
Les variables d’environnement permettent de configurer des applications sans modifier le code. Elles détachent les données externes de la logique de l’application, ce qui peut rester assez mystérieux pour les développeurs en herbe (et même certains expérimentés).
À travers ce guide pratique, nous allons lever le voile sur les variables d’environnement pour que tu comprennes ce qu’elles impliquent, pourquoi elles sont importantes, et comment utiliser les variables d’environnement avec confiance.
Prends ta boisson préférée (et peut-être quelques biscuits) car nous allons nous y plonger. Décortiquons les concepts de variables d’environnement depuis la base.
Quels Sont Les Variables D’environnement ?

Les variables d’environnement sont des valeurs nommées dynamiques qui peuvent influencer le comportement des processus en cours sur un ordinateur. Voici quelques propriétés clés des variables d’environnement :
- Nommés : Utilise des noms de variables descriptifs tels que APP_MODE et DB_URL.
- Externes : Les valeurs sont définies en dehors du code de l’application via des fichiers, des lignes de commande et des systèmes.
- Dynamiques : Peuvent mettre à jour les variables sans redémarrer les applications.
- Configurés : Le code dépend des variables mais ne les définit pas.
- Découplés : Pas besoin de modifier les configurations du code une fois les variables définies.
Voici une analogie. Imagine que tu suis une recette de cookies aux pépites de chocolat. La recette pourrait dire :
- Ajoute 1 tasse de sucre
- Ajoute 1 bâtonnet de beurre ramolli
- Ajoute 2 œufs
Au lieu de ces valeurs codées en dur, tu pourrais utiliser des variables d’environnement :
- Ajoute $SUGAR tasse de sucre
- Ajoute $BUTTER bâtonnets de beurre ramolli
- Ajoute $EGGS œufs
Avant de faire les cookies, tu devrais définir ces noms de variables d’environnement avec les valeurs de ton choix :
SUGAR=1
BUTTER=1
EGGS=2Donc, en suivant la recette, tes ingrédients se résumeront à :
- Ajoute 1 tasse de sucre
- Ajoute 1 bâton de beurre ramolli
- Ajoute 2 œufs
Cela te permet de configurer la recette du cookie sans changer le code de la recette.
Le même concept s’applique au calcul et au développement. Les variables d’environnement te permettent de modifier l’environnement dans lequel un processus fonctionne sans changer le code sous-jacent. Voici quelques exemples courants :
- Définir l’environnement sur “développement” ou “production”
- Configurer les clés API pour les services externes
- Intégrer des clés secrètes ou des identifiants
- Activer ou désactiver certaines fonctionnalités
Les variables d’environnement offrent une grande flexibilité. Tu peux déployer le même code dans plusieurs environnements sans modifier le code lui-même. Mais comprenons davantage pourquoi elles sont précieuses.
Pourquoi Les Variables D’environnement Sont-elles Précieuses ?

Considère les variables d’environnement comme des boutons d’application utilisés pour ajuster les préférences. Nous explorerons bientôt d’excellents cas d’utilisation.
Solidifions notre intuition sur l’importance des variables d’environnement !
Raison #1 : Ils Séparent Le Code Des Applications Des Configurations

Coder en dur des configurations et des identifiants directement dans ton code peut causer toutes sortes de problèmes :
- Engagements accidentels dans le contrôle de source
- Reconstruction et redéploiement du code juste pour changer une valeur
- Problèmes de configuration lors de la promotion à travers les environnements
Cela conduit également à un code désordonné :
import os
# Configuration codée en dur
DB_USER = 'appuser'
DB_PASS = 'password123'
DB_HOST = 'localhost'
DB_NAME = 'myappdb'
def connect_to_db():
print(f"Connexion à {DB_USER}:{DB_PASS}@{DB_HOST}/{DB_NAME}")
connect_to_db()Cela mêle la logique commerciale avec les détails de configuration. Un couplage serré rend la maintenance ardue avec le temps :
- Les modifications nécessitent de modifier le code source
- Risque de fuite de secrets dans le contrôle de source
Utiliser des variables d’environnement réduit ces problèmes. Par exemple, tu peux définir les variables d’environnement DB_USER et DB_NAME.
# fichier .env
DB_USER=utilisateurapp
DB_PASS=motdepasse123
DB_HOST=localhôte
DB_NAME=mabasededonnéesappLe code de l’application peut accéder aux variables d’environnement lorsque nécessaire, gardant le code propre et simple.
import os
# Charger la configuration depuis l'environnement
DB_USER = os.environ['DB_USER']
DB_PASS = os.environ['DB_PASS']
DB_HOST = os.environ['DB_HOST']
DB_NAME = os.environ['DB_NAME']
def connect_to_db():
print(f"Connexion à {DB_USER}:{DB_PASS}@{DB_HOST}/{DB_NAME}")
connect_to_db()Les variables d’environnement séparent proprement la configuration du code, en gardant les valeurs sensibles abstraites dans l’environnement.
Tu peux déployer le même code du développement à la production sans changer quoi que ce soit. Les variables d’environnement peuvent varier entre les environnements sans impacter le code du tout.
Raison N°2 : Ils Simplifient La Configuration Des Applications
Les variables d’environnement simplifient la modification des configurations sans toucher au code :
# fichier .env :
DEBUG=trueVoici comment nous pourrions l’utiliser dans le fichier script :
# Contenu du script :
import os
DEBUG = os.environ.get('DEBUG') == 'true'
if DEBUG:
print("En mode DEBUG")Basculer en mode débogage nécessite uniquement la mise à jour du fichier .env—aucun changement de code, reconstruction ou redéploiement n’est nécessaire. Les « variables d’env » pour faire court, aident également à déployer de manière transparente à travers les environnements :
import os
# Récupère la variable d'environnement pour déterminer l'environnement actuel (production ou préproduction)
current_env = os.getenv('APP_ENV', 'préproduction') # Par défaut à 'préproduction' si non défini
# Clé API de production
PROD_API_KEY = os.environ['PROD_API_KEY']
# Clé API de préproduction
STG_API_KEY = os.environ['STG_API_KEY']
# Logique qui définit api_key basée sur l'environnement actuel
if current_env == 'production':
api_key = PROD_API_KEY
else:
api_key = STG_API_KEY
# Initialisation du client API avec la clé API appropriée
api = ApiClient(api_key)Le même code peut utiliser des clés API séparées pour la production et la préproduction sans aucun changement.
Et enfin, ils permettent des basculements de fonctionnalités sans nouvelles déploiements :
NEW_FEATURE = os.environ['NEW_FEATURE'] == 'true'
if NEW_FEATURE:
enableNewFeature()Modifier la variable NEW_FEATURE active instantanément la fonctionnalité dans notre code. L’interface pour mettre à jour les configurations dépend des systèmes :
- Cloud : les plateformes comme Heroku utilisent des tableaux de bord web
- Les serveurs utilisent des outils de commande OS
- Le développement local peut utiliser des fichiers .env
Les variables d’environnement sont bénéfiques lors de la création d’applications, permettant aux utilisateurs de configurer des éléments selon leurs besoins.
Raison #3 : Ils Aident À Gérer Les Secrets Et Les Identifiants

Vérifier des secrets comme les clés API, les mots de passe et les clés privées directement dans le code source présente des risques de sécurité considérables :
# Évitez d'exposer des secrets dans le code !
STRIPE_KEY = 'sk_live_1234abc'
DB_PASSWORD = 'password123'
stripe.api_key = STRIPE_KEY
db.connect(DB_PASSWORD)Ces identifiants sont maintenant exposés si ce code est intégré dans un dépôt GitHub public!
Les variables d’environnement évitent les fuites en externalisant les secrets :
import os
STRIPE_KEY = os.environ.get('STRIPE_KEY')
DB_PASS = os.environ.get('DB_PASS')
stripe.api_key = STRIPE_KEY
db.connect(DB_PASS)Les valeurs secrètes réelles sont définies dans un fichier .env local.
# fichier .env
STRIPE_KEY=sk_live_1234abc
DB_PASS=password123N’oublie pas d’ajouter le fichier .env à .gitignore pour garder les secrets hors du contrôle de source. Cela implique de définir le fichier .env dans un fichier .gitignore à la racine de n’importe quel dépôt, ce qui indique à git d’ignorer le fichier lors de la création d’un commit.
Cela sépare les définitions secrètes du code d’application, les chargeant de manière sécurisée à partir d’environnements protégés pendant l’exécution. Le risque d’exposer accidentellement des identifiants diminue de manière significative.
Raison N°4 : Ils Promeuvent La Cohérence
Imagine avoir différents fichiers de configuration pour les environnements de développement, de QA et de production :
# Développement
DB_HOST = 'localhost'
DB_NAME = 'appdb_dev'
# Production
DB_HOST = 'db.myapp.com'
DB_NAME = 'appdb_prod'Cette divergence introduit des bugs subtils qui sont difficiles à détecter. Du code qui fonctionne parfaitement en développement peut soudainement causer des problèmes en production en raison de configurations non concordantes.
Les variables d’environnement résolvent cela en centralisant la configuration en un seul endroit :
DB_HOST=db.myapp.com
DB_NAME=appdb_prodMaintenant, les mêmes variables sont utilisées de manière cohérente dans tous les environnements. Tu n’as plus à t’inquiéter des paramètres aléatoires ou incorrects qui se déclenchent.
Le code de l’application fait simplement référence aux variables :
import os
db_host = os.environ['DB_HOST']
db_name = os.environ['DB_NAME']
db.connect(db_host, db_name)Que l’application s’exécute localement ou sur un serveur de production, elle utilise toujours le bon nom et hôte de base de données.
Cette uniformité réduit les bugs, améliore la prévisibilité et rend l’application globalement plus robuste. Les développeurs peuvent avoir confiance que le code se comportera de manière identique dans chaque environnement.
Comment Définir Les Variables D’environnement
Les variables d’environnement peuvent être définies à plusieurs endroits, offrant une flexibilité dans la configuration et l’accès à celles-ci à travers les processus et les systèmes.
1. Variables D’environnement Du Système D’exploitation
La plupart des systèmes d’exploitation fournissent des mécanismes intégrés pour définir des variables globales. Cela rend les variables accessibles à l’échelle du système pour tous les utilisateurs, applications, etc.
Sur les systèmes Linux/Unix, les variables peuvent être définies dans les scripts de démarrage du shell.
Par exemple, ~/.bashrc peut être utilisé pour définir des variables au niveau de l’utilisateur, tandis que /etc/environment est destiné aux variables globales au système auxquelles tous les utilisateurs peuvent accéder.
Les variables peuvent également être définies en ligne avant d’exécuter des commandes en utilisant la commande export ou directement via la commande env dans bash :
# Dans ~/.bashrc
export DB_URL=localhost
export PORT_APP=3000# Dans /etc/environment
DB_HOST=localhost
DB_NAME=mabase de donnéesLes variables peuvent également être définies en ligne avant d’exécuter les commandes :
export TOKEN=abcdef
python app.pyDéfinir des variables au niveau du système d’exploitation les rend disponibles globalement, ce qui est assez utile lorsque tu souhaites exécuter l’application sans dépendre de valeurs internes.
Tu peux également faire référence à des variables définies dans des scripts ou des arguments de ligne de commande.
python app.py --db-name $DB_NAME --db-host $DB_HOST --batch-size $BATCH_SIZE2. Définir Les Variables D’environnement Dans Le Code D’application
En plus des variables de niveau système d’exploitation, les variables d’environnement peuvent être définies et consultées directement dans le code de l’application pendant son exécution.
Le dictionnaire os.environ en Python contient toutes les variables d’environnement actuellement définies. Nous pouvons en définir de nouvelles en ajoutant simplement des paires clé-valeur :
Les variables d’environnement peuvent également être définies et accédées directement dans le code de l’application. En Python, le dictionnaire os.environ contient toutes les variables d’environnement définies :
import os
os.environ["API_KEY"] = "123456"
api_key = os.environ.get("API_KEY")Donc, le dictionnaire os.environ permet de définir et de récupérer dynamiquement les variables d’environnement depuis le code Python.
La plupart des langages sont fournis avec leurs bibliothèques, offrant un accès aux variables d’environnement pendant l’exécution.
Tu peux également utiliser des Framework comme Express, Django et Laravel pour avoir des intégrations plus profondes, telles que le chargement automatique de fichiers .env contenant des variables d’environnement.
3. Création De Fichiers De Configuration Locaux Pour Les Variables D’environnement
En plus des variables de niveau système, les variables d’environnement peuvent être chargées à partir des fichiers de configuration locaux d’une application. Cela permet de séparer les détails de configuration du code, même pour le développement et les tests locaux.
Quelques approches populaires :
Fichiers .env
La convention de format de fichier .env popularisée par Node.js offre un moyen pratique de spécifier les variables d’environnement dans un format clé-valeur :
# .env
DB_URL=localhost
API_KEY=123456Des frameworks web comme Django et Laravel chargent automatiquement les variables définies dans les fichiers .env dans l’environnement de l’application. Pour d’autres langages comme Python, des bibliothèques telles que python-dotenv gèrent l’importation des fichiers .env :
from dotenv import load_dotenv
load_dotenv() # Charge les variables .env
print(os.environ['DB_URL']) # localhostL’avantage d’utiliser des fichiers .env est qu’ils permettent de garder la configuration propre et séparée sans apporter de modifications au code.
Fichiers de Configuration JSON
Pour des besoins de configuration plus complexes impliquant plusieurs variables d’environnement, l’utilisation de fichiers JSON ou YAML aide à organiser les variables ensemble :
// config.json
{
"api_url": "https://api.example.com",
"api_key": "123456",
"port": 3000
}Le code d’application peut alors charger rapidement ces données JSON sous forme de dictionnaire pour accéder aux variables configurées :
import json
config = json.load('config.json')
api_url = config['api_url']
api_key = config['api_key']
port = config['port'] # 3000Cela évite les fichiers dotenv désordonnés lors de la gestion de multiples configurations d’applications.
Comment Accèdes-Tu Aux Variables D’Environnement Dans Différents Langages De Programmation ?
Cependant, quelle que soit la manière dont nous choisissons de définir les variables d’environnement, nos applications ont besoin d’une méthode cohérente pour rechercher des valeurs pendant l’exécution.
De nombreuses méthodes permettent de définir des variables d’environnement, mais le code d’application nécessite une méthode standard pour y accéder en temps réel, quel que soit le langage. Voici un aperçu des techniques d’accès aux variables env dans les langages populaires :
Python
Python fournit le dictionnaire os.environ pour accéder aux variables d’environnement définies :
import os
db = os.environ.get('DB_NAME')
print(db)Nous pouvons obtenir une variable en utilisant os.environ.get(), qui renvoie None si elle n’est pas définie. Ou accéder directement via os.environ(), qui lèvera une KeyError si elle n’est pas présente.
Des méthodes supplémentaires comme os.getenv() et os.environ.get() permettent de spécifier des valeurs par défaut si non définies.
JavaScript (Node.js)
Dans le code JavaScript Node.js, les variables d’environnement sont disponibles sur l’objet global process.env :
// Get env var
const db = process.env.DB_NAME;
console.log(db);Si non défini, process.env contiendra undefined. Nous pouvons également fournir des valeurs par défaut comme :
const db = process.env.DB_NAME || 'defaultdb';Ruby
Les applications Ruby accèdent aux variables d’environnement via le hash ENV :
# Accès à la variable
db = ENV['DB_NAME']
puts dbNous pouvons également passer une valeur par défaut si la clé désirée n’existe pas :
db = ENV.fetch('DB_NAME', 'defaultdb')PHP
PHP fournit les méthodes globales getenv(), $_ENV et $_SERVER pour accéder aux variables d’environnement :
// Obtenir la variable d'environnement
$db_name = getenv('DB_NAME');
// Ou accéder aux tableaux $_ENV ou $_SERVER
$db_name = $_ENV['DB_NAME'];Selon la source de la variable, elles peuvent être disponibles dans différents globaux.
Java
En Java, la méthode System.getenv() renvoie des variables d’environnement qui peuvent être consultées :
String dbName = System.getenv("DB_NAME");Cela permet l’accès aux variables définies au niveau du système de manière globale en Java.
Pour l’instant, quelques bonnes pratiques concernant l’hygiène des variables d’environnement.
Guide De Sécurité Des Variables D’environnement

Quand il s’agit de gérer les variables d’environnement de manière sécurisée, nous devons garder plusieurs bonnes pratiques à l’esprit.
Ne Jamais Stocker D’Informations Sensibles Dans Le Code
Tout d’abord, ne stocke jamais d’informations sensibles comme des mots de passe, des clés API, ou des jetons directement dans ton code.
Il peut être tentant de simplement coder en dur un mot de passe de base de données ou une clé de chiffrement dans ton code source pour un accès rapide, mais résiste à cette envie !
Si tu commets par erreur ce code dans un dépôt public sur GitHub, tu diffuses essentiellement tes secrets au monde entier. Imagine si un pirate obtenait les identifiants de ta base de données de production simplement parce qu’ils étaient en texte clair dans ton codebase. C’est une pensée effrayante, n’est-ce pas ?
À la place, utilise toujours des variables d’environnement pour stocker tout type de configuration sensible. Garde tes secrets dans un endroit sécurisé comme un fichier .env ou un outil de gestion de secrets, et référence-les dans ton code via des variables d’environnement. Par exemple, au lieu de faire quelque chose comme ceci dans ton code Python :
db_password = "supers3cr3tpassw0rd"Tu stockerais ce mot de passe dans une variable d’environnement comme ceci :
# fichier .env
DB_PASSWORD=supers3cr3tpassw0rdEt ensuite accède-le dans ton code comme suit :
import os
db_password = os.environ.get('DB_PASSWORD')Ainsi, tes secrets restent en sécurité même si ton code source est compromis. Les variables d’environnement agissent comme une couche d’abstraction sécurisée.
Utilise des Variables Spécifiques à l’Environnement
Une autre pratique consiste à utiliser différentes variables d’environnement pour chaque environnement d’application, tels que le développement, la préproduction et la production.
Tu ne veux pas te connecter accidentellement à ta base de données de production en développant localement juste parce que tu as oublié de mettre à jour une variable de configuration ! Donne un espace de noms à tes variables d’environnement pour chaque environnement :
# Dev
DEV_API_KEY=abc123
DEV_DB_URL=localhost
# Production
PROD_API_KEY=xyz789
PROD_DB_URL=proddb.amazonaws.comEnsuite, référence les variables appropriées dans ton code en fonction de l’environnement actuel. De nombreux Frameworks comme Rails fournissent des fichiers de configuration spécifiques à l’environnement à cet effet.
Gardez Les Secrets Hors Du Contrôle De Version
Il est également crucial de garder tes fichiers .env et de configuration contenant des secrets hors du contrôle de version. Ajoute .env à ton .gitignore pour ne pas le commettre accidentellement dans ton dépôt.
Tu peux utiliser git-secrets pour scanner les informations sensibles avant chaque commit. Pour une sécurité supplémentaire, chiffre ton fichier de secrets avant de le stocker. Des outils comme Ansible Vault et BlackBox peuvent aider avec cela.
Sécuriser Les Secrets Sur Les Serveurs De Production
Lors de la gestion des variables d’environnement sur tes serveurs de production, évite de les définir en utilisant des arguments de ligne de commande, qui peuvent être inspectés via la table des processus.
Au lieu de cela, utilise ton système d’exploitation ou les outils de gestion d’environnement de ta plateforme d’orchestration de conteneurs. Par exemple, tu peux utiliser les Secrets Kubernetes pour stocker et exposer de manière sécurisée les secrets à tes pods d’application.
Utilise Des Algorithmes De Chiffrement Forts
Utilise des algorithmes de chiffrement robustes et modernes lorsque tu chiffres tes secrets, que ce soit en transit ou au repos. Évite les algorithmes obsolètes comme DES ou MD5, qui présentent des vulnérabilités connues. Opte plutôt pour des algorithmes standard de l’industrie comme AES-256 pour le chiffrement symétrique et RSA-2048 ou ECDSA pour le chiffrement asymétrique.
Tourne Régulièrement Les Secrets
Change tes secrets régulièrement, surtout si tu soupçonnes qu’ils ont pu être compromis. Traite les secrets comme tu le ferais avec un mot de passe — mets-les à jour tous les quelques mois. Un outil de gestion des secrets comme Hashicorp Vault ou AWS Secrets Manager peut aider à automatiser ce processus.
Fais Attention Aux Journaux Et Aux Rapports D’erreurs
Fais attention à la journalisation et au rapport d’erreurs. Assure-toi de ne pas journaliser les variables d’environnement qui contiennent des valeurs sensibles. Si tu utilises un outil de suivi des erreurs tiers, configure-le pour qu’il nettoie les données sensibles. La dernière chose que tu souhaites, c’est que tes secrets apparaissent dans une trace de pile sur un tableau de bord de rapport d’exceptions !
Quand Éviter Les Variables D’environnement ?
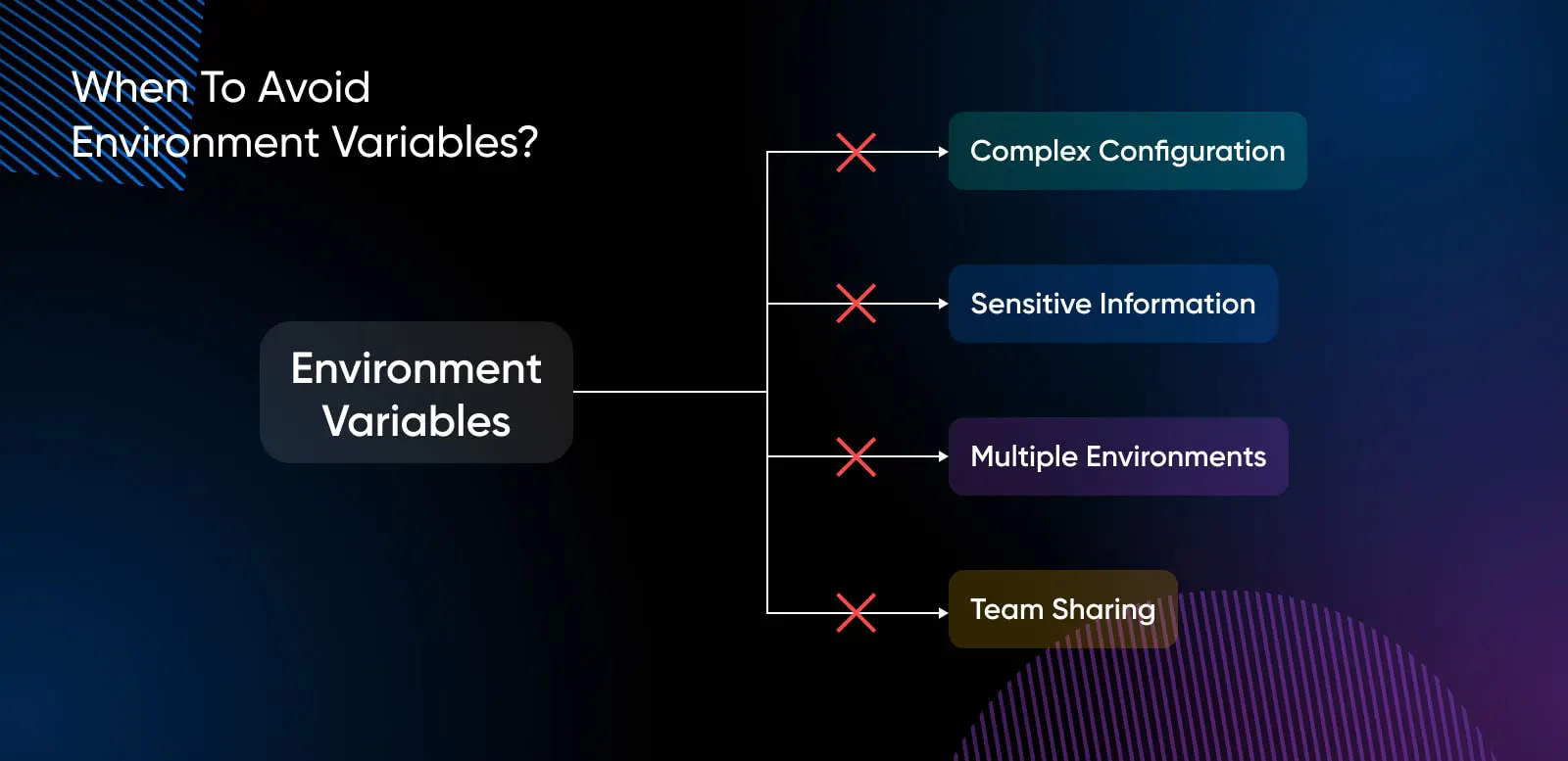
Il existe plusieurs cas où les variables d’environnement devraient être évitées :
Gestion de Configuration Complexe
Utiliser des variables d’environnement pour gérer la configuration de systèmes logiciels complexes peut devenir désordonné et sujet à erreurs. À mesure que le nombre de paramètres de configuration augmente, tu finis par avoir des noms de variables d’environnement longs qui peuvent entrer en collision sans le vouloir. Il n’existe également aucun moyen simple d’organiser ensemble des valeurs de configuration liées.
Au lieu de variables d’environnement, envisage d’utiliser des fichiers de configuration dans un format tel que JSON ou YAML. Cela te permet de :
- Regroupe les paramètres de configuration associés dans une structure imbriquée.
- Évite les collisions de noms en encapsulant la configuration dans des portées et des espaces de noms.
- Définis des types de données personnalisés au lieu de simples chaînes.
- Visualise et modifie rapidement les configurations à l’aide d’un éditeur de texte.
Stockage D’Informations Sensibles
Bien que les variables d’environnement semblent faciles à injecter pour des configurations externes telles que les clés API, les mots de passe de bases de données, etc., cela peut causer des problèmes de sécurité.
Le problème est que les variables d’environnement sont accessibles globalement dans un processus. Ainsi, si une faille existe dans une partie de ton application, elle pourrait compromettre les secrets stockés dans les variables d’environnement.
Une approche plus sécurisée consiste à utiliser un service de gestion des secrets qui gère le chiffrement et le contrôle d’accès. Ces services permettent de stocker des données sensibles de manière externe et fournissent des SDK pour récupérer les valeurs des applications.
Alors, envisage d’utiliser une solution de gestion de secrets dédiée plutôt que des variables d’environnement pour les identifiants et les clés privées. Cela réduit le risque d’exposer accidentellement des données sensibles par des exploits ou des logs non intentionnels.
Travailler Avec Plusieurs Environnements
Gérer les variables d’environnement peut devenir fastidieux à mesure que les applications se développent et sont déployées dans plusieurs environnements (dev, préproduction, préproduction, prod). Tu pourrais avoir des données de configuration fragmentées dispersées à travers différents scripts bash, outils de déploiement, etc.
Une solution de gestion de configuration aide à consolider tous les paramètres spécifiques à l’environnement dans un lieu centralisé. Cela pourrait être des fichiers dans un dépôt, un serveur de configuration dédié, ou intégré à vos pipelines CI/CD.
Si l’objectif est d’éviter de dupliquer les variables d’environnement, une source unique de vérité pour les configurations est plus sensée.
Partage De Configuration Entre Équipes
Puisque les variables d’environnement sont chargées localement par processus, partager et synchroniser les données de configuration entre différentes équipes travaillant sur la même application ou ensemble de services devient très difficile.
Chaque équipe peut maintenir sa copie des valeurs de configuration dans différents scripts bash, manifestes de déploiement, etc. Cette configuration décentralisée conduit aux points suivants :
- Derive de configuration : Sans une seule source de vérité, il est facile pour la configuration de devenir incohérente à travers les environnements alors que différentes équipes apportent des modifications indépendantes.
- Manque de visibilité : Il n’existe aucun moyen centralisé de voir, rechercher et analyser l’état complet de la configuration à travers tous les services. Cela rend extrêmement difficile de comprendre comment un service est configuré.
- Défis de vérification : Les changements aux variables d’environnement ne sont pas suivis de manière standard, rendant difficile l’audit de qui a modifié quelle configuration et quand.
- Difficultés de test : Sans moyen facile de capturer et partager la configuration, garantir des environnements cohérents pour le développement et les tests devient extrêmement encombrant.
Plutôt que cette approche fragmentée, avoir une solution de configuration centralisée permet aux équipes de gérer la configuration à partir d’une seule plateforme ou d’un seul référentiel.
Construis Tes Applications Avec Des Variables D’environnement Pour Le Long Terme
À mesure que ton application se développe, réfléchis à la façon dont tu pourrais avoir besoin de méthodes plus avancées pour gérer ses paramètres de configuration.
Ce qui semble simple maintenant pourrait devenir plus compliqué plus tard. Tu auras probablement besoin de meilleures façons de contrôler l’accès, de partager les paramètres de l’équipe, d’organiser tout clairement et de mettre à jour les configurations de manière fluide.
Ne te retrouve pas coincé en utilisant seulement des variables d’environnement dès le début. Tu veux planifier comment gérer les configurations au fur et à mesure que tes besoins s’étendent.
Alors que les variables d’environnement sont idéales pour gérer des données axées sur l’environnement telles que les identifiants de connexion, les noms de bases de données, les IP locales, etc., tu souhaites créer un système qui suit des principes solides comme la sécurité, la partageabilité, l’organisation et la capacité de s’adapter rapidement aux changements.
Les alternatives que nous avons discutées, comme l’utilisation d’un fichier de configuration dédié ou d’un service, possèdent des caractéristiques précieuses qui s’alignent sur ces principes. Cela t’aidera à continuer à avancer rapidement sans être ralenti.

