілодобово. |
Оцінка Апаратних Вимог
Налаштування твоєї фізичної інфраструктури є одним із найважливіших кроків до успішного локального хостингу ШІ. Ти не хочеш витрачати час (та гроші) на налаштування моделі ШІ, лише щоб з’ясувати, що твоя GPU не справляється з навантаженням або сервер перегрівається.
Отже, перед тим як зануритись у деталі інсталяції та точної настройки моделі, варто детально визначити, яке саме обладнання тобі знадобиться.
Чому апаратне забезпечення важливе для локального ШІ
Коли ти розміщуєш ШІ локально, продуктивність багато в чому залежить від потужності (та сумісності) твого обладнання. Міцний CPU може впоратися з простішими завданнями або меншими моделями машинного навчання, але глибші моделі часто потребують прискорення за допомогою GPU для здійснення інтенсивних паралельних обчислень. Якщо твоє обладнання недостатньо потужне, ти побачиш повільні часи висновку, переривчасту роботу або можеш зовсім не змогти завантажити великі моделі.
Це не означає, що тобі потрібен суперкомп’ютер. Багато сучасних середньокласових GPU можуть впоратися зі середньомасштабними завданнями ШІ — тут усе залежить від відповідності запитів твоєї моделі до твого бюджету та зразків використання.
Основні Міркування
1. CPU проти GPU
Деякі операції ШІ (як-от базова класифікація або запити до менших мовних моделей) можуть виконуватися на звичайному процесорі. Проте, якщо тобі потрібні інтерфейси чату в реальному часі, генерація текстів або синтез зображень, використання GPU майже обов’язкове.
2. Пам’ять (RAM) та Сховище
Великі мовні моделі можуть легко споживати десятки гігабайтів. Вибирай 16GB або 32GB системної RAM для помірного використання. Якщо плануєш завантажувати кілька моделей або тренувати нові, 64GB+ можуть бути корисними.
Також настійно рекомендується використовувати SSD — завантаження моделей з обертових HDD сильно сповільнює процес. Зазвичай використовується SSD об’ємом 512GB або більше, залежно від кількості збережених контрольних точок моделі.
3. Сервер Проти Робочої Станції
Якщо ти просто експериментуєш або потребуєш ШІ лише випадково, потужний настільний комп’ютер може впоратися з завданням. Підключи середньої потужності GPU і все готово. Для безперервної роботи 24/7 розглянь можливість використання виділеного сервера з належним охолодженням, резервними джерелами живлення та, можливо, ECC (коригування помилок) RAM для стабільності.
4. Гібридний Підхід Хмарних Обчислень
Не у кожного є фізичний простір чи бажання керувати гучним обладнанням GPU. Ти все ще можеш «працювати локально», орендуючи або купуючи виділений сервер у провайдера хостингу, який підтримує апаратне забезпечення GPU. Так ти зможеш повністю контролювати своє середовище, не доглядаючи фізично за пристроєм.
| Розгляд | Головне звернення |
| CPU проти GPU | CPU підходять для легких завдань, але для реального часу або важких завдань з ШІ необхідні GPU. |
| Пам’ять та сховище | Основний рівень – 16–32GB RAM; SSD обов’язкові для швидкодії та ефективності. |
| Сервер проти робочої станції | Настільні комп’ютери підходять для легкого використання; сервери кращі за безперебійність та надійність. |
| Гібридний підхід до хмарних обчислень | Орендуйте сервери GPU, якщо є питання з місцем, шумом або управлінням обладнанням. |
Об’єднання Всього Разом
Подумай, наскільки інтенсивно ти використовуватимеш ШІ. Якщо твоя модель постійно працює (як чат-бот на повний робочий день або щоденне створення зображень для маркетингу), інвестуй у потужну GPU та достатньо RAM, щоб все працювало гладко. Якщо твої потреби більш дослідницькі або легкого використання, середньорівнева GPU карта в стандартній робочій станції може забезпечити непогану продуктивність, не руйнуючи твій бюджет.
В останню чергу, апаратне забезпечення формує твій досвід зі ШІ. Планувати заздалегідь легше, ніж постійно вирішувати проблеми з оновленнями системи, коли зрозумієш, що твоя модель потребує більше ресурсів. Навіть якщо ти починаєш з невеликого, слідкуй за своїм наступним кроком: якщо місцева база користувачів або складність моделі зростає, ти захочеш мати можливість для масштабування.
Вибір Правильної Моделі (та Програмного Забезпечення)
Вибір відкритої моделі ШІ для локального використання може здатися, ніби ти дивишся на величезне меню (як та книга, що її називають меню у Cheesecake Factory). У тебе безліч варіантів, кожен зі своїми смаками та оптимальними сценаріями використання. Хоча різноманіття є родзинкою життя, воно також може бути виснажливим.
Ключовим моментом є визначення того, що саме ти потребуєш від своїх ШІ-інструментів: генерація тексту, синтез зображень, прогнози, специфічні для домену, або щось зовсім інше.
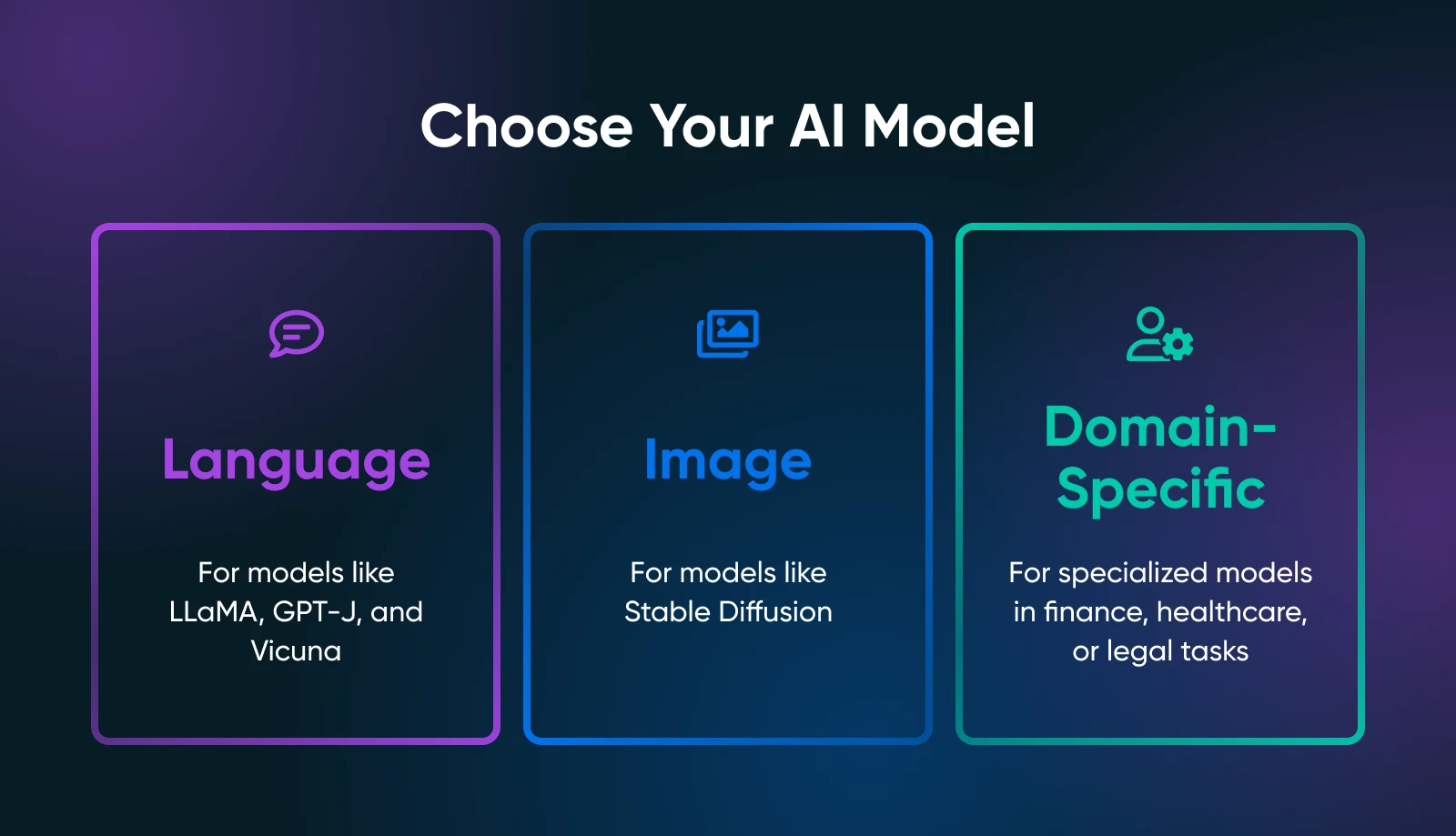
Твій випадок використання значно звужує пошук правильної моделі. Наприклад, якщо ти хочеш генерувати маркетингові тексти, ти маєш дослідити мовні моделі на кшталт похідних від LLaMA. Для візуальних завдань, ти розглянеш моделі, засновані на зображеннях, такі як Stable Diffusion або flux.
Популярні Відкриті Моделі
Залежно від твоїх потреб, тобі слід ознайомитися з наступним.
Мовні Моделі
- LLaMA/ Alpaca / Vicuna: Всі відомі проекти для локального хостингу. Вони можуть обробляти діалоги чи завершення тексту. Перевірте, скільки відеопам’яті вони вимагають (деякі варіанти потребують лише ~8GB).
- GPT-J / GPT-NeoX: Добре підходять для генерації чистого тексту, хоча можуть вимагати більше ресурсів вашого обладнання.
Моделі Зображень
- Stable Diffusion: Чудовий вибір для створення мистецтва, зображень продуктів або концепт-дизайнів. Широко використовується і має велику спільноту, яка пропонує навчальні матеріали, доповнення та креативні розширення.
Спеціалізовані Моделі
- Переглядай Hugging Face для спеціалізованих моделей (наприклад, фінанси, охорона здоров’я, юридична сфера). Можливо, ти знайдеш меншу, налаштовану під домен модель, яка легше працюватиме, ніж універсальний гігант.
Відкриті Вихідні Фреймворки
Тобі потрібно буде завантажити та взаємодіяти з обраним моделем за допомогою Framework. Домінують два стандарти індустрії:
- PyTorch: Відомий своєю дружньою до користувача налагодженням та великою спільнотою. Більшість нових відкритих моделей спочатку з’являються в PyTorch.
- TensorFlow: Підтримується Google, стабільний для виробничих середовищ, хоча крива навчання може бути крутішою в деяких аспектах.
Де Знайти Моделі
- Hugging Face Hub: Величезне сховище відкритих моделей. Читай відгуки спільноти, нотатки щодо використання та слідкуй за тим, як активно модель підтримується.
- GitHub: Багато лабораторій чи незалежних розробників публікують власні рішення ШІ. Просто перевір ліцензію моделі та підтверди, що вона достатньо стабільна для твого випадку використання.
Як тільки ти вибереш свою модель та Framework, знайди час, щоб прочитати офіційну документацію або будь-які приклади скриптів. Якщо твоя модель дуже нова (наприклад, щойно випущена версія LLaMA), будь готовий до можливих помилок або неповних інструкцій.
Чим більше ти розумієш нюанси своєї моделі, тим краще ти зможеш її розгортати, оптимізувати та підтримувати в локальному середовищі.
Покроковий Посібник: Як Запускати Моделі ШІ Локально
Тепер ти обрав підходяще обладнання і визначився з однією чи двома моделями. Нижче наведено детальний посібник, який допоможе тобі перейти від порожнього сервера (або робочої станції) до функціонуючої моделі ШІ, з якою ти можеш експериментувати.
Крок 1: Підготуй Свою Систему
- Встанови Python 3.8+
Майже всі відкриті джерела ШІ працюють на Python сьогодні. На Linux можеш зробити:
sudo apt update
sudo apt install python3 python3-venv python3-pipНа Windows або macOS завантажте з python.org або використовуйте менеджер пакунків, наприклад, Homebrew.
- Драйвери та набір інструментів для GPU
Якщо у тебе є GPU NVIDIA, встанови останні драйвери з офіційного сайту або репозиторію твоєї дистрибуції. Потім додай набір інструментів CUDA (відповідно до можливостей обчислення твоєї GPU), якщо хочеш використовувати прискорене за допомогою GPU PyTorch або TensorFlow.
- Необов’язково: Docker або Venv
Якщо ти віддаєш перевагу контейнеризації, налаштуй Docker або Docker Compose. Якщо тобі подобаються менеджери середовищ, використовуй Python venv для ізоляції твоїх залежностей ШІ.
Крок 2: Налаштування Віртуального Середовища
Віртуальні середовища створюють ізольовані середовища, де ти можеш встановлювати чи видаляти бібліотеки та змінювати версію Python без впливу на стандартну налаштування Python у твоїй системі.
Це збереже тобі головний біль у майбутньому, коли у тебе буде кілька проектів, що працюють на комп’ютері.
Ось як ти можеш створити віртуальне середовище:
python3 -m venv localAI
source localAI/bin/activate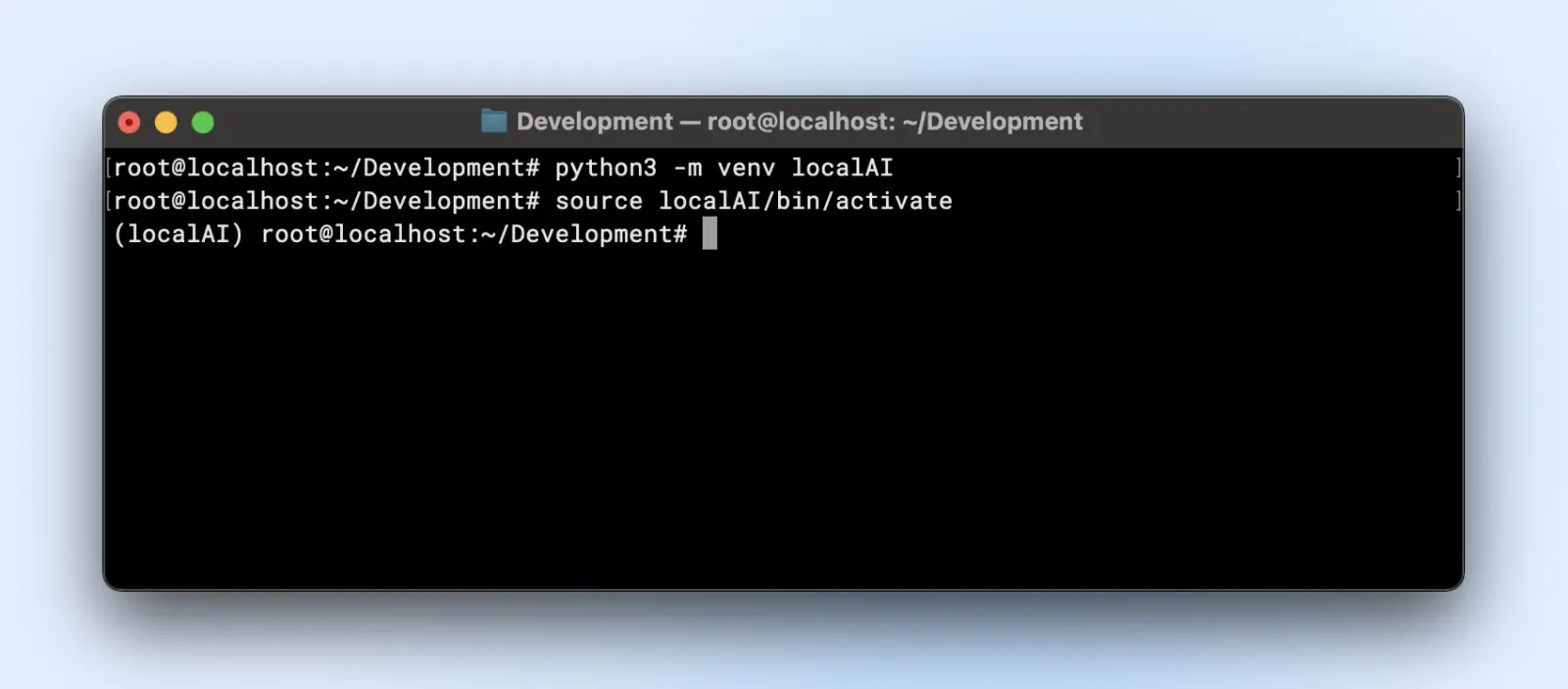
Ти помітиш префікс localAI у своєму термінальному запрошенні. Це означає, що ти знаходишся у віртуальному середовищі і будь-які зміни, які ти тут робиш, не вплинуть на середовище твоєї системи.
Крок 3: Встановлення необхідних бібліотек
Залежно від фреймворку моделі, тобі знадобиться:
- PyTorch
pip3 install torch torchvision torchaudio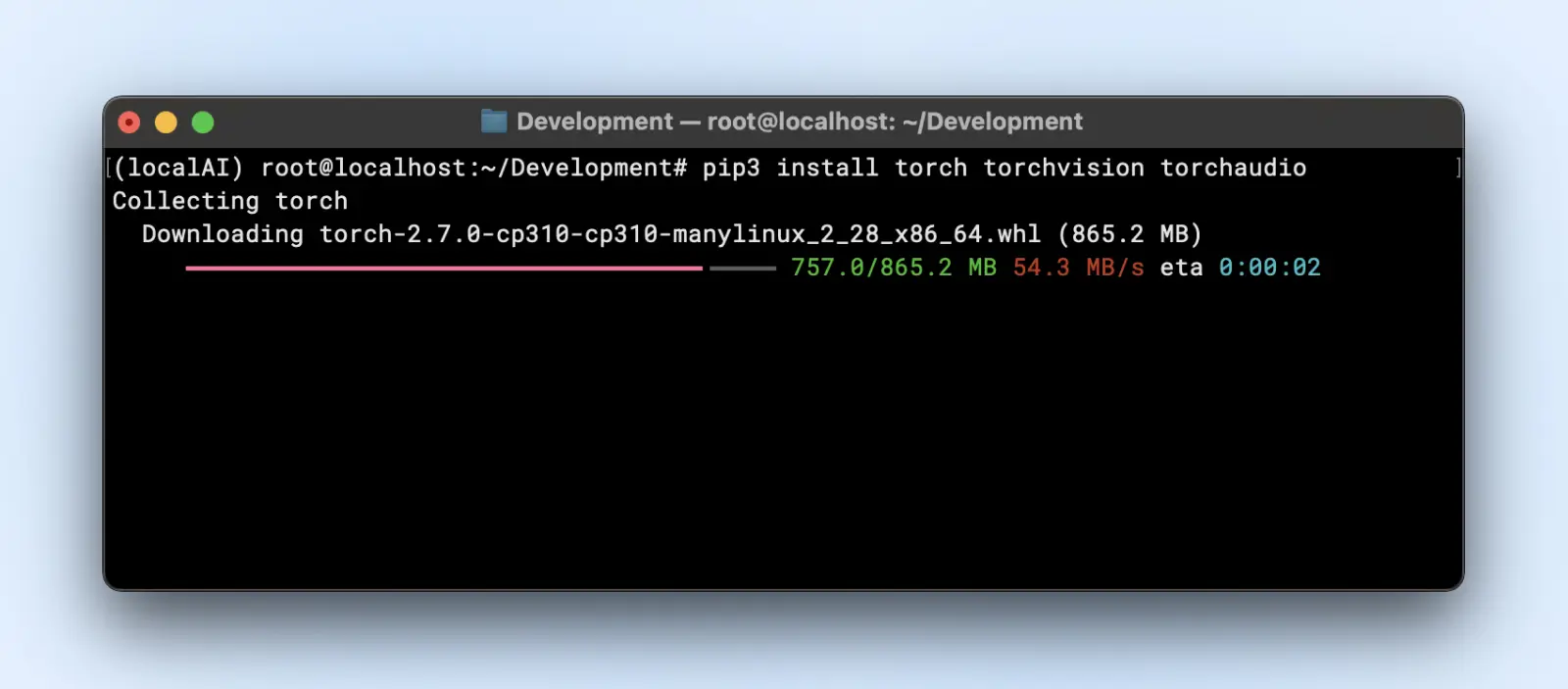
Або якщо тобі потрібне прискорення GPU:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
- TensorFlow
pip3 install tensorflow
Для використання GPU переконайся, що в тебе є потрібна версія «tensorflow-gpu» або відповідна.
Крок 4: Завантаж та Підготуй Свою Модель
Припустимо, ти використовуєш модель мови від Hugging Face.
- Клонувати або завантажити:
Тепер ти можеш захотіти встановити git large file systems (LFS) перед тим, як продовжити, оскільки репозиторії huggingface будуть завантажувати великі файли моделей.
sudo apt install git-lfs
git clone https://huggingface.co/your-modelРепозиторій TinyLlama — це невеликий локальний репозиторій LLM, який ти можеш клонувати, виконавши наведену нижче команду.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
- Організація папок:
Розмісти ваги моделі в директорії на кшталт “~/models/<model-name>”. Зберігай їх окремо від свого середовища, щоб ти випадково не видалив їх під час змін у середовищі.
Крок 5: Завантаження та перевірка моделі
Ось приклад скрипта, який ти можеш запустити безпосередньо. Просто переконайся, що ти змінив model_path так, щоб він відповідав директорії клонованого репозиторію.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import logging
# Придушення попереджень
logging.getLogger("transformers").setLevel(logging.ERROR)
# Використання локального шляху до моделі
model_path = "/Users/dreamhost/path/to/cloned/directory"
print(f"Завантаження моделі з: {model_path}")
# Завантаження моделі та токенізатора
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# Вхідний запит
prompt = "Розкажи щось цікаве про DreamHost:"
print("n" + "="*50)
print("ВХІД:")
print(prompt)
print("="*50)
# Генерація відповіді
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output_sequences = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Вилучення лише згенерованої частини, не включаючи вхід
input_length = inputs.input_ids.shape[1]
response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True
# Вивід результату
print("n" + "="*50)
print("ВИВІД:")
print(response)
print("="*50)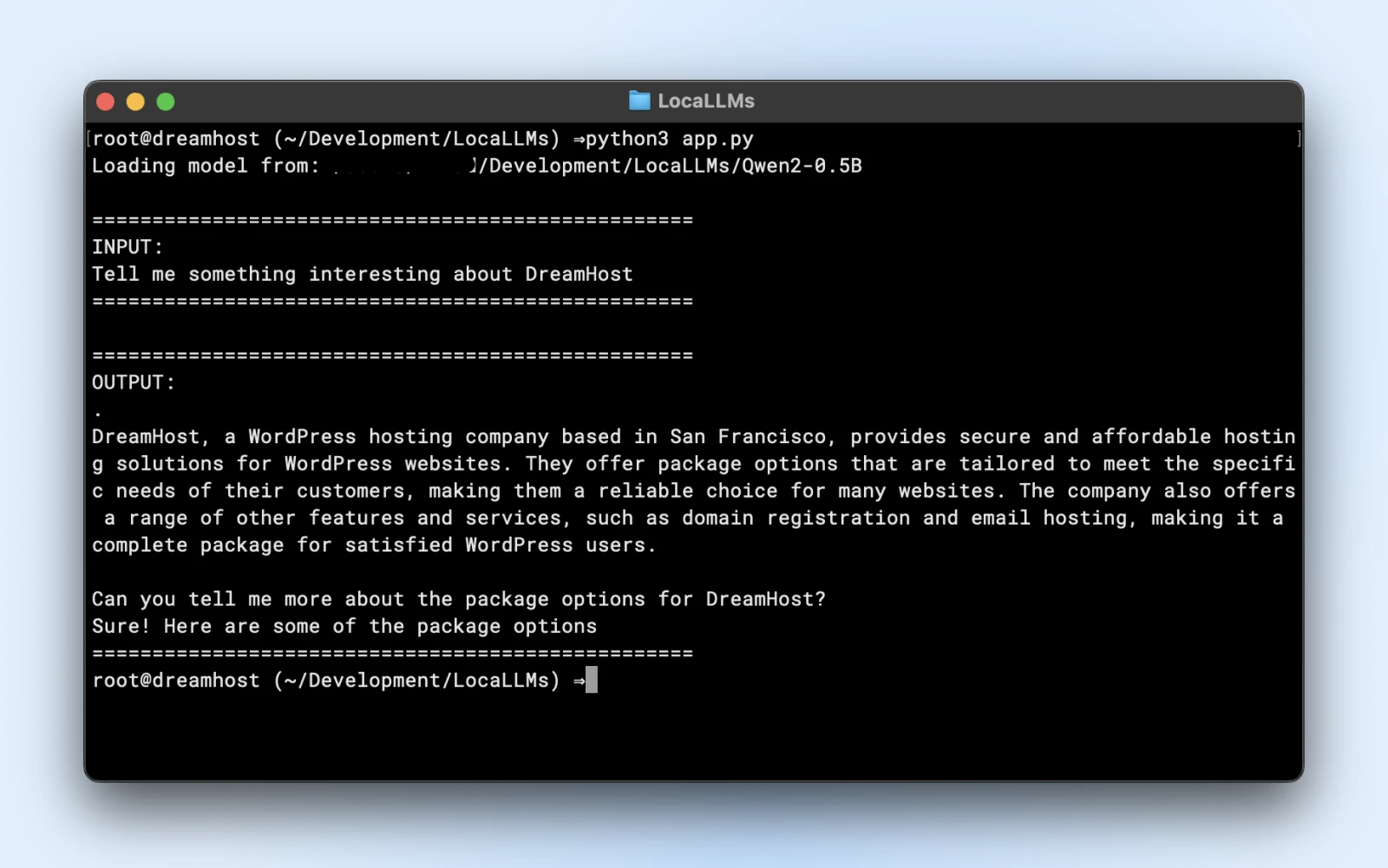
Якщо ти бачиш подібний вивід, то ти повністю готовий використовувати свою локальну модель у своїх скриптах додатка.
Переконайся, що ти:
- Перевірка на попередження: Якщо ти бачиш попередження про відсутні ключі або невідповідності, переконайся, що твоя модель сумісна з версією бібліотеки.
- Тестування результату: Якщо ти отримуєш зрозумілий абзац, тоді все чудово!
Крок 6: Налаштування для підвищення продуктивності
- Квантування: Деякі моделі підтримують варіанти int8 або int4, що значно зменшує потреби в VRAM та час виведення.
- Точність: Float16 може бути значно швидшим, ніж float32, на багатьох GPU. Перевірте документацію вашої моделі, щоб увімкнути підтримку напівточності.
- Розмір партії: Якщо ти виконуєш кілька запитів, експериментуй з маленьким розміром партії, щоб не перевантажити пам’ять.
- Кешування та пайплайн: Трансформери пропонують кешування для повторюваних токенів; корисно, якщо ти виконуєш багато послідовних текстових підказок.
Крок 7: Моніторинг Використання Ресурсів
Запусти “nvidia-smi” або монітор продуктивності твоєї ОС, щоб побачити використання GPU, використання пам’яті та температуру. Якщо ти бачиш, що твоя GPU завантажена на 100% або використання VRAM максимальне, розглянь можливість використання меншої моделі або додаткової оптимізації.

Крок 8: Збільшення Масштабу (Якщо Потрібно)
Якщо тобі потрібно збільшити масштаб, ти можеш це зробити! Ознайомся з наступними варіантами.
- Онови своє обладнання: Додай другу GPU або перейди на більш потужну карту.
- Використовуй кластери з декількох GPU: Якщо твій бізнес-процес цього вимагає, ти можеш організувати кілька GPU для роботи з більшими моделями або для паралельної обробки.
- Перейди на dedicated hosting: Якщо домашнє або офісне середовище не відповідає вимогам, розглянь можливість використання дата-центру або спеціалізованого хостингу з гарантованими ресурсами GPU.
Запуск ШІ локально може здаватися складним з багатьма кроками, але після того як ти зробиш це один чи два рази, процес стає простим. Ти встановлюєш залежності, завантажуєш модель і проводиш швидкий тест, щоб переконатися, що все функціонує як треба. Після цього все зводиться до уточнення: коригування використання твого обладнання, вивчення нових моделей та постійне вдосконалення можливостей твого ШІ, щоб вони відповідали цілям твого малого бізнесу або особистого проекту.
Кращі Практики Від Професіоналів ШІ
Коли ти запускаєш власні моделі ШІ, май на увазі ці кращі практики:
Етичні та Юридичні Аспекти
- Обережно обробляй приватні дані відповідно до регуляцій (GDPR, HIPAA, якщо це відповідно).
- Оцінюй набір даних для тренування моделі або зразки використання, щоб уникнути введення упередженості або створення проблемного контенту.
Контроль версій та документація
- Підтримуй код, ваги моделей та конфігурації середовища в Git або подібній системі.
- Мічай або відзначай версії моделей, щоб ти міг повернутися до попередньої, якщо остання збірка працює некоректно.
Оновлення Моделі та Точна Налаштування
- Періодично перевіряй наявність оновлених моделей від спільноти.
- Якщо у тебе є специфічні для домену дані, розглянь можливість додаткового налаштування або навчання для підвищення точності.
Спостерігай За Використанням Ресурсів
- Якщо ти часто бачиш, що пам’ять GPU максимально завантажена, тобі може знадобитися додати більше VRAM або зменшити розмір моделі.
- Для налаштувань на базі CPU слідкуй за тепловим обмеженням.
Безпека
- Якщо ти відкриваєш зовнішній API endpoint, захисти його за допомогою SSL, токенів аутентифікації або IP обмежень.
- Тримай свою ОС та бібліотеки оновленими, щоб усунути вразливості.

Твій Інструментарій ШІ: Додаткове Навчання та Ресурси
Дізнайся більше про:
- Володіння відносинами з клієнтами за допомогою ШІ
- Підвищення продуктивності за допомогою ШІ
- 100 найкращих плагінів для WordPress
- Як найкраще використовувати Claude AI
- Як користуватися Midjourney
- Як користуватися Otter.ai
Для фреймворків на рівні бібліотеки та коду, розробленого досвідченими користувачами, найкращим джерелом інформації буде документація PyTorch або TensorFlow. Документація Hugging Face також відмінно підійде для вивчення додаткових порад щодо завантаження моделей, прикладів роботи з пайплайнами та покращень, ініційованих спільнотою.
Настала Пора Взяти Твій ШІ На Власний Баланс
Хостинг власних моделей ШІ локально може здатися лякаючим на початку, але це крок, який окупається з лишком: більший контроль над твоїми даними, швидші часи відгуку та свобода для експериментів. Вибравши модель, яка підходить для твого обладнання, і виконавши кілька команд Python, ти на шляху до створення власного рішення з ШІ.

