
Linux è la colonna vertebrale di internet. Alimenta circa il 97% dei principali server web del mondo. E il 55,9% dei sviluppatori professionisti si affida a Linux per le loro esigenze di sviluppo.
Tuttavia, Linux possiede solo una quota di mercato dei desktop del 2.68%. Perché questa discrepanza?
Il focus principale di Linux non è mai stato la sua interfaccia utente. È stato invece progettato per darti il controllo completo sul tuo sistema operativo attraverso la riga di comando.
Questo può rendere Linux intimidatorio per i principianti — E le migliaia di comandi disponibili rendono tutto ciò ancora più difficile.
In questo articolo, copriamo i 100 comandi Linux più utili. Imparare anche solo una manciata di questi comandi può aiutarti a migliorare la tua produttività come utente Linux. Tuffiamoci subito!
Linux
Linux si riferisce a una collezione di Sistemi Operativi (OS) open-source. Non esiste un unico sistema operativo Linux. Invece, gli utenti possono scegliere tra un ampio gruppo di distribuzioni Linux, ognuna delle quali offre esperienze diverse.
Leggi Di PiùCosa Sono i Comandi Linux?
I comandi Linux ti permettono di controllare il tuo sistema dall’interfaccia a riga di comando (CLI) invece di usare il tuo mouse o trackpad. Sono istruzioni testuali inserite nel terminale per dire esattamente al tuo sistema cosa fare.
I comandi che inserisci nel terminale Linux sono sensibili al maiuscolo/minuscolo e seguono una sintassi come “command -options arguments.” Puoi combinarli per compiti complessi utilizzando pipeline e reindirizzamenti.
Alcune cose importanti da sapere sui comandi Linux:
- Sono sensibili alle maiuscole; per esempio, “
ls” e “LS” significano cose diverse. - Seguono una sintassi specifica come “
comando -opzioni argomenti.” - Possono essere combinati per operazioni complesse utilizzando pipeline e reindirizzamenti.
- Ti consentono un controllo dettagliato sul tuo sistema, che è difficile da ottenere con interfacce grafiche.
- Ti permettono di automatizzare compiti tramite script di shell e elaborazione batch.
- Possono essere usati per accedere a risorse di sistema come il file system, la rete, la memoria e la CPU.
- Costituiscono la base dell’interazione con server e sistemi operativi Linux.
Se sei un programmatore che sta imparando a programmare, puoi iniziare a praticare i tuoi comandi Linux senza lasciare Windows utilizzando il Subsystem Windows per Linux. Questo ti permette di eseguire Linux all’interno di Windows senza bisogno di dual boot e di ottenere il meglio di entrambi i sistemi operativi.
I 100 Comandi Linux Più Utili
Ora che hai una conoscenza di base di cosa sono i comandi Linux, immergiamoci nei 100 comandi Linux più usati.
Le abbiamo organizzate per categoria per coprire aree come gestione dei file, monitoraggio del sistema, operazioni di rete, amministrazione degli utenti e altro ancora.
Comandi Per La Gestione Dei File In Linux
La gestione dei file è un’attività comune sulla linea di comando Linux. Ecco alcuni comandi essenziali per i file:
1. ls – Elenca il Contenuto della Directory
Il comando ls è uno dei comandi Linux più usati frequentemente. Elenca i contenuti di una directory, mostrando tutti i file e le sottodirectory contenuti al suo interno.
Senza alcuna opzione o argomento, ls mostrerà il contenuto della directory di lavoro corrente. Puoi inserire un nome di percorso per elencare file e cartelle in quella posizione invece.
Sintassi:
ls [opzioni] [directory] |
Alcune delle opzioni di ls più utili includono:
-l– Mostra i risultati in formato lungo, visualizzando dettagli aggiuntivi come permessi, proprietà, dimensione e data di modifica per ogni file e directory.-a– Mostra file e directory nascosti che iniziano con . oltre agli elementi non nascosti.-R– Elenca ricorsivamente tutti i contenuti delle sottodirectory, scendendo indefinitamente nelle cartelle figlie.-S– Ordina i risultati per dimensione del file, dal più grande al più piccolo.-t– Ordina per marca temporale, dal più recente al più vecchio.
Esempio:
ls -l /home/user/documents |
Questo elencherà i contenuti della cartella “documents” in formato esteso.
Esempio di output:
totale 824-rwxrwx--- 1 utente utente 8389 Lug 12 08:53 report.pdf-rw-r--r-- 1 utente utente 10231 Giu 30 16:32 presentazione.pptxdrwxr-xr-x 2 utente utente 4096 Mag 11 09:21 immagini-rw-rw-r-- 1 utente utente 453 Apr 18 13:32 todo.txt |
Questo output mostra un elenco dettagliato con permessi, dimensione, proprietario e marca temporale per ogni file e directory. Il formato di elenco dettagliato fornito dall’opzione -l offre informazioni utili sui file a colpo d’occhio.
Il comando ls ti offre un controllo flessibile sulla visualizzazione del contenuto delle directory. È uno dei comandi che ti troverai a usare costantemente lavorando su Linux.
2. cd – Cambia Directory
Il comando cd viene utilizzato per navigare tra le directory. Ti permette di spostare la directory di lavoro corrente in una nuova posizione nel filesystem.
Quando esegui il comando cd da solo, verrai riportato alla directory principale. Puoi anche passare un percorso specifico per cambiarla. Ad esempio:
cd /usr/local– Passa alla directory /usr/local.cd ..– Sale di un livello alla directory genitore.cd ~/pictures– Passa alla cartella pictures nella tua directory home.
Sintassi:
cd [directory]
Esempio:
cd /home/user/documents
Questo cambierebbe la directory di lavoro nella cartella “documenti” sotto /home/user. Usare cd è essenziale per poter accedere e lavorare con i file in diverse località in modo conveniente.
3. mkdir – Crea Una Nuova Cartella
Il comando mkdir ti consente di creare una nuova cartella. Devi semplicemente passare il nome della directory da creare.
Sintassi:
mkdir [options] <directory>
Questo creerà una directory chiamata “newproject” nella directory di lavoro corrente.
Alcune opzioni utili di mkdir:
-p– Crea le directory genitori in modo ricorsivo secondo necessità.-v– Output dettagliato che mostra le directory create.
Esempio:
mkdir -v ~/project/code
Questo creerà la sottodirectory “code” sotto “project” nella cartella home dell’utente, con un output dettagliato che mostra la directory in fase di creazione.
4. rmdir – Rimuovi Directory
Per eliminare una directory vuota, usa il comando rmdir. Nota che rmdir può rimuovere solo directory vuote – avremo bisogno del comando rm per eliminare quelle non vuote.
Sintassi:
rmdir [opzioni] <directory>
Alcune opzioni per rmdir includono:
-v– Output dettagliato quando si eliminano le directory.-p– Rimuovi le directory principali in modo ricorsivo se necessario.
Esempio:
rmdir -v ~/project/code
Questo cancellerà la sottodirectory “code” sotto “project” mostrando un output dettagliato.
5. touch – Crea Un Nuovo File Vuoto
Il comando touch viene utilizzato per creare un nuovo file vuoto all’istante. Questo è utile quando hai bisogno di un file vuoto da popolare con dati in seguito.
La sintassi base di touch è:
touch [opzioni] nomefile
Alcune opzioni utili per touch includono:
-c– Non creare il file se esiste già. Questo evita la sovrascrittura accidentale dei file esistenti.-m– Invece di creare un nuovo file, aggiorna la marca temporale su un file esistente. Questo può essere usato per cambiare il tempo di modifica.
Per esempio:
touch /home/user/newfile.txt
Il comando sopra crea un nuovo file vuoto chiamato “newfile.txt” nella directory /home/user dell’utente. Se newfile.txt esiste già, aggiornerà invece i tempi di accesso e di modifica del file.
6. cp – Copia File E Directory
Il comando cp copia file o directory da una posizione a un’altra. Richiede l’inserimento di un percorso di origine e di una destinazione.
La sintassi di base di cp è:
cp [options] source destination
Alcune opzioni utili di cp:
-r– Copia le directory in modo ricorsivo, scendendo nelle sottodirectory per copiarne il contenuto. Necessario quando si copiano le directory.-i– Chiedi conferma prima di sovrascrivere qualsiasi file esistente nella destinazione. Impedisce di sovrascrivere accidentalmente i dati.-v– Mostra un output dettagliato che indica i dettagli di ogni file mentre viene copiato. Utile per confermare esattamente cosa è stato copiato.
Per esempio:
cp -r /home/user/documents /backups/
Questo copierebbe ricorsivamente la directory /home/user/documents e tutto il suo contenuto nella directory /backups/. L’opzione -r è necessaria per copiare le directory.
Il comando cp è uno degli strumenti di gestione dei file più utilizzati per copiare file e directory in Linux. Ti troverai a usare spesso questo comando.
7. mv – Sposta O Rinomina File E Directory
Il comando mv è utilizzato per spostare file o directory in una differente posizione o per rinominarli. A differenza della copia, i file del percorso di origine vengono eliminati dopo essere stati spostati nella destinazione.
Puoi anche usare il comando mv per rinominare i file dato che devi semplicemente modificare i percorsi di origine e destinazione con il vecchio e il nuovo nome.
La sintassi di mv è:
mv [opzioni] origine destinazione
Opzioni mv utili:
-i– Chiedi conferma prima di sovrascrivere qualsiasi file esistente nella destinazione. Ciò previene la sovrascrittura accidentale dei dati.-v– Genera un output dettagliato mostrando ogni file o directory mentre viene spostato. Questo è utile per confermare esattamente cosa è stato spostato.
Ad esempio:
mv ~/folder1 /tmp/folder1
Il comando sopra sposterà la cartella1 dalla directory home (~) alla directory /tmp/. Vediamo un altro esempio di utilizzo del comando mv per rinominare i file.
mv folder1 folder2
Qui, “folder1” viene rinominato in “folder2.”
8. rm – Rimuovi File E Directory
Il comando rm elimina file e directory. Usa cautela perché i file e le directory eliminati non possono essere recuperati.
La sintassi è:
rm [options] name
Opzioni rm utili:
-r– Elimina ricorsivamente le directory, inclusi tutti i contenuti al loro interno. Questo è necessario quando si eliminano le directory.-f– Forza l’eliminazione e sopprime tutti i messaggi di conferma. Questo comando è pericoloso, poiché i file non possono essere recuperati una volta eliminati!-i– Richiede conferma prima di eliminare ogni file o directory, offrendo sicurezza contro la rimozione accidentale.
Per esempio:
rm -rf temp
Questo elimina ricorsivamente la directory “temp” e tutti i suoi contenuti senza richiedere conferme (-f sovrascrive le conferme).
Nota: Il comando rm elimina in modo permanente file e cartelle, quindi usalo con estrema cautela. Se utilizzato con privilegi sudo, potresti anche eliminare completamente la directory root, e Linux non funzionerebbe più dopo il riavvio del computer.
9. find – Cerca File In Una Gerarchia Di Directory
Il comando find ricerca ricorsivamente nelle directory i file che corrispondono ai criteri specificati.
La sintassi di base di find è:
find [path] [criteria]
Alcune opzioni utili per criteri di ricerca includono:
-type f– Cerca solo file normali, escludendo le directory.-mtime +30– Cerca file modificati più di 30 giorni fa.-user jane– Cerca file appartenenti all’utente “jane”.
Per esempio:
find . -type f -mtime +30
Questo troverà tutti i file regolari più vecchi di 30 giorni nella directory corrente (indicata dal punto).
Il comando find permette di cercare file basandosi su varie condizioni avanzate come nome, dimensione, permessi, marca temporale, proprietà e altro.
10. du – Stima dell’Utilizzo dello Spazio dei File
Il comando du misura l’utilizzo dello spazio dei file per una determinata directory. Quando viene utilizzato senza opzioni, mostra l’utilizzo del disco per la directory di lavoro corrente.
La sintassi per du è:
du [opzioni] [percorso]
Opzioni utili di du:
-h– Mostra le dimensioni dei file in formato leggibile dall’uomo, come K per Kilobyte invece di un conteggio in byte. Molto più semplice da interpretare.-s– Mostra solo la dimensione totale di una directory, invece di elencare ogni sottodirectory e file. Utile per un riassunto.-a– Mostra le dimensioni di ogni file individualmente oltre ai totali. Aiuta a identificare i file di grandi dimensioni.
Per esempio:
du -sh pictures
Questo mostrerà una dimensione totale leggibile per la directory “pictures”.
Il comando du è utile per analizzare l’utilizzo del disco di un albero di directory e identificare i file che occupano eccessivo spazio.
Comandi di Ricerca e Filtro in Linux
Ora, esploriamo i comandi che ti permettono di cercare, filtrare e manipolare il testo direttamente dalla linea di comando Linux.
11. grep – Cerca Testo Utilizzando Modelli
Il comando grep è utilizzato per cercare schemi di testo all’interno di file o output. Stampa tutte le righe che corrispondono all’espressione regolare fornita. grep è estremamente potente per la ricerca, il filtraggio e il confronto di schemi in Linux.
Ecco la sintassi di base:
grep [options] pattern [files]
Per esempio:
grep -i "error" /var/log/syslog
Questa ricerca nel file syslog la parola “error,” ignorando la sensibilità al maiuscolo/minuscolo.
Alcune opzioni grep utili:
-i– Ignora le distinzioni tra maiuscole e minuscole nei modelli-R– Cerca ricorsivamente nelle sottodirectory-c– Stampa solo un conteggio delle righe corrispondenti-v– Inverti la corrispondenza, stampa le righe non corrispondenti
grep ti permette di cercare file e output per parole chiave o modelli rapidamente. È indispensabile per l’analisi dei log, la ricerca nel codice sorgente, l’abbinamento di espressioni regolari e l’estrazione di dati.
12. awk – Linguaggio di Scansione ed Elaborazione di Modelli
Il comando awk consente un’elaborazione del testo più avanzata basata su modelli e azioni specificati. Opera su base lineare, suddividendo ogni riga in campi.
La sintassi di awk è:
awk 'pattern { action }' input-file
Per esempio:
awk '/error/ {print $1}' /var/log/syslog
Questo stampa il primo campo di qualsiasi riga che contiene “errore”. awk può anche utilizzare variabili incorporate come NR (numero di record) e NF (numero di campi).
Le capacità avanzate di awk includono:
- Calcoli matematici sui campi
- Istruzioni condizionali
- Funzioni integrate per manipolare stringhe, numeri e date
- Controllo del formato di output
Questo rende awk adatto all’estrazione di dati, alla generazione di report e alla trasformazione dell’output di testo. awk è estremamente potente in quanto è un linguaggio di programmazione indipendente che ti offre molto controllo come comando Linux.
13. sed – Editor di Flusso per Filtrare e Trasformare Testo
Il comando sed consente il filtraggio e la trasformazione del testo. Può eseguire operazioni come ricerca/sostituzione, eliminazione, trasposizione e altro ancora. Tuttavia, a differenza di awk, sed è stato progettato per modificare le righe su base per linea secondo le istruzioni.
Ecco la sintassi di base:
sed options 'commands' input-file
Per esempio:
sed 's/foo/bar/' file.txt
Questo sostituisce “foo” con “bar” in file.txt.
Alcuni comandi sed utili:
s– Cerca e sostituisci testo/pattern/d– Elimina le righe che corrispondono a un modello10,20d– Elimina le righe 10-201,3!d– Elimina tutto tranne le righe 1-3
sed è ideale per compiti come la sostituzione massiva, l’eliminazione selettiva di linee e altre operazioni di modifica del flusso di testo.
14. sort – Ordina Le Righe Dei File Di Testo
Quando lavori con molto testo o dati o anche grandi output di altri comandi, ordinarli è un ottimo modo per rendere tutto gestibile. Il comando sort ordinerà le linee di un file di testo alfabeticamente o numericamente.
Sintassi di base per l’ordinamento:
sort [options] [file]
Opzioni di ordinamento utili:
-n– Ordina numericamente invece che alfabeticamente-r– Inverti l’ordine di ordinamento-k– Ordina in base a un campo o colonna specifica
Per esempio:
sort -n grades.txt
Questo ordina numericamente i contenuti di grades.txt. sort è utile per ordinare i contenuti dei file per un output più leggibile o per analisi.
15. uniq – Segnala O Ometti Linee Ripetute
Il comando uniq filtra le linee duplicate adiacenti dall’input. Questo è spesso usato in combinazione con sort.
Sintassi di base:
uniq [opzioni] [input]
Opzioni:
-c– Prefissa le linee uniche con il conteggio delle occorrenze.-d– Mostra solo le linee duplicate, non quelle uniche.
Per esempio:
sort data.txt | uniq
Questo rimuoverà qualsiasi riga duplicata in data.txt dopo il suo ordinamento. uniq ti offre il controllo sul filtro del testo ripetuto.
16. diff – Confronta File Riga Per Riga
Il comando diff confronta due file riga per riga e stampa le differenze. È comunemente usato per mostrare i cambiamenti tra versioni di file.
Sintassi:
diff [opzioni] file1 file2
Opzioni:
-b– Ignora le modifiche negli spazi bianchi.-B– Mostra le differenze in linea, evidenziando le modifiche.-u– Mostra le differenze con tre righe di contesto.
Per esempio:
diff original.txt updated.txt
Questo produrrà le linee che differiscono tra original.txt e updated.txt. diff è inestimabile per confrontare le revisioni di file di testo e codice sorgente.
17. wc – Stampa Conteggio Linee, Parole e Byte
Il comando wc (conteggio parole) stampa il conteggio di linee, parole e byte in un file.
Sintassi:
wc [opzioni] [file]
Opzioni:
-l– Stampa solo il conteggio delle righe.-w– Stampa solo il conteggio delle parole.-c– Stampa solo il conteggio dei byte.
Per esempio:
wc report.txt
Questo comando stamperà il numero di righe, parole e byte in report.txt.
Comandi Di Reindirizzamento In Linux
I comandi di reindirizzamento sono utilizzati per controllare le sorgenti di input e output in Linux, permettendoti di inviare e aggiungere flussi di output ai file, prendere input dai file, collegare più comandi e dividere l’output verso più destinazioni.
18. > – Reindirizza l’Output Standard
L’operatore > redirection reindirizza il flusso di output standard del comando a un file invece di stamparlo sul terminale. Qualsiasi contenuto esistente del file verrà sovrascritto.
Per esempio:
ls -l /home > homelist.txt
Questo eseguirà ls -l per elencare i contenuti della directory /home.
Allora, invece di stampare quell’output sul terminale, il simbolo > cattura quell’output standard e lo scrive su homelist.txt, sovrascrivendo qualsiasi contenuto del file esistente.
Reindirizzare l’output standard è utile per salvare i risultati dei comandi nei file per l’archiviazione, il debugging o per concatenare comandi insieme.
19. >> – Appendere l’Output Standard
L’operatore >> aggiunge l’output standard di un comando a un file senza sovrascrivere i contenuti esistenti.
Per esempio:
tail /var/log/syslog >> logfile.txt
Questo appenderà le ultime 10 righe del file di log syslog alla fine di logfile.txt. A differenza di >, >> aggiunge l’output senza cancellare il contenuto attuale di logfile.txt.
Aggiungere è utile per raccogliere l’output dei comandi in un unico posto senza perdere i dati esistenti.
20. < – Reindirizzamento dell’Input Standard
L’operatore di reindirizzamento < fornisce il contenuto di un file come input standard a un comando, invece di prendere l’input dalla tastiera.
Ad esempio:
wc -l < myfile.txt
Questo invia il contenuto di myfile.txt come input al comando wc, che conterà le linee in quel file invece di attendere l’input da tastiera.
Reindirizzare l’input è utile per l’elaborazione in batch di file e l’automazione dei flussi di lavoro.
21. | – Reindirizza L’Output a Un Altro Comando
L’operatore | invia l’output di un comando come input a un altro comando, concatenandoli insieme.
Per esempio:
ls -l | less
Questo comando indirizza l’output di ls -l al comando less, che permette di scorrere l’elenco dei file.
Il piping è comunemente utilizzato per concatenare comandi dove l’output di uno alimenta l’input di un altro. Questo permette di costruire operazioni complesse a partire da programmi singoli e specifici.
22. tee – Leggi Dall’Input Standard E Scrivi All’Output Standard E Ai File
Il comando tee divide l’input standard in due flussi.
Scrive l’input sull’output standard (mostra l’output del comando principale) salvando contemporaneamente una copia su un file.
Per esempio:
cat file.txt | tee copy.txt
Questo mostra i contenuti di file.txt nel terminale mentre li scrive contemporaneamente su copy.txt.
tee è diverso dal reindirizzamento, dove non vedi l’output fino a quando non apri il file a cui hai reindirizzato l’output.
Comandi per Archiviare
I comandi di archiviazione ti permettono di raggruppare più file e directory in file di archivio compressi per una migliore portabilità e conservazione. I formati di archivio comuni in Linux includono .tar, .gz e .zip.
23. tar – Archivia ed Estrai File da un Archivio
Il comando tar ti aiuta a lavorare con i file di archivio tape (.tar). Ti permette di raggruppare più file e directory in un unico file .tar compresso.
Sintassi:
tar [options] filename
Opzioni utili di tar:
-c– Crea un nuovo file di archivio .tar.-x– Estrai file da un archivio .tar.-f– Specifica il nome del file di archivio anziché stdin/stdout.-v– Output verboso che mostra i file archiviati.-z– Comprimi o decomprimi l’archivio con gzip.
Per esempio:
tar -cvzf images.tar.gz /home/user/images
Questo crea un archivio tar compresso in gzip chiamato images.tar.gz contenente la cartella /home/user/images.
24. gzip – Comprimi O Espandi File
Il comando gzip comprime i file usando la codifica LZ77 per ridurre le dimensioni per l’archiviazione o la trasmissione. Con gzip, lavori con file .gz.
Sintassi:
gzip [opzioni] nomefile
Opzioni gzip utili:
-c– Scrivi l’output su stdout invece che su file.-d– Decomprimi il file invece di comprimerlo.-r– Comprimi le directory ricorsivamente.
Per esempio:
gzip -cr documents/
Il comando sopra comprime ricorsivamente la cartella dei documenti e invia l’output a stdout.
25. gunzip – Decomprimi File
Il comando gunzip è utilizzato per decomprimere i file .gz.
Sintassi:
gunzip filename.gz
Esempio:
gunzip documents.tar.gz
Il comando sopra estrarrà il contenuto originale non compresso di documents.tar.gz.
26. zip – Pacchetto E Comprimi File
Il comando zip crea file archiviati .zip contenenti contenuti di file compressi.
Sintassi:
zip [options] archive.zip filenames
Opzioni utili per zip:
-r– Zip una directory ricorsivamente.-e– Cripta i contenuti con una password.
Esempio:
zip -re images.zip pictures
Questo cripta e comprime la cartella delle immagini in images.zip.
27. unzip – Estrai File Dagli Archivi ZIP
Simile a gunzip, il comando unzip estrae e decomprime i file dagli archivi .zip.
Sintassi:
unzip archive.zip
Esempio:
unzip images.zip
L’esempio sopra illustra un comando che estrae tutti i file da images.zip nella directory corrente.
Comandi di Trasferimento File
I comandi di trasferimento file ti permettono di spostare file tra sistemi attraverso una rete. Questo è utile per copiare file su server remoti o scaricare contenuti da internet.
28. scp – Copia Sicura dei File Tra Host
Il comando scp (secure copy) copia file tra host tramite una connessione SSH. Tutti i trasferimenti di dati sono criptati per la sicurezza.
La sintassi scp copia i file da un percorso sorgente a una destinazione definita come utente@host:
scp source user@host:destination
Per esempio:
scp image.jpg user@server:/uploads/
Questo copia in modo sicuro image.jpg nella cartella /uploads sul server come utente.
scp funziona come il comando cp ma per il trasferimento di file remoti. Utilizza SSH (Secure Shell) per il trasferimento dei dati, fornendo una crittografia per garantire che nessun dato sensibile, come le password, venga esposto sulla rete. L’autenticazione avviene tipicamente tramite chiavi SSH, anche se è possibile utilizzare anche le password. I file possono essere copiati sia verso che da host remoti.
29. rsync – Sincronizza File Tra Host
Lo strumento rsync sincronizza i file tra due posizioni minimizzando il trasferimento di dati usando la codifica delta. Questo rende più veloce la sincronizzazione di alberi di directory di grandi dimensioni.
La sintassi di rsync sincronizza la sorgente con la destinazione:
rsync [options] source destination
Per esempio:
rsync -ahv ~/documents user@server:/backups/
Il comando nell’esempio sopra sincronizza ricorsivamente la cartella dei documenti con server:/backups/, mostrando un output dettagliato e leggibile dall’uomo.
Opzioni rsync utili:
-a– La modalità Archivio sincronizza ricorsivamente e conserva permessi, tempi, ecc.-h– Output leggibile dall’uomo.-v– Output dettagliato.
rsync è ideale per sincronizzare file e cartelle con sistemi remoti e mantenere tutto decentrato, backuppato e sicuro.
30. sftp – Programma di Trasferimento File Sicuro
Il programma sftp offre trasferimenti di file interattivi tramite SSH, simile al classico FTP ma criptato. Può trasferire file verso e da sistemi remoti.
sftp si connette a un host e accetta comandi come:
sftp user@host
get remotefile localfile
put localfile remotefile
Questo recupera remotefile dal server e copia localfile sull’host remoto.
sftp dispone di una shell interattiva per navigare nei file system remoti, trasferire file e directory e gestire permessi e proprietà.
31. wget – Recupera File dal Web
Lo strumento wget scarica file tramite connessioni HTTP, HTTPS e FTP. È utile per recuperare risorse web direttamente dal terminale.
Per esempio:
wget https://example.com/file.iso
Questo scarica l’immagine file.iso dal server remoto.
Opzioni utili di wget:
-c– Riprendi download interrotto.-r– Scarica in modo ricorsivo.-O– Salva con nome file specifico.
wget è ideale per scriptare download automatici e specchiare siti web.
32. curl – Trasferimento Dati Da o Verso Un Server
Il comando curl trasferisce dati da o verso un server di rete utilizzando protocolli supportati. Questo include REST, HTTP, FTP e altro.
Ad esempio:
curl -L https://example.com
Il comando sopra riportato recupera dati dall’URL HTTPS e li visualizza.
Opzioni utili di curl:
-o– Scrivi l’output su file.-I– Mostra solo le intestazioni di risposta.-L– Segui i reindirizzamenti.
curl è progettato per trasferire dati attraverso le reti in modo programmato.
Comandi Permessi File
I comandi per i permessi dei file ti permettono di modificare i diritti di accesso per gli utenti. Questo include l’impostazione dei permessi di lettura/scrittura/esecuzione, la modifica della proprietà e le modalità di file predefinite.
33. chmod – Cambia Modalità File o Permessi di Accesso
Il comando chmod viene utilizzato per modificare i permessi di accesso o le modalità dei file e delle directory. Le modalità di permesso rappresentano chi può leggere, scrivere o eseguire il file.
Per esempio:
chmod 755 file.txt
Ci sono tre insiemi di permessi: proprietario, gruppo e pubblico. I permessi sono impostati utilizzando modalità numeriche da 0 a 7:
- 7 – leggi, scrivi ed esegui.
- 6 – leggi e scrivi.
- 4 – solo lettura.
- 0 – nessun permesso.
Questo imposta i permessi del proprietario a 7 (rwx), del gruppo a 5 (r-x) e del pubblico a 5 (r-x). Puoi anche fare riferimento a utenti e gruppi in modo simbolico:
chmod g+w file.txt
La sintassi g+w aggiunge il permesso di scrittura di gruppo al file.
Impostare le corrette autorizzazioni per file e directory è fondamentale per la sicurezza Linux e per il controllo degli accessi. chmod ti offre un controllo flessibile per configurare le autorizzazioni esattamente come necessario.
34. chown – Cambia Proprietario e Gruppo del File
Il comando chown cambia la proprietà di un file o di una directory. La proprietà ha due componenti: l’utente che ne è il proprietario e il gruppo a cui appartiene.
Per esempio:
chown john:developers file.txt
L’esempio di comando sopra imposterà l’utente proprietario su “john” e il gruppo proprietario su “developers”.
Solo l’account superutente root può utilizzare chown per cambiare i proprietari dei file. È usato per risolvere problemi di permesso modificando il proprietario e il gruppo come necessario.
35. umask – Imposta i Permessi Predefiniti dei File
Il comando umask controlla i permessi predefiniti assegnati ai file appena creati. Riceve in input una maschera ottale, che si sottrae da 666 per i file e 777 per le directory.
Per esempio:
umask 007
I nuovi file avranno come impostazione predefinita i permessi 750 invece di 666, e le nuove directory 700 invece di 777.
Impostare un umask ti permette di configurare i permessi di file predefiniti piuttosto che affidarti ai valori predefiniti del sistema. Il comando umask è utile per limitare i permessi sui nuovi file senza dipendere da qualcuno che intervenga manualmente per aggiungere restrizioni.
Comandi di Gestione dei Processi
Questi comandi ti permettono di visualizzare, monitorare e controllare i processi in esecuzione sul tuo sistema Linux. Ciò è utile per identificare l’uso delle risorse e interrompere i programmi che non funzionano correttamente.
36. ps – Riporta Uno Snapshot Dei Processi Attuali
Il comando ps mostra un’istantanea dei processi attualmente in esecuzione, inclusi il loro PID, TTY, stato, ora di avvio, ecc.
Per esempio:
ps aux
Questo mostra ogni processo in esecuzione come tutti gli utenti con dettagli aggiuntivi come l’uso della CPU e della memoria.
Alcune opzioni ps utili:
aux– Mostra i processi per tutti gli utenti--forest– Visualizza l’albero dei processi padre/figlio
ps ti offre visibilità su ciò che è attualmente in esecuzione sul tuo sistema.
37. top – Visualizza Processi Linux
Il comando top mostra le informazioni dei processi di Linux in tempo reale, inclusi PID, utente, percentuale di CPU, uso della memoria, tempo di attività e altro. A differenza di ps, aggiorna la visualizzazione dinamicamente per riflettere l’uso corrente.
Per esempio:
top -u mysql
Il comando sopra monitora i processi solamente per l’utente “mysql”. Risulta molto utile per identificare programmi che consumano molte risorse.
38. htop – Visualizzatore Interattivo di Processi
Il comando htop è un visualizzatore interattivo dei processi che sostituisce il comando top. Mostra i processi di sistema insieme ai grafici di utilizzo di CPU/memoria/swap, permette l’ordinamento per colonne, la terminazione di programmi e altro ancora.
Basta digitare htop nella riga di comando per visualizzare i tuoi processi.
htop presenta elementi dell’interfaccia utente migliorati con colori, scorrimento e supporto al mouse per una navigazione più semplice rispetto a top. Ottimo per investigare sui processi.
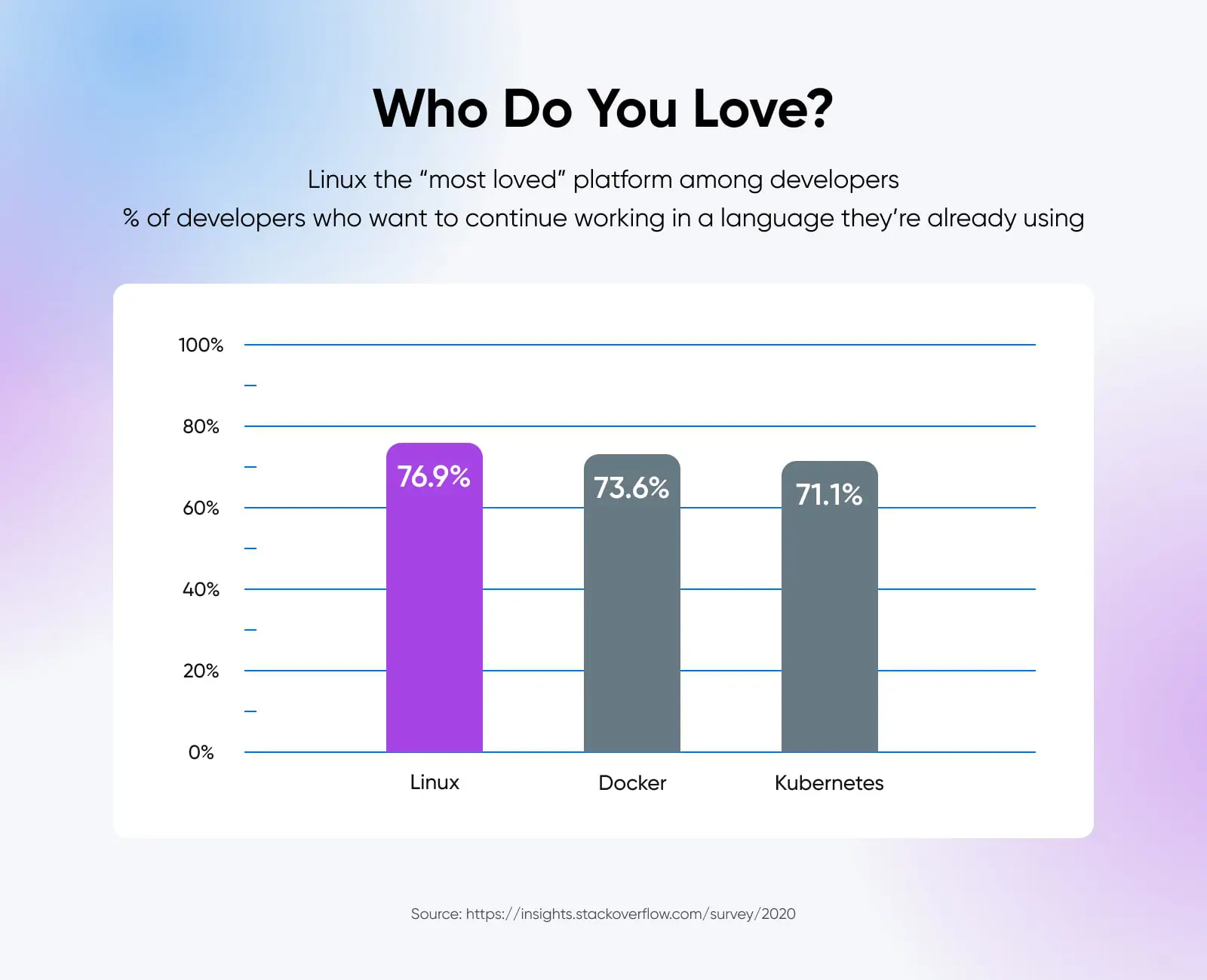
39. kill – Invia Un Segnale A Un Processo
Il comando kill invia un segnale a un processo per terminarlo o eliminarlo. I segnali permettono una chiusura elegante se il processo li gestisce.
Per esempio:
kill -15 12345
Il comando sopra invia il segnale SIGTERM (15) per fermare in modo ordinato il processo con PID 12345.
40. pkill – Invia Un Segnale A Un Processo Basato Sul Nome
Il comando pkill termina i processi per nome invece che per PID. Può semplificare le cose rispetto al trovare prima il PID.
Per esempio:
pkill -9 firefox
Questo ferma forzatamente tutti i processi di Firefox con SIGKILL (9). pkill individua i processi corrispondendo il nome, l’utente e altri criteri invece del PID.
41. nohup – Esegui Un Comando Immune Ai Blocchi
Il comando nohup esegue processi immuni a interruzioni, quindi continuano a funzionare se ti disconnetti o perdi la connessione.
Per esempio:
nohup python script.py &
L’esempio di comando sopra avvierà script.py in background e immune a interruzioni. nohup è generalmente utilizzato per avviare demoni e servizi persistenti in background.
Comandi di Monitoraggio delle Prestazioni
Questi comandi forniscono preziose statistiche sulle prestazioni del sistema per aiutare ad analizzare l’utilizzo delle risorse, identificare i colli di bottiglia e ottimizzare l’efficienza.
42. vmstat – Rapporto Delle Statistiche Della Memoria Virtuale
Il comando vmstat stampa rapporti dettagliati su memoria, swap, I/O e attività della CPU. Questo include metriche come memoria utilizzata/libera, swap in/out, blocchi di disco letti/scritti e tempo di CPU impiegato in processi/inattività.
Per esempio:
vmstat 5
Altre opzioni utili di vmstat:
-a– Mostra memoria attiva e inattiva-s– Visualizza contatori di eventi e statistiche di memoria-S– Esito in KB invece di blocchi5– Aggiornamento ogni 5 secondi.
L’esempio sopra mostra i dati della memoria e della CPU ogni 5 secondi fino all’interruzione, il che è utile per monitorare le prestazioni del sistema in tempo reale.
43. iostat – Rapporto Statistiche CPU E I/O
Il comando iostat monitora e visualizza l’utilizzo della CPU e le metriche di I/O del disco. Ciò include il carico della CPU, IOPS, la velocità di lettura/scrittura e altro ancora.
Per esempio:
iostat -d -p sda 5
Alcune opzioni di iostat:
-c– Mostra informazioni sull’utilizzo della CPU-t– Stampa la marca temporale per ogni rapporto-x– Mostra statistiche estese come tempi di servizio e conteggi di attesa-d– Mostra statistiche dettagliate per disco/partizione invece dei totali aggregati-p– Visualizza le statistiche per specifici dispositivi di disco
Questo mostra statistiche dettagliate I/O per dispositivo per sda ogni 5 secondi.
iostat aiuta ad analizzare le prestazioni del sottosistema del disco e a identificare i colli di bottiglia hardware.
44. free – Visualizza la Quantità di Memoria Libera e Usata
Il comando free mostra il totale, l’usato e la quantità libera di memoria fisica e di swap nel sistema. Questo fornisce una panoramica della memoria disponibile.
Per esempio:
free -h
Alcune opzioni per il comando gratuito:
-b– Mostra il risultato in byte-k– Mostra il risultato in KB invece che in byte predefiniti-m– Mostra il risultato in MB invece di byte-h– Stampa le statistiche in un formato leggibile come GB, MB invece di byte.
Questo stampa le statistiche della memoria in formato leggibile (GB, MB, ecc.). È utile quando desideri una panoramica rapida della capacità di memoria.
45. df – Report Utilizzo Spazio su Disco del File System
Il comando df mostra l’utilizzo dello spazio su disco per i file system. Indica il nome del filesystem, lo spazio totale/usato/disponibile e la capacità.
Per esempio:
df -h
Il comando sopra mostrerà l’utilizzo del disco in un formato leggibile dall’umano. Puoi anche eseguirlo senza argomenti per ottenere gli stessi dati in dimensioni di blocchi.
46. sar – Raccogliere e Riportare l’Attività del Sistema
Lo strumento sar raccoglie e registra informazioni sull’attività del sistema relative a CPU, memoria, I/O, rete e altro nel tempo. Questi dati possono essere analizzati per identificare problemi di prestazioni.
Per esempio:
sar -u 5 60
Questo campione l’utilizzo della CPU ogni 5 secondi per una durata di 60 campioni.
sar fornisce dati dettagliati sulle prestazioni storiche del sistema non disponibili negli strumenti in tempo reale.
Comandi di Gestione degli Utenti
Quando utilizzi sistemi multiutente, potresti aver bisogno di comandi che ti aiutino a gestire utenti e gruppi per il controllo degli accessi e le autorizzazioni. Copriamo qui quei comandi.
47. useradd – Crea Un Nuovo Utente
Il comando useradd crea un nuovo account utente e directory home. Imposta l’UID, il gruppo, la shell e altri valori predefiniti del nuovo utente.
Per esempio:
useradd -m john
Opzioni utili di useradd:
-m– Crea la directory home dell’utente.-g– Specifica il gruppo primario invece del predefinito.-s– Imposta la shell di login dell’utente.
Il comando sopra creerà un nuovo utente, “john,” con un UID generato e una cartella home creata in /home/john.
48. usermod – Modifica Un Account Utente
Il comando usermod modifica le impostazioni di un account utente esistente. Questo può cambiare il nome utente, la directory home, la shell, il gruppo, la data di scadenza, ecc.
Per esempio:
usermod -aG developers john
Con questo comando, aggiungi un utente john a un gruppo aggiuntivo—“developers.” L’opzione -a aggiunge agli elenchi esistenti di gruppi ai quali l’utente viene inserito.
49. userdel – Elimina Un Account Utente
Il comando userdel elimina un account utente, la directory home e lo spool della posta.
Per esempio:
userdel -rf john
Opzioni utili di userdel:
-r– Rimuovi la directory home dell’utente e la casella di posta.-f– Forza l’eliminazione anche se l’utente è ancora connesso.
Questo forza la rimozione dell’utente “john,” eliminando i file associati.
Specificare opzioni come -r e -f con userdel garantisce che l’account utente sia completamente eliminato anche se l’utente è loggato o ha processi attivi.
50. groupadd – Aggiungi Un Gruppo
Il comando groupadd crea un nuovo gruppo di utenti. I gruppi rappresentano squadre o ruoli per scopi di permessi.
Per esempio:
groupadd -r sysadmin
Opzioni utili di groupadd:
-r– Crea un gruppo di sistema utilizzato per le funzioni di sistema principali.-g– Specifica il GID del nuovo gruppo invece di utilizzare il successivo disponibile.
Il comando sopra crea un nuovo gruppo “sysadmin” con privilegi di sistema. Quando crei nuovi gruppi, l’-r o l’-g aiutano a configurarli correttamente.
51. passwd – Aggiorna i Token di Autenticazione dell’Utente
Il comando passwd imposta o aggiorna la password/tokens di autenticazione di un utente. Questo consente di cambiare la tua password di accesso.
Per esempio:
passwd john
Questo invita l’utente “john” a inserire una nuova password in modo interattivo. Se hai perso la password di un account, potresti voler accedere a Linux con privilegi sudo o su e cambiare la password utilizzando lo stesso metodo.
Comandi di Rete
Questi comandi sono utilizzati per monitorare le connessioni, risolvere problemi di rete, instradamento, ricerche DNS e configurazione dell’interfaccia.
52. ping – Invia ICMP ECHO_REQUEST agli Host di Rete
Il comando ping verifica la connettività a un host remoto inviando pacchetti di richiesta echo ICMP e ascoltando le risposte echo.
Per esempio:
ping google.comPING google.com (142.251.42.78): 56 byte di dati64 byte da 142.251.42.78: icmp_seq=0 ttl=112 tempo=8.590 ms64 byte da 142.251.42.78: icmp_seq=1 ttl=112 tempo=12.486 ms64 byte da 142.251.42.78: icmp_seq=2 ttl=112 tempo=12.085 ms64 byte da 142.251.42.78: icmp_seq=3 ttl=112 tempo=10.866 ms--- statistiche ping google.com ---4 pacchetti trasmessi, 4 pacchetti ricevuti, perdita 0.0% dei pacchettiandata e ritorno min/media/max/dev.std = 8.590/11.007/12.486/1.518 ms
Opzioni ping utili:
-c [count]– Limita i pacchetti inviati.-i [interval]– Attendi intervallo secondi tra i ping.
Con il comando sopra, fai un ping a google.com e visualizzi le statistiche di andata e ritorno che indicano connettività e latenza. Generalmente, ping è utilizzato per verificare se un sistema a cui stai cercando di connetterti è attivo e connesso alla rete.
53. ifconfig – Configura Interfacce di Rete
Il comando ifconfig visualizza e configura le impostazioni dell’interfaccia di rete, inclusi indirizzo IP, netmask, broadcast, MTU e indirizzo MAC hardware.
Ad esempio:
ifconfigeth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 10.0.2.15 netmask 255.255.255.0 broadcast 10.0.2.255inet6 fe80::a00:27ff:fe1e:ef1d prefixlen 64 scopeid 0x20<link>ether 08:00:27:1e:ef:1d txqueuelen 1000 (Ethernet)RX packets 23955654 bytes 16426961213 (15.3 GiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 12432322 bytes 8710937057 (8.1 GiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Eseguendo ifconfig senza altri argomenti otterrai un elenco di tutte le interfacce di rete disponibili per l’uso, insieme a IP e ulteriori informazioni di rete. ifconfig può anche essere utilizzato per impostare indirizzi, abilitare/disabilitare interfacce e modificare opzioni.
54. netstat – Statistiche di Rete
Il comando netstat ti mostra le connessioni di rete, le tabelle di routing, le statistiche delle interfacce, le connessioni mascherate e le appartenenze multicast.
Per esempio:
netstat -pt tcp
Questo comando mostrerà tutte le connessioni TCP attive e i processi che le utilizzano.
55. ss – Statistiche dei Socket
Il comando ss fornisce informazioni statistiche sui socket simili a netstat. Può mostrare socket TCP e UDP aperti, dimensioni dei buffer di invio/ricezione, e altro ancora.
Per esempio:
ss -t -a
Questo stampa tutte le socket TCP aperte. Più efficiente di netstat.
56. Traceroute – Traccia Percorso Verso Host
Il comando traceroute mostra il percorso che i pacchetti prendono verso un host di rete, evidenziando ogni tappa lungo il cammino e i tempi di transito. Utile per il debug della rete.
Per esempio:
traceroute google.com
Questo traccia il percorso per raggiungere google.com e mostra ogni salto di rete.
57. dig - Ricerca DNS
Il comando dig esegue ricerche DNS e restituisce informazioni sui record DNS di un dominio.
Ad esempio:
dig google.com; <<>> DiG 9.10.6 <<>> google.com;; opzioni globali: +cmd;; Risposta ricevuta:;; ->>HEADER<<- opcode: QUERY, stato: NOERROR, id: 60290;; flag: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1;; SEZIONE PSEUDO-OPT:; EDNS: versione: 0, flag:; udp: 1280;; SEZIONE DOMANDE:;google.com. IN A;; SEZIONE RISPOSTE:google.com. 220 IN A 142.251.42.78;; Tempo di interrogazione: 6 msec;; SERVER: 2405:201:2:e17b::c0a8:1d01#53(2405:201:2:e17b::c0a8:1d01);; QUANDO: Mer Nov 15 01:36:16 IST 2023;; DIMENSIONE MSG ricevuta: 55
Questa query interroga i server DNS per i record relativi a google.com e ne stampa i dettagli.
58. nslookup – Interroga Interattivamente i Server dei Nomi Internet
Il comando nslookup interroga i server DNS interattivamente per eseguire ricerche di risoluzione dei nomi o visualizzare i record DNS.
Entra in una shell interattiva, permettendoti di cercare manualmente hostname, invertire gli indirizzi IP, trovare tipi di record DNS e altro ancora.
Per esempio, alcuni utilizzi comuni di nslookup. Digita nslookup sulla tua riga di comando:
nslookup
In seguito, imposteremo il server DNS di Google 8.8.8.8 per le ricerche.
> server 8.8.8.8
Ora, interroghiamo il record A di stackoverflow.com per trovare il suo indirizzo IP.
> set type=A> stackoverflow.comServer: 8.8.8.8Indirizzo: 8.8.8.8#53Risposta non autorevole:Nome: stackoverflow.comIndirizzo: 104.18.32.7Nome: stackoverflow.comIndirizzo: 172.64.155.249
Ora, troviamo i record MX per github.com per vedere i suoi server di posta.
> set type=MX> github.comServer: 8.8.8.8Address: 8.8.8.8#53Risposta non autorevole:github.com scambio di posta = 1 aspmx.l.google.com.github.com scambio di posta = 5 alt1.aspmx.l.google.com.github.com scambio di posta = 5 alt2.aspmx.l.google.com.github.com scambio di posta = 10 alt3.aspmx.l.google.com.github.com scambio di posta = 10 alt4.aspmx.l.google.com.
Le query interattive rendono nslookup molto utile per esplorare il DNS e risolvere i problemi di risoluzione dei nomi.
59. iptables – Filtraggio dei pacchetti IPv4 e NAT
Il comando iptables consente di configurare le regole del firewall netfilter di Linux per filtrare ed elaborare i pacchetti di rete. Stabilisce politiche e regole su come il sistema gestirà i diversi tipi di connessioni in entrata e in uscita e il traffico.
Per esempio:
iptables -A INPUT -s 192.168.1.10 -j DROP
Il comando sopra bloccherà tutti gli input dall’IP 192.168.1.10.
iptables offre un controllo potente sul firewall del kernel Linux per gestire il routing, NAT, filtraggio dei pacchetti e altre forme di controllo del traffico. È uno strumento fondamentale per la sicurezza dei server Linux.
60. ip – Gestisci Dispositivi di Rete e Routing
Il comando ip consente di gestire e monitorare varie attività relative ai dispositivi di rete come l’assegnazione di indirizzi IP, la configurazione di sottoreti, la visualizzazione dei dettagli dei collegamenti e la configurazione delle opzioni di routing.
Per esempio:
ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000link/ether 08:00:27:8a:5c:04 brd ff:ff:ff:ff:ff:ff
Il comando sopra mostra tutte le interfacce di rete, il loro stato e altre informazioni.
Questo comando ha lo scopo di sostituire ifconfig con una gestione della rete Linux più moderna. ip può controllare dispositivi di rete, tabelle di routing e altre impostazioni dello stack di rete.
Comandi di Gestione dei Pacchetti
I gestori di pacchetti consentono una facile installazione, aggiornamento e rimozione del software sulle distribuzioni Linux. I gestori di pacchetti popolari includono APT, YUM, DNF, Pacman e Zypper.
61. apt – Gestore di Pacchetti Debian/Ubuntu
Il comando apt gestisce i pacchetti nei sistemi Debian/Ubuntu utilizzando il repository APT. Permette di installare, aggiornare e rimuovere i pacchetti.
Per esempio:
apt update
Questo comando recupera le ultime versioni dei pacchetti e i metadati dai repository.
apt install nginx
Puoi installare il pacchetto nginx dai repository APT configurati utilizzando il comando sopra.
apt upgrade
E questo comando aggiorna i pacchetti e le dipendenze alle versioni più recenti.
APT rende facile l’installazione del software recuperando i pacchetti dai repository.
62. pacman – Gestore di Pacchetti di Arch Linux
pacman gestisce i pacchetti su Arch Linux dall’Arch User Repository. Può installare, aggiornare e rimuovere pacchetti.
Per esempio:
pacman -S nmap
Questo installa il pacchetto nmap dai repository configurati.
pacman -Syu
Questo sincronizza con i repository e aggiorna tutti i pacchetti.
pacman mantiene Arch Linux aggiornato e permette una facile gestione dei pacchetti.
63. dnf – Gestore di Pacchetti Fedora
dnf installa, aggiorna e rimuove pacchetti nelle distribuzioni Linux Fedora utilizzando pacchetti RPM. Sostituisce Yum come gestore di pacchetti di nuova generazione.
Per esempio:
dnf install util-linux
Questo installa il pacchetto util-linux.
dnf upgrade
Questo aggiorna tutti i pacchetti installati alle ultime versioni.
dnf rende la gestione dei pacchetti di Fedora veloce ed efficiente.
64. yum – Gestore di Pacchetti Red Hat
yum gestisce i pacchetti sulle distribuzioni Linux RHEL e CentOS utilizzando pacchetti RPM. Preleva dai repository Yum per installare e aggiornare.
Per esempio:
yum update
Questo aggiorna tutti i pacchetti installati alle versioni più recenti.
yum install httpd
Il comando sopra installa il pacchetto Apache httpd. yum è stato il principale gestore di pacchetti per mantenere aggiornate le distribuzioni Red Hat.
65. zypper – Gestore dei Pacchetti OpenSUSE
zypper gestisce i pacchetti su Linux SUSE/openSUSE. Può aggiungere repository, cercare, installare e aggiornare pacchetti.
Per esempio:
zypper refresh
Il comando di aggiornamento per zypper aggiorna i metadati del repository dai repository aggiunti.
zypper install python
Questo installa il pacchetto Python dai repository configurati. zypper rende l’esperienza di gestione dei pacchetti senza sforzo sui sistemi SUSE/openSUSE.
66. flatpak – Gestore di pacchetti di applicazioni Flatpak
Il comando flatpak ti aiuta a gestire le applicazioni e gli ambienti di esecuzione Flatpak. flatpak permette la distribuzione di applicazioni desktop isolate su Linux.
Per esempio:
flatpak install flathub org.libreoffice.LibreOffice
Ad esempio, il comando sopra installerà LibreOffice dal repository Flathub.
flatpak run org.libreoffice.LibreOffice
E questa avvia l’applicazione LibreOffice Flatpak in sandbox. flatpak offre un repository di applicazioni Linux centralizzato e inter-distribuzioni, quindi non sei più limitato ai pacchetti disponibili con la libreria di pacchetti di una specifica distribuzione.
67. appimage – Gestore di Pacchetti di Applicazioni AppImage
I pacchetti AppImage sono applicazioni autonome che funzionano sulla maggior parte delle distribuzioni Linux. Il comando appimage esegue gli AppImage esistenti.
Per esempio:
chmod +x myapp.AppImage./myapp.AppImage
Questo consente di eseguire direttamente il file binario AppImage.
AppImages permettono il dispiegamento delle applicazioni senza installazione su tutto il sistema. Pensale come piccoli contenitori che includono tutti i file necessari per far funzionare l’app senza troppe dipendenze esterne.
68. snap – Gestore di Pacchetti di Applicazioni Snappy
Il comando snap gestisce gli snap—pacchetti software contenitizzati. Gli snap si aggiornano automaticamente e funzionano su distribuzioni Linux similmente a Flatpak.
Ad esempio:
snap install vlc
Questo semplice comando installa lo snap del media player VLC.
snap run vlc
Una volta installato, puoi utilizzare snap per eseguire pacchetti installati tramite snap usando il comando sopra. Gli snap isolano le app dal sistema di base per la portabilità e consentono installazioni più pulite.
Comandi Informazioni di Sistema
Questi comandi ti permettono di visualizzare dettagli riguardo l’hardware del tuo sistema Linux, il kernel, le distribuzioni, l’hostname, l’uptime e altro ancora.
69. uname – Stampa Informazioni di Sistema
Il comando uname stampa informazioni dettagliate sul kernel del sistema Linux, l’architettura hardware, l’hostname e il sistema operativo. Questo include i numeri di versione e le informazioni sulla macchina.
Per esempio:
uname -aLinux hostname 5.4.0-48-generic x86_64 GNU/Linux
uname è utile per interrogare questi dettagli del sistema principale. Alcune opzioni includono:
-a– Stampa tutte le informazioni di sistema disponibili-r– Stampa solo il numero di rilascio del kernel
Il comando sopra ha stampato informazioni estese sul sistema, incluse nome/versione del kernel, architettura hardware, hostname e sistema operativo.
uname -r
Questo stamperà solo il numero di release del kernel. Il comando uname mostra dettagli sui componenti principali del tuo sistema Linux.
70. Hostname – Mostra O Imposta Il Nome Host Del Sistema
Il comando hostname stampa o imposta l’identificatore di nome host per il tuo sistema Linux sulla rete. Senza argomenti mostra il nome host corrente. Passando un nome aggiornerà il nome host.
Per esempio:
hostnamelinuxserver
Questo stampa linuxserver — il nome host di sistema configurato.
hostname UbuntuServer
hostnames identificano i sistemi su una rete. hostname ottiene o configura il nome identificativo del tuo sistema sulla rete. Il secondo comando ti aiuta a cambiare il nome host locale in UbuntuServer.
71. Uptime – Da Quanto Tempo Il Sistema È In Funzione
Il comando uptime mostra da quanto tempo il sistema Linux è in funzione dall’ultimo riavvio. Visualizza l’uptime e l’ora corrente.
Esegui semplicemente il seguente comando per ottenere i dati di uptime del tuo sistema:
uptime23:51:26 up 2 giorni, 4:12, 1 utente, carico medio: 0.00, 0.01, 0.05
Questo stampa l’uptime del sistema mostrando da quanto tempo il sistema è acceso dall’ultimo avvio.
72. whoami – Stampa ID Utente Attivo
Il comando whoami mostra il nome utente effettivo dell’utente attualmente connesso al sistema. Visualizza il livello di privilegio con cui stai operando.
Digita il comando nel tuo terminale per ottenere l’ID:
whoamijohn
Questo stampa il nome utente effettivo con cui l’utente attuale è loggato e sta operando, ed è utile negli script o nelle diagnostiche per identificare quale account utente sta eseguendo le azioni.
73. id – Stampa gli ID Utente e Gruppo Reali ed Effettivi
Il comando id stampa informazioni dettagliate su utente e gruppo riguardanti gli ID effettivi e i nomi dell’utente corrente. Questo include:
- ID e nome dell’utente reale.
- ID e nome dell’utente effettivo.
- ID e nome del gruppo reale.
- ID e nome del gruppo effettivo.
Per usare il comando id, digita semplicemente:
iduid=1000(john) gid=1000(john) groups=1000(john),10(wheel),998(developers)
Il comando id stampa gli ID utente e gruppo reali ed effettivi dell’utente corrente. id mostra dettagli su utente e gruppo utili per determinare i permessi di accesso ai file.
74. lscpu – Mostra Informazioni Sull’Architettura della CPU
Il comando lscpu mostra informazioni dettagliate sull’architettura della CPU, inclusi:
- Numero di core della CPU
- Numero di socket
- Nome del modello
- Dimensioni della Cache
- Frequenza della CPU
- Dimensioni degli indirizzi
Per utilizzare il comando lscpu, digita semplicemente:
lscpuArchitettura: x86_64Modalità operativa CPU: 32-bit, 64-bitOrdine dei byte: Little EndianCPU: 16Elenco CPU online: 0-15
lscpu fornisce dettagli sull’architettura della CPU come il numero di core, socket, nome del modello, cache e altro ancora.
75. lsblk – Elenco dei Dispositivi a Blocchi
Il comando lsblk elenca informazioni su tutti i dispositivi a blocchi disponibili, inclusi dischi locali, partizioni e volumi logici. L’output include nomi dei dispositivi, etichette, dimensioni e punti di montaggio.
lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 1.8T 0 disk|-sda1 8:1 0 512M 0 part /boot|-sda2 8:2 0 16M 0 part`-sda5 8:5 0 1.8T 0 part`-lvm1 254:0 0 1.8T 0 lvm /
lsblk elenca tutti i dispositivi di blocco, inclusi dischi, partizioni e volumi logici. Offre una panoramica dei dispositivi di archiviazione.
76. lsmod – Mostra Lo Stato dei Moduli Nel Kernel Linux
Il comando lsmod visualizza i moduli del kernel attualmente caricati, come i driver di dispositivo. Questo include moduli di networking, archiviazione e altri moduli hardware utilizzati dal kernel Linux per interfacciarsi con dispositivi interni ed esterni.
lsmodModulo Grandezza Usato daipv6 406206 27evdev 17700 0crct10dif_pclmul 16384 1crc32_pclmul 16384 0ghash_clmulni_intel 16384 0aesni_intel 399871 0aes_x86_64 20274 1 aesni_intel
Come puoi vedere, elenca i moduli del kernel attualmente caricati come i driver di dispositivo. In questo caso, mostra l’utilizzo di moduli di networking, input, crittografia e cifratura.
77. dmesg – Stampa o Controlla il Buffer Circolare del Kernel
Il comando dmesg scarica i messaggi dal buffer circolare del kernel. Questo include eventi di sistema essenziali registrati dal kernel durante l’avvio e il funzionamento.
dmesg | grep -i error[ 12.345678] Errore nella ricezione della risposta della lettura batch: -110[ 23.456789] tplink_mdio 0000:03:00.0: Caricamento diretto del firmware per tplink-mdio/leap_p8_v1_0.bin fallito con errore -2[ 40.567890] iwlwifi 0000:09:00.0: Caricamento diretto del firmware per iwlwifi-ty-a0-gf-a0-59.ucode fallito con errore -2
La ricerca di “error” mostra problemi nel caricamento del firmware specifico. Questo stampa i messaggi di log del kernel memorizzati nel buffer, inclusi eventi di sistema come l’avvio, errori, avvisi ecc.
Comandi di Amministrazione del Sistema
I comandi di amministrazione del sistema ti aiutano a eseguire programmi come altri utenti, spegnere o riavviare il sistema, e gestire sistemi di init e servizi.
78. sudo – Esegui Un Comando Come Un Altro Utente
Il comando sudo ti permette di eseguire comandi come un altro utente, tipicamente il superutente. Dopo aver inserito il comando sudo, ti verrà chiesto di inserire la tua password per autenticarti.
Questo fornisce accesso avanzato per compiti come installare pacchetti, modificare file di sistema, amministrare servizi ecc.
Per esempio:
sudo adduser bob[sudo] password per john:
L’utente ‘bob’ è stato aggiunto al sistema.
Questo utilizza sudo per creare un nuovo utente, ‘bob’. Normalmente gli utenti regolari non possono aggiungere utenti senza sudo.
79. Su – Cambia ID Utente o Diventa Superutente
Il comando su ti permette di passare a un altro account utente, incluso il superutente. Devi fornire la password dell’utente di destinazione per autenticarti. Questo consente l’accesso diretto per eseguire comandi nell’ambiente di un altro utente.
Per esempio:
su bobPassword:bob@linux:~$
Dopo aver inserito la password di bob, questo comando cambia l’utente corrente con l’utente ‘bob’. Il prompt della Shell rifletterà il nuovo utente.
80. shutdown – Spegni O Riavvia Linux
Il comando shutdown programma lo spegnimento, l’arresto o il riavvio del sistema dopo un timer specificato o immediatamente. È necessario per riavviare o spegnere in modo sicuro i sistemi Linux multi-utente.
Per esempio:
shutdown -r nowMessaggio di broadcast da root@linux Ven 2023-01-20 18:12:37 CST:Il sistema si sta spegnendo per un riavvio IMMEDIATO!
Questo riavvia il sistema immediatamente con un avviso agli utenti.
81. reboot – Riavvia O Riavvia Il Sistema
Il comando reboot riavvia il sistema operativo Linux, disconnettendo tutti gli utenti e riavviando il sistema in modo sicuro. Sincronizza i dischi e spegne il sistema correttamente prima di riavviarlo.
Per esempio:
rebootRiavvio del sistema.
Questo riavvia immediatamente il sistema operativo. reboot è un’alternativa semplice a shutdown -r.
82. systemctl – Controlla Il Gestore Di Sistema E Servizi systemd
Il comando systemctl ti permette di gestire i servizi systemd come avviarli, fermarli, riavviarli o ricaricarli. Systemd è il nuovo sistema init utilizzato nella maggior parte delle distribuzioni Linux moderne, che sostituisce SysV init.
Per esempio:
systemctl start apache2==== AUTENTICAZIONE PER org.freedesktop.systemd1.manage-units ===È richiesta l'autenticazione per avviare 'apache2.service'.Autenticazione come: Nome utentePassword:==== AUTENTICAZIONE COMPLETATA ===
Questo avvia il servizio apache2 dopo l’autenticazione.
83. Servizio – Esegui Uno Script di Init System V
Il comando service esegue gli script di inizializzazione di System V per controllare i servizi. Questo consente di avviare, fermare, riavviare e ricaricare i servizi gestiti sotto l’inizializzazione SysV tradizionale.
Per esempio:
service iptables start[ ok ] Avvio di iptables (tramite systemctl): iptables.service.
Il comando sopra avvia il servizio firewall iptables utilizzando il suo script di init SysV.
Altri Comandi Linux da Provare
-
mount– Monta o “collega” i drive al sistema. -
umount– Smonta o “rimuove” i drive dal sistema. -
xargs– Costruisce ed esegue comandi forniti tramite input standard. -
alias– Crea scorciatoie per comandi lunghi o complessi. -
jobs– Elenca i programmi che attualmente eseguono lavori in background. -
bg– Riprende un processo in background interrotto o in pausa. -
killall– Termina processi per nome del programma anziché per PID. -
history– Visualizza i comandi usati in precedenza nella sessione corrente del terminale. -
man– Accedi ai manuali di aiuto per i comandi direttamente nel terminale. -
screen– Gestisci più sessioni di terminale da una singola finestra. -
ssh– Stabilisci connessioni crittografate sicure con server remoti. -
tcpdump– Cattura il traffico di rete basato su criteri specifici. -
watch– Ripeti un comando a intervalli e evidenzia le differenze nell’output. -
tmux– Multiplexer di terminali per sessioni persistenti e divisione. -
nc– Apri connessioni TCP o UDP per test e trasferimento dati. -
nmap– Scoperta di host, scansione di porte e fingerprinting di sistemi operativi. -
strace– Debug dei processi tracciando segnali e chiamate del sistema operativo.
7 Consigli Chiave Per Usare I Comandi Linux
- Conosci La Tua Shell: Bash, zsh, fish? Le diverse shell hanno caratteristiche uniche. Scegli quella che meglio si adatta alle tue esigenze.
- Padroneggia Gli Strumenti Di Base:
ls,cat,grep,sed,awk, ecc formano il nucleo di un toolkit Linux. - Utilizza Le Pipeline: Evita l’uso eccessivo di file temporanei. Collega i programmi in modo intelligente.
- Verifica Prima Di Sovrascrivere: Controlla sempre prima di sovrascrivere file con
>e>>. - Traccia I Tuoi Flussi Di Lavoro: Documenta comandi e flussi di lavoro complessi per riutilizzarli o condividerli in seguito.
- Crea I Tuoi Strumenti: Scrivi semplici script e alias per compiti frequenti.
- Inizia Senza
sudo: Usa un account utente standard inizialmente per capire le autorizzazioni.
E ricorda di continuare a testare nuovi comandi su macchine virtuali o server VPS affinché diventino una seconda natura per te prima di iniziare a usarli sui server di produzione.
Hosting VPS
Un Virtual Private Server (VPS) è una piattaforma virtuale che memorizza dati. Molti provider di web hosting offrono piani di Hosting VPS, che garantiscono ai proprietari dei siti uno spazio dedicato e privato su un server condiviso.
Leggi di piùMiglior Hosting Linux Con DreamHost
Dopo aver padroneggiato i comandi Linux essenziali, hai anche bisogno di un provider di hosting e server che ti dia il pieno controllo per sfruttare la potenza e la flessibilità di Linux.
È qui che DreamHost eccelle.
L’infrastruttura Linux ottimizzata di DreamHost è perfetta per eseguire le tue app, siti e servizi:
- Hosting veloce su server Linux moderni.
- Accesso Shell SSH per il controllo da linea di comando.
- Versioni PHP personalizzabili inclusa PHP 8.0.
- Server web Apache o NGINX.
- Database MySQL, PostgreSQL, Redis gestiti.
- Installazioni con un clic di applicazioni come WordPress e Drupal.
- Archiviazione accelerata SSD NVMe per velocità.
- Rinnovo automatico gratuito del SSL di Let’s Encrypt.
Gli esperti di DreamHost possono aiutarti a ottenere il massimo dalla piattaforma Linux. I nostri server sono configurati meticolosamente per sicurezza, prestazioni e affidabilità.
Lancia il tuo prossimo progetto su una piattaforma di hosting Linux di cui puoi fidarti. Inizia con un hosting robusto e scalabile su DreamHost.com.

