
Quand Claude Sonnet 4.5 a été lancé en septembre 2025, cela a rendu obsolètes de nombreux prompts existants. Non pas à cause de bugs lors de la sortie, mais parce qu’Anthropic avait reconstruit la manière dont Claude suit les instructions.
Les versions antérieures devinaient ton intention et développaient les demandes vagues. Claude 4.x te prend au pied de la lettre et fait exactement ce que tu demandes, rien de plus.

Pour comprendre les nouvelles méthodes, nous avons évalué 25 techniques populaires d’ingénierie de prompts contre les documents d’Anthropic, les expériences communautaires et les déploiements réels pour découvrir quelles prompts fonctionnent réellement mieux avec Claude 4.x. Ces cinq techniques
Qu’est-Ce Qui A Changé Dans Claude 4.5 Qui A Perturbé Les Prompts Existantes ?
Modèles Claude 4.5 privilégient les instructions précises plutôt que des suppositions “utiles”.
Les versions précédentes remplissaient les blancs pour toi. Si tu demandais un “tableau de bord”, elles supposaient que tu voulais des graphiques, des filtres et des tableaux de données.
Claude 4.5 te prend au pied de la lettre. Si tu demandes un tableau de bord, il pourrait te donner un cadre vide avec un titre parce que tu n’as pas demandé le reste.
Anthropic déclare clairement : “Les clients qui désirent un comportement ‘au-delà’ pourraient avoir besoin de demander ces comportements de manière plus explicite.”
Alors, nous devons arrêter de traiter le modèle comme une baguette magique et commencer à le traiter comme un employé au sens littéral.
Aucune compétence en design. Aucun constructeur. Aucun tracas. Juste des résultats.
Commencer
Les 5 Techniques Éprouvées Qui Améliorent Mesurablement Les Performances De Claude
Basé sur notre recherche, ces cinq techniques ont constamment fourni des améliorations notables dans les performances de Claude pour les tâches que nous lui avons confiées.
1. Prompts Structurés et Étiquetés
Le système de prompts de Claude Sonnet 4.5 utilise des prompts structurés partout. Simon Willison a exploré les prompts du système et a trouvé des sections enveloppées dans des balises comme <behavior_instructions>, <artifacts_info>, et <knowledge_cutoff>.
En fait, tu pourrais modifier les « Styles » pour voir le prompting structuré d’Anthropic en action.
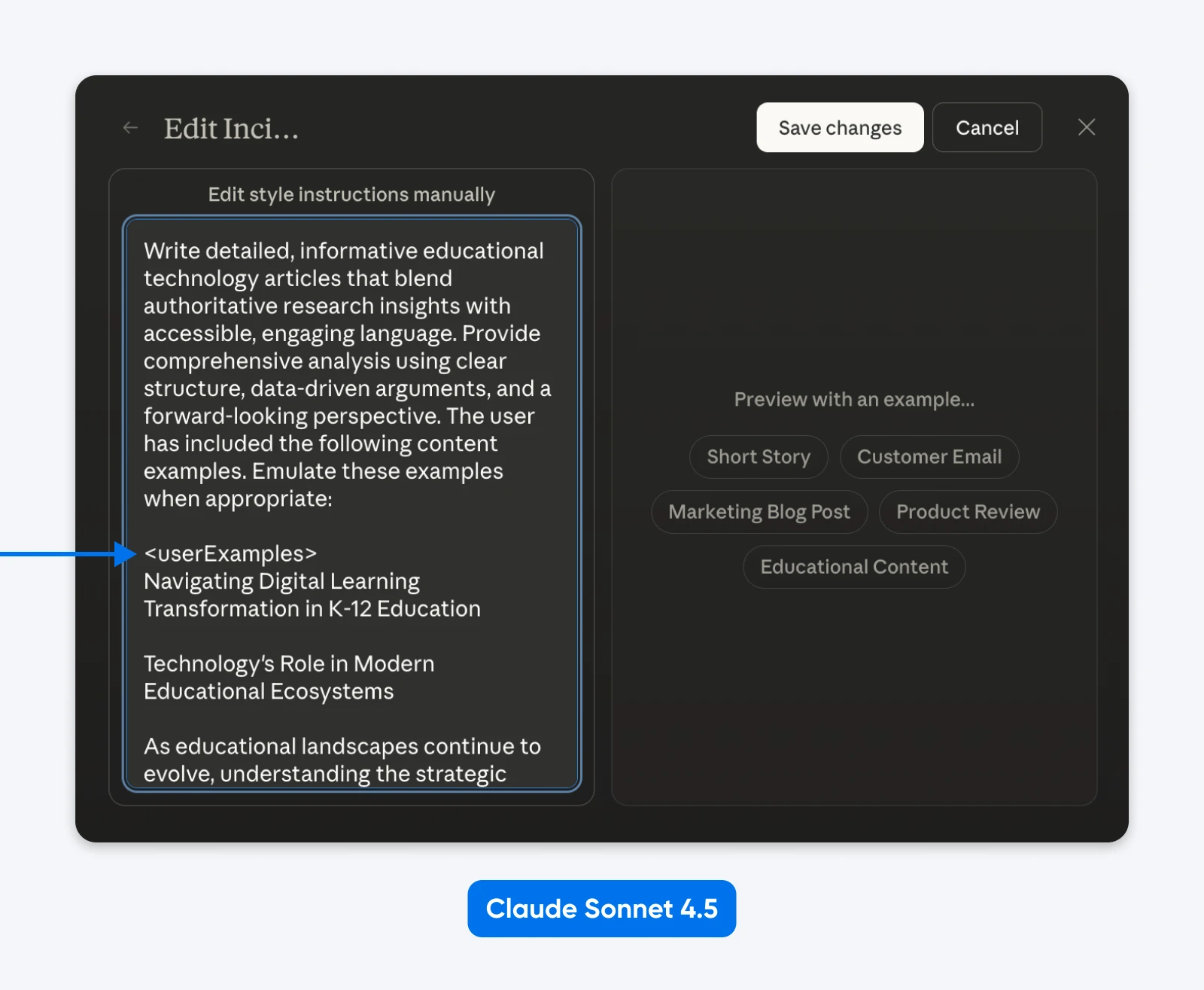
Ce que nous pouvons déduire, c’est que Claude a été formé sur des invites structurées et sait comment les analyser. XML fonctionne très bien, tout comme JSON ou d’autres invites étiquetées.
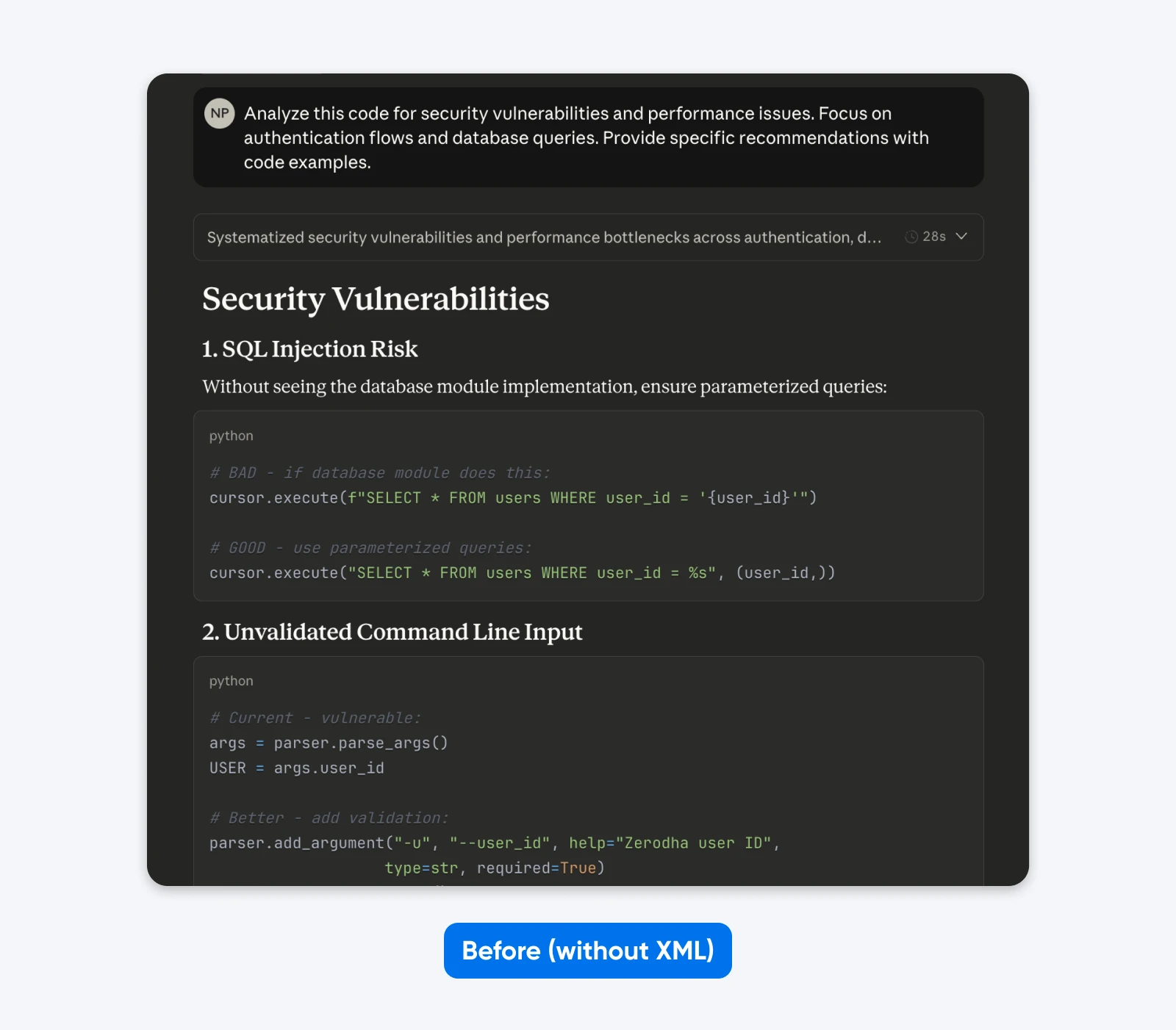
Avant :
Analyse ce code pour les vulnérabilités de sécurité et les problèmes de performance. Concentre-toi sur les flux d’authentification et les requêtes en base de données. Fournis des recommandations spécifiques avec des exemples de code.
Après (Commande Structurée):
<task>Analyse le code fourni pour des problèmes de sécurité et de performance</task>
<focus_areas>
– Flux d’authentification
– Optimisation des requêtes de base de données
</focus_areas>
<code>
[ton code ici]
</code>
<exigences_de_sortie>
– Identifier les vulnérabilités spécifiques avec des évaluations de gravité
– Fournir des exemples de code corrigés
– Prioriser les recommandations en fonction de l’impact sur l’entreprise</exigences_de_sortie>
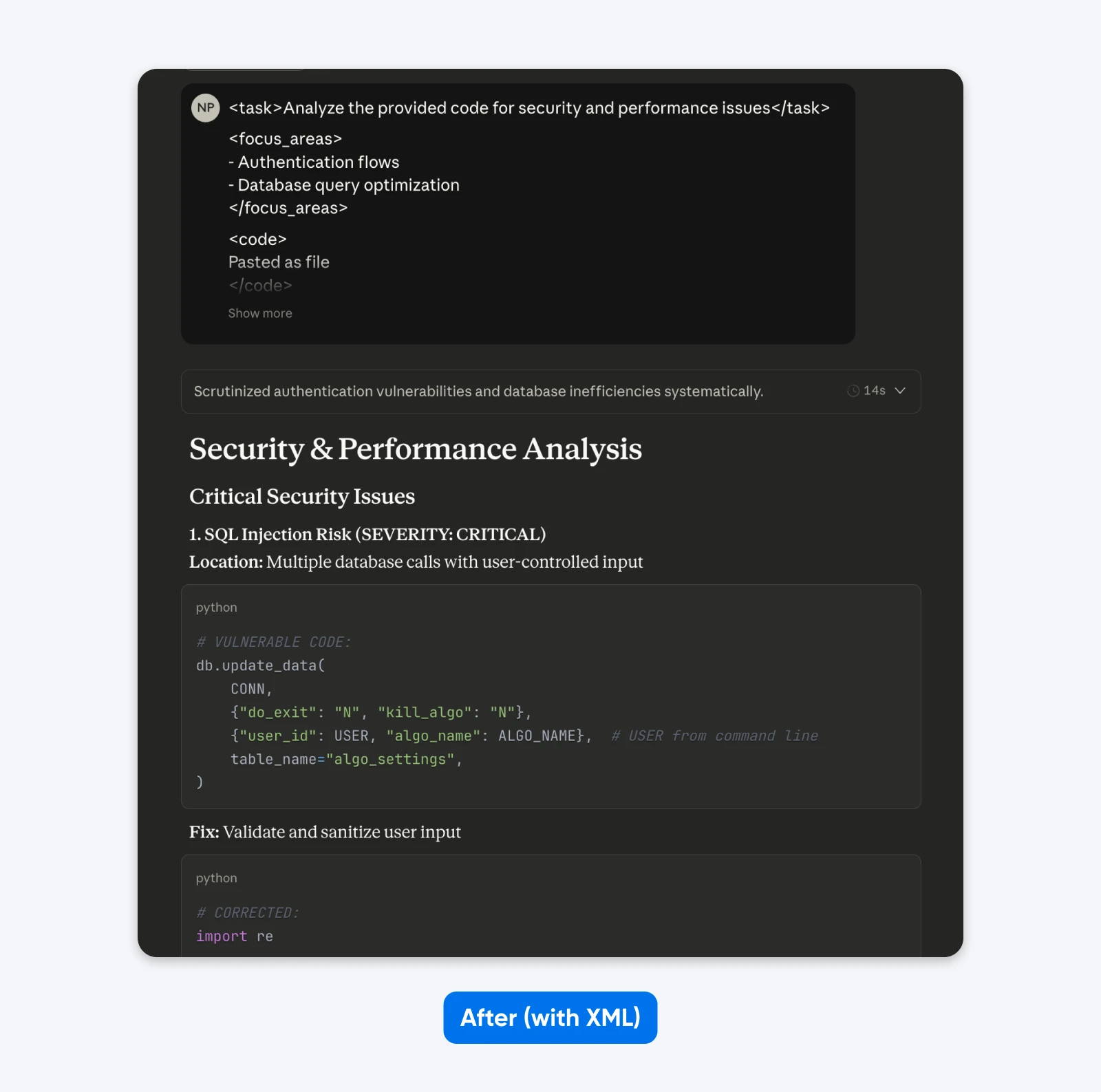
Si tu compares ces résultats, tu remarqueras que l’invite structurée fournit une sortie avec plus de contexte pour t’aider à comprendre et à résoudre les problèmes de sécurité dans le code. Elle explique le problème, indique ce que la correction fait et fournit ensuite le code de correction.
Formats Alternatifs Fonctionnels :
JSON :
{
"task": "Revoir le code d'authentification",
"focus_areas": ["Hachage de mot de passe", "Sécurité de session", "Injection SQL"],
"context": "Application de santé, HIPAA nécessaire",
"output_format": "Risque, impact, correction, gravité par vulnérabilité"
}
En-tête Clair :
TÂCHE : Vérifier le code d'authentification pour détecter les vulnérabilités
ACCENT : Hashage de mots de passe, sessions, injection SQL
CONTEXTE : Application de soins de santé nécessitant la conformité HIPAA
FORMAT DE SORTIE : Risque → Impact HIPAA → Correction → Sévérité
Les trois fonctionnent également bien.
Quand les invites structurées fonctionnent le mieux:
- Plusieurs composants d’invite (tâche, contexte, exemples, exigences)
- Entrées longues (plus de 10 000 tokens de code ou documents)
- Flux de travail séquentiels avec des étapes distinctes
- Tâches nécessitant des références répétées à des sections spécifiques
Quand éviter les invites structurées : Des questions simples où un texte brut suffit.
Note d’efficacité : 9/10 pour les tâches complexes, 5/10 pour les requêtes simples.
2. Réflexion Approfondie Pour Les Problèmes Complexes
Une Réflexion Approfondie apporte des améliorations considérables sur les tâches de raisonnement complexes avec un inconvénient majeur : la vitesse.
L’annonce de Claude 4 par Anthropic a montré des gains de performance substantiels avec la réflexion prolongée activée. Lors du concours de mathématiques AIME 2025, les scores se sont nettement améliorés.
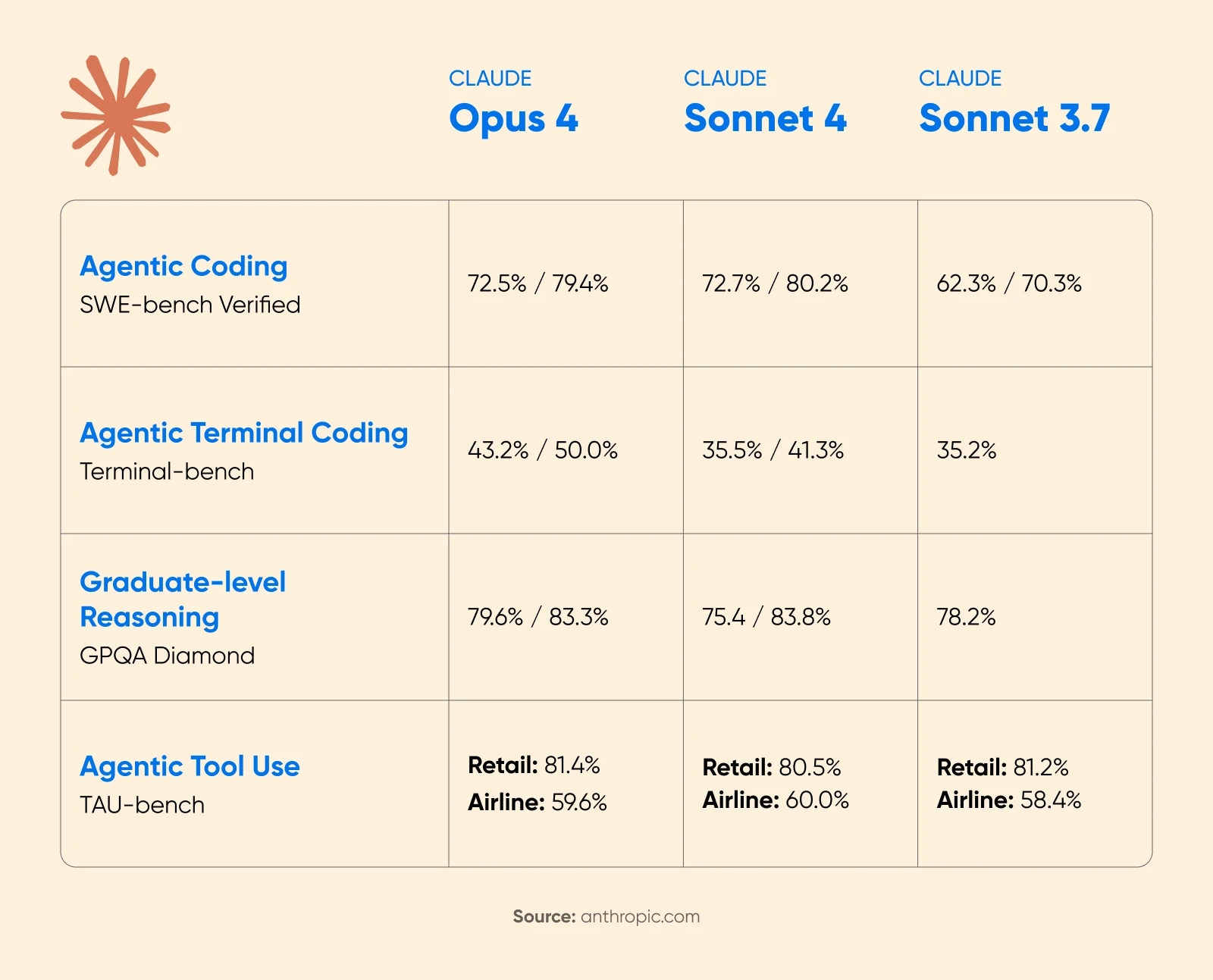
Cognition AI a signalé une augmentation de 18 % de la performance de planification avec Sonnet 4.5, le qualifiant de « plus grand bond que nous avons vu depuis Claude Sonnet 3.6 ».
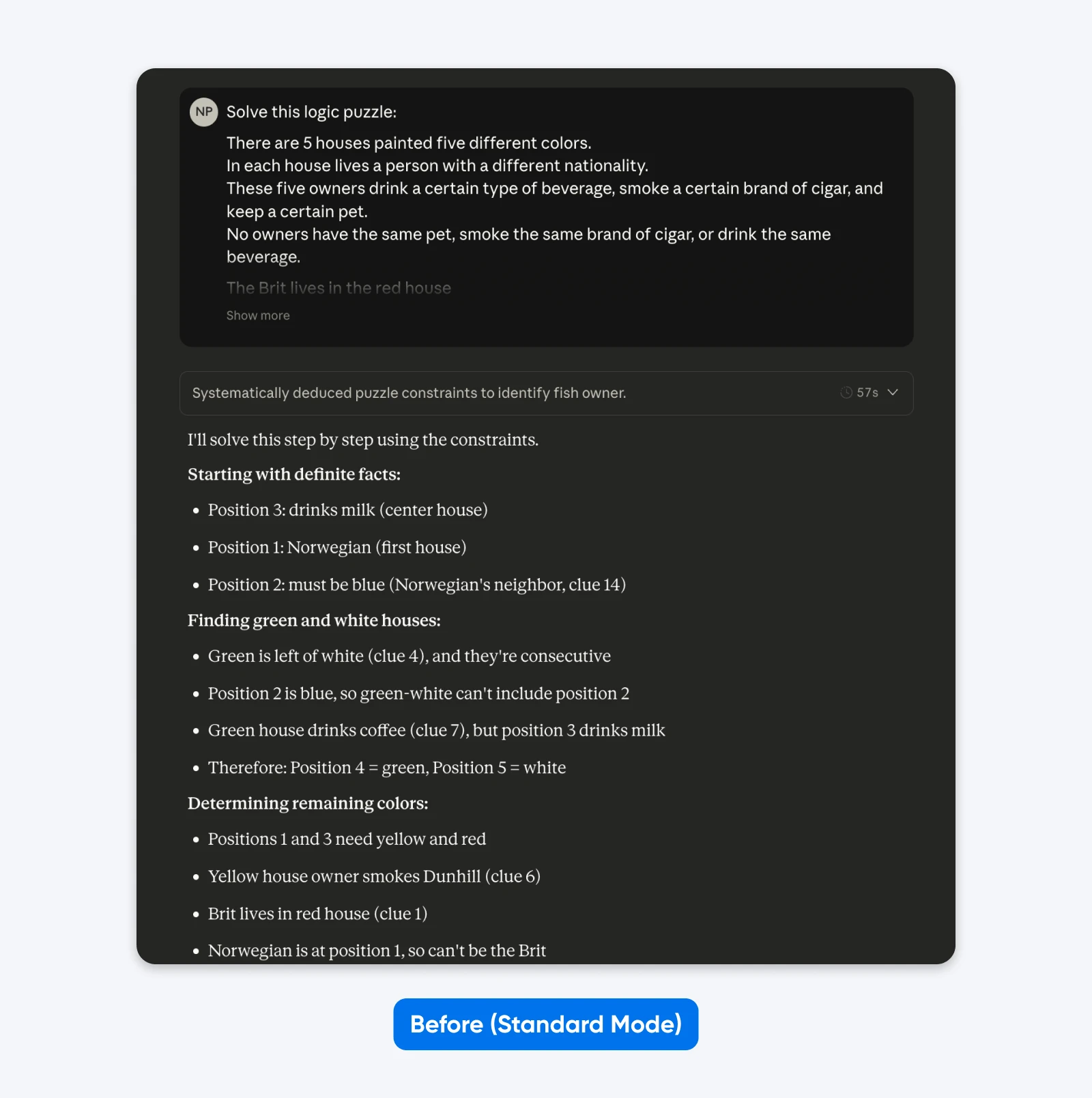
Avant (Mode Standard):
Résous ce casse-tête logique : Cinq maisons alignées, chacune d’une couleur différente…
Après (avec Une Réflexion Approfondie):
Comprends la logique de cette énigme de manière systématique. Passe en revue les contraintes étape par étape, vérifiant chaque possibilité avant de tirer des conclusions.
Cinq maisons en ligne, chacune d’une couleur différente…
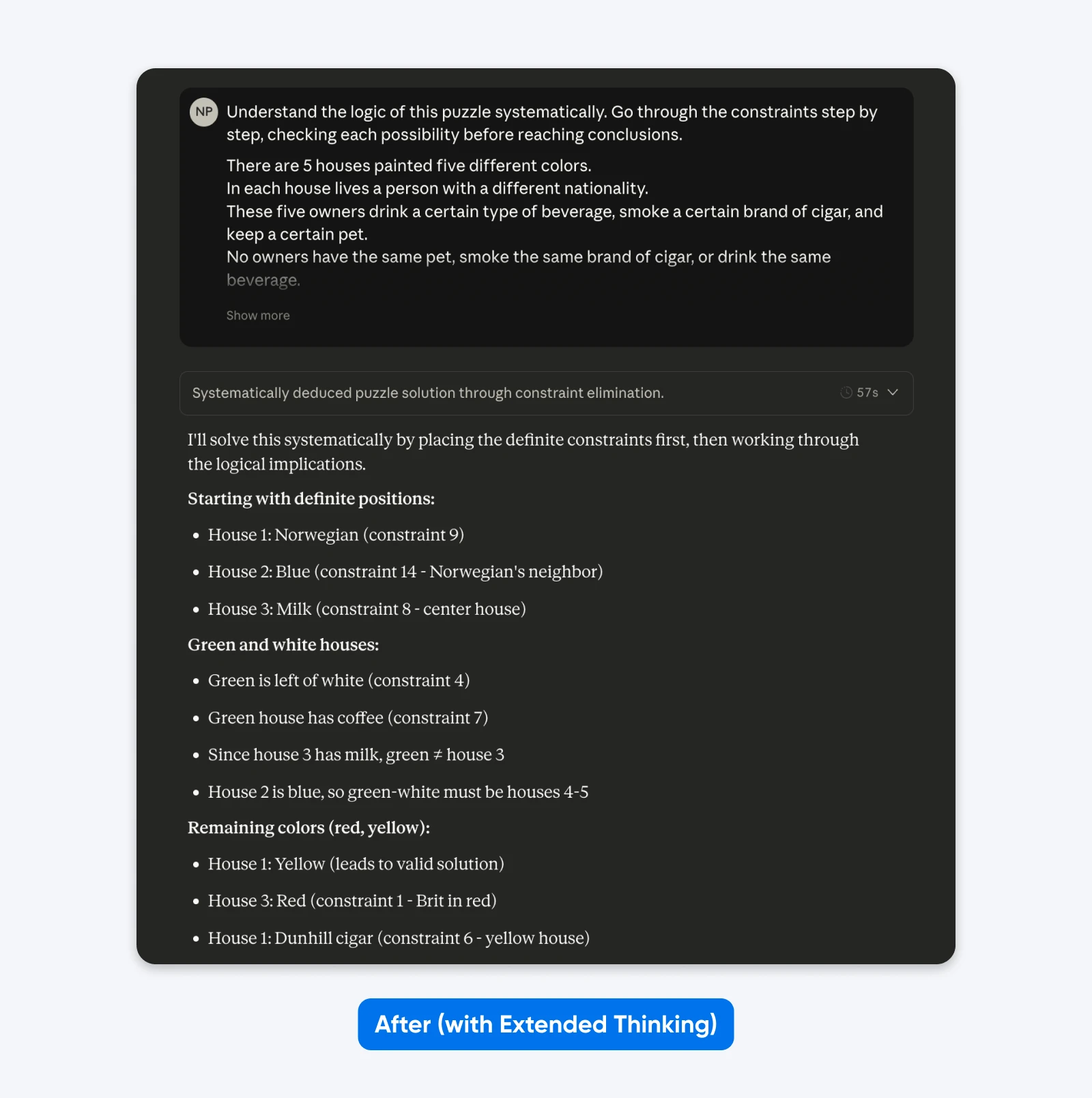
Tu ne verras pas beaucoup de différence avec des invites simples comme celle ci-dessus. Mais pour des problèmes complexes et spécialisés (bases de code personnalisées, planification logique en plusieurs étapes), la différence devient claire.
Quand les choses étendues fonctionnent :
- Planification logique en plusieurs étapes nécessitant une vérification
- Raisonnement mathématique avec plusieurs chemins de solutions
- Tâches de codage complexes couvrant plusieurs fichiers
- Situations où la justesse est plus importante que la rapidité
Quand Ignorer : Itérations rapides, requêtes simples, écriture créative, tâches sensibles au temps
Note d’efficacité : 10/10 pour le raisonnement complexe, 3/10 pour les requêtes simples.
3. Sois Extrêmement Précis Concernant Les Exigences
Les modèles Claude 4 ont été formés pour suivre les instructions de manière plus précise que les générations précédentes.
La documentation d’Anthropic indique :
“Les modèles Claude 4.x réagissent bien aux instructions claires et explicites. Être précis sur le résultat souhaité peut aider à améliorer les résultats. Les clients qui désirent un comportement ‘au-delà des attentes’ des modèles Claude précédents pourraient avoir besoin de demander ces comportements plus explicitement avec les nouveaux modèles.”
La documentation indique également que Claude est suffisamment intelligent pour généraliser à partir de l’explication lorsque tu fournis un contexte pour expliquer pourquoi les règles existent, plutôt que de simplement énoncer des commandes. Cela signifie que fournir une justification aide le modèle à appliquer correctement les principes dans les cas limites non explicitement couverts.
Les tests effectués par 16x Eval ont montré que tant Opus 4 que Sonnet 4 ont obtenu 9,5/10 pour les tâches TODO lorsque les instructions spécifiaient clairement les exigences, le format et les critères de réussite. Les modèles ont démontré une concision impressionnante et des capacités à suivre les instructions.
Avant (attentes implicites):
Crée un tableau de bord analytique.
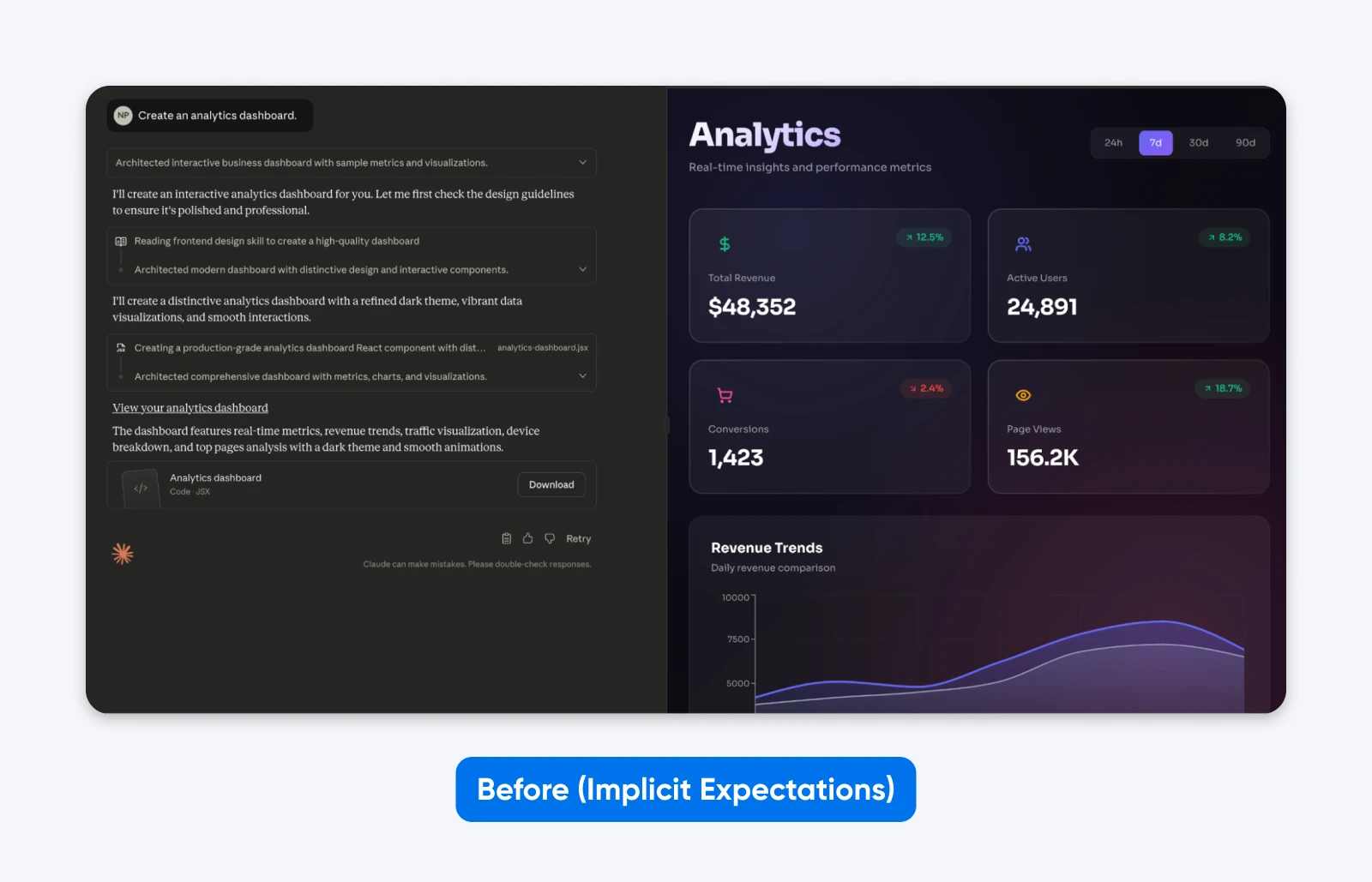
Tu remarqueras que ce résultat est EXACTEMENT ce que nous avons demandé. Bien que Claude ait pris un peu de liberté créative dans l’esthétique, cela n’affecte en rien la fonctionnalité.
Après (exigences explicites):
Crée un tableau de bord d’analyse. Inclus autant de fonctionnalités et d’interactions pertinentes que possible. Va au-delà des bases pour créer une mise en œuvre complète avec visualisation des données, capacités de filtrage, et fonctions d’exportation.
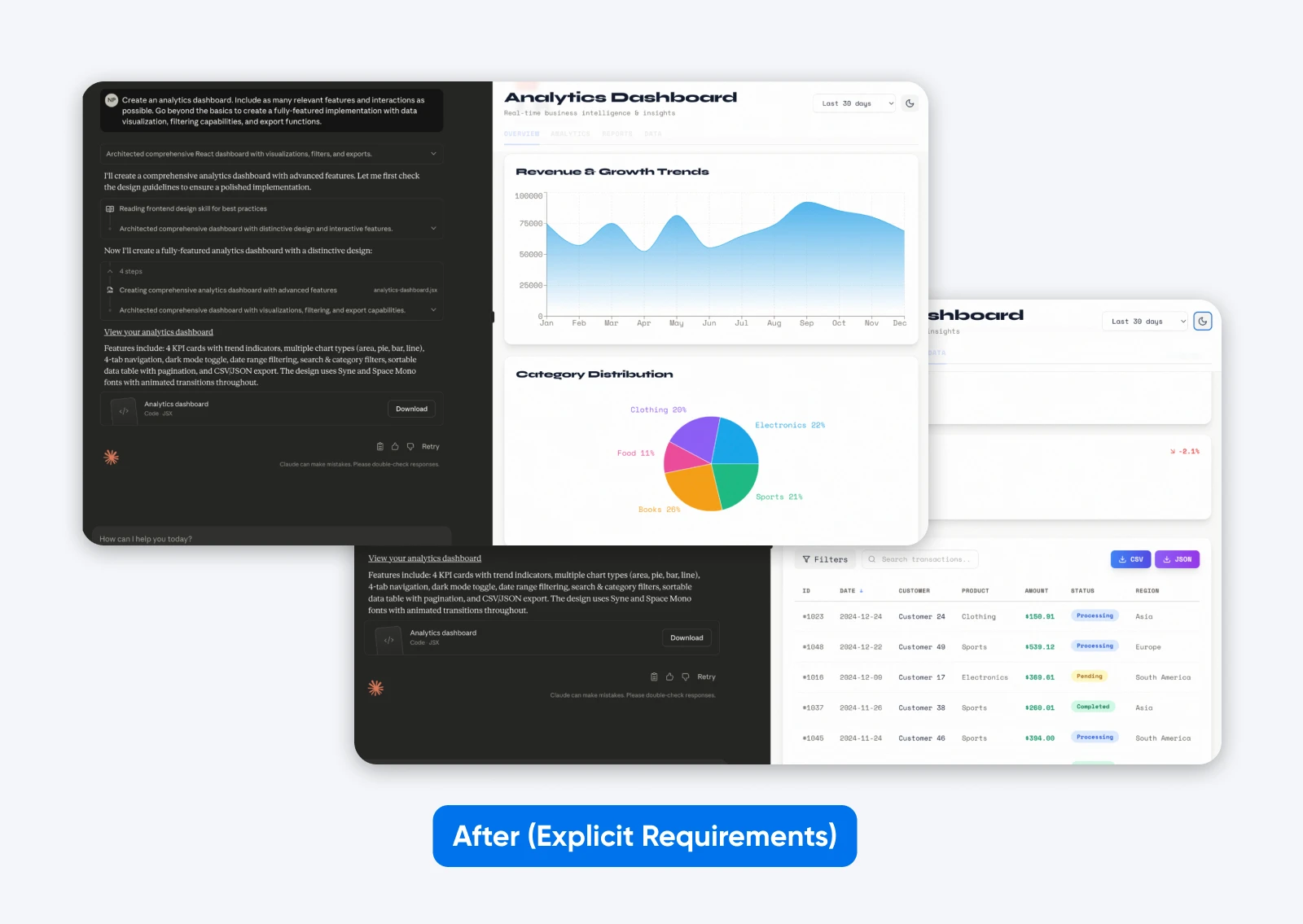
Cette deuxième sortie avec une invite plus descriptive offre plus de fonctionnalités, un tableau de bord construit sur des données fictives, qui sont présentées à la fois graphiquement et sous forme de tableau, et elle comporte des onglets pour séparer toutes les données.
C’est ce que fait la précision avec le dernier Claude.
Pour clarifier davantage ce point, voici un autre exemple montrant comment le contexte améliore le suivi des instructions :
Avant (commande sans contexte):
NE JAMAIS utiliser des points de suspension dans ta réponse.
Après (instruction motivée par le contexte):
Ta réponse sera lue à haute voix par un moteur de synthèse vocale, donc évite les points de suspension puisque le moteur ne saura pas comment les prononcer.
Principes clés pour des instructions explicites:
- Définis ce que signifie “complet” pour ta tâche spécifique : Ne suppose pas que Claude déduira les normes de qualité.
- Explique pourquoi les règles existent plutôt que de simplement les énoncer : Claude généralise mieux à partir d’instructions motivées.
- Spécifie explicitement le format de sortie : Demande des “paragraphes de prose” au lieu d’espérer que Claude ne choisira pas par défaut les points de forme.
- Fournis des critères de réussite concrets : À quoi ressemble la complétion de la tâche ?
Note d’efficacité : 9/10 sur tous les types de tâches.
4. Montre Des Exemples De Ce Que Tu Veux
Le prompting en quelques exemples fournit à Claude des entrées et sorties exemplaires démontrant le comportement souhaité. Cela fonctionne, mais seulement lorsque les exemples sont de haute qualité et adaptés à la tâche, et l’impact varie considérablement selon le cas d’utilisation.
Les recommandations officielles d’Anthropic soulignent :
« Les modèles Claude 4.x prêtent une attention particulière aux détails et aux exemples dans le cadre de leur suivi d’instructions précis. Assure-toi que tes exemples correspondent aux comportements que tu souhaites encourager et minimisent les comportements que tu souhaites éviter. »
Anthropic recommande 3 à 5 exemples divers et pertinents pour les tâches complexes. Plus d’exemples équivaut à de meilleures performances.
Voici un exemple de ce que cela donne en pratique :
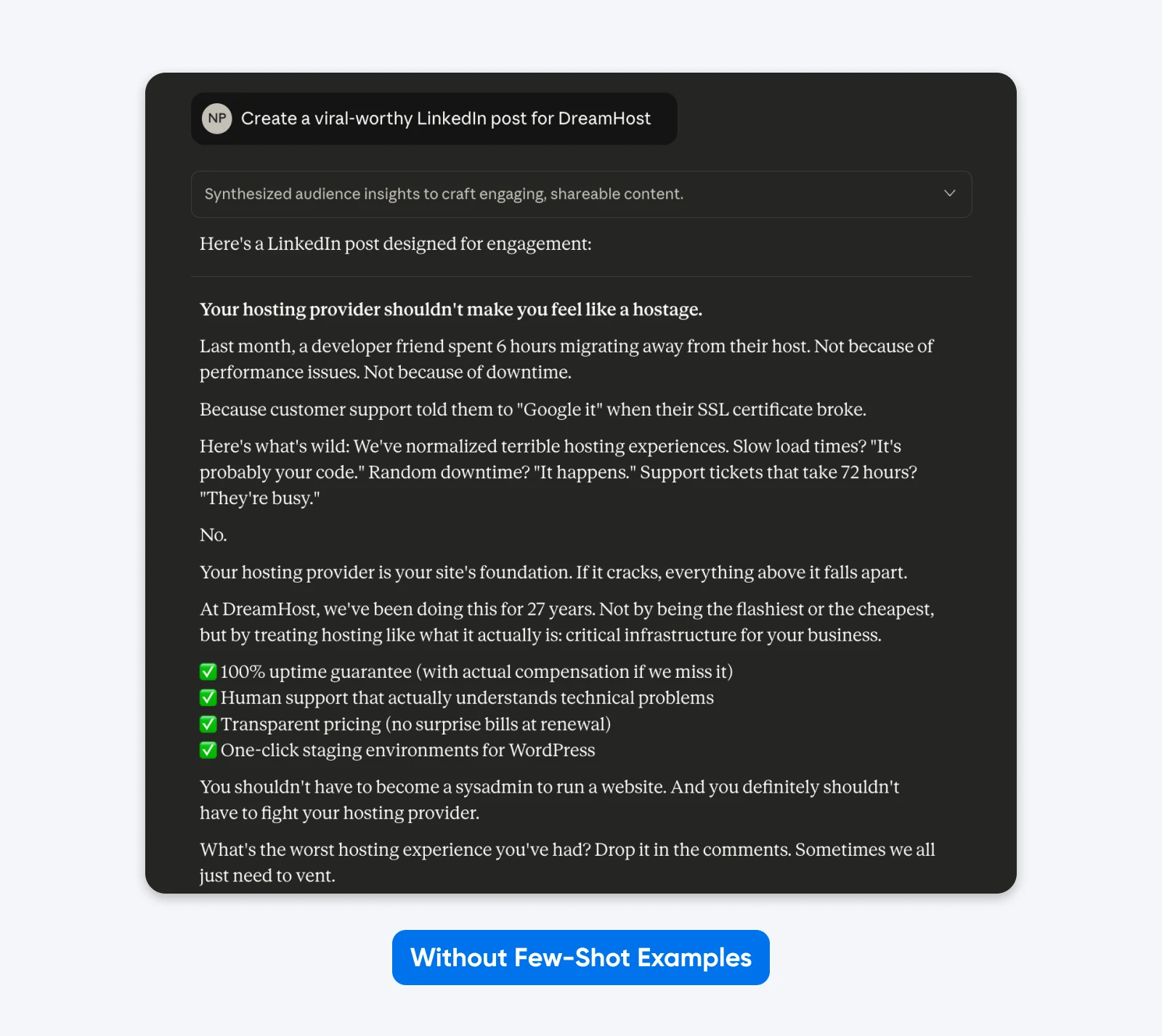
Ici, Claude a pris la liberté créative avec le format, l’utilisation des emojis, le message et le ton. Langage d’entreprise générique
Ajouter des exemples fonctionne parce qu’ils montrent plutôt que de dire, tout en clarifiant les exigences subtiles qui sont difficiles à exprimer uniquement par la description.
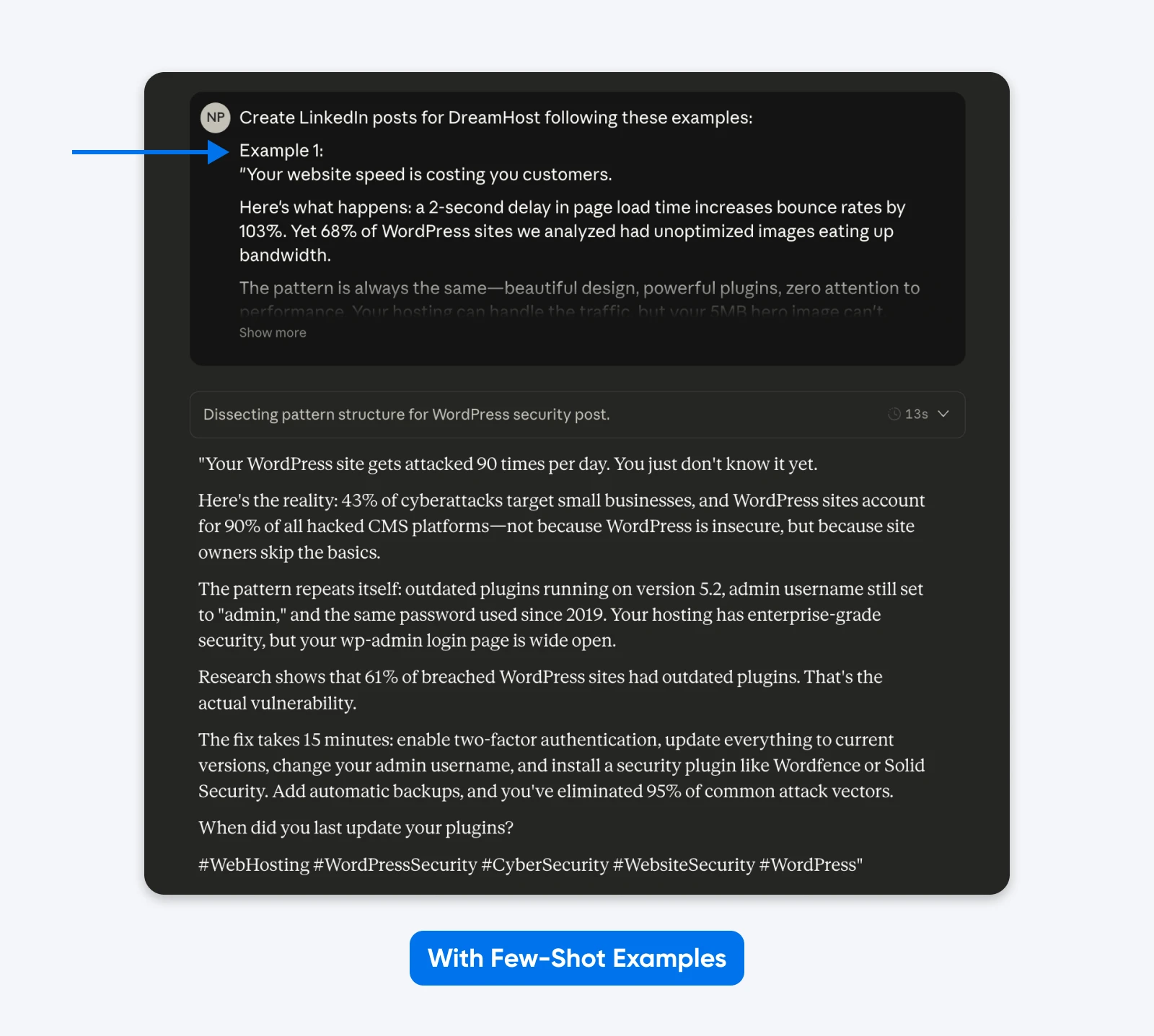
Ce résultat se rapproche davantage des exemples que j’ai fournis dans l’invite. Tu peux utiliser la méthode des exemples ponctuels pour obtenir des publications LinkedIn comme celles qui ont le mieux performé. Un article académique sur la conception de machines à états finis (FSM) a montré que les exemples structurés obtenaient un taux de succès de 90 % par rapport aux instructions sans exemples.
Comment Implémenter :
- Place les exemples dans les balises <example>, regroupés dans les balises <examples>
- Place les exemples tôt dans le premier message utilisateur
- Utilise 3-5 exemples divers pour les tâches complexes
- Assure la correspondance de chaque détail dans les exemples avec le résultat souhaité (Claude 4.x reproduit les conventions de nommage, le style de code, la mise en forme, la ponctuation)
- Évite les exemples redondants
Quand Les Exemples Fonctionnent Le Mieux :
- Formatage des données nécessitant une structure précise
- Modèles de codage complexes nécessitant des approches spécifiques
- Tâches analytiques démontrant des méthodes de raisonnement
- Sortie nécessitant un style et des conventions cohérents
Quand Ignorer : Requêtes simples où les instructions suffisent, ou lorsque tu veux que Claude utilise son propre jugement.
Évaluation de l’efficacité : 10/10 pour les tâches de formatage, 6/10 pour les requêtes simples.
5. Mets Le Contexte Avant Ta Question
Claude dispose d’une fenêtre de contexte de 200 000 jetons (jusqu’à 1 million dans certains cas) et peut comprendre les requêtes placées n’importe où dans le contexte. Mais la documentation d’Anthropic recommande de placer les documents longs (plus de 20 000 jetons) en haut des invites, avant les requêtes.
Les tests ont montré que cela améliore la qualité de la réponse jusqu’à 30% par rapport à l’ordre basé sur la requête, surtout avec des entrées complexes et multi-documents.
Pourquoi ? Les mécanismes d’attention de Claude donnent plus de poids au contenu vers la fin des invites. Placer la question après le contexte permet au modèle de référencer le matériel précédent tout en générant des réponses.
Avant (d’abord la requête):
Analyse la performance financière trimestrielle et identifie les tendances clés.
[20,000 jetons de données financières]
Après (contexte d’abord):
[20,000 jetons de données financières]
Sur la base des données financières trimestrielles fournies ci-dessus, analysez la performance et identifiez les tendances clés en matière de croissance des revenus, d’expansion des marges et d’efficacité opérationnelle. Concentrez-vous sur les informations pratiques pour la prise de décision exécutive.
Quand cela compte : Analyse de contexte long où Claude doit se référer de manière approfondie au matériel précédent.
Quand Ignorer : Les instructions courtes de moins de 5 000 jetons.
Note d’efficacité : 8/10 pour les tâches à contexte long, 4/10 pour les invites courtes.
Quelles Techniques D’Incitation Ne Fonctionnent Plus : Briser Les Mythes Courants
Les modifications de Claude 4.5 ont invalidé plusieurs techniques populaires qui fonctionnaient avec les modèles antérieurs.
1. Mots Accentués (EN MAJUSCULES, “OBLIGATOIRE”, “TOUJOURS”)
Écrire en majuscules ne garantit plus la conformité. L’analyse de Chris Tyson a révélé que Claude donne désormais la priorité au contexte et à la logique plutôt qu’à l’emphase.
Si tu écris « NE JAMAIS fabriquer de données » mais que le contexte implique que tu as besoin d’une estimation, Claude 4.5 privilégie le besoin logique par rapport à ton ordre en majuscules.
Utilise plutôt la logique conditionnelle :
- Mauvais : Utilise TOUJOURS des chiffres exacts !
- Bon : Si des données vérifiées sont disponibles, utilise des chiffres précis. Sinon, fournis des intervalles et étiquette-les comme des estimations.
2. Instructions Manuelles De Raisonnement En Chaîne
Dire au modèle de « penser étape par étape » gaspille des jetons lors de l’utilisation du mode Pensée Étendue.
Lorsque tu actives la Pensée Étendue, le modèle gère son propre budget de raisonnement. Ajouter tes propres instructions « pas à pas » est redondant.
Que faire à la place :
Fais confiance à l’outil. Si tu actives la Réflexion Étendue, supprime toutes les instructions sur la manière de penser.
3. Contraintes Négatives (« Ne Fais Pas X »)
Dire à Claude exactement ce qu’il ne faut pas faire se retourne souvent contre nous.
Le mécanisme d’attention de Claude met en évidence le concept interdit, en le maintenant actif dans la fenêtre de contexte.
Au lieu de cela, reformule chaque négatif en une commande positive :
- Mauvais : Ne rédige pas de longues introductions superflues. N’utilise pas des mots comme « explorer » ou « tapisserie ».
- Bon : Commence directement par l’argument principal. Utilise un langage concis et percutant.
Comment Migrer Les Prompts De Claude 3.5 à Claude 4 ?
Si tu migres de Claude 3.5 à 4.5, tu peux migrer ta bibliothèque de prompts en suivant cinq étapes systématiques validées par l’expérience des développeurs.
Nous utiliserons un scénario d’hébergement courant pour cet exemple. L’objectif est de générer une réponse de support technique pour un client confronté à une erreur “503 Service Unavailable” sur son site WordPress.

1. Audit Des Hypothèses Implicites
Commence par identifier où l’invite dépend du modèle pour deviner le contexte. Dans les versions antérieures, le modèle présumait que tu utilisais la pile logicielle la plus commune. Claude 4.5 ne fera pas cette supposition.
Invite Héritée :
“Mon site web charge lentement et affiche des erreurs. Tu es un administrateur de serveur expert. Pense étape par étape et dis-moi comment corriger la configuration pour le rendre plus rapide.”
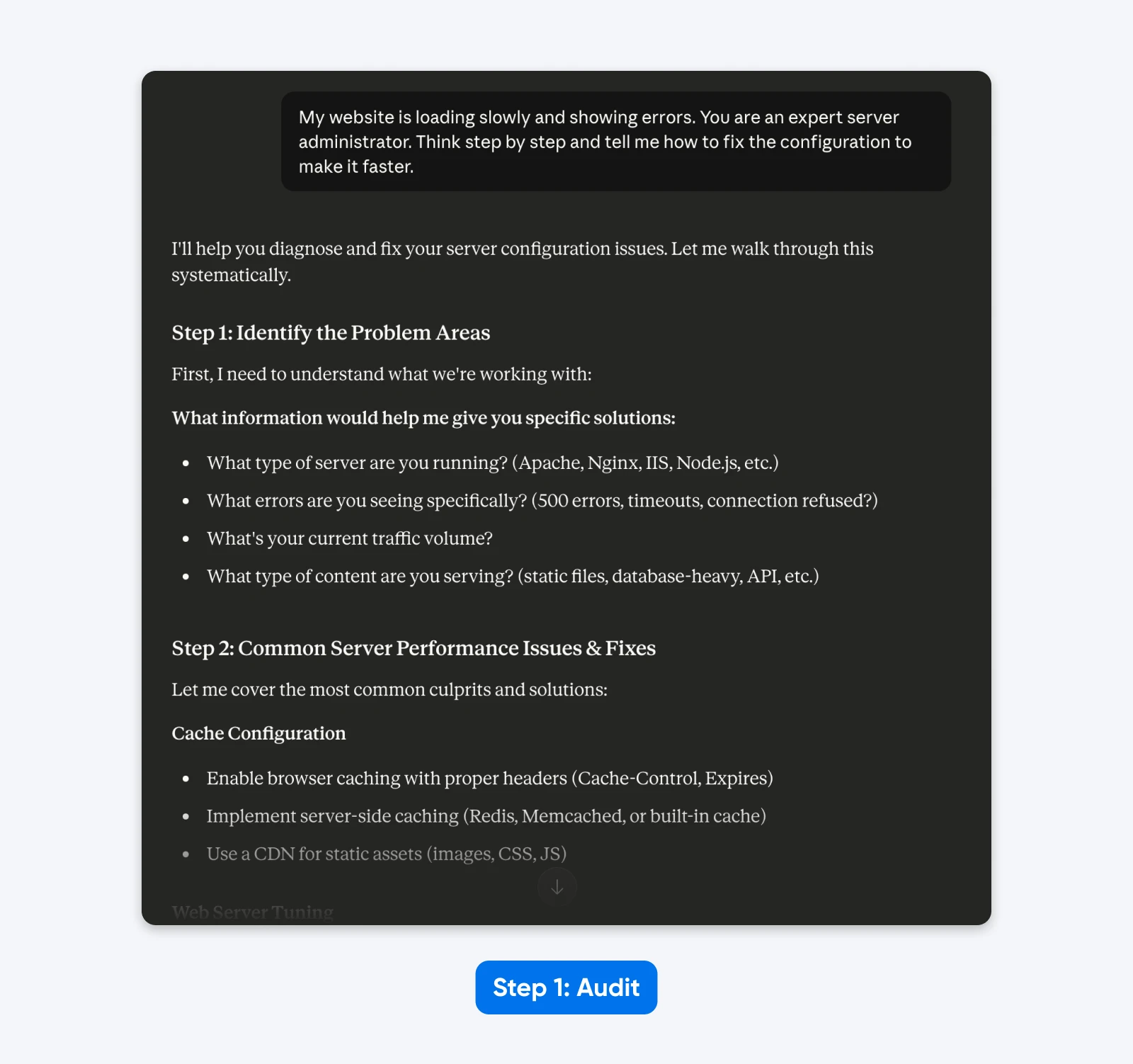
L’Audit :
- “Site web” implique une configuration générique plutôt qu’un CMS spécifique (WordPress).
- “Lentement” est subjectif; cela pourrait signifier un temps élevé avant le premier octet ou un rendu lent des éléments.
- “Erreurs” manque les codes de statut HTTP spécifiques nécessaires pour le diagnostic.
- “Administrateur serveur expert” et “Penser étape par étape” sont des instructions de direction inutiles.
Dans la réponse, Claude 4.5 demande plus d’informations car il est entraîné à éviter de faire des suppositions.
2. Refactoriser pour une Spécificité Explicite
Maintenant, réécris l’invite pour définir l’environnement, le problème spécifique et le format de sortie souhaité. Tu dois fournir les détails techniques que le modèle a précédemment devinés.
Indication Reformulée :
“Mon site WordPress fonctionnant sur Nginx et Ubuntu 20.04 rencontre un temps élevé pour le premier octet (TTFB) et des erreurs occasionnelles 502 Bad Gateway. Tu es un administrateur de serveur expert. Pense étape par étape et fournis des modifications spécifiques de configuration Nginx et PHP-FPM pour résoudre ces délais d’attente.”

Le Résultat : La consigne spécifie maintenant la pile logicielle exacte (Nginx, Ubuntu, WordPress) et l’erreur spécifique (502 Bad Gateway), réduisant les chances de conseils non pertinents sur Apache ou IIS. Et Claude répond avec une analyse et une solution étape par étape.
3. Implémenter La Logique Conditionnelle
Claude 4.5 excelle lorsqu’il est confronté à un arbre de décision. Au lieu de demander une seule solution statique, demande au modèle de gérer différents scénarios en fonction des données qu’il analyse.
Invite Avec Logique :
“Mon site WordPress fonctionnant sur Nginx et Ubuntu 20.04 subit des TTFB élevés et des erreurs 502 Bad Gateway. Tu es un administrateur de serveur expert. Pense étape par étape.
Si les journaux d’erreurs indiquent ‘upstream sent too big header’, fournis les modifications de configuration pour les tailles de buffer. Si les journaux d’erreurs montrent ‘upstream timed out’, fournis les modifications de configuration pour les limites de temps d’exécution.”
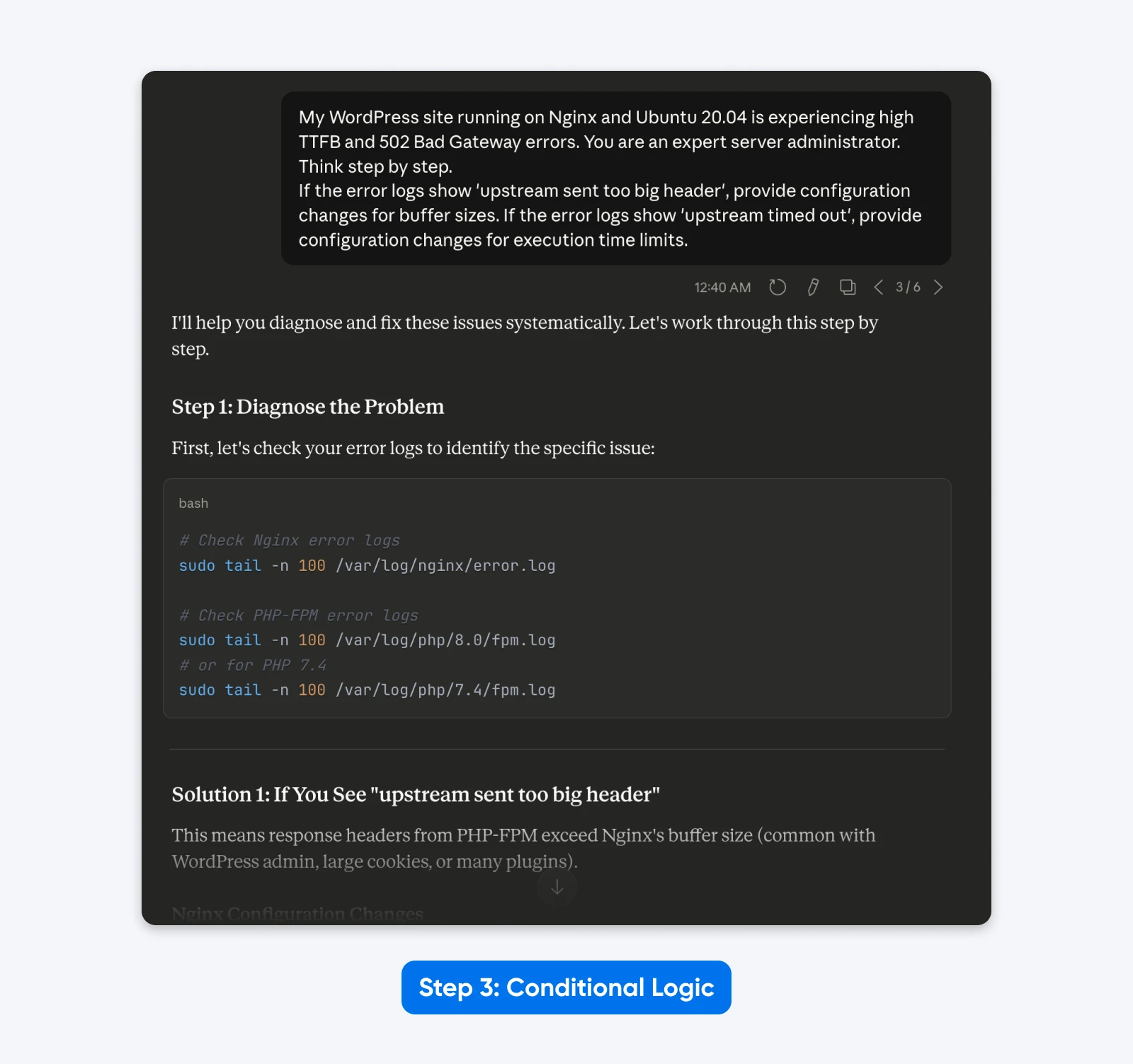
Le Résultat : La sortie devient dynamique. Le modèle propose des solutions ciblées basées sur la logique de cause racine spécifique que tu as définie, plutôt qu’une liste générique de corrections.
4. Supprimer le Langage de Direction Obsolète
Les anciennes invites contiennent souvent des instructions de réflexion que les utilisateurs pensaient améliorer les performances. Elles sont inutiles et redondantes avec Claude 4.5 car il possède une réflexion étendue.
Invite Nettoyée :
“Mon site WordPress fonctionnant sur Nginx et Ubuntu 20.04 rencontre des TTFB élevés et des erreurs 502 Bad Gateway.
Si les journaux d’erreur indiquent ‘upstream sent too big header’, fournissez des modifications de configuration pour les tailles de tampon. Si les journaux d’erreur indiquent ‘upstream timed out’, fournissez des modifications de configuration pour les limites de temps d’exécution.”
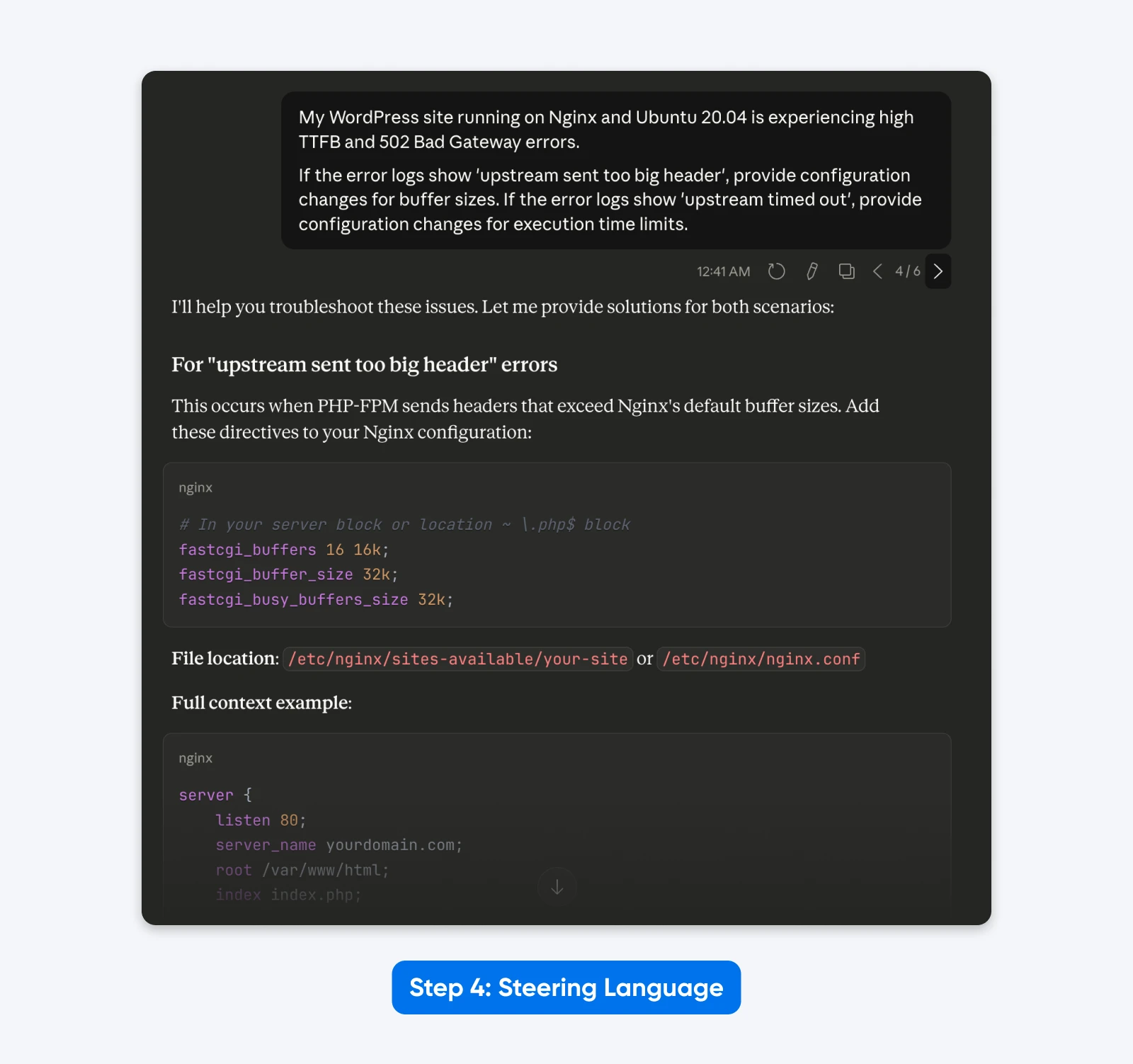
Le Résultat : Une consigne plus épurée qui se concentre uniquement sur la tâche technique, éliminant la distraction de “Tu es un expert” et “Pense pas à pas.”
5. Tester Systématiquement
Assemble les composants dans un format structuré en utilisant XML ou des en-têtes clairs. Cela correspond aux données d’entraînement du modèle et donne les résultats les plus cohérents.
RÔLE : Administrateur système Linux spécialisé dans la performance de Nginx et WordPress.
TÂCHE : Résoudre les erreurs 502 Bad Gateway et réduire le Time to First Byte (TTFB) pour un site WordPress sur Ubuntu 20.04.
LOGIQUE :
- Si les logs montrent 'upstream sent too big header', augmenter fastcgi_buffer_size et fastcgi_buffers.
- Si les logs montrent 'upstream timed out', augmenter fastcgi_read_timeout dans nginx.conf et request_terminate_timeout dans www.conf.
EXIGENCES DE SORTIE :
- Fournir les lignes de configuration exactes à modifier.
- Expliquer l'impact de chaque changement sur la mémoire du serveur.
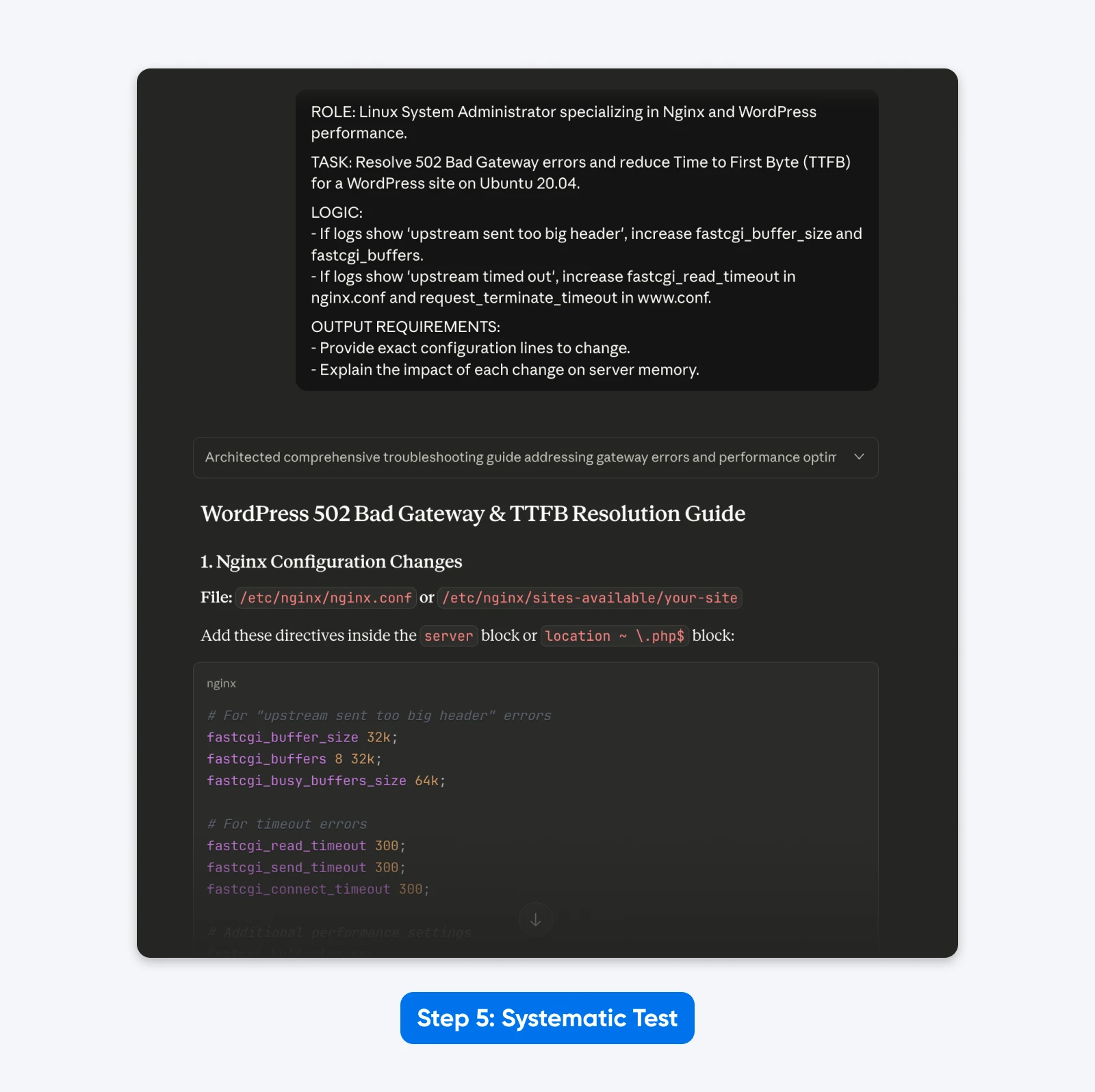
Le Résultat : La réponse était plus structurée, m’a permis de résoudre le problème avec des données de fichier de configuration pouvant être copiées-collées comme demandé et a mieux expliqué la solution.
Ce Que Cela Signifie Pour Ton Flux De Travail
Les modèles Claude 4.x fonctionnent différemment des modèles antérieurs. Ils suivent tes instructions exactes au lieu de supposer ce que tu voulais dire, ce qui est utile lorsque tu as besoin de résultats cohérents. L’effort que tu consacres à l’ingénierie des invites au début sera rentable si tu exécutes la même tâche de manière répétée.
Chaque technique dans ce guide a été soigneusement sélectionnée car elle s’aligne étroitement avec la manière dont Claude 4.x a été construit. Les balises XML, le mode de Pensée Étendue, les instructions explicites, les exemples à quelques essais, et une approche axée sur le contexte fonctionnent parce que, basé sur les guides de sollicitation de Claude et des preuves anecdotiques, c’est probablement ainsi qu’Anthropic a formé les modèles.
Alors vas-y, choisis une ou deux techniques de ce guide et teste-les sur tes flux de travail réels. Mesure ce qui change et quelles méthodes fonctionnent en ta faveur. La meilleure approche est celle soutenue par des données réelles issues de tes propres flux de travail quotidiens.

