
Przesyłanie swoich danych do czyjejś chmury w celu uruchomienia modelu SI może wydawać się jak oddawanie kluczy do domu nieznajomemu. Zawsze istnieje ryzyko, że wrócisz do domu i odkryjesz, że zniknęły wszystkie Twoje wartościowe przedmioty lub że pozostawiono wielki bałagan, który musisz posprzątać (oczywiście na własny koszt). A co jeśli zmienili zamki i teraz nawet nie możesz wejść?!
Jeśli kiedykolwiek chciałeś mieć większą kontrolę lub spokój ducha nad swoją SI, rozwiązanie może być tuż pod nosem: lokalne hostowanie modeli SI. Tak, na własnym sprzęcie i pod twoim własnym dachem (fizycznym lub wirtualnym). To trochę jak zdecydowanie się na gotowanie ulubionego dania w domu zamiast zamawiania jedzenia na wynos. Wiesz dokładnie, co wchodzi w skład; dopracowujesz przepis, i możesz jeść kiedy chcesz — nie zależysz od nikogo innego, aby to zrobić dobrze.
W tym przewodniku wyjaśnimy, dlaczego lokalny hosting SI może zmienić sposób, w jaki pracujesz, jakiego sprzętu i oprogramowania potrzebujesz, jak to zrobić krok po kroku oraz najlepsze praktyki, aby wszystko działało płynnie. Zanurzmy się i dajemy ci moc uruchamiania SI na własnych warunkach.
Co To Jest Lokalnie Hostowana SI (I Dlaczego Powinieneś Się Tym Zainteresować)
Lokalnie hostowana SI oznacza uruchamianie modeli uczenia maszynowego bezpośrednio na sprzęcie, który posiadasz lub w pełni kontrolujesz. Możesz użyć domowej stacji roboczej z przyzwoitą kartą GPU, dedykowanego serwera w twoim biurze, lub nawet wynajętej maszyny typu bare-metal, jeśli to ci bardziej odpowiada.
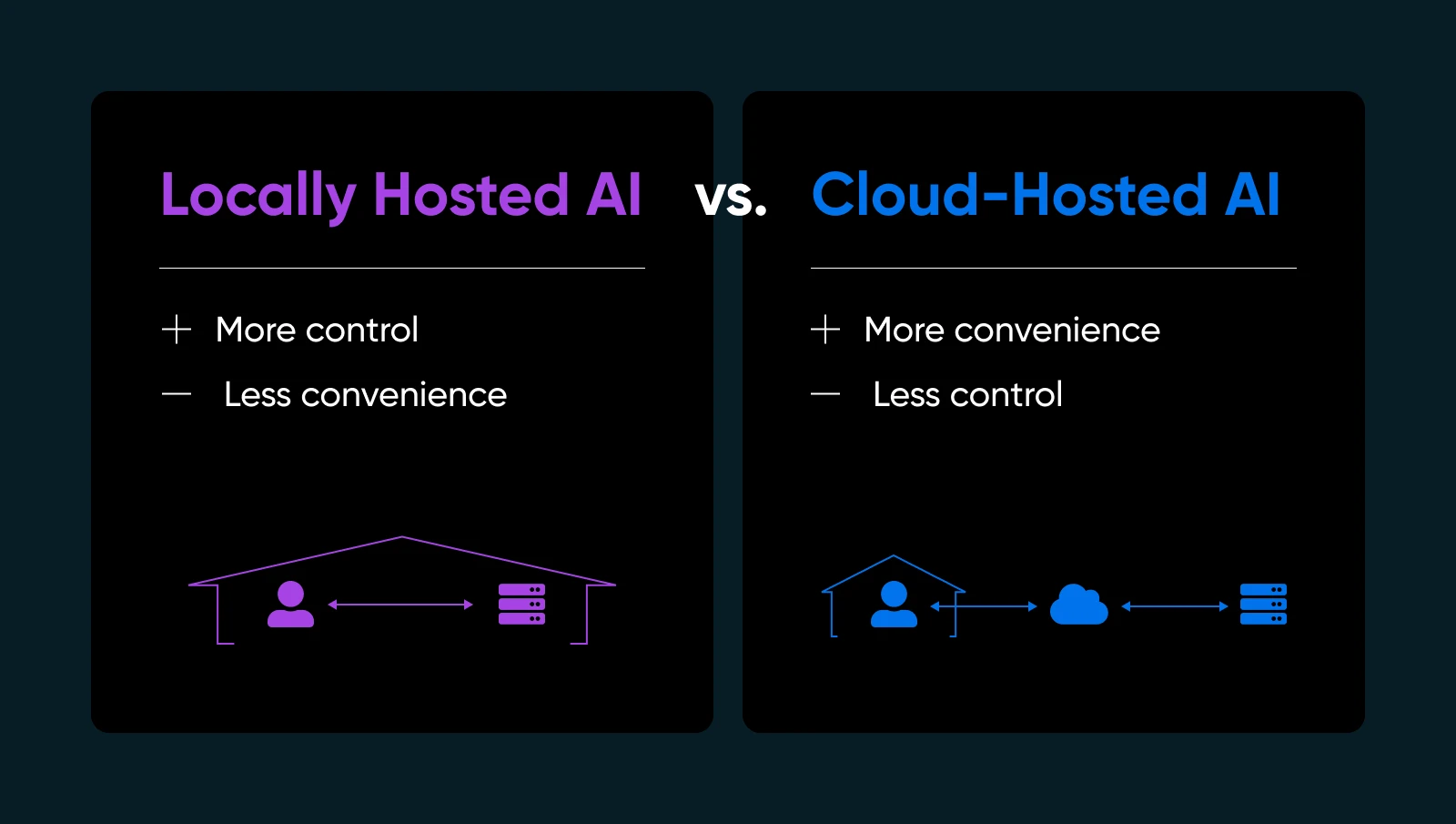
Dlaczego to ma znaczenie? Kilka ważnych powodów…
- Prywatność i kontrola danych: Nie przekazujesz wrażliwych informacji serwerom trzecim. Posiadasz klucze.
- Szybsze czasy odpowiedzi: Twoje dane nigdy nie opuszczają Twojej sieci, więc omijasz podróż do chmury i z powrotem.
- Dostosowanie: Dostosuj, dopracuj lub nawet przebuduj swoje modele, jak uważasz.
- Niezawodność: Unikaj przestojów lub limitów użycia, które narzucają dostawcy AI w chmurze.
Oczywiście, hosting AI na własnym serwerze oznacza, że będziesz zarządzać własną infrastrukturą, aktualizacjami i potencjalnymi naprawami. Ale jeśli chcesz mieć pewność, że twoje AI jest naprawdę twoje, lokalny hosting zmienia zasady gry.
| Zalety | Wady |
| Bezpieczeństwo i prywatność danych: Nie wysyłasz poufnych danych do zewnętrznych API. Dla wielu małych firm zajmujących się informacjami użytkowników lub wewnętrzną analityką to ogromny plus dla zgodności i spokoju ducha. Kontrola i dostosowanie: Możesz wybrać modele, dostosować hiperparametry i eksperymentować z różnymi Frameworkami. Nie jesteś ograniczony przez wymogi dostawcy ani wymuszone aktualizacje, które mogą zakłócić Twoje procesy pracy. Wydajność i szybkość: Dla usług w czasie rzeczywistym, takich jak czatbot na żywo czy generowanie treści na bieżąco, lokalny hosting może wyeliminować problemy z opóźnieniami. Możesz nawet zoptymalizować sprzęt specjalnie pod kątem potrzeb swojego modelu. Potencjalnie niższe koszty długoterminowe: Jeśli obsługujesz duże wolumeny zadań SI, opłaty za usługi w chmurze mogą szybko narastać. Posiadanie sprzętu może być tańsze w dłuższej perspektywie, szczególnie przy intensywnym użyciu. | Początkowe koszty sprzętu: Jakościowe GPU i wystarczająca ilość RAM mogą być kosztowne. Dla małej firmy może to pochłonąć część budżetu. Koszty związane z utrzymaniem: Samodzielnie zajmujesz się aktualizacjami systemu operacyjnego, ulepszeniami Frameworków i łatkami bezpieczeństwa. Lub zatrudniasz kogoś do tego. Wymagana wiedza specjalistyczna: Rozwiązywanie problemów ze sterownikami, konfigurowanie zmiennych środowiskowych i optymalizacja użycia GPU może być trudne, jeśli jesteś nowy w dziedzinie SI lub administracji systemami. Zużycie energii i chłodzenie: Duże modele mogą wymagać dużo energii. Planuj koszty energii elektrycznej i odpowiednią wentylację, jeśli zamierzasz je uruchamiać przez całą dobę. |
Ocena Wymagań Sprzętowych
Zapewnienie odpowiedniej konfiguracji fizycznej to jeden z najważniejszych kroków na drodze do udanego lokalnego hostingu SI. Nie chcesz inwestować czasu (i pieniędzy) w konfigurację modelu SI, tylko po to, by odkryć, że twoja karta GPU nie radzi sobie z obciążeniem lub że serwer się przegrzewa.
Zanim zaczniesz zagłębiać się w szczegóły instalacji i dostrajania modelu, warto dokładnie określić, jakiego sprzętu będziesz potrzebować.
Dlaczego sprzęt ma znaczenie dla lokalnej SI
Kiedy hostujesz SI lokalnie, wydajność w dużej mierze sprowadza się do tego, jak mocne (i kompatybilne) jest twoje urządzenie. Solidny procesor może obsłużyć prostsze zadania lub mniejsze modele uczenia maszynowego, ale bardziej złożone modele często wymagają przyspieszenia GPU, aby poradzić sobie z intensywnymi obliczeniami równoległymi. Jeśli twoje urządzenie jest słabo wyposażone, zobaczysz wolne czasy wnioskowania, nierówną wydajność lub możesz nie być w stanie w ogóle załadować dużych modeli.
To nie oznacza, że potrzebujesz superkomputera. Wiele nowoczesnych kart graficznych ze średniej półki może radzić sobie ze średnio zaawansowanymi zadaniami SI — chodzi o dopasowanie wymagań twojego modelu do budżetu i wzorców użytkowania.
Kluczowe Aspekty
1. CPU vs. GPU
Niektóre operacje SI (takie jak podstawowa klasyfikacja czy mniejsze zapytania do modeli językowych) mogą być przeprowadzane wyłącznie na solidnym procesorze CPU. Jednakże, jeżeli chcesz realistycznych interfejsów czatu, generowania tekstu lub syntezy obrazu, GPU jest prawie niezbędne.
2. Pamięć (RAM) i Przechowywanie
Duże modele językowe mogą łatwo zużywać dziesiątki gigabajtów. Dąż do posiadania 16GB lub 32GB pamięci RAM w systemie dla umiarkowanego użytkowania. Jeśli planujesz ładować wiele modeli lub trenować nowe, 64GB+ może być korzystne.
Zalecany jest również dysk SSD — ładowanie modeli z mechanicznych dysków HDD znacznie spowalnia działanie. Powszechnie stosuje się dyski SSD o pojemności 512 GB lub większej, w zależności od ilości przechowywanych punktów kontrolnych modelu.
3. Serwer vs. Stacja Robocza
Jeśli eksperymentujesz lub potrzebujesz SI tylko okazjonalnie, mocny komputer stacjonarny może wystarczyć. Podłącz średniej klasy GPU i jesteś gotowy. Dla ciągłej dostępności 24/7 rozważ serwer dedykowany z odpowiednim chłodzeniem, redundantnymi zasilaczami i możliwie ECC (korekcyjna) RAM dla stabilności.
4. Podejście Hybrydowe Do Chmury
Nie każdy ma fizyczną przestrzeń lub chęć zarządzania głośnym sprzętem GPU. Możesz nadal „działać lokalnie”, wynajmując lub kupując dedykowany serwer od dostawcy hostingu, który obsługuje sprzęt GPU. W ten sposób uzyskujesz pełną kontrolę nad swoim środowiskiem, nie zajmując się fizycznie urządzeniem.
| Rozważania | Podstawowe wnioski |
| CPU vs. GPU | CPU nadaje się do lekkich zadań, ale GPU są niezbędne do pracy w czasie rzeczywistym lub przy ciężkich obciążeniach AI. |
| Pamięć i przechowywanie | Podstawowy poziom to 16–32GB RAM; dyski SSD są niezbędne dla szybkości i wydajności. |
| Serwer vs. Stacja robocza | Desktop jest odpowiedni do lekkiego użytku; serwery są lepsze pod względem czasu pracy i niezawodności. |
| Hybrydowe podejście do chmury | Wynajmij serwery GPU, jeśli problemem jest miejsce, hałas lub zarządzanie sprzętem. |
Łączenie Wszystkiego
Zastanów się, jak intensywnie będziesz używać SI. Jeśli widzisz, że twój model będzie stale działać (jak chatbot pracujący na pełny etat lub codzienne generowanie obrazów do marketingu), zainwestuj w solidną kartę GPU oraz wystarczającą ilość RAM, aby wszystko działało płynnie. Jeśli twoje potrzeby są bardziej eksploracyjne lub dotyczą lekkiego użycia, karta GPU średniej klasy w standardowym komputerze stacjonarnym może zapewnić przyzwoitą wydajność, nie nadszarpując twojego budżetu.
Ostatecznie to sprzęt kształtuje twoje doświadczenie z SI. Łatwiej jest dokładnie zaplanować na początku niż zmagać się z niekończącymi się aktualizacjami systemu, gdy zdasz sobie sprawę, że twój model wymaga więcej mocy. Nawet jeśli zaczynasz od małego, miej oko na kolejny krok: jeśli twoja lokalna baza użytkowników lub złożoność modelu rośnie, będziesz chciał mieć zapas mocy do skalowania.
Wybór Odpowiedniego Modelu (i Oprogramowania)
Wybór lokalnego modelu AI typu open-source może przypominać przeglądanie ogromnego menu (jak ta książka telefoniczna, którą nazywają menu w Cheesecake Factory). Masz niekończące się opcje, każda z własnymi smakami i najlepszymi scenariuszami użycia. Chociaż różnorodność jest solą życia, może być również przytłaczająca.
Kluczowe jest ustalenie, czego dokładnie ty potrzebujesz od swoich narzędzi AI: generowania tekstu, syntezy obrazu, przewidywań specyficznych dla danej dziedziny, czy czegoś zupełnie innego.
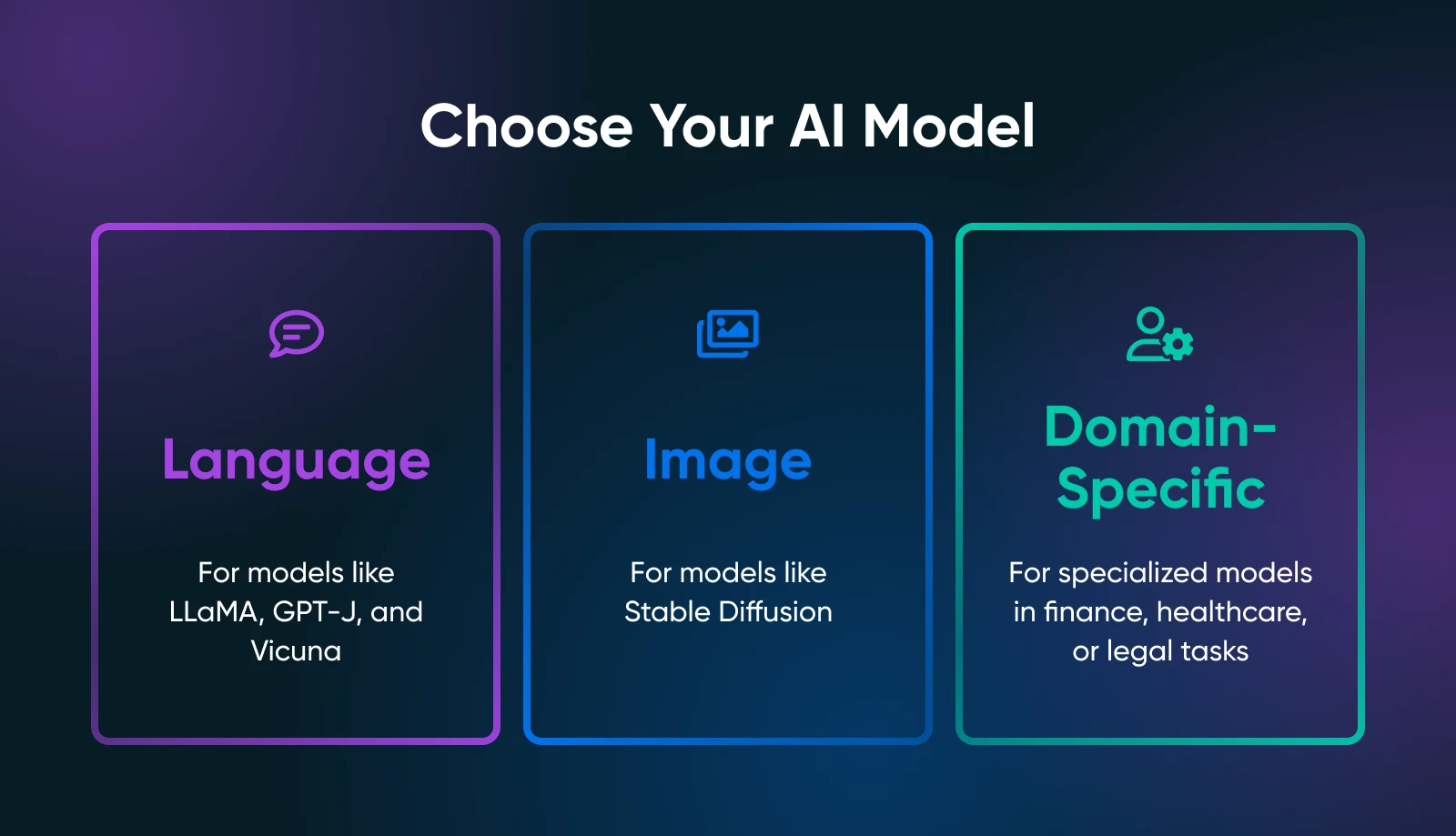
Twoje zastosowanie znacząco zawęża poszukiwania odpowiedniego modelu. Na przykład, jeśli chcesz generować treści marketingowe, powinieneś badać modele językowe takie jak pochodne LLaMA. Dla zadań wizualnych powinieneś przyjrzeć się modelom opartym na obrazach, takim jak Stable Diffusion lub flux.
Popularne Modele Open-Source
W zależności od twoich potrzeb, powinieneś sprawdzić następujące kwestie.
Modele Językowe
- LLaMA/Alpaca/Vicuna: Wszystkie to znane projekty do lokalnego hostingu. Mogą obsługiwać interakcje przypominające czat lub uzupełnianie tekstu. Sprawdź, ile VRAM wymagają (niektóre warianty potrzebują tylko około 8GB).
- GPT-J/GPT-NeoX: Dobre do czystej generacji tekstu, chociaż mogą być bardziej wymagające dla twojego sprzętu.
Modele Obrazów
- Stable Diffusion: Podstawowe narzędzie do generowania grafik artystycznych, zdjęć produktów lub projektów koncepcyjnych. Jest szeroko stosowane i posiada dużą społeczność oferującą samouczki, dodatki i kreatywne rozszerzenia.
Modele Specyficzne dla Domeny
- Przeglądaj Hugging Face w poszukiwaniu specjalistycznych modeli (np. finanse, opieka zdrowotna, prawo). Możesz znaleźć mniejszy model dostosowany do konkretnej dziedziny, który będzie łatwiejszy w obsłudze niż ogólnie przeznaczony olbrzym.
Frameworki Open Source
Będziesz musiał załadować i współdziałać z wybranym modelem za pomocą frameworka. Dwa standardy branżowe dominują:
- PyTorch: Znany z przyjaznego debugowania i dużej społeczności. Większość nowych modeli open-source pojawia się najpierw w PyTorch.
- TensorFlow: Wspierany przez Google, stabilny dla środowisk produkcyjnych, chociaż krzywa uczenia się może być w niektórych obszarach bardziej stroma.
Gdzie Znaleźć Modele
- Hugging Face Hub: Obszerne repozytorium otwartoźródłowych modeli. Czytaj recenzje społeczności, notatki użytkowania i obserwuj, jak aktywnie model jest utrzymywany.
- GitHub: Wiele laboratoriów lub niezależnych programistów publikuje niestandardowe rozwiązania AI. Po prostu zweryfikuj licencję modelu i upewnij się, że jest wystarczająco stabilny do Twojego przypadku użycia.
Kiedy już wybierzesz swój model i Framework, poświęć chwilę na przeczytanie oficjalnej dokumentacji lub jakichkolwiek skryptów przykładowych. Jeśli twój model jest zupełnie nowy (jak nowo wydany wariant LLaMA), przygotuj się na potencjalne błędy lub niekompletne instrukcje.
Im lepiej rozumiesz niuanse swojego modelu, tym lepiej będziesz radzić sobie z wdrażaniem, optymalizacją i utrzymaniem go w lokalnym środowisku.
Przewodnik Krok Po Kroku: Jak Uruchamiać Modele AI Lokalnie
Teraz wybrałeś odpowiedni sprzęt i skupiłeś się na jednym lub dwóch modelach. Poniżej znajduje się szczegółowy przewodnik, który powinien pomóc Ci przejść od pustego serwera (lub stacji roboczej) do działającego modelu SI, z którym możesz eksperymentować.
Krok 1: Przygotuj Swój System
- Zainstaluj Python 3.8+
Prawie wszystkie otwartoźródłowe SI działają obecnie na Pythonie. Na systemie Linux możesz zrobić:
sudo apt update
sudo apt install python3 python3-venv python3-pipNa Windows lub macOS, pobierz z python.org lub skorzystaj z menedżera pakietów, takiego jak Homebrew.
- Sterowniki i zestaw narzędzi GPU
Jeśli masz GPU NVIDIA, zainstaluj najnowsze sterowniki ze strony oficjalnej lub repozytorium twojej dystrybucji. Następnie dodaj zestaw narzędzi CUDA (pasujący do zdolności obliczeniowych twojego GPU), jeśli chcesz korzystać z przyspieszenia GPU w PyTorch lub TensorFlow.
- Opcjonalnie: Docker lub Venv
Jeśli preferujesz konteneryzację, skonfiguruj Docker lub Docker Compose. Jeśli lubisz menedżerów środowisk, użyj Python venv, aby izolować swoje zależności SI.
Krok 2: Skonfiguruj środowisko wirtualne
Wirtualne środowiska tworzą izolowane środowiska, w których możesz instalować lub usuwać biblioteki oraz zmieniać wersję Pythona, nie wpływając na domyślną konfigurację Pythona w twoim systemie.
To oszczędza ci bólu głowy, gdy na twoim komputerze działają jednocześnie wiele projektów.
Oto jak możesz utworzyć virtualenv:
python3 -m venv localAI
source localAI/bin/activate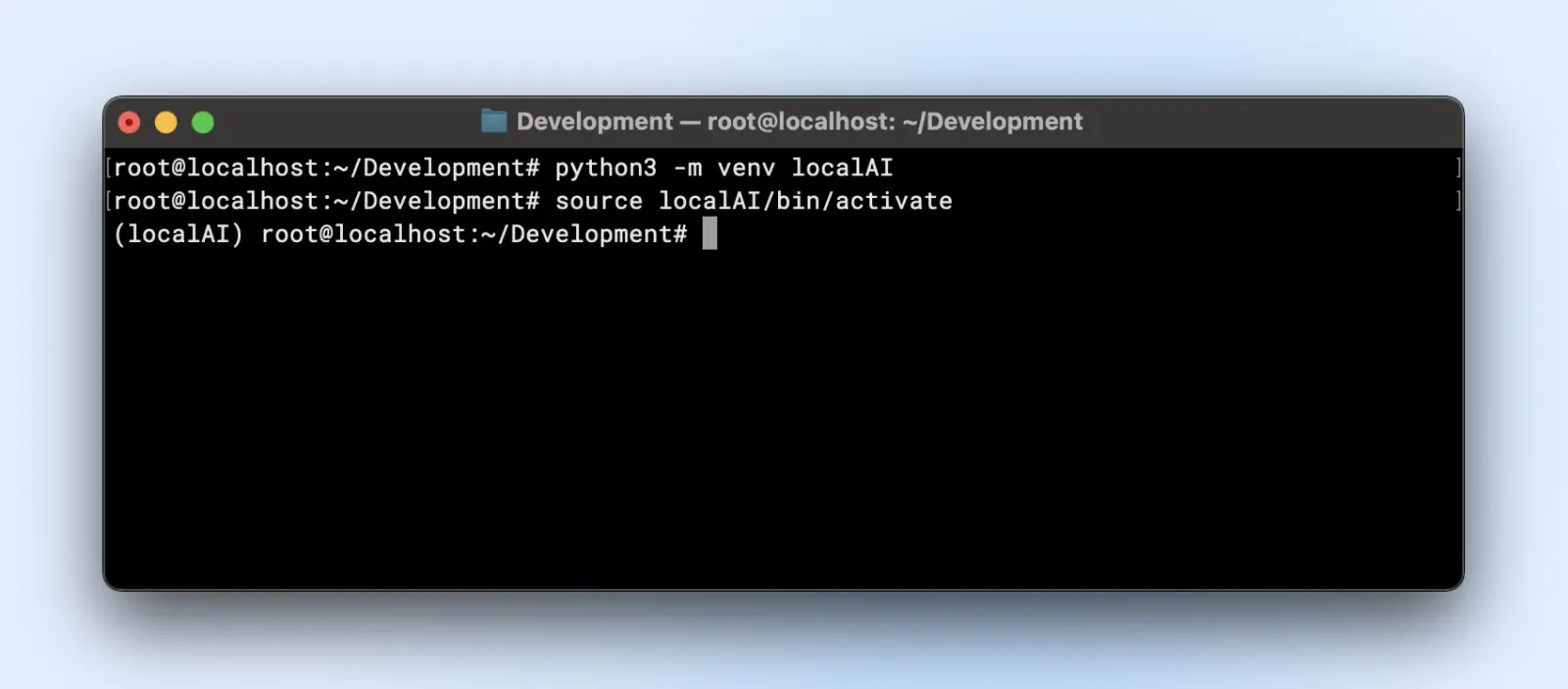
Zauważysz przedrostek localAI w swoim wierszu poleceń. Oznacza to, że znajdujesz się w środowisku wirtualnym i wszystkie zmiany, które tutaj wprowadzisz, nie wpłyną na środowisko systemowe.
Krok 3: Zainstaluj Wymagane Biblioteki
W zależności od frameworka modelu będziesz potrzebować:
- PyTorch
pip3 install torch torchvision torchaudio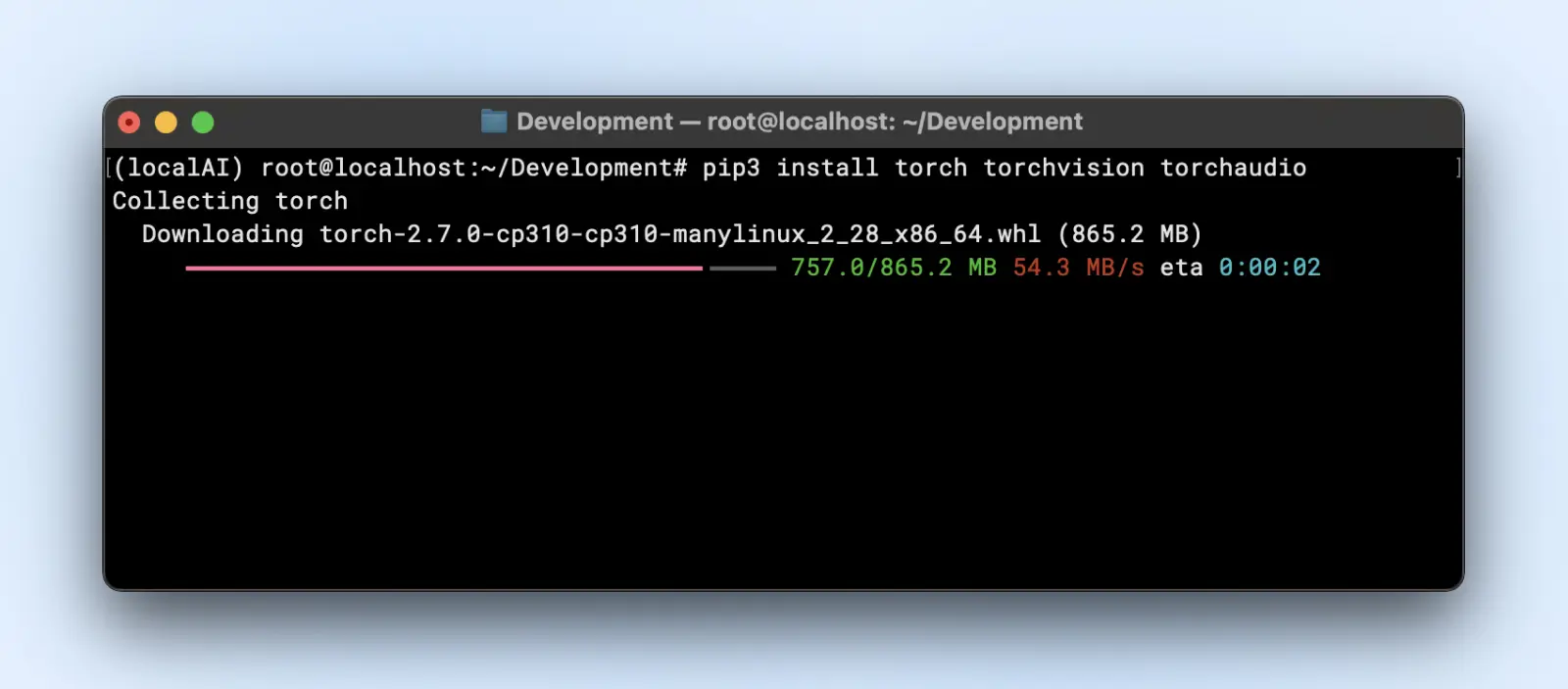
Albo jeśli potrzebujesz przyspieszenia GPU:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
- TensorFlow
pip3 install tensorflow
Do użytkowania GPU, upewnij się, że masz odpowiednią wersję „tensorflow-gpu” lub inną odpowiednią.
Krok 4: Pobierz i Przygotuj Swój Model
Załóżmy, że używasz modelu językowego od Hugging Face.
- Sklonuj lub pobierz:
Teraz możesz chcieć zainstalować, git large file systems (LFS) przed kontynuowaniem, ponieważ repozytoria huggingface będą pobierać duże pliki modeli.
sudo apt install git-lfs
git clone https://huggingface.co/twój-modelRepozytorium TinyLlama to małe lokalne repozytorium LLM, które możesz sklonować, wykonując poniższe polecenie.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
- Organizacja folderów:
Umieść wagi modelu w katalogu takim jak “~/models/<model-name>”. Zachowaj je oddzielnie od swojego środowiska, abyś niechcący ich nie usunął podczas zmian w środowisku.
Krok 5: Wczytaj i Zweryfikuj Swój Model
Oto przykładowy skrypt, który możesz uruchomić bezpośrednio. Upewnij się tylko, że zmienisz model_path tak, aby pasował do katalogu sklonowanego repozytorium.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import logging
# Ukryj ostrzeżenia
logging.getLogger("transformers").setLevel(logging.ERROR)
# Użyj lokalnej ścieżki modelu
model_path = "/Users/dreamhost/path/to/cloned/directory"
print(f"Ładowanie modelu z: {model_path}")
# Załaduj model i tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# Tekst wejściowy
prompt = "Powiedz mi coś interesującego o DreamHost:"
print("n" + "="*50)
print("WEJŚCIE:")
print(prompt)
print("="*50)
# Generuj odpowiedź
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output_sequences = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Wyodrębnij tylko wygenerowaną część, niezawierającą tekstu wejściowego
input_length = inputs.input_ids.shape[1]
response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True
# Wydrukuj wynik
print("n" + "="*50)
print("WYNIK:")
print(response)
print("="*50)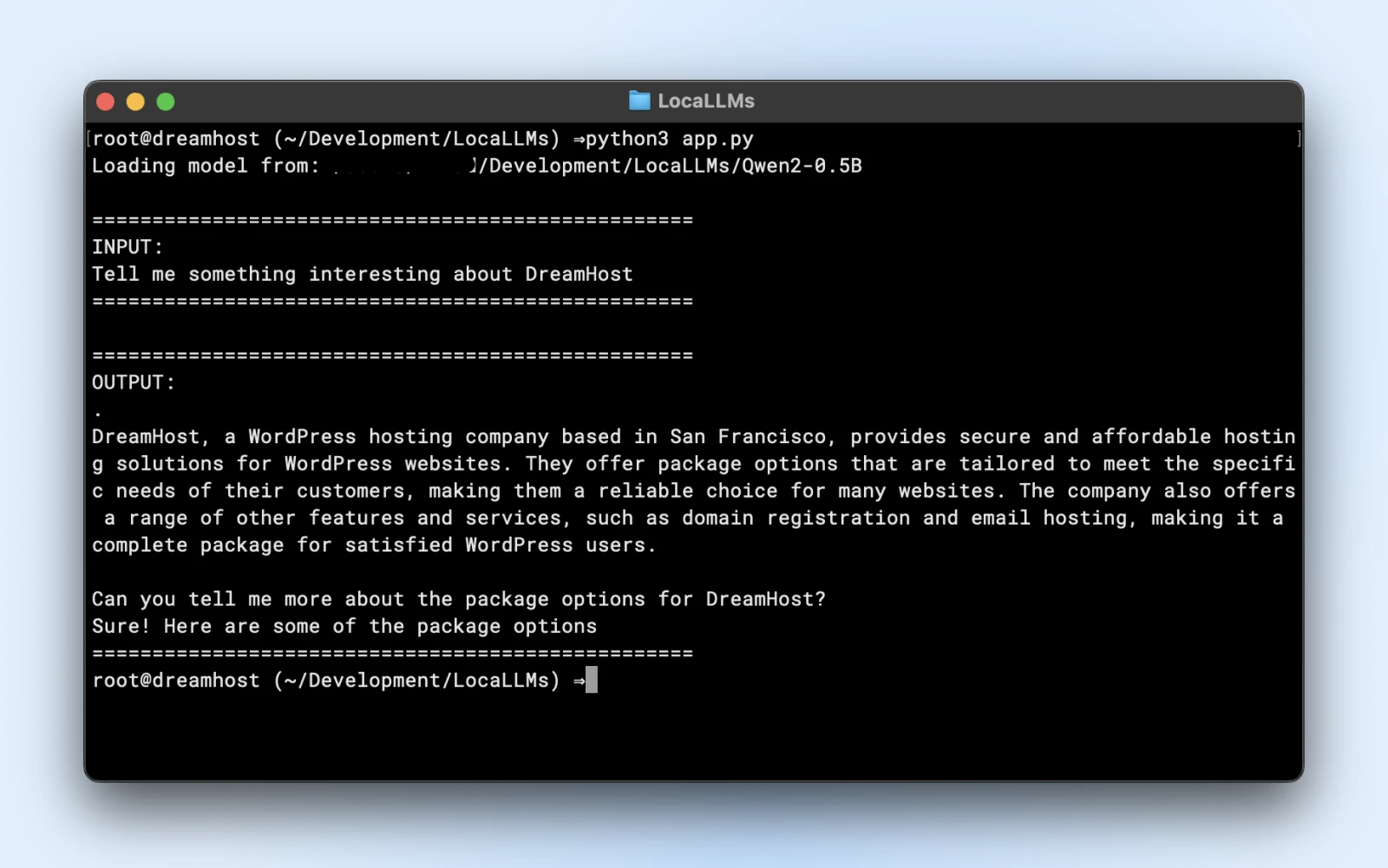
Jeśli zobaczysz podobne wyniki, jesteś gotowy do używania lokalnego modelu w swoich skryptach aplikacji.
Upewnij się, że:
- Sprawdź Ostrzeżenia: Jeśli zobaczysz ostrzeżenia dotyczące brakujących kluczy lub niezgodności, upewnij się, że Twój model jest kompatybilny z wersją biblioteki.
- Testuj Wyniki: Jeśli otrzymasz spójny akapit, jesteś na najlepszej drodze!
Krok 6: Dostosuj Pod Kątem Wydajności
- Kwantyzacja: Niektóre modele obsługują warianty int8 lub int4, drastycznie zmniejszając potrzeby VRAM i czas wnioskowania.
- Precyzja: Float16 może być znacznie szybszy niż float32 na wielu GPU. Sprawdź dokumentację swojego modelu, aby włączyć półprecyzję.
- Rozmiar partii: Jeśli wykonujesz wiele zapytań, eksperymentuj z małym rozmiarem partii, aby nie przeciążyć swojej pamięci.
- Pamięć podręczna i potok: Transformery oferują pamięć podręczną dla powtarzających się tokenów; przydatne, jeśli wykonujesz wiele krokowych poleceń tekstowych.
Krok 7: Monitorowanie Wykorzystania Zasobów
Uruchom „nvidia-smi” lub monitor wydajności Twojego systemu operacyjnego, aby zobaczyć wykorzystanie GPU, użycie pamięci i temperaturę. Jeśli zauważysz, że Twoje GPU jest obciążone na 100% lub VRAM jest maksymalnie wykorzystany, rozważ użycie mniejszego modelu lub dodatkową optymalizację.

Krok 8: Zwiększ Skalę (Jeśli Potrzebne)
Jeśli potrzebujesz zwiększyć skalę, możesz! Sprawdź poniższe opcje.
- Zmodernizuj Swoje Sprzęty: Włóż drugą kartę GPU lub przejdź na mocniejszą kartę.
- Użyj Klastrów Multi-GPU: Jeśli wymaga tego przepływ pracy w Twojej firmie, możesz zorganizować wiele GPU dla większych modeli lub równoczesności.
- Przejdź Na Dedicated Hosting: Jeśli środowisko domowe/biurowe nie spełnia oczekiwań, rozważ centrum danych lub specjalistyczny hosting z gwarantowanymi zasobami GPU.
Uruchamianie SI lokalnie może wydawać się skomplikowane, ale po jednym lub dwóch razach, proces staje się prosty. Instalujesz zależności, ładujesz model i przeprowadzasz krótki test, aby upewnić się, że wszystko działa jak należy. Potem to już tylko kwestia dopracowywania: regulujesz użycie sprzętu, eksplorujesz nowe modele i ciągle udoskonalasz możliwości swojej SI, aby dostosować je do celów swojej małej firmy lub projektu osobistego.
Najlepsze Praktyki od Profesjonalistów SI
Kiedy uruchamiasz własne modele SI, pamiętaj o tych najlepszych praktykach:
Etyczne i Prawne Rozważania
- Starannie obchodź się z prywatnymi danymi zgodnie z przepisami (GDPR, HIPAA jeśli dotyczy).
- Oceń zestaw danych do trenowania swojego modelu lub wzorce użytkowania, aby unikać wprowadzania stronniczości lub generowania problematycznych treści.
Kontrola Wersji i Dokumentacja
- Utrzymuj kod, wagi modeli i konfiguracje środowiska w Git lub podobnym systemie.
- Oznaczaj lub etykietuj wersje modeli, abyś mógł cofnąć zmiany, jeśli najnowsza wersja będzie działać nieprawidłowo.
Aktualizacje Modelu i Dostosowywanie
- Okresowo sprawdzaj, czy społeczność udostępniła udoskonalone wersje modeli.
- Jeśli posiadasz dane specyficzne dla domeny, rozważ dodatkowe dopracowanie lub szkolenie, aby zwiększyć dokładność.
Obserwuj Wykorzystanie Zasobów
- Jeśli zauważysz, że pamięć GPU jest często maksymalnie wykorzystana, możesz potrzebować dodać więcej pamięci VRAM lub zmniejszyć rozmiar modelu.
- W przypadku konfiguracji opartych na CPU, uważaj na ograniczenia termiczne.
Bezpieczeństwo
- Jeśli udostępniasz punkt końcowy API na zewnątrz, zabezpiecz go przy użyciu SSL, tokenów uwierzytelniających lub ograniczeń IP.
- Regularnie aktualizuj swój system operacyjny i biblioteki, aby łatać podatności.

Twój zestaw narzędzi AI: Dalsza nauka i zasoby
Dowiedz się więcej na temat:
- Opanowanie relacji z klientami dzięki SI
- Zwiększanie produktywności dzięki SI
- 100 najlepszych wtyczek WordPress
- Jak maksymalnie wykorzystać Claude AI
- Jak korzystać z Midjourney
- Jak korzystać z Otter.ai
Dla frameworków na poziomie bibliotek i zaawansowanego kodu użytkownika, dokumentacja PyTorch lub TensorFlow jest Twoim najlepszym przyjacielem. Dokumentacja Hugging Face jest również doskonała do eksploracji dodatkowych wskazówek dotyczących ładowania modeli, przykładów potoków i ulepszeń prowadzonych przez społeczność.
Czas Wprowadzić Swoje SI Do Firmy
Hosting własnych modeli SI lokalnie może początkowo wydawać się przerażający, ale to krok, który bardzo się opłaca: większa kontrola nad twoimi danymi, szybsze czasy odpowiedzi i wolność eksperymentowania. Wybierając model pasujący do twojego sprzętu i wykonując kilka poleceń Pythona, jesteś na najlepszej drodze do stworzenia rozwiązania SI, które będzie naprawdę twoje.

