
Enviar seus dados para a nuvem de outra pessoa para rodar um modelo de IA pode parecer como entregar as chaves da sua casa para um estranho. Há sempre a chance de você voltar para casa e descobrir que eles fugiram com todos os seus objetos de valor ou deixaram uma grande bagunça para você limpar (à sua custa, é claro). Ou e se eles mudaram as fechaduras e agora você nem consegue entrar?!
Se alguma vez quiseste mais controle ou tranquilidade sobre a tua IA, a solução pode estar bem debaixo do teu nariz: hospedar modelos de IA localmente. Sim, no teu próprio hardware e sob o teu próprio teto (físico ou virtual). É como decidir cozinhar o teu prato favorito em casa em vez de pedir comida de fora. Sabes exatamente o que entra nele; ajustas a receita, e podes comer quando quiseres — sem depender de mais ninguém para acertar.
Neste guia, vamos explicar por que a hospedagem local de IA pode transformar a maneira como você trabalha, quais hardware e software são necessários, como fazer isso passo a passo, e as melhores práticas para manter tudo funcionando perfeitamente. Vamos mergulhar e dar a você o poder de executar a IA em seus próprios termos.
O Que É IA Hospedada Localmente (e Por Que Você Deve Se Importar)
A hospedagem local de IA significa executar modelos de aprendizado de máquina diretamente em equipamentos que você possui ou controla totalmente. Você pode usar uma estação de trabalho em casa com uma GPU decente, um servidor dedicado em seu escritório ou até mesmo uma máquina bare-metal alugada, se isso for melhor para você.
Por que isso é importante? Algumas razões importantes…
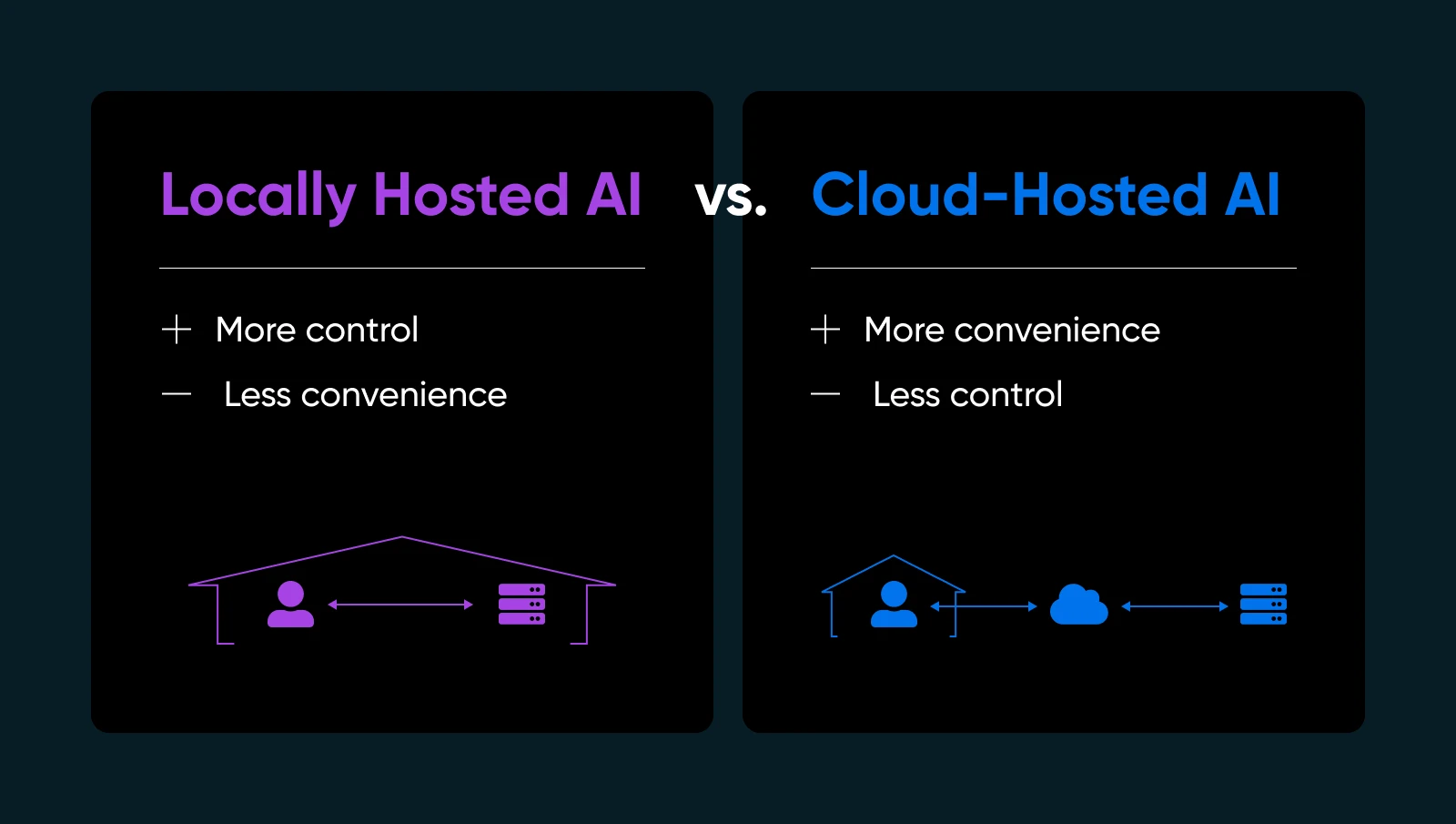
- Privacidade e Controle dos Dados: Não envia informações sensíveis para servidores de terceiros. Você detém as chaves.
- Tempos de Resposta Mais Rápidos: Seus dados nunca saem da sua rede, então você evita a ida e volta para a nuvem.
- Personalização: Ajuste, refine ou até reestruture seus modelos como achar melhor.
- Confiabilidade: Evite inatividade ou limites de uso que os provedores de IA na nuvem impõem.
Claro, hospedar a IA por conta própria significa que você gerenciará sua própria infraestrutura, atualizações e possíveis correções. Mas se você quer ter certeza de que sua IA é realmente sua, a hospedagem local é uma mudança radical.
| Prós | Contras |
| Segurança e privacidade de dados: Você não envia dados proprietários para APIs externas. Para muitas pequenas empresas que lidam com informações de usuários ou análises internas, isso é um grande benefício para a conformidade e tranquilidade. Controle e personalização: Você tem liberdade para escolher modelos, ajustar hiperparâmetros e experimentar diferentes frameworks. Você não está limitado por restrições de fornecedores ou atualizações forçadas que podem interromper seus fluxos de trabalho. Desempenho e velocidade: Para serviços em tempo real, como um chatbot ao vivo ou geração de conteúdo instantâneo, a hospedagem local pode eliminar problemas de latência. Você pode até otimizar o hardware especificamente para as necessidades do seu modelo. Potencialmente menores custos a longo prazo: Se você gerenciar grandes volumes de tarefas de IA, as taxas de cloud podem acumular rapidamente. Possuir o hardware pode ser mais barato ao longo do tempo, especialmente para uso intenso. | Custos iniciais de hardware: GPUs de qualidade e RAM suficiente podem ser caros. Para uma pequena empresa, isso pode consumir parte do orçamento. Custos de manutenção: Você lida com atualizações do OS, upgrades de framework e patches de segurança. Ou você contrata alguém para fazer isso. Expertise necessária: Solucionar problemas de drivers, configurar variáveis de ambiente e otimizar o uso de GPU pode ser complicado se você é novo em IA ou administração de sistemas. Uso de energia e refrigeração: Modelos grandes podem exigir muita energia. Planeje os custos de eletricidade e ventilação adequada se você os operar continuamente. |
Avaliando Requisitos de Hardware
Ter o seu setup físico correto é um dos maiores passos para o sucesso da hospedagem local de IA. Você não quer investir tempo (e dinheiro) configurando um modelo de IA, apenas para descobrir que sua GPU não pode suportar a carga ou seu servidor superaquece.
Então, antes de mergulhar nos detalhes da instalação e ajuste fino do modelo, vale a pena mapear exatamente que tipo de hardware você precisará.
Por Que o Hardware é Importante para IA Local
Quando você está hospedando IA localmente, o desempenho depende muito da potência (e compatibilidade) do seu hardware. Um CPU robusto pode gerenciar tarefas mais simples ou modelos de aprendizado de máquina menores, mas modelos mais profundos frequentemente necessitam de aceleração GPU para lidar com os intensos cálculos paralelos. Se o seu hardware for insuficiente, você verá tempos de inferência lentos, desempenho irregular ou pode falhar ao carregar modelos grandes completamente.
Isso não significa que você precise de um supercomputador. Muitas GPUs de médio alcance modernas podem lidar com tarefas de IA em escala média — é tudo uma questão de adequar as demandas do seu modelo ao seu orçamento e padrões de uso.
Considerações Principais
1. CPU vs. GPU
Algumas operações de IA (como classificação básica ou consultas de modelos de linguagem menores) podem ser executadas apenas em uma CPU sólida. No entanto, se você deseja interfaces de chat em tempo real, geração de texto ou síntese de imagens, uma GPU é quase indispensável.
2. Memória (RAM) E Armazenamento
Modelos de linguagem grandes podem facilmente consumir dezenas de gigabytes. Opte por 16GB ou 32GB de RAM do sistema para uso moderado. Se você planeja carregar vários modelos ou treinar novos, 64GB ou mais podem ser benéficos.
Um SSD também é altamente recomendado — carregar modelos de HDDs convencionais torna tudo mais lento. Um SSD de 512GB ou maior é comum, dependendo de quantos pontos de controle de modelo você armazena.
3. Servidor vs. Estação de Trabalho
Se você está apenas experimentando ou precisa da IA ocasionalmente, um desktop poderoso pode dar conta do recado. Conecte uma GPU de médio alcance e você estará pronto. Para uma disponibilidade contínua de 24/7, considere um servidor dedicado com refrigeração adequada, fontes de alimentação redundantes e possivelmente RAM com ECC (correção de erros) para estabilidade.
4. Abordagem de Nuvem Híbrida
Nem todos têm o espaço físico ou o desejo de gerenciar um equipamento de GPU barulhento. Você ainda pode “ficar local” alugando ou comprando um servidor dedicado de um provedor de hospedagem que suporte hardware de GPU. Assim, você obtém controle total sobre seu ambiente sem ter que manter fisicamente a caixa.
| Consideração | Conclusão Principal |
| CPU vs. GPU | CPUs são adequadas para tarefas leves, mas GPUs são essenciais para IA em tempo real ou pesada. |
| Memória e Armazenamento | 16–32GB de RAM é a base; SSDs são essenciais para velocidade e eficiência. |
| Servidor vs. Estação de Trabalho | Desktops são adequados para uso leve; servidores são melhores para uptime e confiabilidade. |
| Abordagem de Nuvem Híbrida | Alugue servidores GPU se espaço, ruído ou gestão de hardware for uma preocupação. |
Reunindo Tudo
Pense em quão intensamente você usará a IA. Se você perceber que seu modelo está constantemente em ação (como um chatbot em tempo integral ou geração diária de imagens para marketing), invista em uma GPU robusta e RAM suficiente para manter tudo funcionando sem problemas. Se suas necessidades forem mais exploratórias ou de uso leve, um cartão de GPU de médio porte em uma estação de trabalho padrão pode oferecer um desempenho decente sem destruir seu orçamento.
Em última análise, o hardware molda sua experiência com IA. É mais fácil planejar cuidadosamente desde o início do que lidar com atualizações constantes do sistema quando você perceber que seu modelo requer mais recursos. Mesmo que você comece pequeno, fique atento ao seu próximo passo: se sua base de usuários local ou a complexidade do modelo crescer, você vai querer espaço para escalar.
Escolhendo O Modelo Certo (e Software)
Escolher um modelo de IA de código aberto para rodar localmente pode parecer como olhar para um cardápio gigante (como aquele livro que chamam de cardápio na Cheesecake Factory). Você tem infinitas opções, cada uma com seus próprios sabores e cenários de melhor uso. Embora a variedade seja o tempero da vida, também pode ser avassaladora.
O segredo é definir exatamente o que você precisa das suas ferramentas de IA: geração de texto, síntese de imagem, previsões específicas para o domínio ou algo completamente diferente.
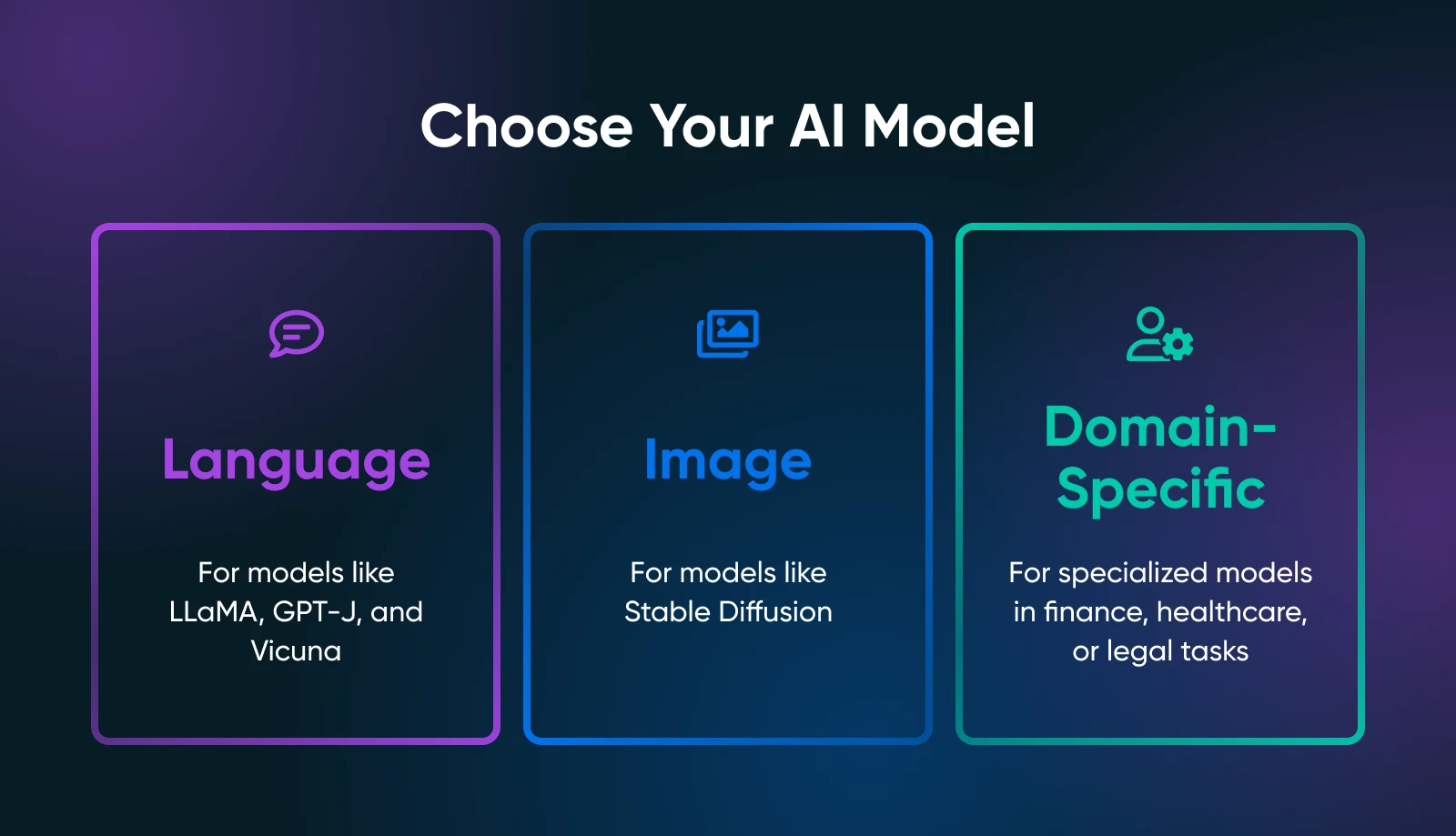
Seu caso de uso restringe drasticamente a busca pelo modelo certo. Por exemplo, se deseja gerar cópias de marketing, você deveria explorar modelos de linguagem como derivados de LLaMA. Para tarefas visuais, você examinaria modelos baseados em imagens como Stable Diffusion ou flux.
Modelos Open-Source Populares
Dependendo das tuas necessidades, deves verificar o seguinte.
Modelos de Linguagem
- LLaMA/ Alpaca / Vicuna: Projetos bem conhecidos para hospedagem local. Eles podem lidar com interações semelhantes a chat ou completar textos. Verifique quanto de VRAM eles necessitam (algumas variantes precisam de apenas ~8GB).
- GPT-J / GPT-NeoX: Bom para geração de texto puro, embora possam exigir mais do seu hardware.
Modelos de Imagem
- Stable Diffusion: Uma referência para a geração de arte, imagens de produtos ou designs conceituais. É amplamente utilizado e possui uma grande comunidade que oferece tutoriais, complementos e expansões criativas.
Modelos Específicos de Domínio
- Navegue pela Hugging Face para modelos especializados (por exemplo, finanças, saúde, jurídico). Você pode encontrar um modelo menor e ajustado ao domínio que é mais fácil de executar do que um gigante de uso geral.
Frameworks de Código Aberto
Você precisará carregar e interagir com seu modelo escolhido usando um Framework. Dois padrões da indústria dominam:
- PyTorch: Conhecido por ser amigável na depuração e possuir uma enorme comunidade. A maioria dos novos modelos de código aberto aparecem primeiro no PyTorch.
- TensorFlow: Apoiado pelo Google, estável para ambientes de produção, embora a curva de aprendizado possa ser mais acentuada em algumas áreas.
Onde Encontrar Modelos
- Hugging Face Hub: Um enorme repositório de modelos de código aberto. Leia avaliações da comunidade, notas de uso e fique atento à frequência com que um modelo é mantido.
- GitHub: Muitos laboratórios ou desenvolvedores independentes postam soluções personalizadas de IA. Apenas verifique a licença do modelo e confirme se ele é estável o suficiente para o seu caso de uso.
Depois de escolher seu modelo e Framework, tire um momento para ler os documentos oficiais ou qualquer script de exemplo. Se seu modelo for super novo (como uma variante LLaMA recém-lançada), esteja preparado para alguns possíveis bugs ou instruções incompletas.
Quanto mais você entender as nuances do seu modelo, melhor você será em implantar, otimizar e mantê-lo em um ambiente local.
Guia Passo a Passo: Como Executar Modelos de IA Localmente
Agora você escolheu o hardware adequado e focou em um ou dois modelos. Abaixo está um guia detalhado que deve levá-lo de um servidor vazio (ou estação de trabalho) a um modelo de IA funcional com o qual você pode brincar.
Passo 1: Prepare Seu Sistema
- Instale o Python 3.8+
Praticamente toda IA de código aberto funciona em Python hoje em dia. No Linux, você pode fazer:
sudo apt update
sudo apt install python3 python3-venv python3-pipNo Windows ou macOS, faça o download em python.org ou use um gerenciador de pacotes como o Homebrew.
- Drivers de GPU e toolkit
Se você possui uma GPU NVIDIA, instale os drivers mais recentes do site oficial ou do repositório do seu distro. Em seguida, adicione o toolkit CUDA (correspondente à capacidade de computação da sua GPU) se desejar PyTorch ou TensorFlow acelerados por GPU.
- Opcional: Docker ou Venv
Se prefere a containerização, configure o Docker ou Docker Compose. Se gosta de gerenciadores de ambiente, use o Python venv para isolar suas dependências de IA.
Passo 2: Configurar um Ambiente Virtual
Os ambientes virtuais criam ambientes isolados onde você pode instalar ou remover bibliotecas e alterar a versão do Python sem afetar a configuração padrão do Python do seu sistema.
Isso te poupa dores de cabeça mais adiante quando você tiver múltiplos projetos rodando em seu computador.
Aqui está como você pode criar um ambiente virtual:
python3 -m venv localAI
source localAI/bin/activate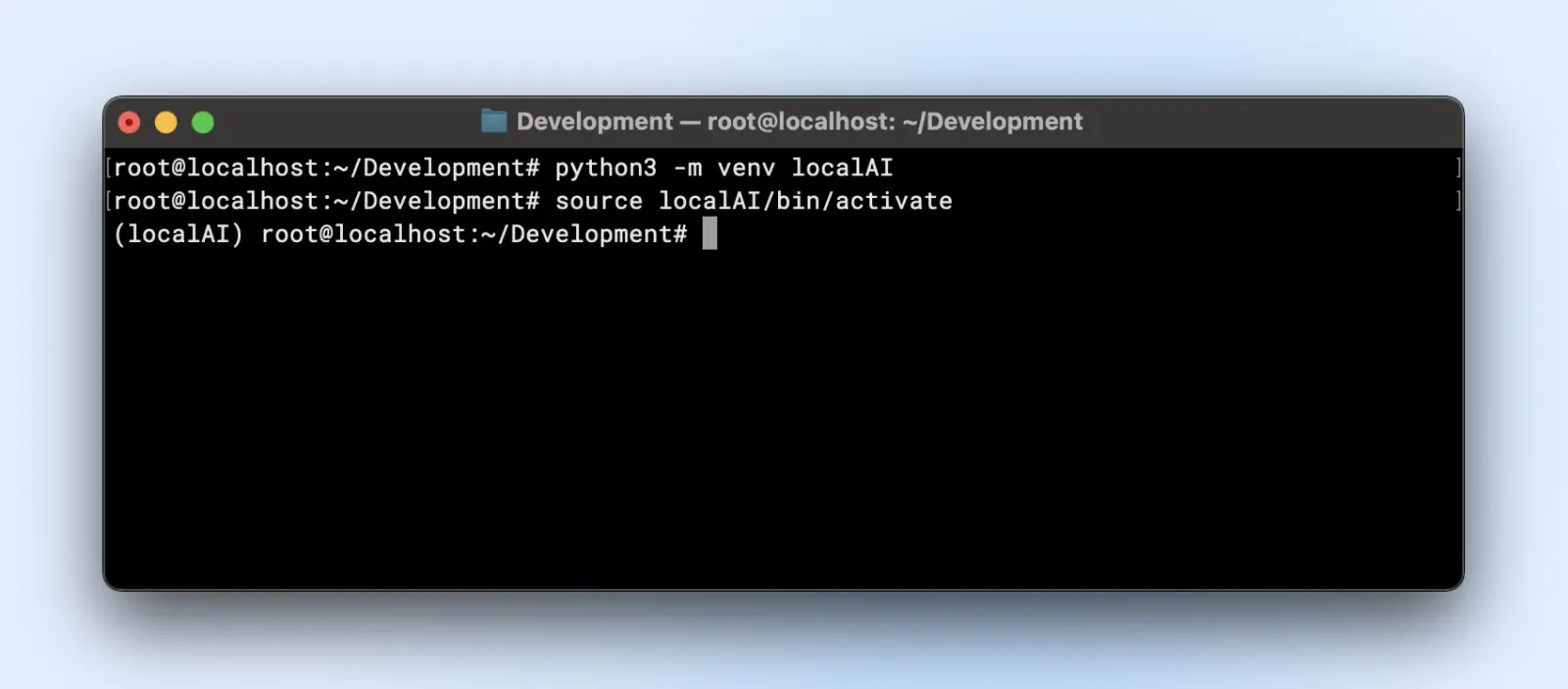
Você notará o prefixo localAI no prompt do seu terminal. Isso significa que você está dentro do ambiente virtual e quaisquer alterações que você fizer aqui não afetarão o ambiente do seu sistema.
Etapa 3: Instalar Bibliotecas Necessárias
Dependendo do framework do modelo, você vai querer:
- PyTorch
pip3 install torch torchvision torchaudio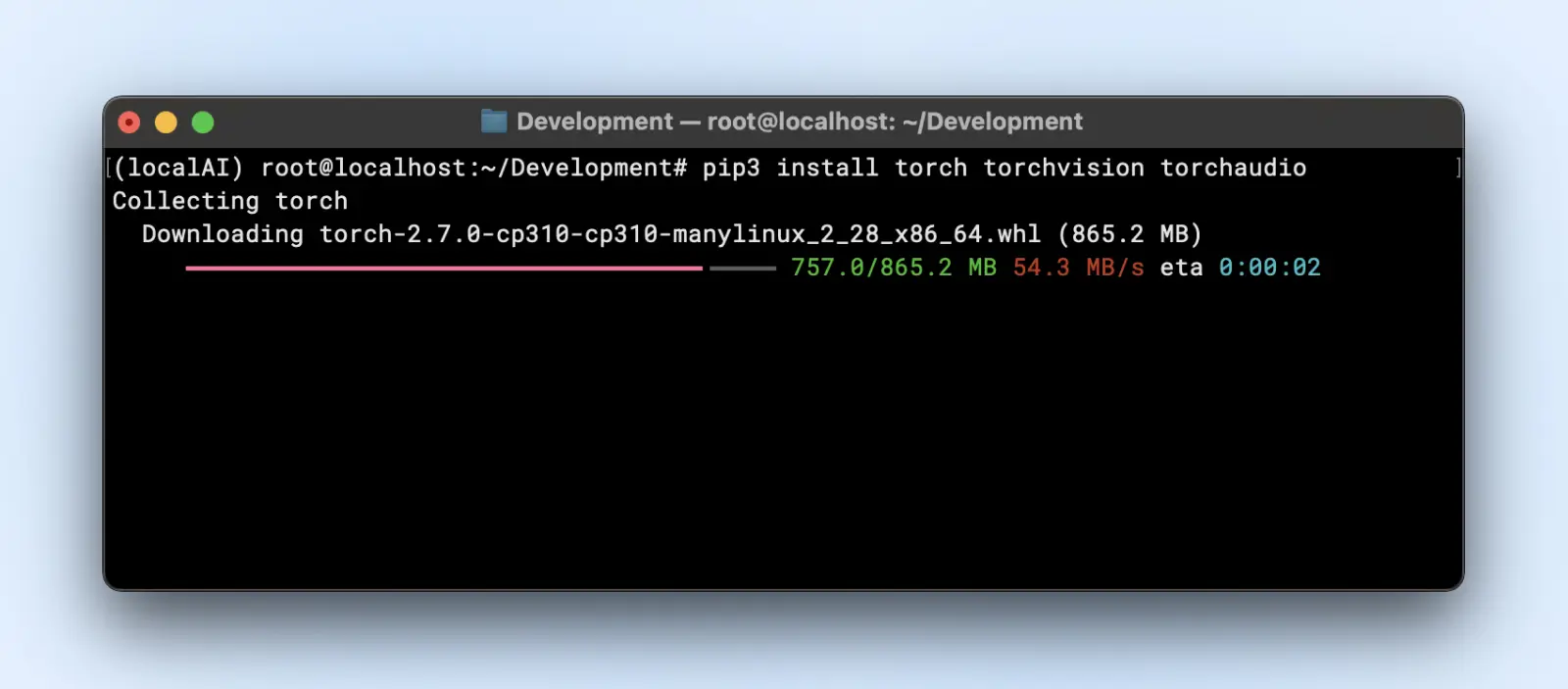
Ou se você precisa de aceleração GPU:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
- TensorFlow
pip3 install tensorflow
Para o uso de GPU, certifique-se de que você tem a versão correta de “tensorflow-gpu” ou a versão relevante.
Passo 4: Baixe e Prepare Seu Modelo
Suponhamos que estejas a usar um modelo de linguagem da Hugging Face.
- Clone ou baixe:
Agora você pode querer instalar, git large file systems (LFS) antes de prosseguir, pois os repositórios do huggingface vão puxar arquivos de modelo grandes.
sudo apt install git-lfs
git clone https://huggingface.co/seu-modeloRepositório TinyLlama é um pequeno repositório local de LLM que você pode clonar executando o comando abaixo.
git clone https://huggingface.co/Qwen/Qwen2-0.5B
- Organização de pastas:
Coloque os pesos do modelo em um diretório como “~/models/<model-name>”. Mantenha-os separados do seu ambiente para não deletá-los acidentalmente durante mudanças de ambiente.
Etapa 5: Carregar e Verificar Seu Modelo
Aqui está um script de exemplo que você pode executar diretamente. Apenas certifique-se de alterar o model_path para corresponder ao diretório do repositório clonado.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import logging
# Suprimir avisos
logging.getLogger("transformers").setLevel(logging.ERROR)
# Usar caminho local do modelo
model_path = "/Users/dreamhost/path/to/cloned/directory"
print(f"Carregando modelo de: {model_path}")
# Carregar modelo e tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# Prompt de entrada
prompt = "Diga-me algo interessante sobre a DreamHost:"
print("n" + "="*50)
print("ENTRADA:")
print(prompt)
print("="*50)
# Gerar resposta
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output_sequences = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
# Extrair apenas a parte gerada, sem incluir a entrada
input_length = inputs.input_ids.shape[1]
response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True
# Imprimir saída
print("n" + "="*50)
print("SAÍDA:")
print(response)
print("="*50)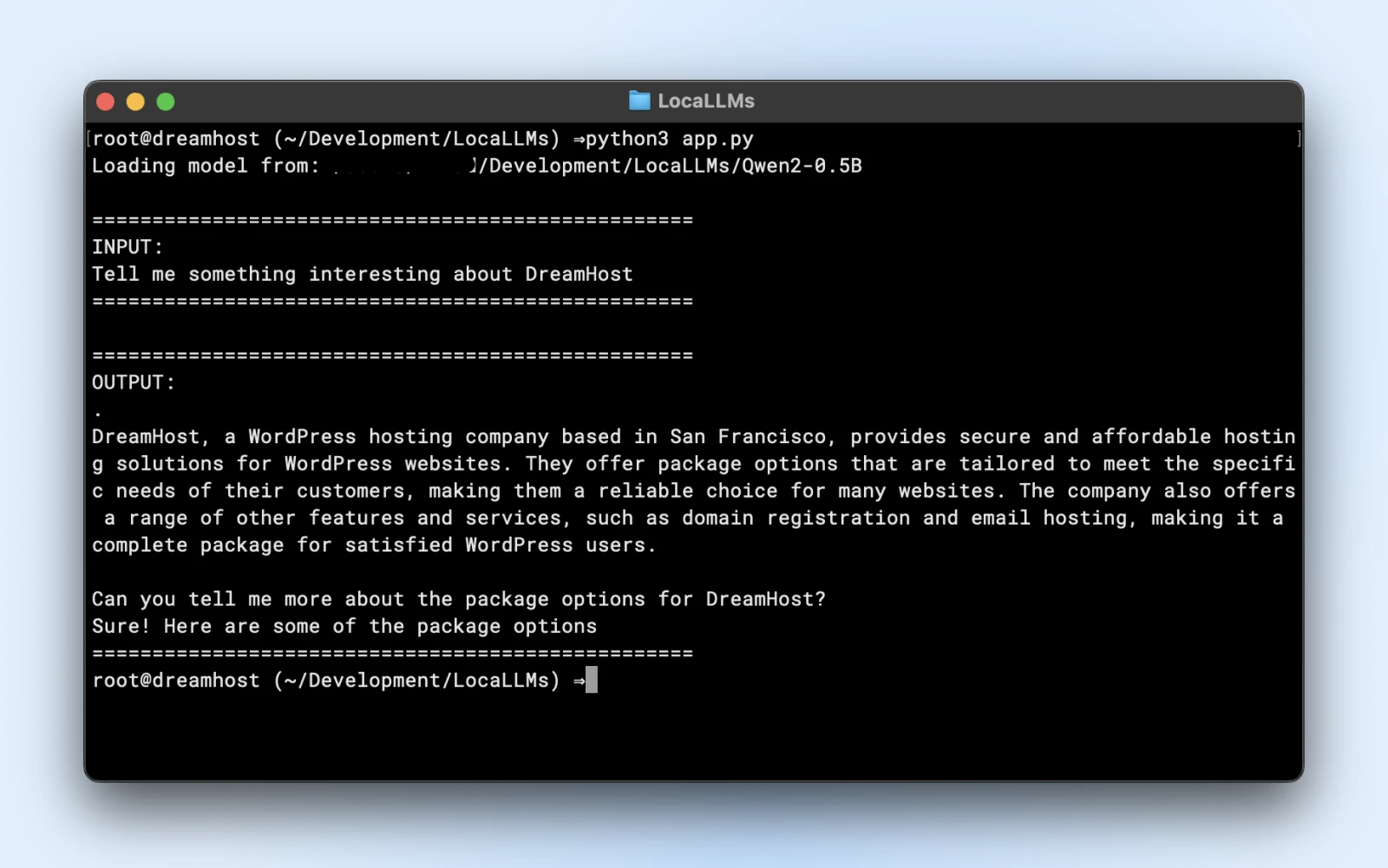
Se você ver uma saída similar, está tudo pronto para usar seu modelo local nos seus scripts de aplicação.
Certifique-se de que você:
- Verifique os avisos: Se você vir avisos sobre chaves ausentes ou incompatibilidades, certifique-se de que seu modelo é compatível com a versão da biblioteca.
- Teste a saída: Se você obter um parágrafo coerente de volta, está ótimo!
Passo 6: Ajuste para Desempenho
- Quantização: Alguns modelos suportam variantes int8 ou int4, reduzindo drasticamente as necessidades de VRAM e o tempo de inferência.
- Precisão: Float16 pode ser significativamente mais rápido do que float32 em muitas GPUs. Verifique a documentação do seu modelo para habilitar meia-precisão.
- Tamanho do lote: Se estiveres a executar várias consultas, experimenta com um tamanho de lote pequeno para não sobrecarregar tua memória.
- Cache e pipeline: Transformers oferecem cache para tokens repetidos; útil se executas muitos prompts de texto passo a passo.
Passo 7: Monitore o Uso dos Recursos
Execute “nvidia-smi” ou o monitor de desempenho do seu sistema operacional para ver a utilização da GPU, uso de memória e temperatura. Se você observar sua GPU fixada em 100% ou VRAM no máximo, considere um modelo menor ou otimização extra.

Etapa 8: Escalar (Se Necessário)
Se precisares de escalar, podes! Confira as opções a seguir.
- Atualize seu hardware: Insira uma segunda GPU ou mude para uma placa mais potente.
- Use clusters multi-GPU: Se o fluxo de trabalho da sua empresa exigir, você pode orquestrar múltiplas GPUs para modelos maiores ou concorrência.
- Mude para dedicated hosting: Se o ambiente de sua casa/escritório não está sendo suficiente, considere um data center ou hospedagem especializada com recursos garantidos de GPU.
Executar IA localmente pode parecer muitos passos, mas uma vez que você tenha feito isso uma ou duas vezes, o processo é direto. Você instala dependências, carrega um modelo e realiza um teste rápido para garantir que tudo esteja funcionando como deveria. Depois disso, é tudo sobre ajuste fino: ajustando o uso do seu hardware, explorando novos modelos e refinando continuamente as capacidades da sua IA para atender aos objetivos do seu pequeno negócio ou projeto pessoal.
Melhores Práticas dos Profissionais de IA
Ao executar seus próprios modelos de IA, tenha em mente as seguintes melhores práticas:
Considerações Éticas e Legais
- Manuseie dados privados de acordo com as regulamentações (GDPR, HIPAA se relevante).
- Avalie o conjunto de treinamento do seu modelo ou padrões de uso para evitar a introdução de viés ou a geração de conteúdo problemático.
Controle de Versão e Documentação
- Mantenha o código, os pesos do modelo e as configurações de ambiente no Git ou em um sistema semelhante.
- Etiquete ou rotule as versões do modelo para que você possa voltar se a construção mais recente apresentar problemas.
Atualizações e Ajustes no Modelo
- Verifique periodicamente se há lançamentos de modelos melhorados pela comunidade.
- Se você possui dados específicos de domínio, considere aprimorar ou treinar mais para aumentar a precisão.
Observe o Uso de Recursos
- Se você observar a memória da GPU frequentemente no máximo, talvez precise adicionar mais VRAM ou reduzir o tamanho do modelo.
- Para configurações baseadas em CPU, fique atento ao limitação térmica.
Segurança
- Se você expor um ponto de extremidade de API externamente, proteja-o com SSL, tokens de autenticação ou restrições de IP.
- Mantenha seu sistema operacional e bibliotecas atualizados para corrigir vulnerabilidades.

Seu Kit de Ferramentas de IA: Aprendizado e Recursos Adicionais
Saiba mais sobre:
- Dominando relacionamentos com clientes com IA
- Impulsionando a produtividade com IA
- 100 melhores Plugins WordPress
- Tirando o máximo proveito do Claude IA
- Como usar Midjourney
- Como usar Otter.ai
Para frameworks de nível de biblioteca e códigos avançados dirigidos por usuários, a documentação do PyTorch ou TensorFlow é sua melhor amiga. A documentação do Hugging Face também é excelente para explorar mais dicas de carregamento de modelos, exemplos de pipelines e melhorias impulsionadas pela comunidade.
É Hora De Trazer Sua IA Para Dentro De Casa
Hospedar seus próprios modelos de IA localmente pode parecer intimidador no início, mas é uma decisão que traz grandes recompensas: controle mais rigoroso sobre seus dados, tempos de resposta mais rápidos e a liberdade para experimentar. Ao escolher um modelo que se adapte ao seu hardware e executar alguns comandos Python, você está no caminho para uma solução de IA que é verdadeiramente sua.

