
Jouw website is als een koffiezaak. Mensen komen binnen en bekijken het menu. Sommigen bestellen lattes, gaan zitten, nippen en vertrekken.
Maar wat als de helft van je “klanten” alleen maar tafels bezet, de tijd van je barista’s verspilt en nooit koffie koopt?
Ondertussen vertrekken echte klanten vanwege geen tafels en trage service?
Nou, dat is de wereld van webcrawlers en bots.
Deze geautomatiseerde programma’s verslinden je bandbreedte, vertragen je site en jagen echte klanten weg.
Recente studies tonen aan dat bijna 51% van het internetverkeer afkomstig is van bots. Dat klopt — meer dan de helft van je digitale bezoekers kunnen gewoon jouw serverbronnen verspillen.
Maar raak niet in paniek!
Deze gids helpt je problemen te herkennen en de prestaties van je site te beheren, allemaal zonder te coderen of je technische neef te bellen.
Een Snelle Opfriscursus Over Bots
Bots zijn geautomatiseerde softwareprogramma’s die taken op het internet uitvoeren zonder menselijke tussenkomst. Ze:
- Bezoek websites
- Interactie met digitale inhoud
- En voer specifieke functies uit op basis van hun programmering.
Sommige bots analyseren en indexeren je site (wat mogelijk de zoekmachineranking verbetert.) Sommige besteden hun tijd aan het schrapen van je inhoud voor AI-trainingsdatasets — of erger — het plaatsen van spam, het genereren van neprecensies, of het zoeken naar exploits en beveiligingslekken in je website.
Natuurlijk zijn niet alle bots gelijk. Sommige zijn cruciaal voor de gezondheid en zichtbaarheid van je website. Andere zijn mogelijk neutraal, en een paar zijn ronduit schadelijk. Het verschil kennen — en beslissen welke bots te blokkeren en welke toe te staan — is essentieel voor het beschermen van je site en zijn reputatie.
Goede Bot, Slechte Bot: Wat Is Wat?
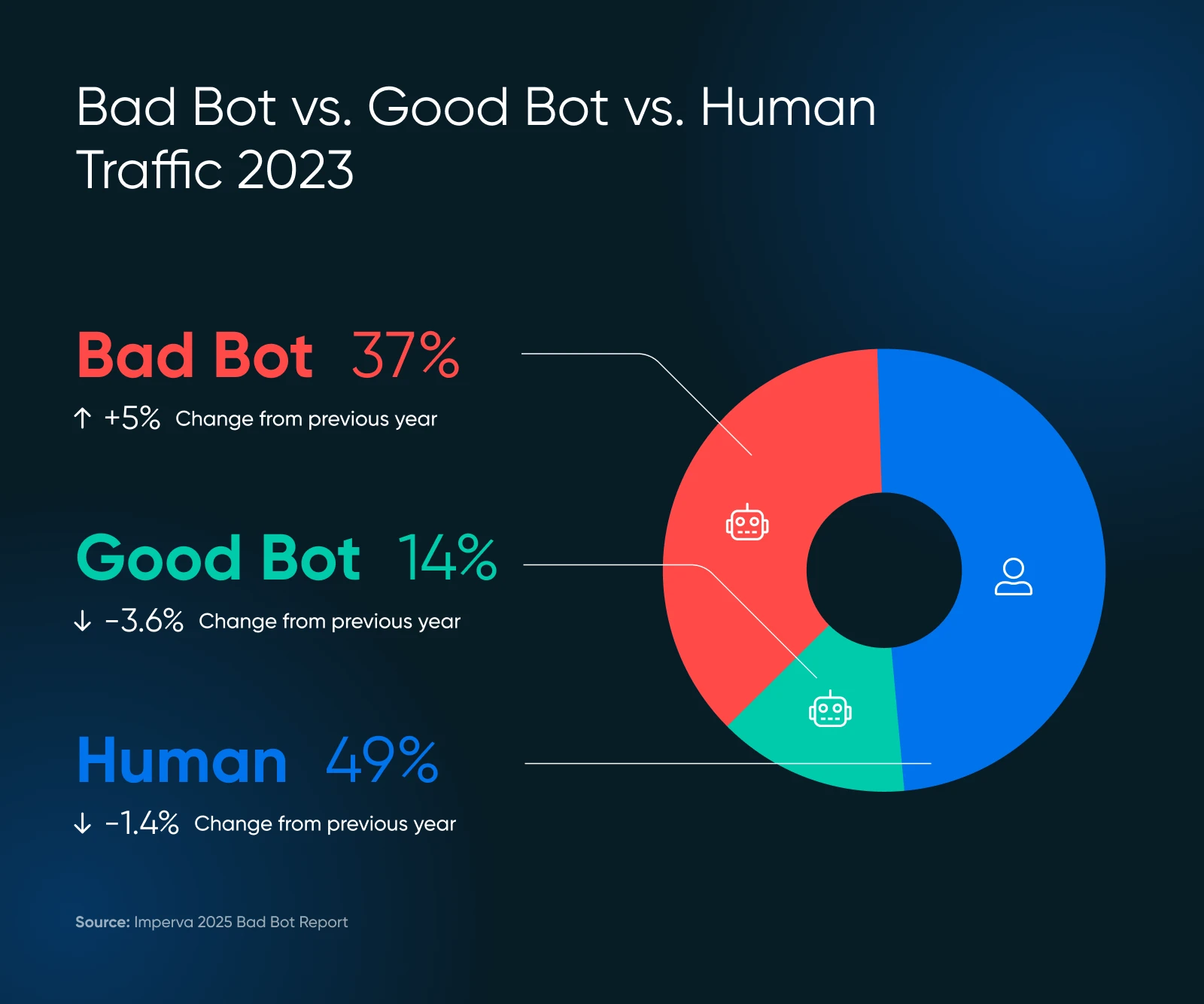
Bots vormen het internet.
Bijvoorbeeld, Google’s bot bezoekt elke pagina op het internet en voegt deze toe aan hun databases voor ranking. Deze bot helpt bij het leveren van waardevol zoekverkeer, wat belangrijk is voor de gezondheid van je website.
Maar niet elke bot levert waarde, en sommige zijn gewoon ronduit slecht. Hier is wat je moet behouden en wat je moet blokkeren.
De VIP Bots (Behoud Deze)
- Zoekmachine webcrawlers zoals Googlebot en Bingbot zijn voorbeelden van deze crawlers. Blokkeer ze niet, anders word je online onzichtbaar.
- Analytics bots verzamelen gegevens over de prestaties van je site, zoals de Google Pagespeed Insights bot of de GTmetrix bot.
De Onruststokers (Hebben Beheer Nodig)
- Content scrapers die jouw inhoud stelen voor gebruik elders
- Spam bots die jouw formulieren en reacties overspoelen met rommel
- Slechte acteurs die proberen accounts te hacken of kwetsbaarheden te misbruiken
De schaal van slechte bots kan je verrassen. In 2024 maakten geavanceerde bots 55% uit van al het geavanceerde slechte botverkeer, terwijl de goede 44% voor hun rekening namen.
Die geavanceerde bots zijn sluw — ze kunnen menselijk gedrag nabootsen, inclusief muisbewegingen en klikken, waardoor ze moeilijker te detecteren zijn.
Vertragen Bots Jouw Website? Let Op Deze Waarschuwingssignalen
Voordat we naar oplossingen springen, laten we eerst zeker weten dat bots daadwerkelijk je probleem zijn. Bekijk de onderstaande tekenen.
Waarschuwingssignalen In Je Analytics
- Onverklaarbare Verkeerspieken: Als je bezoekersaantal plotseling omhoogschiet, maar de verkopen niet, kunnen bots de boosdoener zijn.
- Alles Vertraagt: Pagina’s doen er langer over om te laden, wat echte klanten frustreert die wellicht voorgoed vertrekken. Aberdeen toont aan dat 40% van de bezoekers websites verlaten die meer dan drie seconden nodig hebben om te laden, wat leidt tot…
- Hoge Bouncepercentages: boven de 90% wijzen vaak op botactiviteit.
- Vreemde Sessiepatronen: Mensen bezoeken doorgaans niet slechts voor milliseconden of blijven uren op één pagina.
- Je Begint Veel Ongebruikelijk Verkeer te Krijgen: Vooral uit landen waar je geen zaken doet. Dat is verdacht.
- Formulierinzendingen Met Willekeurige Tekst: Klassiek botgedrag.
- Je Server Raakt Overweldigd: Stel je voor dat je in één keer 100 klanten ziet, maar 75 zijn er gewoon aan het rondkijken.
Controleer Je Serverlogboeken
De serverlogboeken van je website bevatten gegevens van elke bezoeker.
Hier is waar je op moet letten:
- Te veel opeenvolgende verzoeken van hetzelfde IP-adres
- Vreemde user-agent strings (de identificatie die bots geven)
- Verzoeken voor ongebruikelijke URL’s die niet op je site bestaan
User Agent
Een user agent is een type software dat webinhoud ophaalt en weergeeft zodat gebruikers ermee kunnen interageren. De meest voorkomende voorbeelden zijn webbrowsers en e-maillezers.
Lees MeerEen legitiem Googlebot-verzoek kan er zo uitzien in je logboeken:
66.249.78.17 - - [13/Jul/2015:07:18:58 -0400] "GET /robots.txt HTTP/1.1" 200 0 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"Als je patronen ziet die niet overeenkomen met normaal menselijk surfgedrag, is het tijd om actie te ondernemen.
Het GPTBot-Probbleem bij Toename van AI Webcrawlers
Onlangs hebben veel website-eigenaren problemen gemeld met AI webcrawlers die abnormale verkeerspatronen genereren.
Volgens onderzoek van Imperva deed de GPTBot van OpenAI 569 miljoen verzoeken in één maand, terwijl de bot van Claude 370 miljoen verzoeken deed over het netwerk van Vercel.
Zoek naar:
- Foutpieken in je logboeken: Als je plotseling honderden of duizenden 404-fouten ziet, controleer dan of ze van AI webcrawlers zijn.
- Extreem lange, onzinnige URL’s: AI bots kunnen bizarre URL’s aanvragen zoals de volgende:
/Odonto-lieyectoresli-541.aspx/assets/js/plugins/Docs/Productos/assets/js/Docs/Productos/assets/js/assets/js/assets/js/vendor/images2021/Docs/...- Recursieve Parameters: Zoek naar oneindig herhalende parameters, bijvoorbeeld:
amp;amp;amp;page=6&page=6- Bandbreedtepieken: Readthedocs, een gerenommeerd bedrijf in technische documentatie, verklaarde dat één AI-crawler 73TB aan ZIP-bestanden heeft gedownload, waarvan 10TB in één dag, wat hen meer dan $5,000 aan bandbreedtekosten heeft gekost.
Deze patronen kunnen wijzen op AI webcrawlers die ofwel defect zijn of gemanipuleerd worden om problemen te veroorzaken.
Wanneer Technische Hulp In te Schakelen
Als je deze signalen ziet maar niet weet wat je vervolgens moet doen, is het tijd om professionele hulp in te schakelen. Vraag je ontwikkelaar om specifieke user agents zoals deze te controleren:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, zoals Gecko; compatibel; GPTBot/1.2; +https://openai.com/gptbot)
Er zijn veel geregistreerde user agent strings voor andere AI crawlers die je op Google kunt opzoeken om te blokkeren. Let op dat de strings veranderen, wat betekent dat je na verloop van tijd een vrij lange lijst kunt krijgen.
👉 Heb je geen ontwikkelaar onder sneltoets? Het DreamCare team van DreamHost kan je logboeken analyseren en beschermingsmaatregelen implementeren. Zij hebben deze problemen eerder gezien en weten precies hoe ze ermee om moeten gaan.
Je Bot-Bestrijdingsuitrusting: 5 Eenvoudige Stappen Om De Controle Terug Te Pakken
Nu het leuke deel: hoe je deze bots kunt stoppen die je site vertragen. Sla je mouwen op en laten we aan de slag gaan.
1. Maak Een Correct robots.txt Bestand
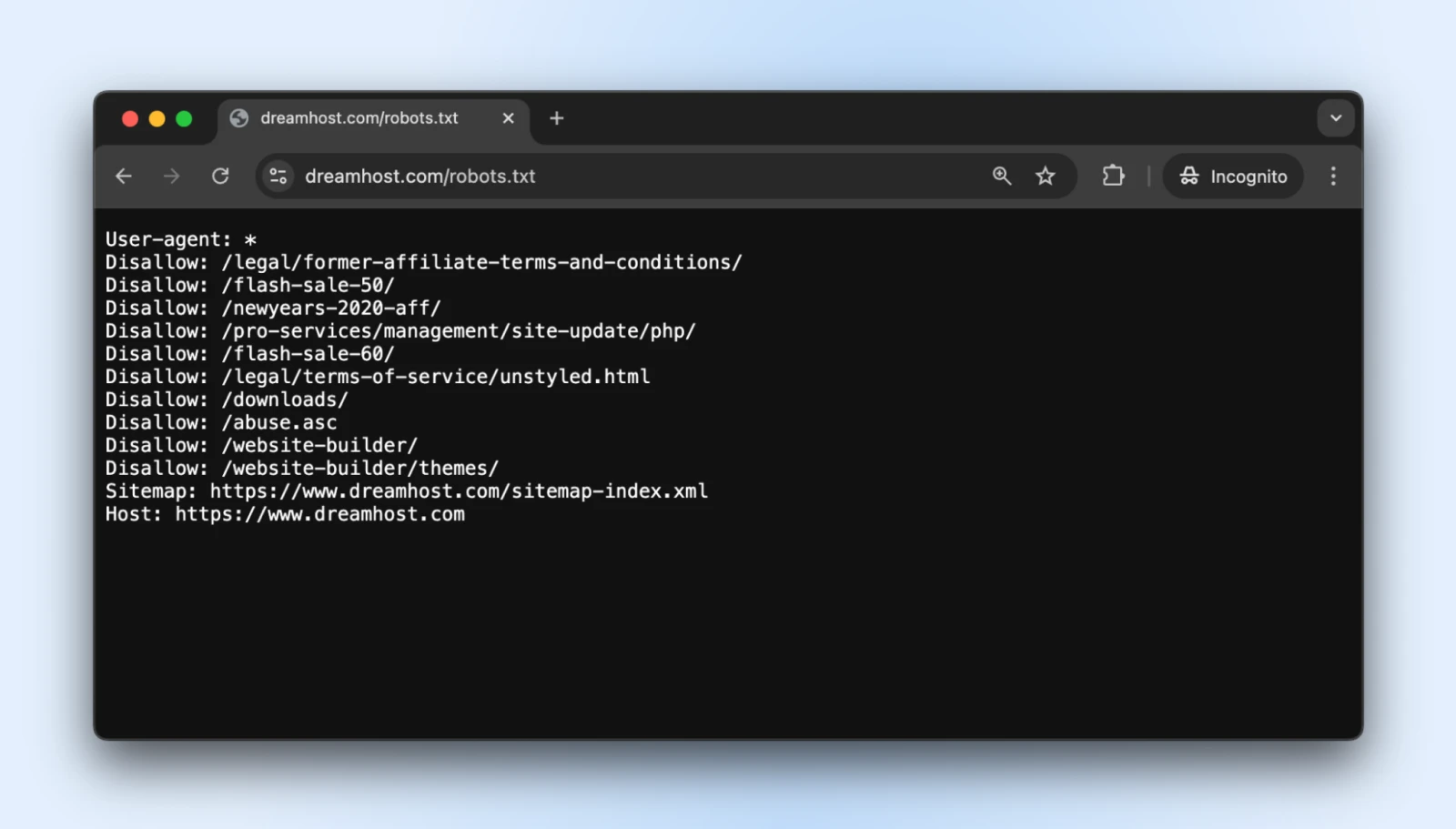
Het robots.txt eenvoudige tekstbestand bevindt zich in je Root-directory en vertelt goed opgevoede bots welke delen van je site ze niet moeten benaderen.
Je kunt de robots.txt voor vrijwel elke website openen door /robots.txt toe te voegen aan het domein. Bijvoorbeeld, als je het robots.txt-bestand voor DreamHost wilt zien, voeg je robots.txt toe aan het einde van het domein zoals dit: https://dreamhost.com/robots.txt
Er is geen verplichting voor een van de bots om de regels te accepteren.
Maar beleefde bots zullen het respecteren, en de lastpakken kunnen ervoor kiezen om de regels te negeren. Het is het beste om toch een robots.txt toe te voegen, zodat de goede bots niet beginnen met het indexeren van admin login, post-checkout pagina’s, bedankpagina’s, enz.
Hoe Te Implementeren
1. Maak een platte tekstbestand met de naam robots.txt
2. Voeg je instructies toe met dit formaat:
User-agent: * # Deze regel geldt voor alle bots
Disallow: /admin/ # Crawl de admin-gebied niet
Disallow: /private/ # Blijf uit privé mappen
Crawl-delay: 10 # Wacht 10 seconden tussen aanvragen
User-agent: Googlebot # Speciale regels alleen voor Google
Allow: / # Google kan alles toegang hebben3. Upload het bestand naar de rootdirectory van je website (zodat het op je-domein.com/robots.txt staat)
De “Crawl-delay”-richtlijn is hier jouw geheime wapen. Het dwingt bots te wachten tussen verzoeken, waardoor ze jouw server niet kunnen overbelasten.
De meeste grote webcrawlers respecteren dit, hoewel Googlebot zijn eigen systeem volgt (dat je kunt beheren via Google Search Console).
Professionele tip: Test je robots.txt met Google’s robots.txt testtool om er zeker van te zijn dat je geen belangrijke inhoud per ongeluk hebt geblokkeerd.
2. Stel Snelheidsbeperking In
Rate limiting beperkt het aantal verzoeken dat een enkele bezoeker kan doen binnen een bepaalde periode.
Het voorkomt dat bots je server overbelasten, zodat gewone mensen zonder onderbrekingen je site kunnen bekijken.
Hoe Te Implementeren
Als je Apache gebruikt (veelvoorkomend voor WordPress-sites), voeg dan deze regels toe aan je .htaccess-bestand:
<IfModule mod_rewrite.c>
RewriteEngine Aan
RewriteCond %{REQUEST_URI} !(.css|.js|.png|.jpg|.gif|robots.txt)$ [NC]
RewriteCond %{HTTP_USER_AGENT} !^Googlebot [NC]
RewriteCond %{HTTP_USER_AGENT} !^Bingbot [NC]
# Sta maximaal 3 verzoeken in 10 seconden per IP toe
RewriteCond %{REMOTE_ADDR} ^([0-9]+.[0-9]+.[0-9]+.[0-9]+)$
RewriteRule .* - [F,L]
</IfModule>.htaccess
u201c.htaccessu201d is een configuratiebestand dat wordt gebruikt door de Apache-webserversoftware. Het .htaccess-bestand bevat richtlijnen (instructies) die Apache vertellen hoe het zich moet gedragen voor een bepaalde website of directory.
Lees MeerAls je Nginx gebruikt, voeg dit toe aan je serverconfiguratie:
limit_req_zone $binary_remote_addr zone=one:10m rate=30r/m;
server {
...
location / {
limit_req zone=one burst=5;
...
}
}Veel hosting controlepanelen, zoals cPanel of Plesk, bieden ook snelheidsbeperkende hulpmiddelen in hun beveiligingssecties.
Professionele tip: Begin met conservatieve limieten (zoals 30 verzoeken per minuut) en monitor je site. Je kunt altijd strengere beperkingen toepassen als het verkeer van bots aanhoudt.
3. Gebruik Een Content Delivery Netwerk (CDN)
CDNs doen twee goede dingen voor je:
- Verspreid inhoud over wereldwijde servernetwerken zodat je website snel wereldwijd wordt geleverd
- Filter verkeer voordat het de website bereikt om irrelevante bots en aanvallen te blokkeren
Het deel over “irrelevante bots” is voor nu belangrijk voor ons, maar de andere voordelen zijn ook nuttig. De meeste CDNs bevatten ingebouwde botbeheer dat verdachte bezoekers automatisch identificeert en blokkeert.
Hoe Te Implementeren
- Meld je aan voor een CDN-service zoals DreamHost CDN, Cloudflare, Amazon CloudFront of Fastly.
- Volg de installatie-instructies (kan vereisen dat je nameservers verandert).
- Configureer de beveiligingsinstellingen om botbescherming in te schakelen.
Als je hostingdienst standaard een CDN aanbiedt, worden alle stappen geëlimineerd aangezien je website automatisch op CDN gehost zal worden.
Zodra ingesteld, zal je CDN:
- Cache statische inhoud om de serverbelasting te verminderen.
- Filter verdacht verkeer voordat het je site bereikt.
- Pas machine learning toe om onderscheid te maken tussen legitieme en kwaadaardige verzoeken.
- Blokkeer automatisch bekende kwaadaardige actoren.
Professionele Tip: De gratis versie van Cloudflare omvat basisbescherming tegen bots die goed werkt voor de meeste kleine zakelijke websites. Hun betaalde plannen bieden geavanceerdere opties als je die nodig hebt.
4. Voeg CAPTCHA Toe Voor Gevoelige Acties
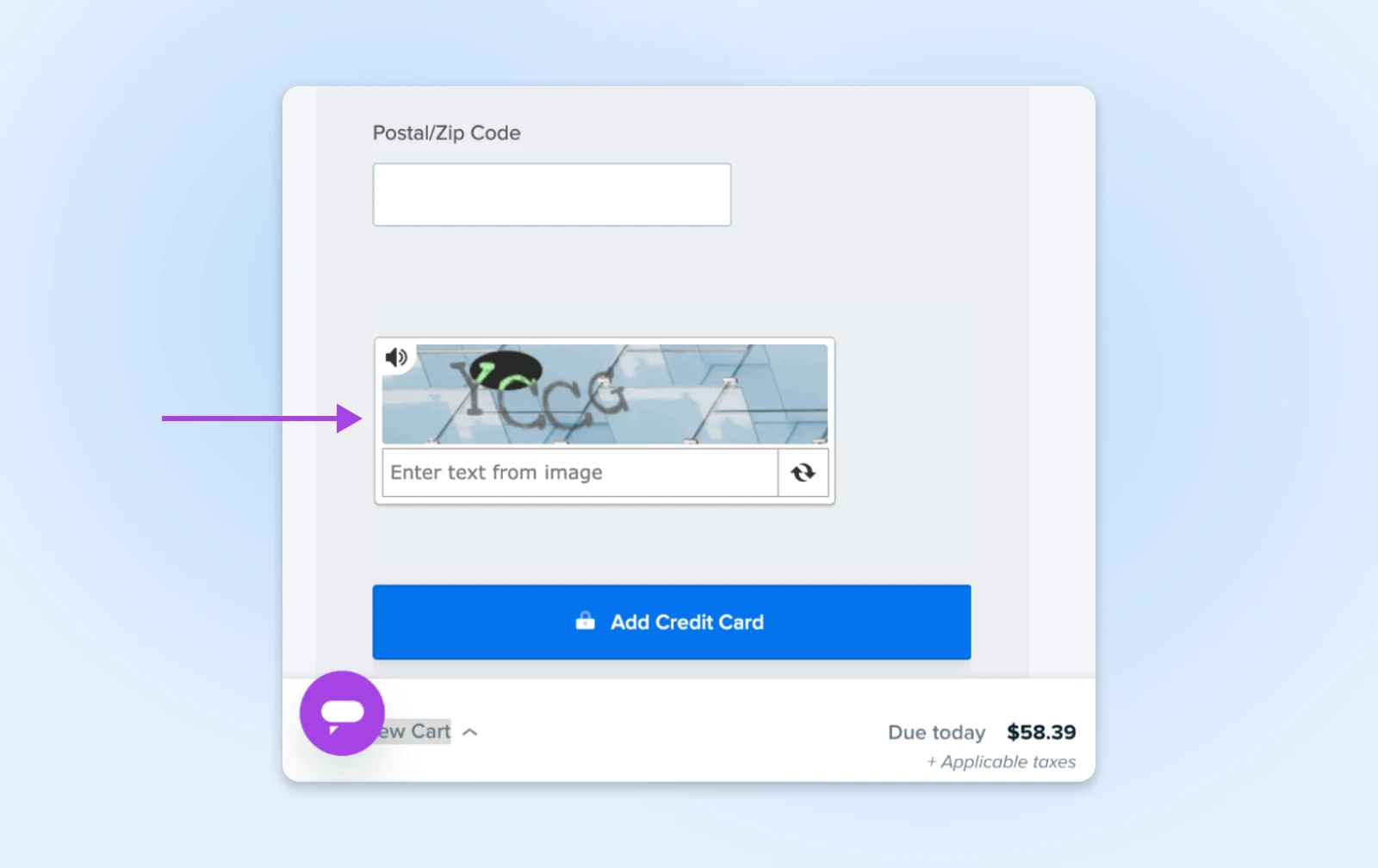
CAPTCHAs zijn die kleine puzzels die je vragen om verkeerslichten of fietsen te identificeren. Ze zijn vervelend voor mensen maar bijna onmogelijk voor de meeste bots, waardoor ze perfecte poortwachters zijn voor belangrijke delen van je site.
Hoe Te Implementeren
- Meld je aan voor Google’s reCAPTCHA (gratis) of hCaptcha.
- Voeg de CAPTCHA-code toe aan je gevoelige formulieren:
- Inlogpagina’s
- Contactformulieren
- Betaalprocessen
- Commentaarsecties
Voor WordPress-gebruikers kunnen plugins zoals Akismet dit automatisch afhandelen voor reacties en formulierinzendingen.
Professionele tip: Moderne onzichtbare CAPTCHA’s (zoals reCAPTCHA v3) werken achter de schermen voor de meeste bezoekers en tonen alleen uitdagingen aan verdachte gebruikers. Gebruik deze methode om bescherming te krijgen zonder legitieme klanten te irriteren.
5. Overweeg De Nieuwe llms.txt Standaard
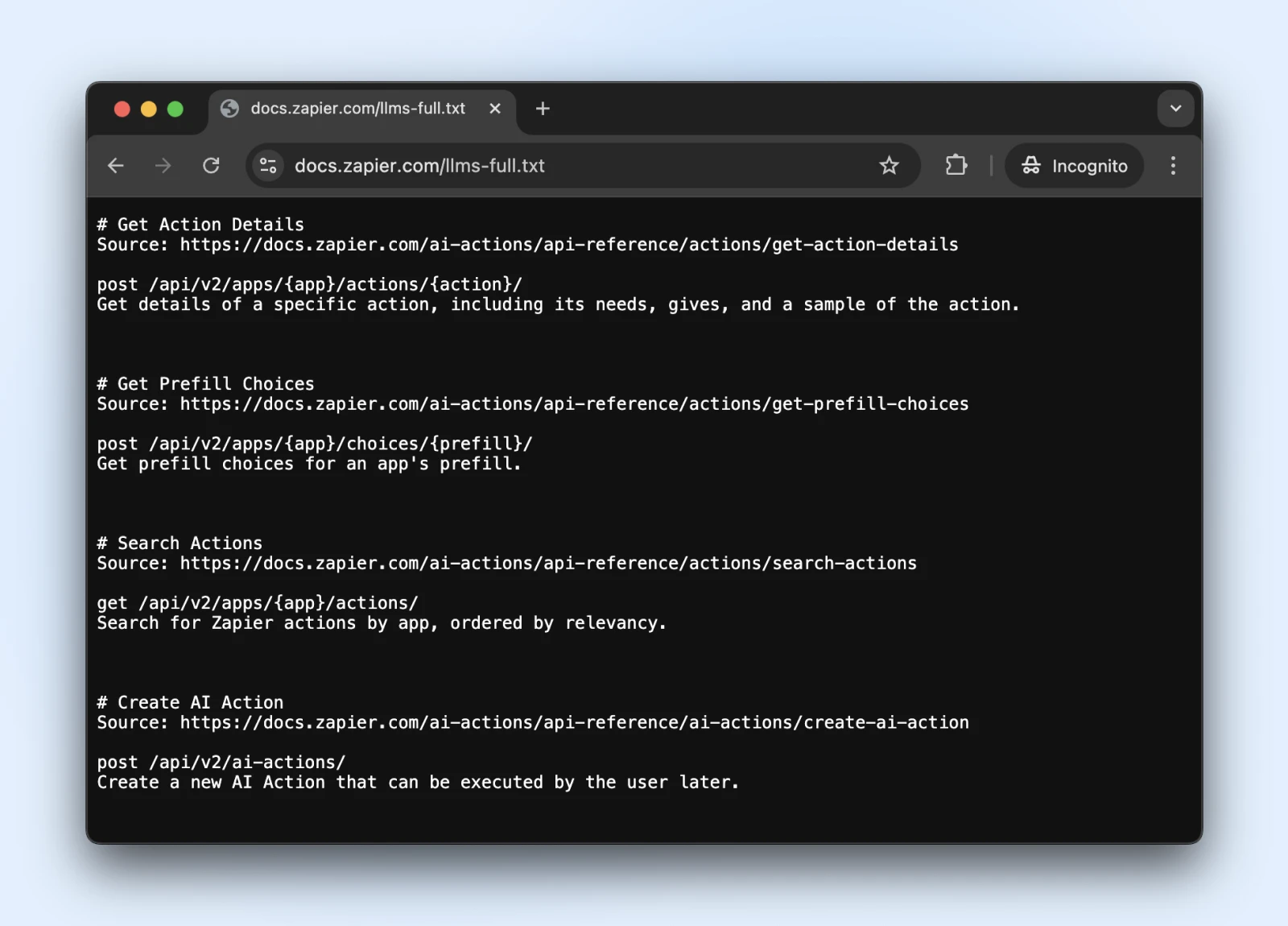
De llms.txt standaard is een recente ontwikkeling die beheert hoe AI webcrawlers interageren met jouw inhoud.
Het is vergelijkbaar met robots.txt, maar specifiek voor het vertellen aan AI-systemen welke informatie ze kunnen benaderen en wat ze moeten vermijden.
Hoe Te Implementeren
1. Maak een markdown-bestand genaamd llms.txt met deze inhoudsstructuur:
# Jouw Website Naam
> Korte beschrijving van je site
## Belangrijkste Inhoudsgebieden
- [Productpagina's](https://yoursite.com/products): Informatie over producten
- [Blogartikelen](https://yoursite.com/blog): Educatieve inhoud
## Beperkingen
- Gelieve onze prijsinformatie niet te gebruiken in training2. Upload het naar je root directory (op jouwdomein.com/llms.txt) → Neem contact op met een ontwikkelaar als je geen directe toegang tot de server hebt.
Is llms.txt de officiële standaard? Nog niet.
Het is een standaard voorgesteld eind 2024 door Jeremy Howard, die is overgenomen door Zapier, Stripe, Cloudflare, en vele andere grote bedrijven. Hier is een groeiende lijst van websites die llms.txt adopteren.
Dus, als je aan boord wilt springen, hebben ze officiële documentatie op GitHub met implementatierichtlijnen.
Professionele tip: Nadat het geïmplementeerd is, kijk of ChatGPT (met ingeschakelde webzoekfunctie) het llms.txt-bestand kan openen en begrijpen.

Controleer of het llms.txt-bestand toegankelijk is voor deze bots door ChatGPT (of een andere LLM) te vragen om “te controleren of je deze pagina kunt lezen” of “wat zegt de pagina”.
We kunnen niet weten of de bots llms.txt binnenkort zullen respecteren. Echter, als de AI-zoekfunctie het llms.txt-bestand nu kan lezen en begrijpen, kunnen ze het in de toekomst misschien ook gaan respecteren.
Monitoring En Onderhoud Van De Bot Bescherming Van Je Site
Dus je hebt je botverdedigingen ingesteld — geweldig werk!
Houd er rekening mee dat bottechnologie altijd in ontwikkeling is, wat betekent dat bots terugkomen met nieuwe trucs. Laten we ervoor zorgen dat jouw site op de lange termijn beschermd blijft.
- Plan Regelmatig Veiligheidscontroles: Kijk eens per maand naar je serverlogboeken voor iets verdachts en zorg ervoor dat je robots.txt en llms.txt bestanden bijgewerkt zijn met eventuele nieuwe paginalinks die je wilt dat de bots wel/niet bezoeken.
- Houd Je Bot Blokkeerlijst Actueel: Bots veranderen regelmatig van vermomming. Volg beveiligingsblogs (of laat je hostingprovider dit voor je doen) en werk je blokkeringsregels regelmatig bij.
- Let Op Je Snelheid: Botbescherming die je site vertraagt, doet je geen goed. Houd je paginalaadtijden in de gaten en stel je bescherming bij als dingen beginnen te vertragen. Onthoud, echte mensen zijn ongeduldige wezens!
- Overweeg Automatisering: Als dit allemaal te veel werk lijkt (we begrijpen het, je hebt een bedrijf te runnen!), kijk dan naar geautomatiseerde oplossingen of beheerde hosting die de beveiliging voor je regelt. Soms is de beste doe-het-zelf aanpak DIHV — Doe Het Voor Mij!
Een Website Zonder Bots Terwijl Je Slaapt? Ja, Graag!
Geef jezelf een schouderklopje. Je hebt hier veel voor elkaar gekregen!
Hoe dan ook, zelfs met onze stap-voor-stap begeleiding, kan dit spul behoorlijk technisch worden. (Wat is een .htaccess-bestand eigenlijk?)
En hoewel zelfbeheer van bots zeker mogelijk is, merk je misschien dat je tijd beter besteed kan worden aan het runnen van het bedrijf.
DreamCare is de “wij regelen het voor je” knop waar je naar op zoek bent.
Ons team houdt je site beschermd met:
- 24/7 monitoring die verdachte activiteiten opvangt terwijl je slaapt
- Regelmatige beveiligingscontroles om voor te blijven op opkomende bedreigingen
- Automatische software-updates die kwetsbaarheden dichten voordat bots ze kunnen uitbuiten
- Uitgebreide Malware-scanning en -verwijdering als er toch iets doorheen glipt
Zie, bots zijn hier om te blijven. En gezien hun toename in de afgelopen jaren, zouden we in de nabije toekomst meer bots dan mensen kunnen zien. Niemand weet het.
Maar, waarom er wakker van liggen?
Wij Regelen Het Technische Gedoe
Breng prestaties en betrouwbaarheid van ondernemingsniveau naar je website. Laat de backend aan de experts over – jij concentreert je op je bedrijf.
Zie MeerDeze pagina bevat affiliate links. Dit betekent dat we een commissie kunnen verdienen als je diensten koopt via onze link zonder extra kosten voor jou.

