
Twoja strona internetowa jest jak kawiarnia. Ludzie przychodzą, przeglądają menu. Niektórzy zamawiają latte, siadają, popijają i wychodzą.
A co jeśli połowa twoich „klientów” tylko zajmuje stoliki, marnuje czas twoich baristów i nigdy nie kupuje kawy?
Tymczasem prawdziwi klienci odchodzą z powodu braku stolików i wolnej obsługi?
No cóż, to świat robotów indeksujących i botów.
Te zautomatyzowane programy pochłaniają Twoją przepustowość, spowalniają Twoją stronę i odstraszają rzeczywistych klientów.
Najnowsze badania pokazują, że prawie 51% ruchu internetowego pochodzi od botów. Dokładnie tak — więcej niż połowa twoich cyfrowych gości może tylko marnować zasoby twojego serwera.
Ale nie panikuj!
Ten przewodnik pomoże Ci zlokalizować problemy i kontrolować wydajność Twojej strony, wszystko to bez kodowania czy dzwonienia do swojego technicznego kuzyna.
Krótkie przypomnienie o botach
Boty to zautomatyzowane programy, które wykonują zadania w internecie bez ingerencji człowieka. One:
- Odwiedzaj strony internetowe
- Interakcja z treściami cyfrowymi
- Wykonuj określone funkcje na podstawie ich programowania.
Niektóre boty analizują i indeksują Twoją stronę (potencjalnie poprawiając pozycję w wyszukiwarkach). Inne spędzają czas na scrapowaniu Twoich treści w celu wykorzystania ich w zestawach danych do trenowania SI — lub co gorsza — na publikowaniu spamu, generowaniu fałszywych recenzji lub szukaniu luk i błędów bezpieczeństwa na Twojej stronie internetowej.
Oczywiście nie wszystkie boty są stworzone równo. Niektóre są kluczowe dla zdrowia i widoczności Twojej strony internetowej. Inne można uznać za neutralne, a kilka z nich jest wyraźnie szkodliwych. Znajomość różnicy — oraz decydowanie, które boty zablokować, a które zezwolić — jest kluczowa dla ochrony Twojej strony i jej reputacji.
Dobry Bot, Zły Bot: Co Jest Co?
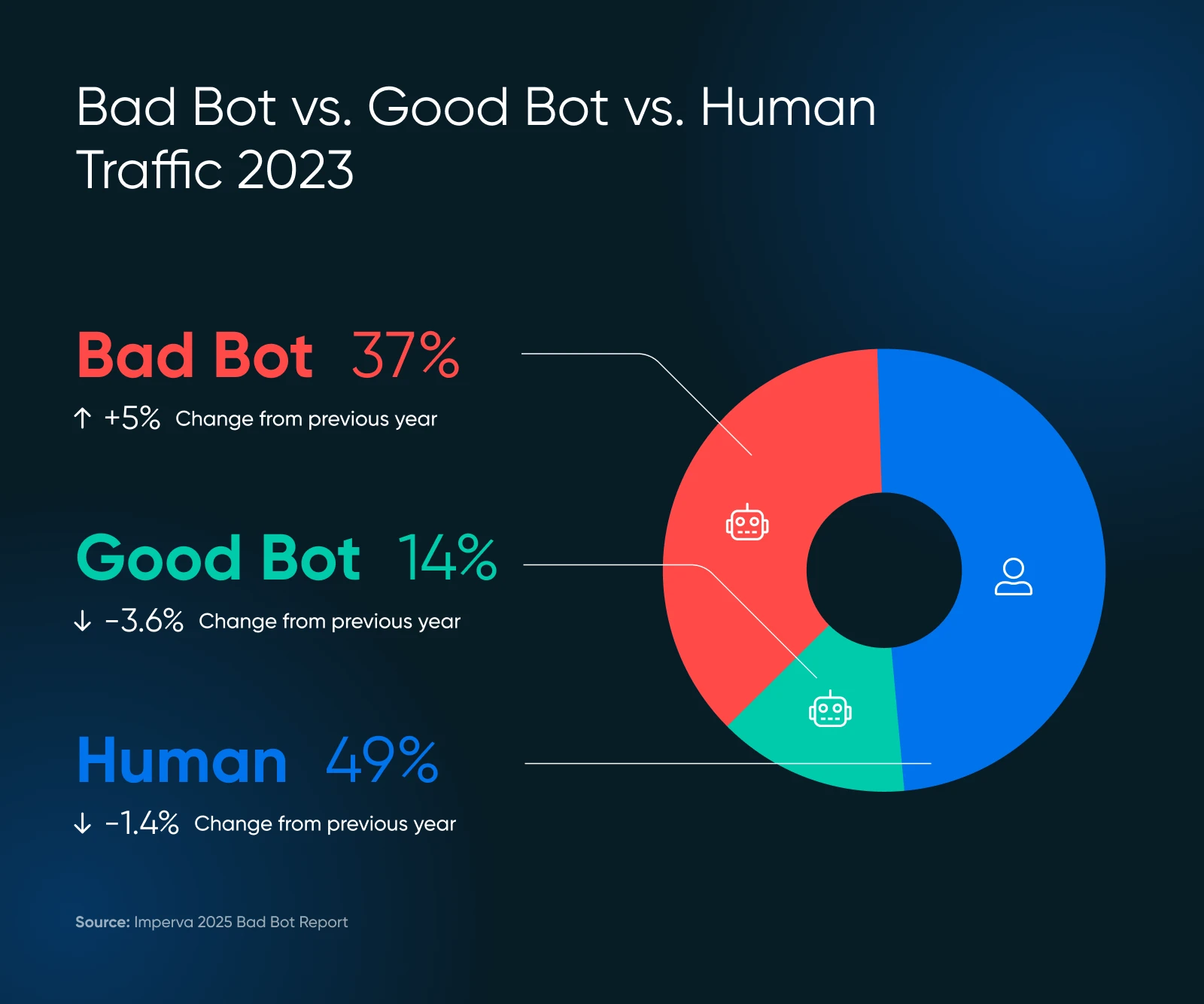
Boty tworzą internet.
Na przykład, bot Google odwiedza każdą stronę w internecie i dodaje ją do swoich baz danych do rankingu. Ten bot pomaga w zapewnieniu cennego ruchu z wyszukiwarek, co jest ważne dla zdrowia twojej strony internetowej.
Ale nie każdy bot przynosi wartość, a niektóre są po prostu złe. Oto, co warto zachować, a co blokować.
VIP Boty (Zachowaj Te)
- Roboty indeksujące, takie jak Googlebot i Bingbot, są przykładami tych robotów. Nie blokuj ich, inaczej staniesz się niewidoczny w internecie.
- Boty analityczne zbierają dane o wydajności twojej strony, takie jak bot Google Pagespeed Insights czy bot GTmetrix.
Osoby Sprawiające Problemy (Wymagają Zarządzania)
- Skopiowane treści, które kradną i wykorzystują gdzie indziej
- Boty spamujące, które zalewają twoje formularze i komentarze śmieciami
- Złe podmioty, które próbują zhakować konta lub wykorzystać luki
Skala złych botów może cię zaskoczyć. W 2024 roku zaawansowane boty stanowiły 55% całego ruchu zaawansowanych złych botów, podczas gdy te dobre odpowiadały za 44%.
Te zaawansowane boty są przebiegłe — potrafią naśladować ludzkie zachowania, w tym ruchy myszy i kliknięcia, co sprawia, że są trudniejsze do wykrycia.
Czy Boty Obciążają Twoją Stronę? Oto Sygnały Ostrzegawcze
Zanim przejdziemy do rozwiązań, upewnijmy się, że roboty są faktycznie twoim problemem. Sprawdź poniższe sygnały.
Czerwone flagi w twojej analityce
- Nieoczekiwane skoki ruchu: Jeśli liczba odwiedzających nagle wzrasta, ale sprzedaż nie, to mogą być roboty.
- Wszystko zwalnia: Strony ładują się dłużej, co frustruje prawdziwych klientów, którzy mogą odejść na dobre. Aberdeen pokazuje, że 40% odwiedzających porzuca strony, które ładują się dłużej niż trzy sekundy, co prowadzi do…
- Wysoki wskaźnik odrzuceń: powyżej 90% często wskazuje na aktywność botów.
- Dziwne wzorce sesji: Ludzie zazwyczaj nie odwiedzają strony tylko przez milisekundy lub nie zostają na jednej stronie przez godziny.
- Zaczynasz otrzymywać dużo nietypowego ruchu: Szczególnie z krajów, w których nie prowadzisz działalności. To podejrzane.
- Wysyłanie formularzy z losowym tekstem: Klasyczne zachowanie botów.
- Twój serwer jest przeciążony: Wyobraź sobie widok 100 klientów naraz, ale 75 z nich tylko ogląda.
Sprawdź Dzienniki Serwera
Dzienniki serwera Twojej strony zawierają zapisy każdego odwiedzającego.
Oto na co warto zwrócić uwagę:
- Zbyt wiele kolejnych żądań z tego samego adresu IP
- Dziwne ciągi identyfikacyjne użytkownika (identyfikacja, którą dostarczają boty)
- Żądania dotyczące nietypowych adresów URL, które nie istnieją na Twojej stronie
Agent Użytkownika
Agent użytkownika to rodzaj oprogramowania, które pobiera i wyświetla treści internetowe, umożliwiając użytkownikom interakcję z nimi. Najczęstszymi przykładami są przeglądarki internetowe oraz czytniki e-mail.
Czytaj WięcejLegalne żądanie Googlebot może wyglądać tak w twoich dziennikach:
66.249.78.17 - - [13/Jul/2015:07:18:58 -0400] "GET /robots.txt HTTP/1.1" 200 0 "-" "Mozilla/5.0 (zgodny; Googlebot/2.1; +http://www.google.com/bot.html)"Jeśli zauważysz wzorce, które nie pasują do normalnego zachowania podczas przeglądania, czas działać.
Problem GPTBot jako Wzrost Robotów AI
Ostatnio wielu właścicieli stron internetowych zgłaszało problemy z robotami AI generującymi nietypowe wzorce ruchu.
Zgodnie z badaniami Imperva, GPTBot firmy OpenAI wykonał 569 milionów żądań w ciągu jednego miesiąca, podczas gdy bot Claude’a wykonał 370 milionów na sieci Vercel.
Szukaj:
- Piki błędów w twoich dziennikach: Jeśli nagle zauważysz setki lub tysiące błędów 404, sprawdź, czy pochodzą one od robotów SI.
- Niezwykle długie, niewiarygodne adresy URL: Boty SI mogą żądać dziwnych adresów URL, takich jak:
/Odonto-lieyectoresli-541.aspx/assets/js/plugins/Docs/Productos/assets/js/Docs/Productos/assets/js/assets/js/assets/js/vendor/images2021/Docs/...- Rekurencyjne parametry: Szukaj nieskończenie powtarzających się parametrów, na przykład:
amp;amp;amp;page=6&page=6- Piki przepustowości: Readthedocs, renomowana firma dokumentacyjna, stwierdziła, że jeden robot indeksujący AI pobrał 73TB plików ZIP, z czego 10TB zostało pobrane w ciągu jednego dnia, co kosztowało ich ponad 5 000 dolarów za przepustowość.
Te wzorce mogą wskazywać na roboty indeksujące SI, które albo działają nieprawidłowo, albo są manipulowane w celu sprawiania problemów.
Kiedy Zwrócić Się Po Pomoc Techniczną
Jeśli zauważysz te oznaki, ale nie wiesz, co robić dalej, czas zaangażować profesjonalną pomoc. Poproś swojego dewelopera, aby sprawdził konkretne agenty użytkownika, takie jak ten:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, jak Gecko; kompatybilny; GPTBot/1.2; +https://openai.com/gptbot)
Istnieje wiele zarejestrowanych ciągów agentów użytkownika dla innych robotów indeksujących SI, które możesz wyszukać w Google, aby je zablokować. Zwróć uwagę, że ciągi się zmieniają, co oznacza, że z czasem możesz zebrać dość dużą listę.
👉 Nie masz dewelopera na szybkim wybieraniu? Zespół DreamCare DreamHost może przeanalizować Twoje dzienniki i wprowadzić środki ochronne. Znają te problemy i wiedzą dokładnie, jak sobie z nimi radzić.
Twój Zestaw Narzędzi Do Walki Z Botami: 5 Prostych Kroków, Aby Odzyskać Kontrolę
A teraz dobre wieści: jak zatrzymać te boty, aby nie spowalniały twojej strony. Zakasaj rękawy i zabierzmy się do pracy.
1. Utwórz Prawidłowy Plik robots.txt
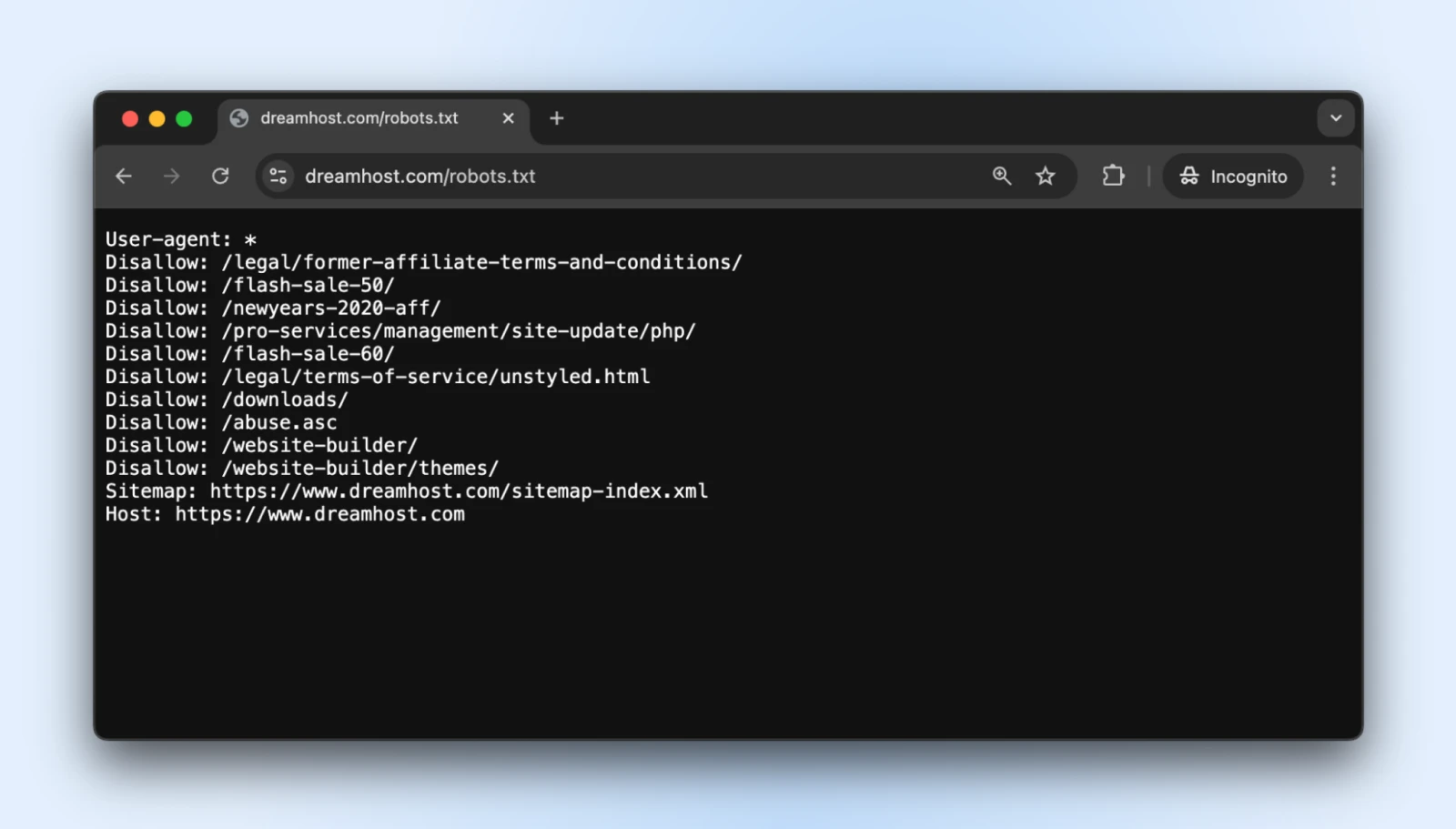
Plik tekstowy robots.txt znajduje się w Twoim katalogu głównym i informuje grzeczne boty, do których części Twojej strony nie powinny mieć dostępu.
Możesz uzyskać dostęp do pliku robots.txt praktycznie dla każdej strony internetowej, dodając /robots.txt do jej domeny. Na przykład, jeśli chcesz zobaczyć plik robots.txt dla DreamHost, dodaj robots.txt na końcu domeny tak jak tutaj: https://dreamhost.com/robots.txt
Nie ma obowiązku, aby którykolwiek z botów akceptował reguły.
Ale grzeczne boty będą go przestrzegać, a psotnicy mogą zdecydować się na ignorowanie reguł. Najlepiej dodać plik robots.txt, aby dobre boty nie zaczęły indeksować strony logowania administratora, stron po zakupie, stron podziękowania itp.
Jak Wdrożyć
1. Stwórz plik tekstowy o nazwie robots.txt
2. Dodaj swoje instrukcje, używając tego formatu:
User-agent: * # Ta linia dotyczy wszystkich robotów
Disallow: /admin/ # Nie indeksuj obszaru administracyjnego
Disallow: /private/ # Nie wchodź do prywatnych folderów
Crawl-delay: 10 # Poczekaj 10 sekund między zapytaniami
User-agent: Googlebot # Specjalne reguły tylko dla Google
Allow: / # Google ma dostęp do wszystkiego3. Prześlij plik do katalogu głównego Twojej strony (aby znajdował się pod adresem twojadomena.com/robots.txt)
Dyrektywa „Crawl-delay” to twoja tajna broń w tym przypadku. Zmusza boty do oczekiwania między żądaniami, zapobiegając przeciążeniu twojego serwera.
Większość głównych robotów indeksujących przestrzega tego, chociaż Googlebot stosuje własny system (którym możesz zarządzać za pomocą Google Search Console).
Wskazówka: Przetestuj swój plik robots.txt za pomocą narzędzia do testowania robots.txt Google, aby upewnić się, że nie zablokowałeś przypadkowo ważnych treści.
2. Skonfiguruj Limitowanie Częstotliwości
Ograniczenie szybkości określa, ile żądań pojedynczy odwiedzający może wykonać w określonym czasie.
Zapobiega to przeciążeniu twojego serwera przez boty, dzięki czemu zwykli ludzie mogą przeglądać twoją stronę bez przeszkód.
Jak zaimplementować
Jeśli używasz Apache (częste w przypadku stron WordPress), dodaj te linie do swojego pliku .htaccess:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{REQUEST_URI} !(.css|.js|.png|.jpg|.gif|robots.txt)$ [NC]
RewriteCond %{HTTP_USER_AGENT} !^Googlebot [NC]
RewriteCond %{HTTP_USER_AGENT} !^Bingbot [NC]
# Zezwalaj na maksymalnie 3 żądania w ciągu 10 sekund na IP
RewriteCond %{REMOTE_ADDR} ^([0-9]+.[0-9]+.[0-9]+.[0-9]+)$
RewriteRule .* - [F,L]
</IfModule>.htaccess
u201c.htaccessu201d to plik konfiguracyjny używany przez oprogramowanie serwera internetowego Apache. Plik .htaccess zawiera dyrektywy (instrukcje), które mówią Apache, jak ma się zachowywać dla konkretnej strony internetowej lub katalogu.
Czytaj więcejJeśli korzystasz z Nginx, dodaj to do konfiguracji serwera:
limit_req_zone $binary_remote_addr zone=one:10m rate=30r/m;
server {
...
location / {
limit_req zone=one burst=5;
...
}
}Wiele paneli sterowania hostingiem, takich jak cPanel czy Plesk, oferuje również narzędzia do ograniczania szybkości w swoich sekcjach zabezpieczeń.
Wskazówka: Zacznij od konserwatywnych limitów (jak 30 zapytań na minutę) i monitoruj swoją stronę. Zawsze możesz zaostrzyć ograniczenia, jeśli ruch botów będzie się kontynuował.
3. Użyj Sieci Dostarczania Treści (CDN)
CDNs robią dla ciebie dwie dobre rzeczy:
- Przekazuj treści za pomocą globalnych sieci serwerów, aby Twoja strona była szybko dostępna na całym świecie
- Filtruj ruch zanim dotrze do strony, aby blokować nieistotne boty i ataki
Część dotycząca „nieistotnych botów” jest dla nas obecnie najważniejsza, ale inne korzyści również są przydatne. Większość CDN zawiera wbudowane zarządzanie botami, które identyfikuje i blokuje podejrzanych odwiedzających automatycznie.
Jak Wdrożyć
- Zapisz się na usługę CDN taką jak DreamHost CDN, Cloudflare, Amazon CloudFront lub Fastly.
- Zastosuj się do instrukcji konfiguracji (może wymagać zmiany serwerów nazw).
- Skonfiguruj ustawienia bezpieczeństwa, aby włączyć ochronę przed botami.
Jeśli twoja usługa hostingowa oferuje domyślnie CDN, eliminujesz wszystkie kroki, ponieważ twoja strona internetowa będzie automatycznie hostowana na CDN.
Gdy już skonfigurujesz, twoja CDN będzie:
- Keszuj statyczne treści, aby zmniejszyć obciążenie serwera.
- Filtruj podejrzany ruch zanim dotrze do twojej strony.
- Zastosuj uczenie maszynowe do rozróżniania między legalnymi a złośliwymi żądaniami.
- Blokuj automatycznie znanych, złośliwych aktorów.
Profesjonalna rada: Darmowy pakiet Cloudflare obejmuje podstawową ochronę przed Botami, która sprawdza się w przypadku większości małych firm. Ich płatne plany oferują bardziej zaawansowane opcje, jeśli ich potrzebujesz.
4. Dodaj CAPTCHA dla Wrażliwych Działań
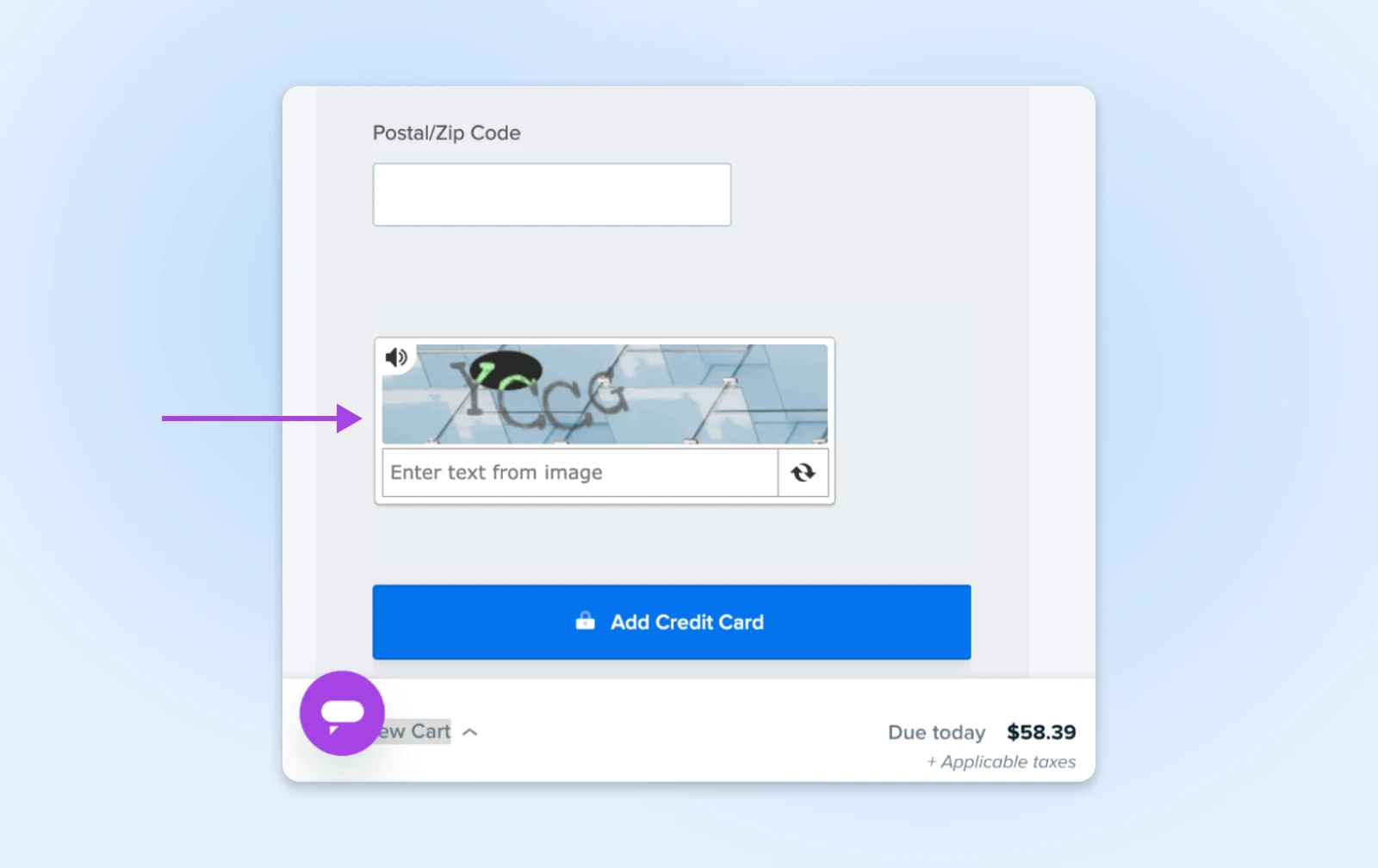
CAPTCHA to te małe zagadki, które proszą cię o zidentyfikowanie świateł ulicznych lub rowerów. Są irytujące dla ludzi, ale prawie niemożliwe do pokonania dla większości botów, co czyni je idealnymi strażnikami ważnych obszarów twojej strony.
Jak Zaimplementować
- Zarejestruj się w Google’s reCAPTCHA (za darmo) lub hCaptcha.
- Dodaj kod CAPTCHA do swoich wrażliwych formularzy:
- Strony logowania
- Formularze kontaktowe
- Procesy zakupu
- Sekcje komentarzy
Dla użytkowników WordPressa, wtyczki takie jak Akismet mogą automatycznie zarządzać tym w przypadku komentarzy i zgłoszeń formularzy.
Wskazówka: Nowoczesne niewidoczne CAPTCHA (jak reCAPTCHA v3) działają w tle dla większości odwiedzających, wyświetlając wyzwania tylko podejrzanym użytkownikom. Użyj tej metody, aby zyskać ochronę, nie irytując przy tym prawdziwych klientów.
5. Rozważ Nowy Standard llms.txt
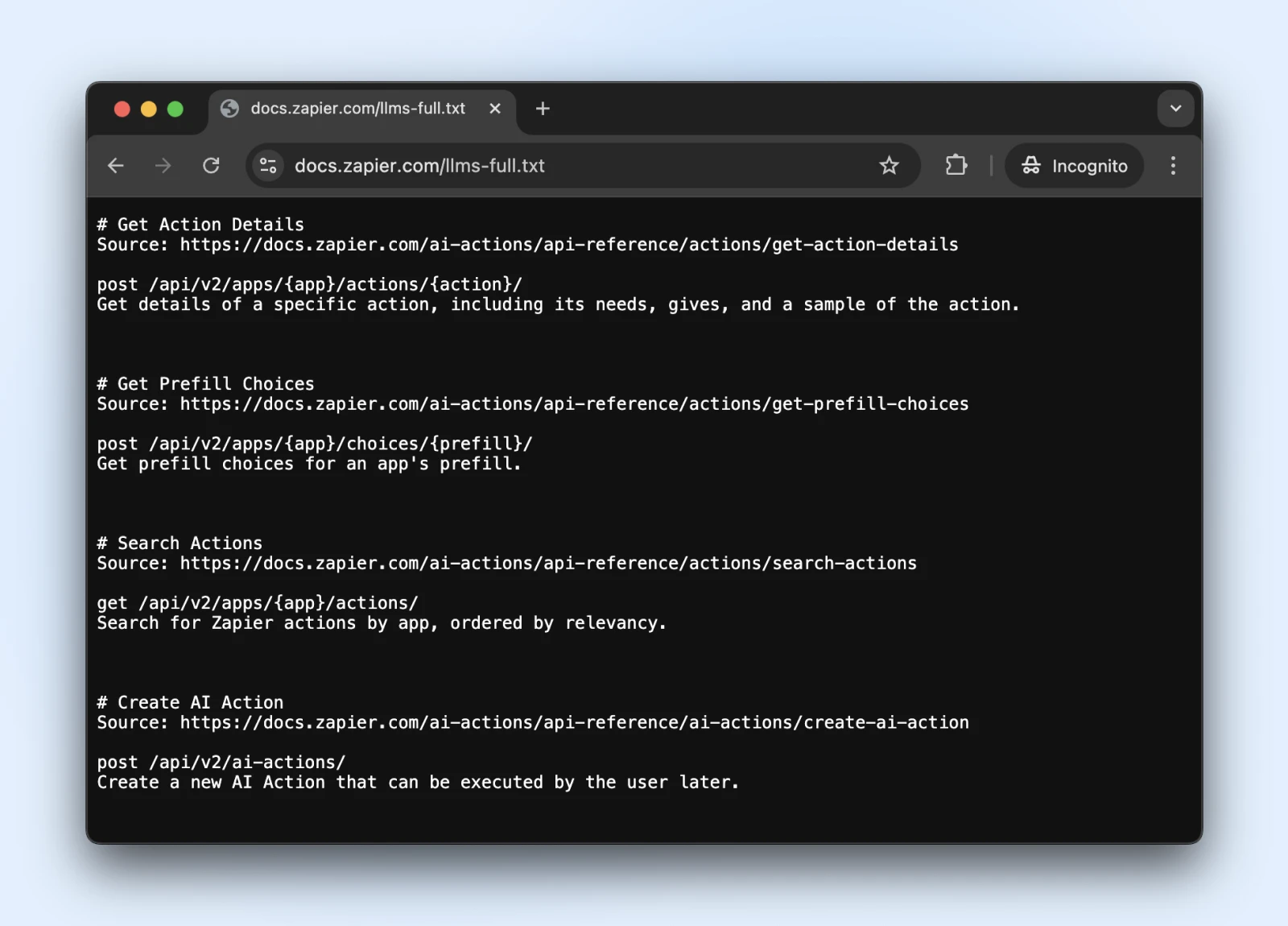
Standard llms.txt to nowy rozwój, który kontroluje, jak roboty indeksujące SI wchodzą w interakcję z twoją treścią.
To jak robots.txt, ale specjalnie do informowania systemów SI, jakie informacje mogą uzyskać dostęp i czego powinny unikać.
Jak zaimplementować
1. Utwórz plik markdown o nazwie llms.txt z tą strukturą zawartości:
# Nazwa Twojej Strony
> Krótki opis Twojej strony
## Główne Obszary Treści
- [Strony Produktów](https://yoursite.com/products): Informacje o produktach
- [Artykuły Blogowe](https://yoursite.com/blog): Edukacyjne treści
## Ograniczenia
- Prosimy nie używać naszych informacji o cenach w szkoleniach2. Wgraj to do swojego katalogu głównego (na twojadomena.com/llms.txt) → Skontaktuj się z programistą, jeśli nie masz bezpośredniego dostępu do serwera.
Czy llms.txt to oficjalny standard? Jeszcze nie.
To standard proponowany pod koniec 2024 roku przez Jeremy’ego Howarda, który został przyjęty przez Zapier, Stripe, Cloudflare i wiele innych dużych firm. Oto rosnąca lista stron przyjmujących llms.txt.
Więc jeśli chcesz dołączyć, mają oficjalną dokumentację na GitHubie z wytycznymi implementacji.
Wskazówka: Po zaimplementowaniu sprawdź, czy ChatGPT (z włączoną wyszukiwarką internetową) może uzyskać dostęp i zrozumieć plik llms.txt.

Sprawdź, czy plik llms.txt jest dostępny dla tych botów, pytając ChatGPT (lub innego LLM) o to, czy „możesz przeczytać tę stronę” lub „co mówi ta strona”.
Nie możemy wiedzieć, czy roboty będą respektować plik llms.txt w najbliższym czasie. Jednakże, jeśli sztuczna inteligencja już teraz potrafi odczytać i zrozumieć plik llms.txt, mogą zacząć go respektować również w przyszłości.
Monitorowanie I Utrzymywanie Ochrony Przed Botami Na Twojej Stronie
Więc ustawiłeś swoje obrony przed botami — świetna robota!
Pamiętaj, że technologia Bot ciągle się rozwija, co oznacza, że boty wracają z nowymi sztuczkami. Upewnijmy się, że Twoja strona pozostanie chroniona na dłuższą metę.
- Regularnie planuj kontrole bezpieczeństwa: Raz w miesiącu sprawdzaj swoje dzienniki serwera pod kątem podejrzanych aktywności i upewnij się, że twoje pliki robots.txt i llms.txt są aktualizowane o nowe linki stron, które chcesz, aby boty miały dostęp/nie miały dostępu.
- Trzymaj swoją listę blokującą boty na bieżąco: Boty ciągle zmieniają swoje przebrania. Śledź blogi o bezpieczeństwie (lub pozwól, żeby zrobił to za ciebie twój dostawca hostingu) i aktualizuj swoje reguły blokowania w regularnych odstępach czasu.
- Obserwuj swoją szybkość: Ochrona przed botami, która spowalnia twoją stronę do nieakceptowalnego poziomu, nie przynosi korzyści. Monitoruj czasy ładowania swoich stron i dostosowuj swoją ochronę, jeśli zaczną występować opóźnienia. Pamiętaj, że prawdziwi ludzie są niecierpliwi!
- Rozważ automatyzację: Jeśli to wszystko wydaje się zbyt dużą pracą (rozumiemy, masz biznes do prowadzenia!), zainteresuj się automatycznymi rozwiązaniami lub zarządzanym hostingiem, który zajmie się bezpieczeństwem za ciebie. Czasami najlepsze DIY to DIFM — Zrób to za mnie!
Strona Wolna Od Botów Podczas Snu? Tak, Proszę!
Poklep się po plecach. Przebyłeś tutaj długą drogę!
Jednakże, nawet z naszym szczegółowym przewodnikiem, te sprawy mogą być dość techniczne. (Co dokładnie jest plikiem .htaccess?)
A choć samodzielne zarządzanie botami jest zdecydowanie możliwe, możesz stwierdzić, że twój czas lepiej jest wykorzystać na prowadzenie firmy.
DreamCare to przycisk „zajmiemy się tym za ciebie”, którego szukasz.
Nasz zespół chroni Twoją stronę za pomocą:
- Monitorowanie 24/7, które wykrywa podejrzane działania, podczas gdy ty śpisz
- Regularne przeglądy bezpieczeństwa, aby wyprzedzać pojawiające się zagrożenia
- Automatyczne aktualizacje oprogramowania, które łatają luki zanim boty zdążą je wykorzystać
- Wszechstronne skanowanie w poszukiwaniu złośliwego oprogramowania i jego usuwanie, jeśli coś prześlizgnie się przez zabezpieczenia
Zobacz, boty pozostaną z nami na stałe. Biorąc pod uwagę ich wzrost w ostatnich latach, w niedalekiej przyszłości może być więcej botów niż ludzi. Nikt nie wie.
Ale po co tracić przez to sen?
Zajmiemy się Kwestami Technicznymi
Zapewnij wydajność i niezawodność na poziomie przedsiębiorstwa dla swojej strony. Zostaw backend ekspertom – Ty skup się na swoim biznesie.
Zobacz więcejTa strona zawiera linki afiliacyjne. Oznacza to, że możemy otrzymać prowizję, jeśli zakupisz usługi przez nasz link, bez dodatkowych kosztów dla ciebie.

