
Als Claude Sonnet 4.5 im September 2025 startete, wurden viele der bestehenden Prompts beschädigt. Nicht weil die Veröffentlichung fehlerhaft war, sondern weil Anthropic neu gestaltet hat, wie Claude Anweisungen folgt.
Frühere Versionen würden deine Absicht erkennen und vage Anfragen erweitern. Claude 4.x nimmt dich wörtlich und macht genau das, was du verlangst, nicht mehr.

Um die neuen Methoden zu verstehen, haben wir 25 beliebte Prompt-Engineering-Techniken anhand von Anthropic-Dokumenten, Community-Experimenten und realen Einsätzen bewertet, um herauszufinden, welche Prompts tatsächlich besser mit Claude 4.x funktionieren. Diese fünf Techniken
Was Hat Sich In Claude 4.5 Verändert, Das Bestehende Prompts Beschädigt Hat?
Claude 4.5 Modelle bevorzugen präzise Anweisungen gegenüber „hilfreichem“ Raten.
Die vorherigen Versionen haben die Lücken für dich ausgefüllt. Wenn du nach einem „Dashboard“ gefragt hast, gingen sie davon aus, dass du Diagramme, Filter und Datentabellen wolltest.
Claude 4.5 nimmt dich wörtlich. Wenn du nach einem Dashboard fragst, könnte es dir einen leeren Rahmen mit einem Titel geben, weil du nicht nach dem Rest gefragt hast.
Anthropic erklärt deutlich: „Kunden, die das ‚über das Übliche hinausgehende‘ Verhalten wünschen, müssen diese Verhaltensweisen möglicherweise ausdrücklicher anfordern.“
Also, wir müssen aufhören, das Modell wie einen Zauberstab zu behandeln und beginnen, es wie einen wörtlich nehmenden Mitarbeiter zu behandeln.
Keine Designkenntnisse. Keine Baukästen. Kein Aufwand. Nur Ergebnisse.
Jetzt Starten
Die 5 Bewährten Techniken, Die Claudes Leistung Messbar Verbessern
Basierend auf unserer Forschung haben diese fünf Techniken konsistent spürbare Verbesserungen in Claudes Leistung für die Aufgaben gebracht, die wir ihm gestellt haben.
1. Strukturierte Und Beschriftete Aufforderungen
Claude Sonnet 4.5s Systemaufforderung verwendet überall strukturierte Aufforderungen. Simon Willison hat die Systemaufforderungen untersucht und Abschnitte gefunden, die in Tags wie <behavior_instructions>, <artifacts_info> und <knowledge_cutoff> eingewickelt sind.
Tatsächlich könntest Du „Styles“ bearbeiten, um Anthropics strukturiertes Auffordern in Aktion zu sehen.
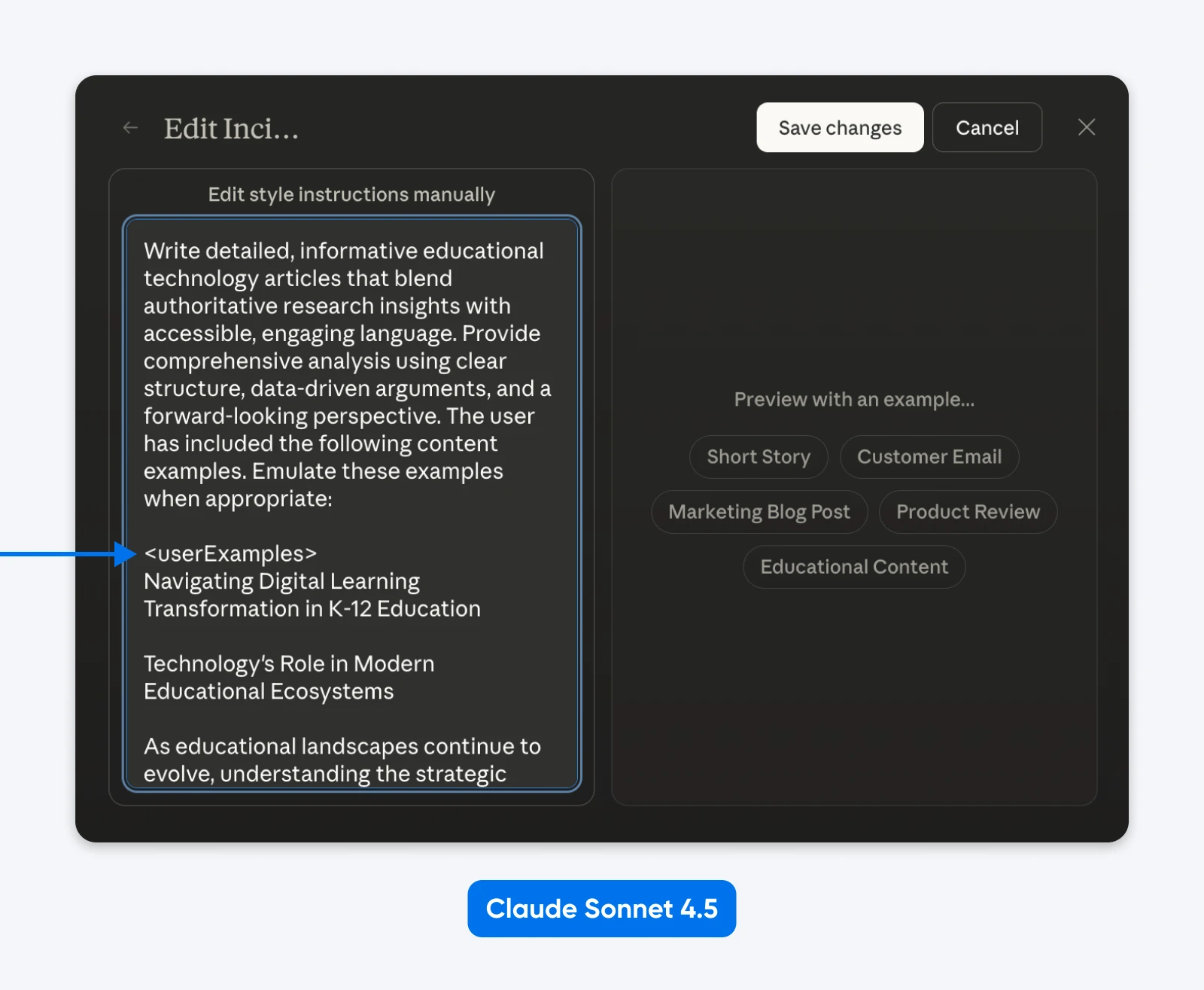
Was wir daraus schließen können ist, dass Claude anhand strukturierter Aufforderungen trainiert wurde und weiß, wie man sie analysiert. XML funktioniert großartig, ebenso wie JSON oder andere beschriftete Aufforderungen.
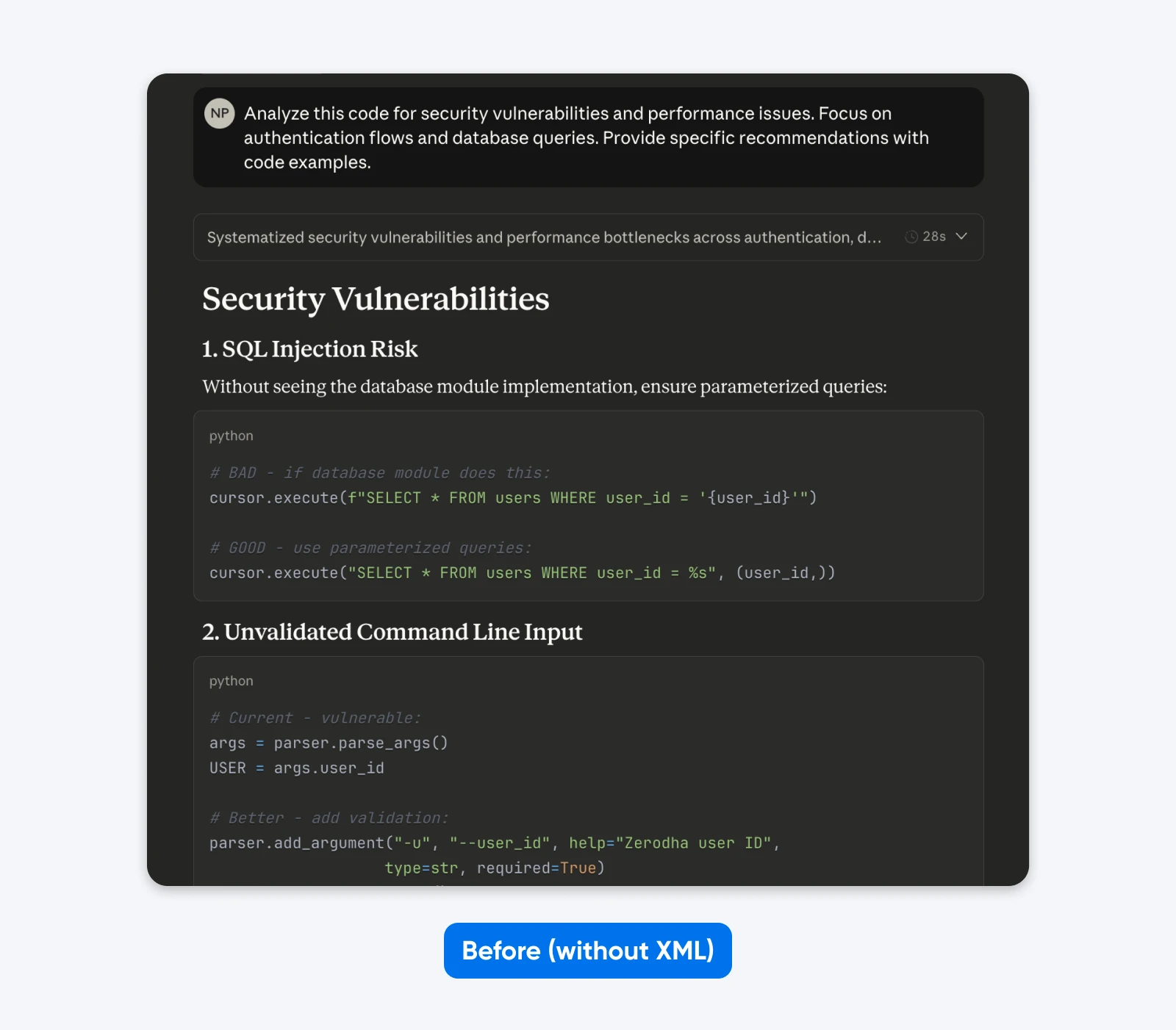
Vorher:
Analyisiere diesen Code auf Sicherheitslücken und Leistungsprobleme. Konzentriere dich auf Authentifizierungsabläufe und Datenbankabfragen. Gib spezifische Empfehlungen mit Codebeispielen.
Nach (Strukturierter Aufforderung):
<task>Analysiere den bereitgestellten Code auf Sicherheits- und Leistungsprobleme</task>
<focus_areas>
– Authentifizierungsflüsse
– Optimierung von Datenbankabfragen</focus_areas>
<code>
[dein Code hier]
</code>
<output_requirements>
– Bestimmte Schwachstellen mit Schweregradbewertungen identifizieren
– Korrigierte Codebeispiele bereitstellen
– Empfehlungen nach Geschäftsauswirkung priorisieren
</output_requirements>
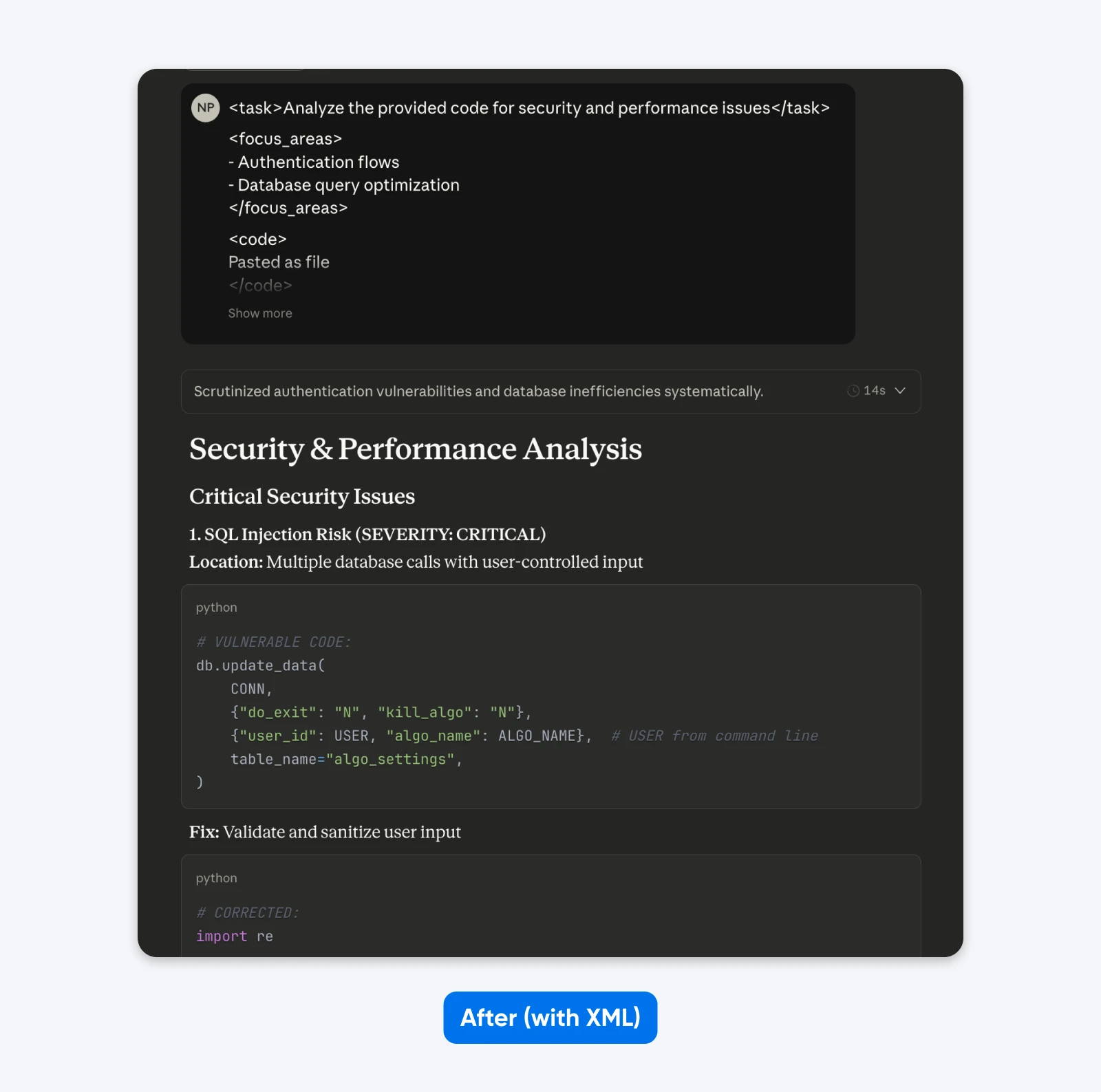
Wenn Du diese Ausgaben vergleichst, wirst Du feststellen, dass die strukturierte Aufforderung eine Ausgabe mit mehr Kontext liefert, um Dir zu helfen, die Sicherheitsprobleme im Code zu verstehen und zu beheben. Sie erklärt das Problem, sagt, was die Korrektur bewirkt, und liefert dann den Code zur Behebung.
Alternative Formate, Die Funktionieren:
JSON:
{
"task": "Authentifizierungscode überprüfen",
"focus_areas": ["Passwort-Hashing", "Sitzungssicherheit", "SQL-Injektion"],
"context": "Healthcare-App, HIPAA erforderlich",
"output_format": "Risiko, Auswirkung, Lösung, Schweregrad pro Schwachstelle"
}
Klare Überschriften:
AUFGABE: Überprüfe den Authentifizierungscode auf Schwachstellen
SCHWERPUNKT: Passwort-Hashing, Sitzungen, SQL-Injection
KONTEXT: Gesundheits-App, die HIPAA-Konformität erfordert
AUSGABEFORMAT: Risiko → HIPAA-Auswirkung → Lösung → Schweregrad
Alle drei funktionieren gleich gut.
Wann strukturierte Aufforderungen am besten funktionieren:
- Mehrere Eingabeelemente (Aufgabe, Kontext, Beispiele, Anforderungen)
- Lange Eingaben (10.000+ Zeichen Code oder Dokumente)
- Sequentielle Abläufe mit deutlichen Schritten
- Aufgaben, die wiederholtes Beziehen auf bestimmte Abschnitte erfordern
Wann strukturierte Aufforderungen übersprungen werden sollten: Einfache Fragen, bei denen einfacher Text ausreicht.
Effektivitätsbewertung: 9/10 für komplexe Aufgaben, 5/10 für einfache Anfragen.
2. Erweitertes Denken Für Komplexe Probleme
Erweitertes Denken bringt enorme Verbesserungen bei komplexen Denkaufgaben mit einem großen Nachteil: Geschwindigkeit.
Anthropics Ankündigung zu Claude 4 zeigte erhebliche Leistungssteigerungen mit aktiviertem erweitertem Denken. Beim Mathematikwettbewerb AIME 2025 verbesserten sich die Ergebnisse deutlich.
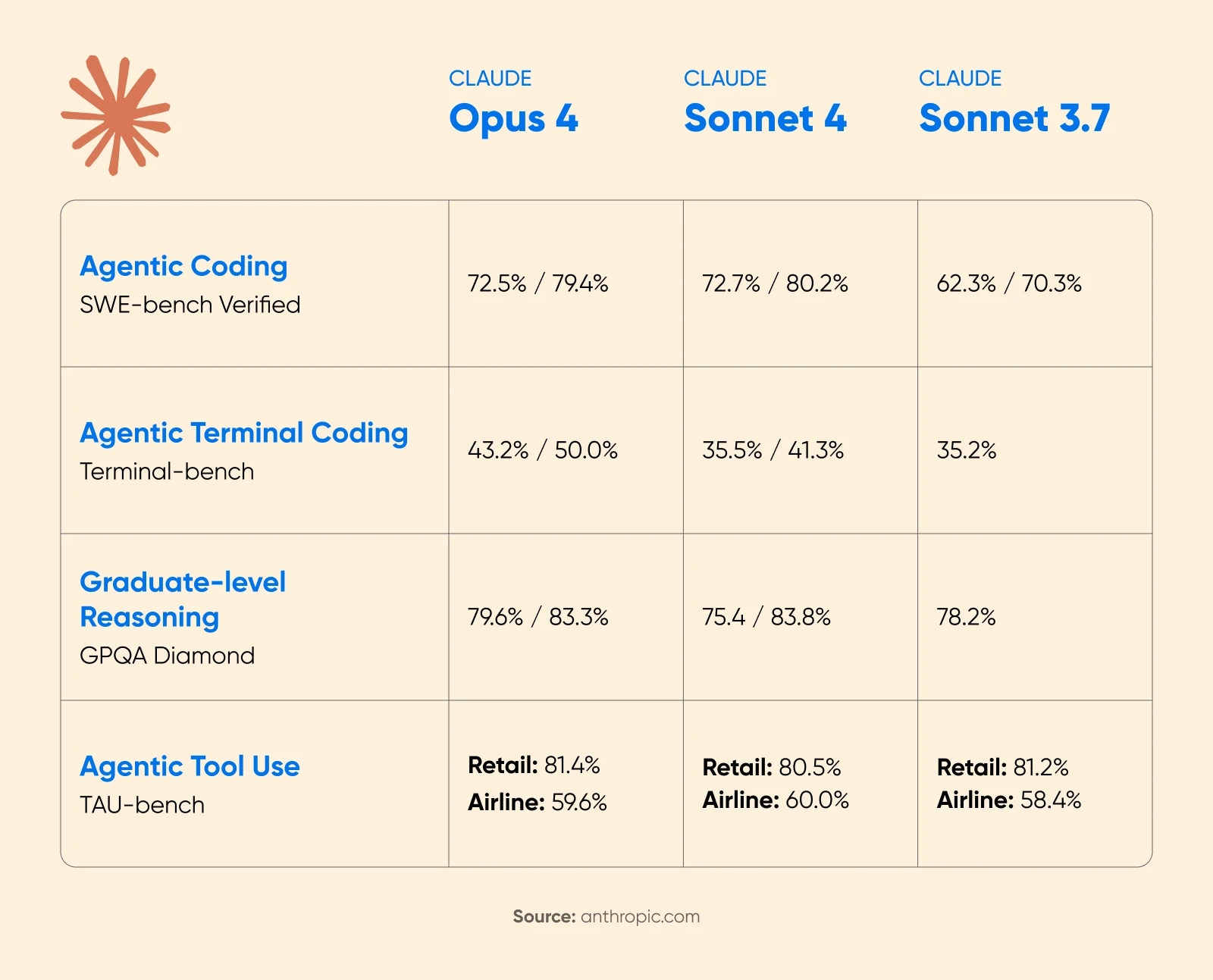
Cognition AI berichtete von einem Anstieg von 18% in der Planungsleistung mit Sonnet 4.5 und bezeichnete es als „den größten Sprung, den wir seit Claude Sonnet 3.6 gesehen haben.“
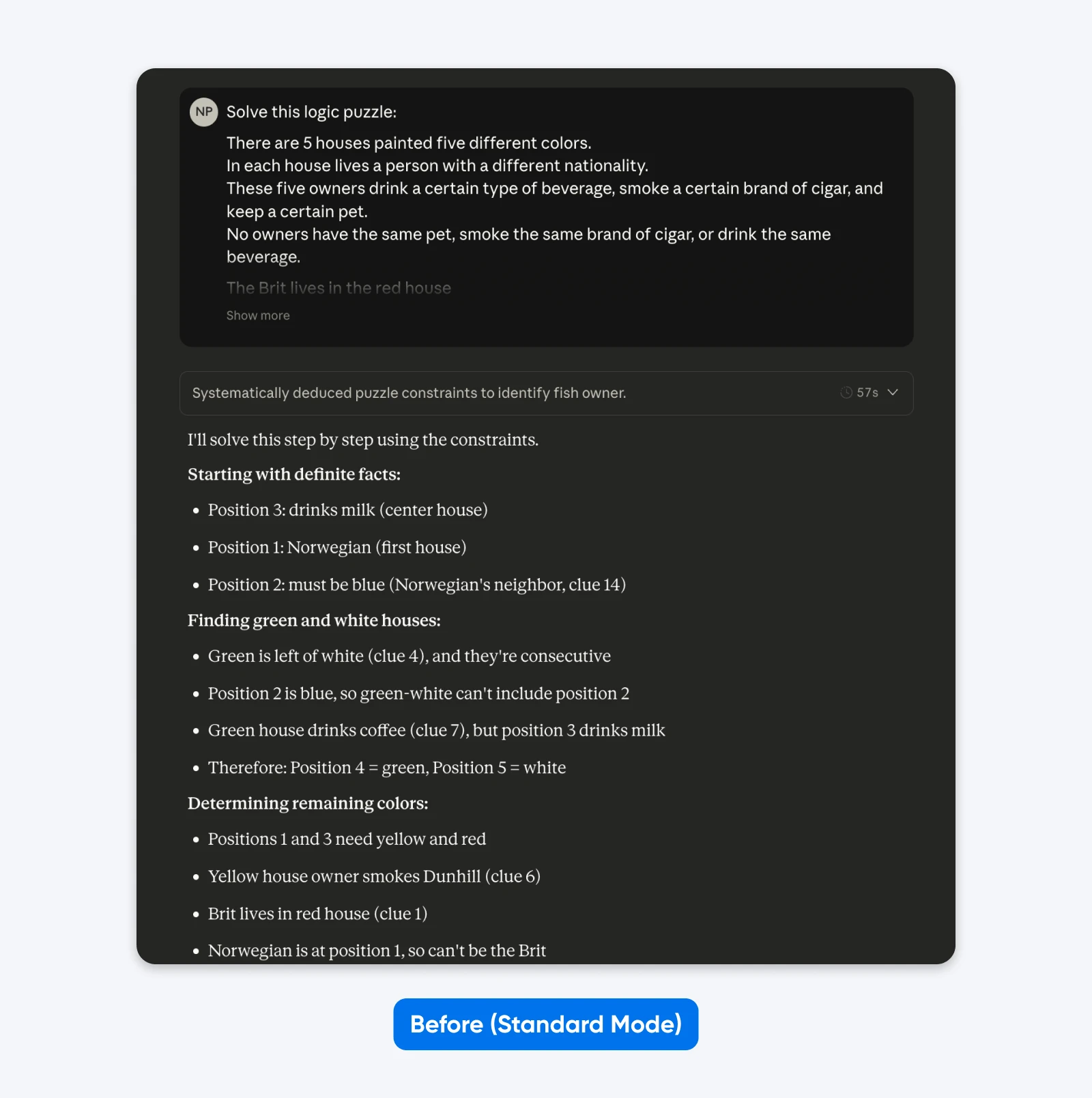
Vorher (Standardmodus):
Löse dieses Logikrätsel: Fünf Häuser in einer Reihe, jedes in einer anderen Farbe…
Nach (mit Erweitertem Denken):
Verstehe die Logik dieses Rätsels systematisch. Gehe schrittweise durch die Einschränkungen und prüfe jede Möglichkeit, bevor Du Schlussfolgerungen ziehst.
Fünf Häuser in einer Reihe, jedes in einer anderen Farbe…
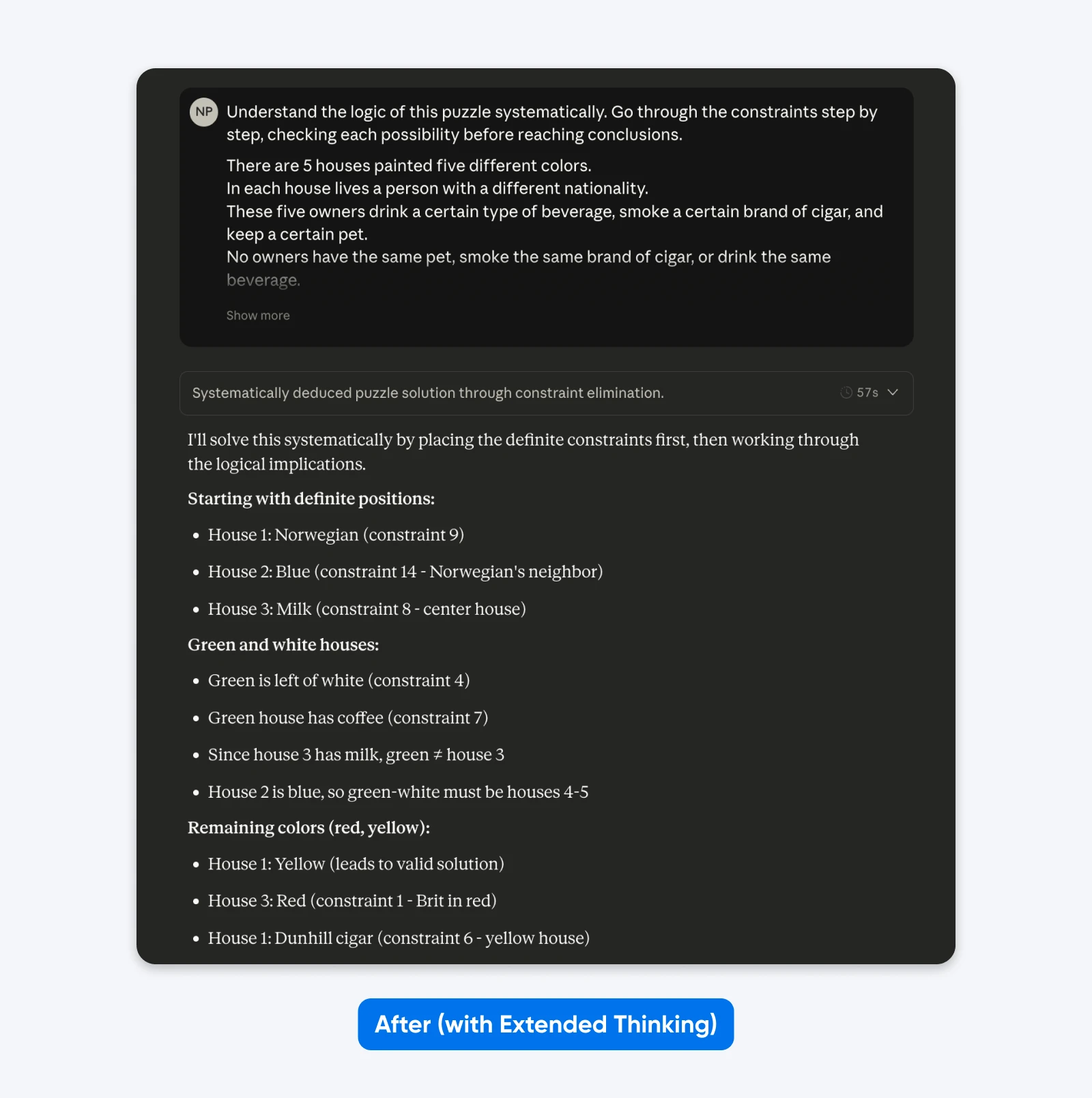
Du wirst bei einfachen Aufforderungen wie der oben genannten nicht viel Unterschied sehen. Aber bei komplexen, speziellen Problemen (benutzerdefinierte Codebasen, mehrstufige logische Planung) wird der Unterschied deutlich.
Wenn erweiterte Dinge funktionieren:
- Mehrstufige logische Planung, die eine Überprüfung erfordert
- Mathematisches Denken mit mehreren Lösungswegen
- Komplexe Codierungsaufgaben, die sich über mehrere Dateien erstrecken
- Situationen, in denen Korrektheit wichtiger ist als Geschwindigkeit
Wann Zu Überspringen: Schnelle Iterationen, einfache Abfragen, kreatives Schreiben, zeitkritische Aufgaben
Effektivitätsbewertung: 10/10 für komplexe Überlegungen, 3/10 für einfache Anfragen.
3. Sei Brutal Spezifisch Bei Den Anforderungen
Die Claude 4 Modelle wurden für eine präzisere Befolgung von Anweisungen als frühere Generationen trainiert.
Die Dokumentation von Anthropic besagt:
„Claude 4.x Modelle reagieren gut auf klare, explizite Anweisungen. Je spezifischer Du Dein gewünschtes Ergebnis formulierst, desto besser können die Ergebnisse sein. Kunden, die das ‚über das Gewöhnliche hinausgehende‘ Verhalten früherer Claude-Modelle wünschen, müssen diese Verhaltensweisen bei neueren Modellen möglicherweise expliziter anfordern.“
Die Dokumentation weist auch darauf hin, dass Claude klug genug ist, von der Erklärung zu verallgemeinern, wenn Du den Kontext dafür gibst, warum Regeln existieren, anstatt nur Befehle zu nennen. Das bedeutet, dass das Bereitstellen einer Begründung dem Modell hilft, Prinzipien korrekt in Randfällen anzuwenden, die nicht explizit abgedeckt sind.
Tests von 16x Eval zeigten, dass sowohl Opus 4 als auch Sonnet 4 9,5/10 bei TODO-Aufgaben erreichten, wenn die Anweisungen Anforderungen, Format und Erfolgskriterien klar spezifizierten. Die Modelle zeigten beeindruckende Prägnanz und Fähigkeiten zur Befolgung von Anweisungen.
Vorher (Implizite Erwartungen):
Erstelle ein Analyse-Dashboard.
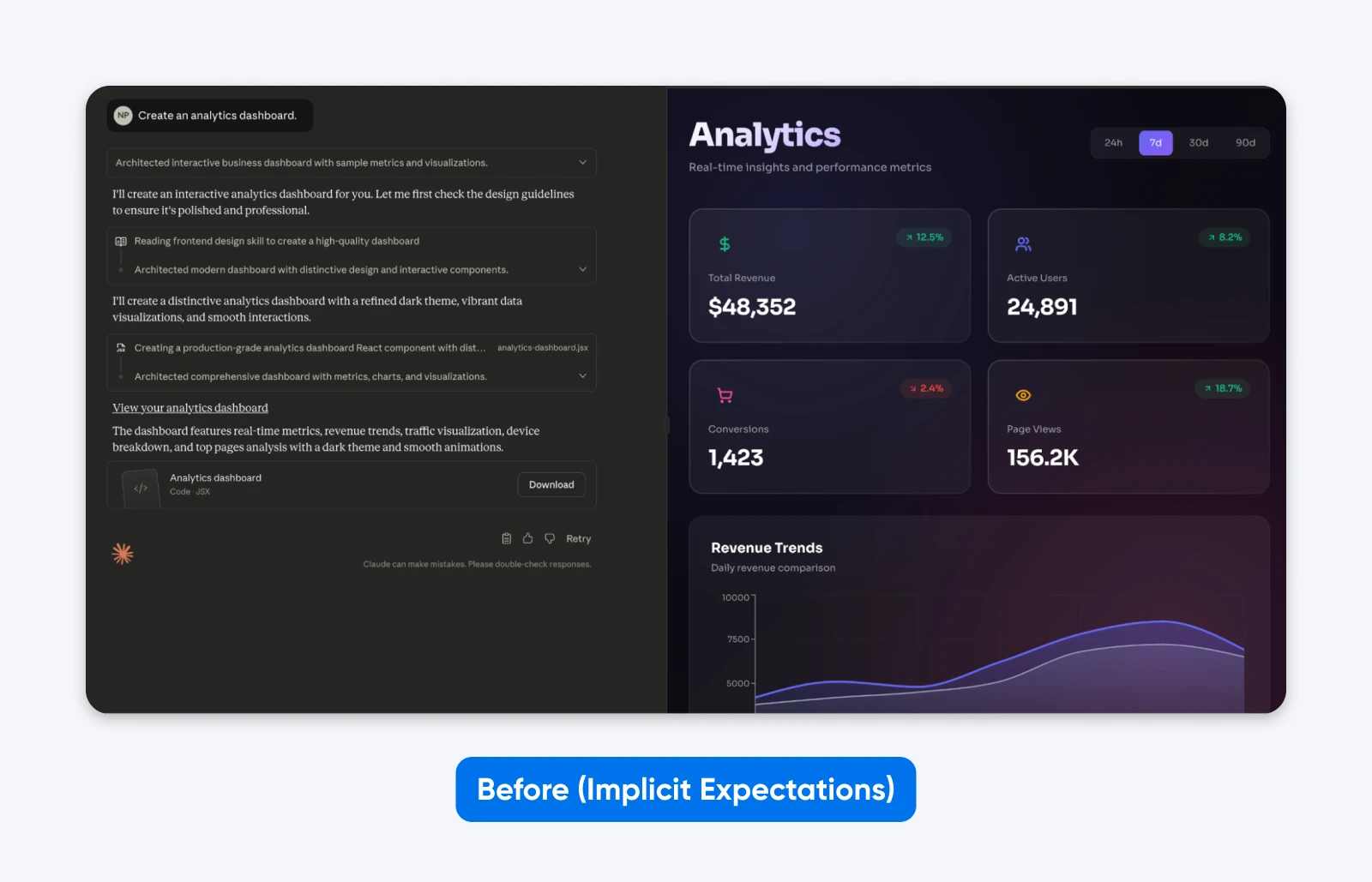
Du wirst feststellen, dass dieses Ergebnis genau das ist, was wir gefragt haben. Obwohl Claude sich ein wenig kreative Freiheit bei der Ästhetik genommen hat, hat es keine Funktionalität.
Nach (expliziten Anforderungen):
Erstelle ein Analyse-Dashboard. Integriere so viele relevante Funktionen und Interaktionen wie möglich. Gehe über die Grundlagen hinaus, um eine vollständig ausgestattete Implementierung mit Datenvisualisierung, Filtermöglichkeiten und Exportfunktionen zu erstellen.
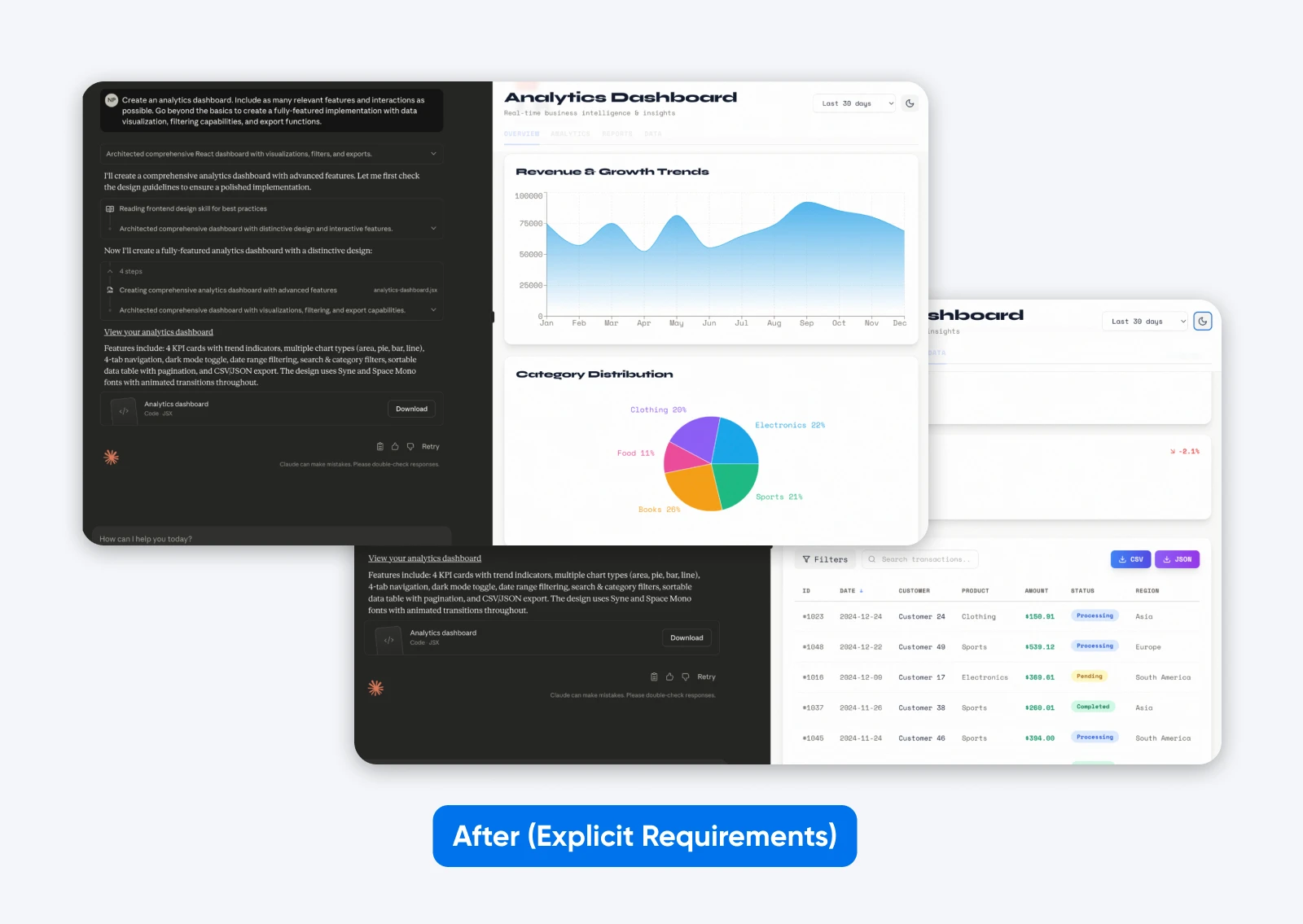
Dieser zweite Ausgang mit einer beschreibenderen Aufforderung bietet mehr Funktionen, ein Dashboard basierend auf einigen Dummy-Daten, die sowohl grafisch als auch in Tabellenform dargestellt werden, und es hat Registerkarten, um alle Daten zu trennen.
Das bewirkt Spezifität mit dem neuesten Claude.
Um diesen Punkt noch weiter zu klären, hier ein weiteres Beispiel, das zeigt, wie Kontext das Befolgen von Anweisungen verbessert:
Vorher (Befehl ohne Kontext):
NIE Punkte in deiner Antwort verwenden.
Nach (kontextbedingte Anleitung):
Deine Antwort wird von einer Text-zu-Sprache-Engine vorgelesen, daher vermeide Ellipsen, da die Engine nicht weiß, wie sie diese aussprechen soll.
Grundprinzipien Für Ausdrückliche Anweisungen:
- Definiere, Was „Umfassend“ Für Deine Spezifische Aufgabe Bedeutet: Gehe nicht davon aus, dass Claude Qualitätsstandards ableiten wird.
- Erläutere, Warum Regeln Existieren, Anstatt Sie Nur Zu Nennen: Claude generalisiert besser aus motivierten Anweisungen.
- Gib Das Ausgabeformat Explizit An: Fordere „Prosaabsätze“ anstatt zu hoffen, dass Claude nicht standardmäßig Aufzählungszeichen verwendet.
- Biete Konkrete Erfolgskriterien: Wie sieht die Aufgabenerfüllung aus?
Effektivitätsbewertung: 9/10 über alle Aufgabentypen hinweg.
4. Zeige Beispiele Dessen, Was Du Möchtest
Das Few-Shot-Prompting versorgt Claude mit Beispiel-Eingaben und -Ausgaben, die das gewünschte Verhalten demonstrieren. Dies funktioniert, aber nur, wenn die Beispiele hochwertig und aufgabenangemessen sind, und der Einfluss variiert stark je nach Anwendungsfall.
Die offizielle Anleitung von Anthropic betont:
„Claude 4.x-Modelle achten genau auf Details und Beispiele als Teil ihrer präzisen Anweisungsbefolgung. Stelle sicher, dass deine Beispiele mit den Verhaltensweisen übereinstimmen, die du fördern möchtest, und minimiere Verhaltensweisen, die du vermeiden möchtest.“
Anthropic empfiehlt 3-5 vielfältige, relevante Beispiele für komplexe Aufgaben. Mehr Beispiele bedeuten bessere Leistung.
Hier ist ein Beispiel dafür, wie das in der Praxis aussieht:
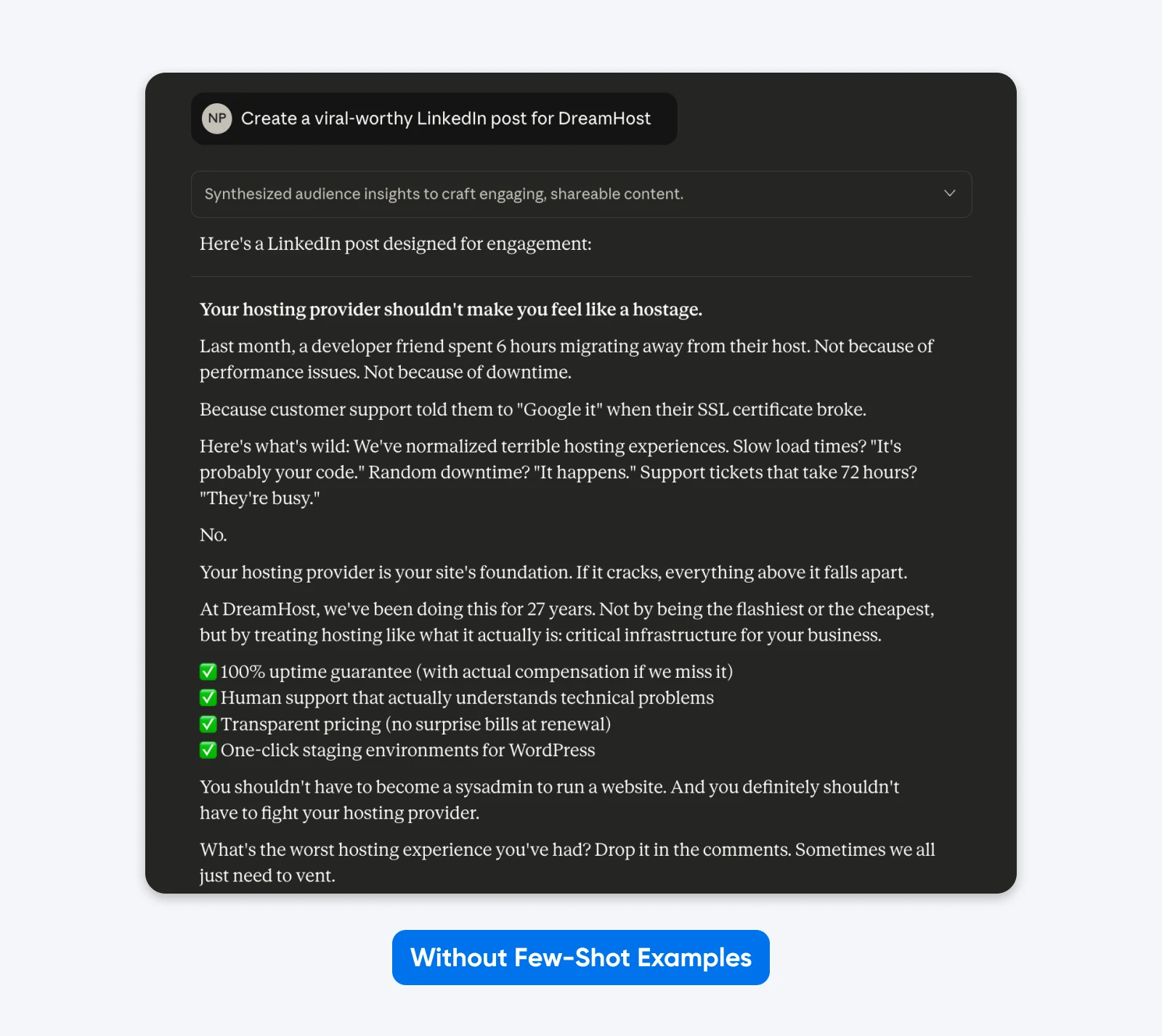
Hier hat Claude sich kreative Freiheit in Bezug auf Format, Emoji-Nutzung, Nachrichteninhalt und Ton erlaubt. Generische Unternehmenssprache
Beispiele hinzuzufügen funktioniert, weil sie eher zeigen als erzählen, während sie die subtilen Anforderungen klären, die allein durch Beschreibung schwer zu vermitteln sind.
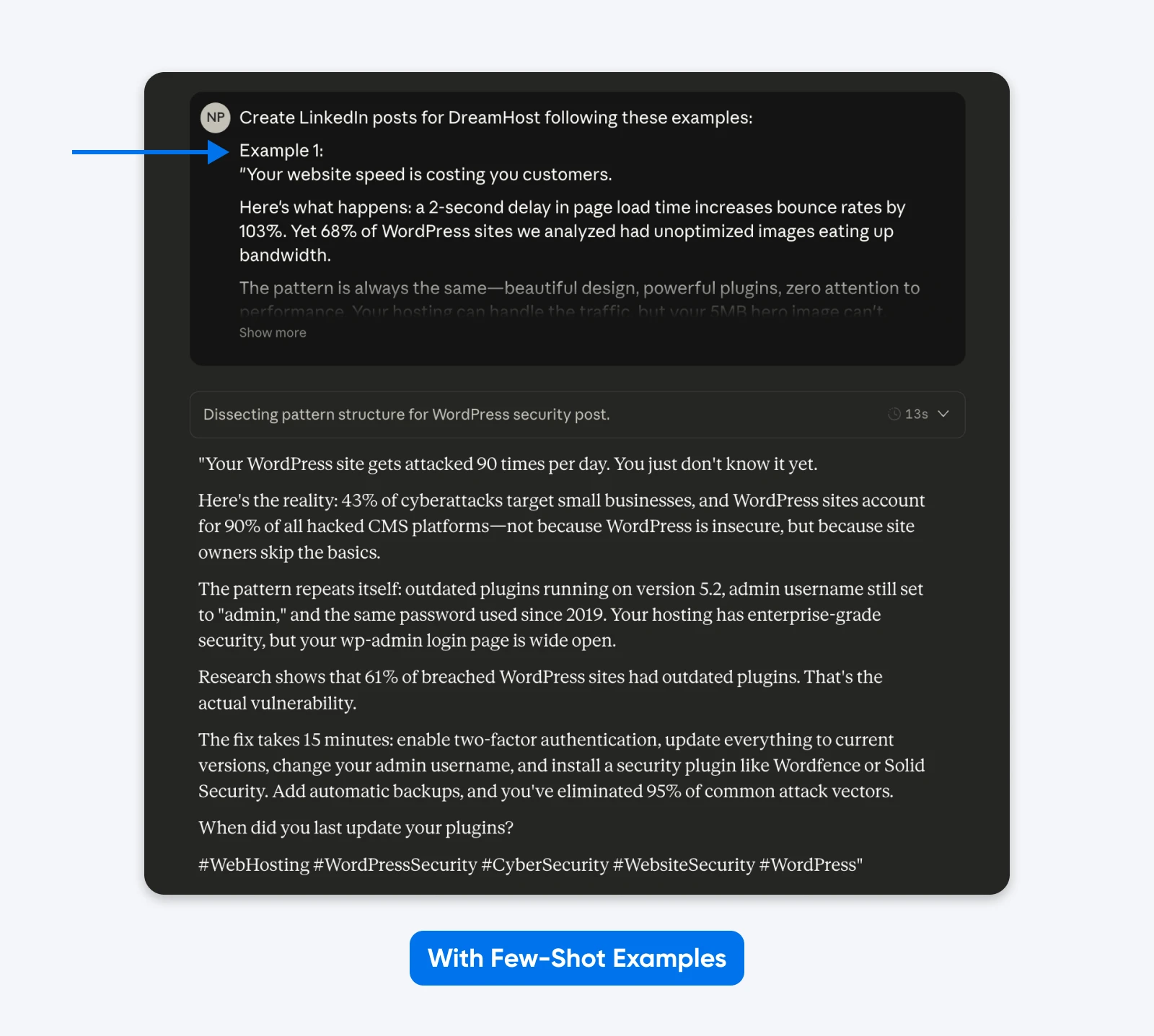
Dieses Ergebnis orientiert sich stärker an den Beispielen, die ich in der Aufforderung gegeben habe. Du kannst die Methode der wenigen Beispiele verwenden, um LinkedIn-Posts zu erstellen, die wie deine am besten performenden sind. Ein wissenschaftlicher Artikel über Finite-State-Machine (FSM)-Design zeigte, dass strukturierte Beispiele im Vergleich zu Anweisungen ohne Beispiele eine Erfolgsrate von 90% erreichten.
Wie Du Umsetzt:
- Verpacke Beispiele in <example> Tags, gruppiert in <examples> Tags
- Platziere Beispiele früh in der ersten Nutzernachricht
- Verwende 3-5 verschiedene Beispiele für komplexe Aufgaben
- Stimme jedes Detail in Beispielen auf die gewünschte Ausgabe ab (Claude 4.x repliziert Benennungskonventionen, Code-Stil, Formatierung, Zeichensetzung)
- Vermeide redundante Beispiele
Wann Beispiele Am Besten Funktionieren:
- Datenformatierung, die eine präzise Struktur erfordert
- Komplexe Programmiervorgänge, die spezifische Ansätze benötigen
- Analytische Aufgaben, die Denkmethoden demonstrieren
- Ausgabe, die einen konsistenten Stil und Konventionen erfordert
Wann Zu Überspringen: Einfache Anfragen, bei denen Anweisungen ausreichen, oder wenn Du möchtest, dass Claude nach eigenem Ermessen handelt.
Effektivitätsbewertung: 10/10 für Formatierungsaufgaben, 6/10 für einfache Anfragen.
5. Stelle Den Kontext Vor Deiner Frage
Claude verfügt über ein Kontextfenster von 200.000 Token (in einigen Fällen bis zu 1 Million) und kann Anfragen verstehen, die irgendwo im Kontext platziert sind. Aber die Dokumentation von Anthropic empfiehlt, lange Dokumente (20.000+ Token) oben in den Aufforderungen, vor den Anfragen zu platzieren.
Tests haben gezeigt, dass dies die Antwortqualität um bis zu 30% im Vergleich zur Abfrage-zuerst-Reihenfolge verbessert, insbesondere bei komplexen, mehrdokumentigen Eingaben.
Warum? Claudes Aufmerksamkeitsmechanismen gewichten Inhalte am Ende von Eingabeaufforderungen stärker. Das Platzieren der Frage nach dem Kontext ermöglicht es dem Modell, auf früheres Material zu verweisen, während Antworten generiert werden.
Vorher (Frage zuerst):
Die Quartalsfinanzleistung analysieren und Schlüsseltrends identifizieren.
[20,000 Token an Finanzdaten]
Nach (Kontext-Zuerst):
[20.000 Token finanzieller Daten]
Auf Grundlage der oben bereitgestellten Quartalsfinanzdaten, analysiere die Leistung und identifiziere Schlüsseltrends im Umsatzwachstum, der Margenexpansion und der betrieblichen Effizienz. Konzentriere Dich auf umsetzbare Erkenntnisse für die Entscheidungsfindung des Managements.
Wann Dies Wichtig Ist: Langzeitanalyse, bei der Claude umfangreich auf früheres Material Bezug nehmen muss.
Wann Zu Überspringen: Kurze Anfragen unter 5.000 Tokens.
Effektivitätsbewertung: 8/10 für Aufgaben mit langem Kontext, 4/10 für kurze Aufforderungen.
Welche Aufforderungstechniken Funktionieren Nicht Mehr: Aufklärung Über Häufige Mythen
Die Änderungen in Claude 4.5 haben mehrere beliebte Techniken ungültig gemacht, die mit früheren Modellen funktionierten.
1. Betonung Von Wörtern (GROSSBUCHSTABEN, „MUSS“, „IMMER“)
Schreiben in Großbuchstaben garantiert nicht mehr die Einhaltung. Chris Tysons Analyse ergab, dass Claude nun Kontext und Logik über Betonung stellt.
Wenn Du „NIEMALS Daten erfinden“ schreibst, aber der Kontext eine Schätzung erfordert, gibt Claude 4.5 der logischen Notwendigkeit den Vorrang vor Deinem großgeschriebenen Befehl.
Verwende stattdessen bedingte Logik:
- Schlecht: Verwende IMMER genaue Zahlen!
- Gut: Wenn verifizierte Daten verfügbar sind, verwende präzise Zahlen. Wenn nicht, gib Bereiche an und kennzeichne sie als Schätzungen.
2. Anleitung Für Manuelle Gedankengänge
Dem Modell zu sagen, es solle „Schritt für Schritt denken“, verschwendet Tokens, wenn der erweiterte Denkmodus verwendet wird.
Wenn Du Erweitertes Denken aktivierst, verwaltet das Modell sein eigenes Begründungsbudget. Eigene „Schritt-für-Schritt“-Anweisungen hinzuzufügen, ist überflüssig.
Was stattdessen zu tun ist:
Vertraue dem Werkzeug. Wenn Du Erweitertes Denken aktivierst, entferne alle Anweisungen darüber, wie man denkt.
3. Negative Einschränkungen („Tue Nicht X“)
Claude genau zu sagen, was er nicht tun soll, geht oft nach hinten los.
Forschung über Anweisungen zum „Pink Elephant“ zeigt, dass es wahrscheinlicher ist, dass ein fortgeschrittenes Modell sich darauf konzentriert, wenn man ihm sagt, nicht darüber nachzudenken.
Claudes Aufmerksamkeitsmechanismus hebt das verbotene Konzept hervor, indem er es im Kontextfenster aktiv hält.
Stattdessen formuliere jedes Negative als einen positiven Befehl um:
- Schlecht: Schreibe keine langen, ausschweifenden Einleitungen. Verwende keine Wörter wie „eintauchen“ oder „Gewebe.“
- Gut: Beginne direkt mit dem Hauptargument. Verwende prägnante, treffende Sprache.
Wie Migriert Man Prompts Von Claude 3.5 Zu Claude 4?
Wenn Du von Claude 3.5 auf 4.5 umsteigst, kannst Du Deine Prompt-Bibliothek mithilfe von fünf systematischen Schritten migrieren, die durch die Erfahrung der Entwickler validiert wurden.
Wir werden ein gängiges Hosting-Szenario für dieses Beispiel verwenden. Ziel ist es, eine technische Support-Antwort für einen Kunden zu generieren, der auf seiner WordPress-Website einen „503 Service Unavailable“-Fehler erlebt.

1. Implizite Annahmen Prüfen
Beginne damit, zu identifizieren, wo der Prompt davon ausgeht, dass das Modell den Kontext erraten muss. In älteren Versionen würde das Modell annehmen, dass Du den am häufigsten verwendeten Software-Stack benutzt. Claude 4.5 wird diese Annahme nicht mehr treffen.
Alte Aufforderung:
„Meine Website lädt langsam und zeigt Fehler an. Du bist ein erfahrener Serveradministrator. Denke Schritt für Schritt und sage mir, wie ich die Konfiguration ändern kann, um sie schneller zu machen.“
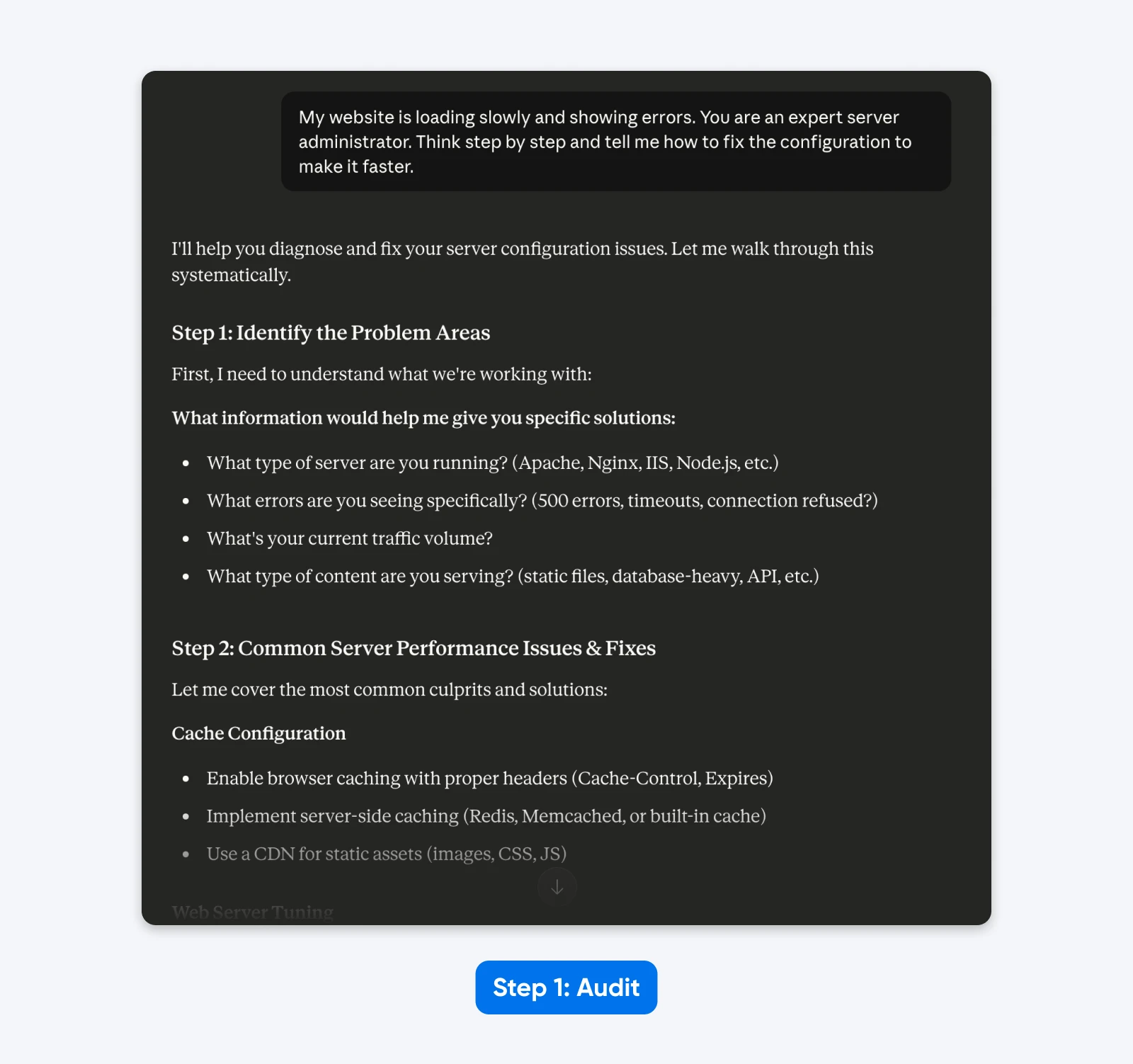
Die Überprüfung:
- „Website“ impliziert eine generische Einrichtung anstatt eines spezifischen CMS (WordPress).
- „Langsam“ ist subjektiv; es könnte eine hohe Time to First Byte oder langsames Rendern von Ressourcen bedeuten.
- „Fehler“ fehlen die spezifischen HTTP-Statuscodes, die für die Diagnose benötigt werden.
- „Experten-Serveradministrator“ und „Schritt für Schritt denken“ sind unnötige Lenkungsanweisungen.
In der Antwort bittet Claude 4.5 um weitere Informationen, da er darauf trainiert ist, Annahmen zu vermeiden.
2. Refaktorisierung Für Explizite Spezifität
Jetzt, definiere die Umgebung neu, das spezifische Problem und das gewünschte Ausgabeformat. Du musst die technischen Details angeben, die das Modell zuvor erraten hat.
Überarbeitete Aufforderung:
„Meine WordPress-Website, die auf Nginx und Ubuntu 20.04 läuft, zeigt eine hohe Zeit bis zum ersten Byte (TTFB) und gelegentliche 502 Bad Gateway-Fehler. Du bist ein erfahrener Serveradministrator. Denke Schritt für Schritt und gib spezifische Änderungen in der Nginx- und PHP-FPM-Konfiguration an, um diese Zeitüberschreitungen zu beheben.“

Das Ergebnis: Die Eingabeaufforderung gibt jetzt den genauen Software-Stack (Nginx, Ubuntu, WordPress) und den spezifischen Fehler (502 Bad Gateway) an, wodurch die Wahrscheinlichkeit irrelevanter Ratschläge über Apache oder IIS verringert wird. Und Claude antwortet mit einer Analyse und einer schrittweisen Lösung.
3. Bedingte Logik Implementieren
Claude 4.5 zeigt seine Stärken, wenn er einen Entscheidungsbaum vorgelegt bekommt. Anstatt nach einer einzigen statischen Lösung zu fragen, weise das Modell an, verschiedene Szenarien basierend auf den analysierten Daten zu behandeln.
Aufforderung Mit Logik:
„Meine WordPress-Site, die auf Nginx und Ubuntu 20.04 läuft, hat hohe TTFB und 502 Bad Gateway Fehler. Du bist ein erfahrener Serveradministrator. Denke Schritt für Schritt.
Wenn die Fehlerprotokolle ‚upstream sent too big header‘ zeigen, gib Konfigurationsänderungen für Puffergrößen an. Wenn die Fehlerprotokolle ‚upstream timed out‘ zeigen, gib Konfigurationsänderungen für die Ausführungszeitgrenzen an.“
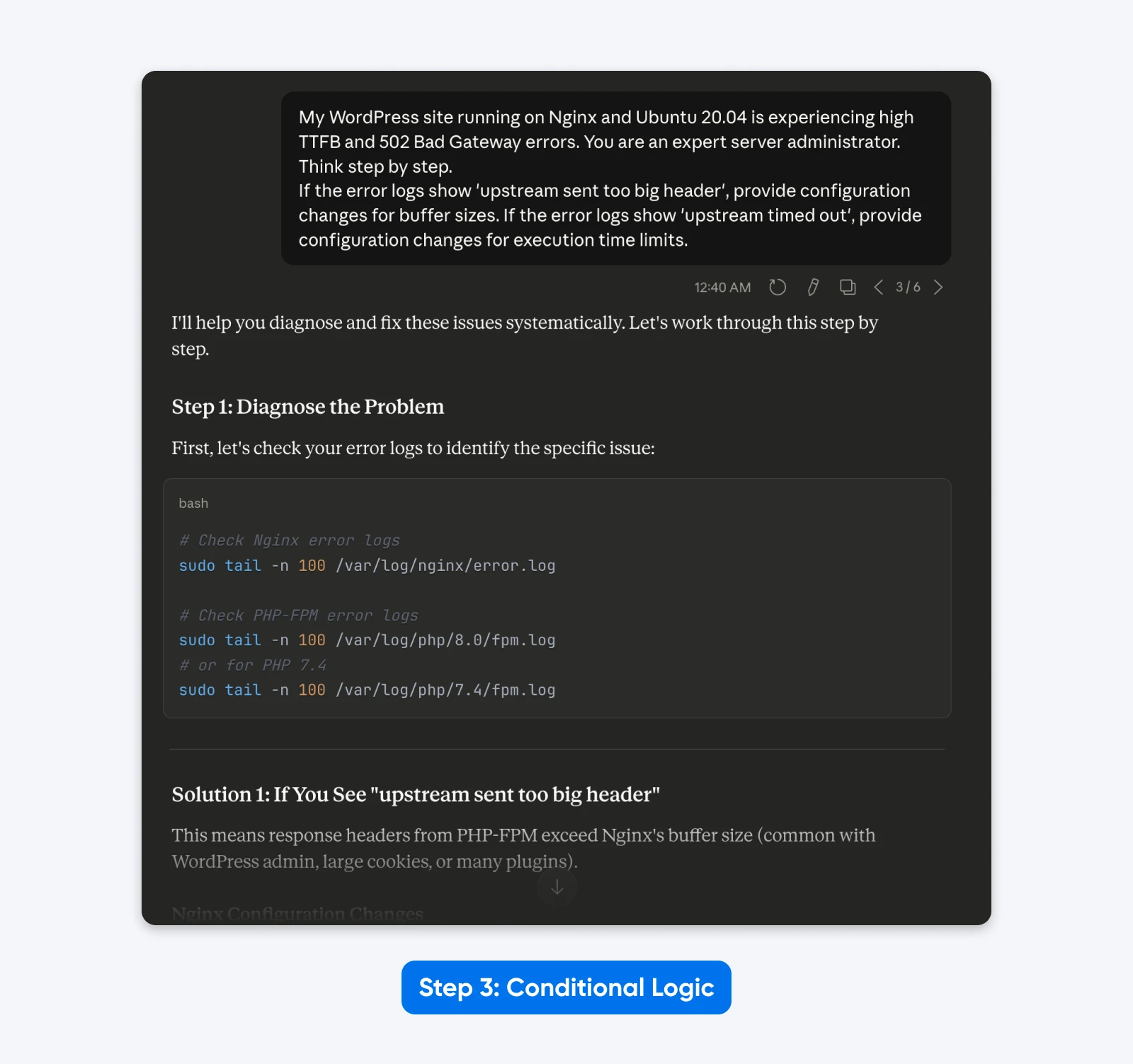
Das Ergebnis: Die Ausgabe wird dynamisch. Das Modell bietet gezielte Lösungen basierend auf der von dir definierten spezifischen Ursachenlogik, anstatt einer allgemeinen Liste von Lösungen.
4. Veraltete Steuersprache Entfernen
Alte Aufforderungen enthalten oft Denkanweisungen, von denen die Benutzer glaubten, dass sie die Leistung verbessern. Diese sind mit Claude 4.5 überflüssig und redundant, da es erweitertes Denken bietet.
Bereinigter Prompt:
„Meine WordPress-Website, die auf Nginx und Ubuntu 20.04 läuft, hat eine hohe TTFB und 502 Bad Gateway Fehler.
Wenn die Fehlerprotokolle ‚upstream sent too big header‘ anzeigen, gib Konfigurationsänderungen für die Puffergrößen an. Wenn die Fehlerprotokolle ‚upstream timed out‘ zeigen, gib Konfigurationsänderungen für die Ausführungszeitlimits an.“
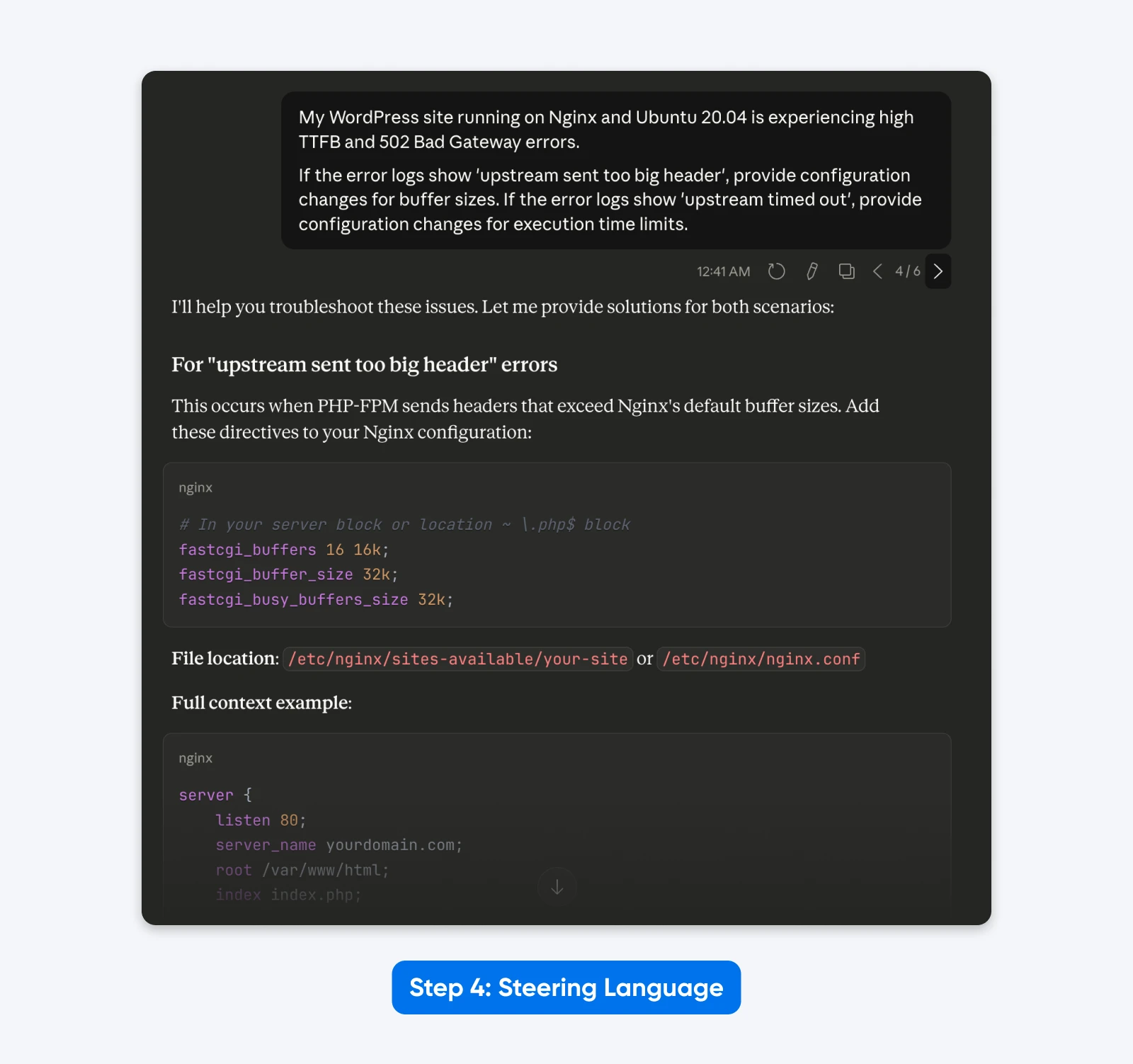
Das Ergebnis: Ein schlankeres Prompt, das sich rein auf die technische Aufgabe konzentriert und die Ablenkung durch „Du bist ein Experte“ und „Denke Schritt für Schritt“ entfernt.
5. Systematisch Testen
Füge die Komponenten in einem strukturierten Format mithilfe von XML oder klaren Überschriften zusammen. Dies entspricht den Trainingsdaten des Modells und liefert die konsistentesten Ergebnisse.
ROLLE: Linux-Systemadministrator, spezialisiert auf Nginx und WordPress-Leistung.
AUFGABE: Behebung von 502 Bad Gateway-Fehlern und Reduzierung der Zeit bis zum ersten Byte (TTFB) für eine WordPress-Seite auf Ubuntu 20.04.
LOGIK:
- Wenn Protokolle 'upstream sent too big header' zeigen, erhöhe fastcgi_buffer_size und fastcgi_buffers.
- Wenn Protokolle 'upstream timed out' zeigen, erhöhe fastcgi_read_timeout in nginx.conf und request_terminate_timeout in www.conf.
AUSGABEANFORDERUNGEN:
- Gib genaue Konfigurationszeilen zur Änderung an.
- Erkläre die Auswirkungen jeder Änderung auf den Server-Speicher.
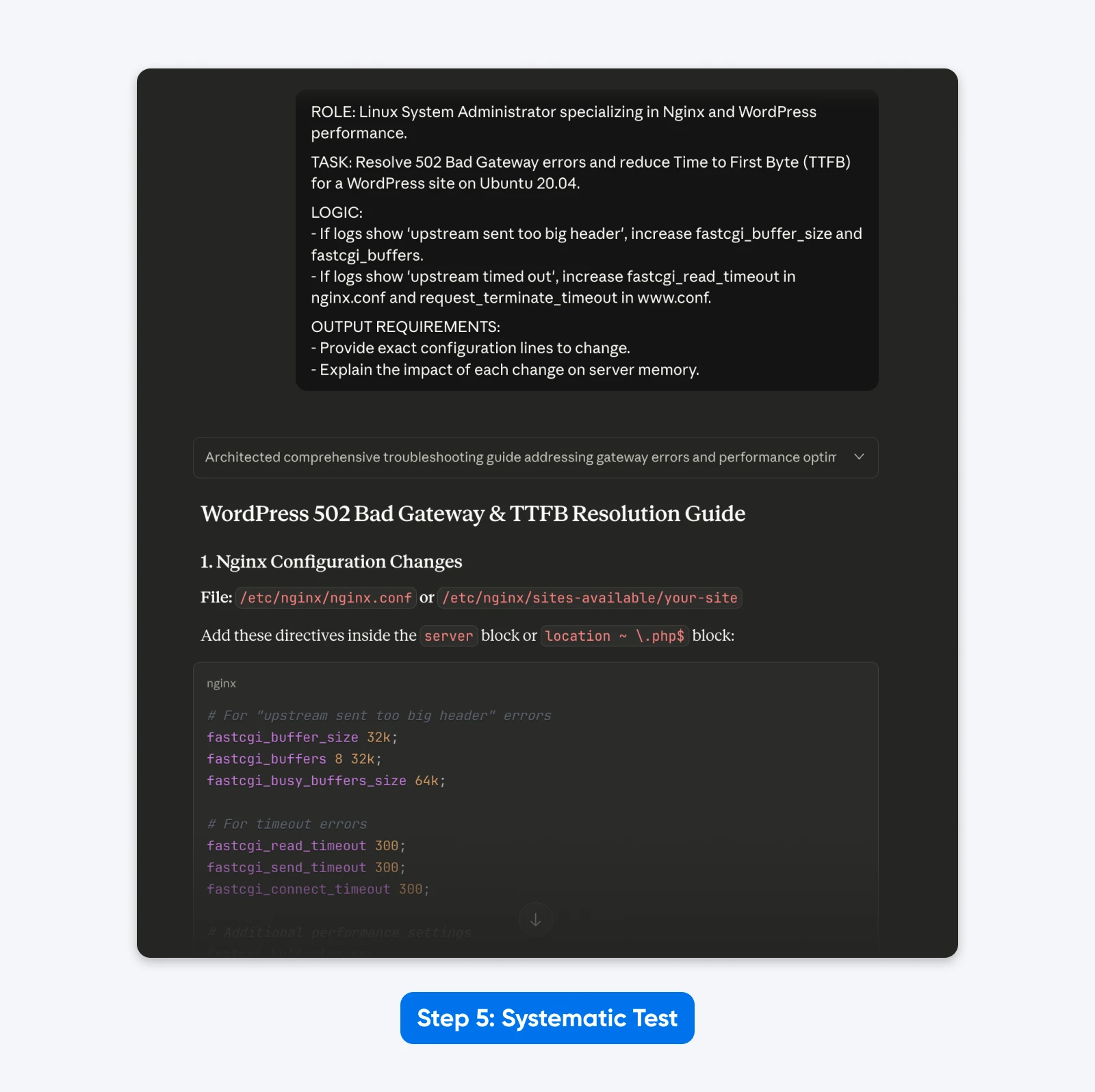
Das Ergebnis: Die Antwort war strukturierter, ermöglichte es mir, das Problem mit kopierbaren Konfigurationsdateidaten zu lösen, wie angefordert, und erklärte die Lösung besser.
Was Das Für Deinen Workflow Bedeutet
Die Claude 4.x Modelle funktionieren anders als frühere Modelle. Sie folgen Deinen genauen Anweisungen, anstatt anzunehmen, was Du gemeint hast, was hilft, wenn Du konsistente Ergebnisse benötigst. Der Aufwand, den Du am Anfang in das Prompt-Engineering investierst, zahlt sich aus, wenn Du dieselbe Aufgabe wiederholt ausführst.
Jede Technik in diesem Leitfaden wurde sorgfältig ausgewählt, weil sie eng mit der Art und Weise übereinstimmt, wie Claude 4.x entwickelt wurde. XML-Tags, Erweiterter Denkmodus, explizite Anweisungen, wenige Beispiele und ein kontextorientierter Ansatz funktionieren, weil sie, basierend auf Claudes Aufforderungsleitfäden und anekdotischen Beweisen, wahrscheinlich so sind, wie Anthropic die Modelle trainiert hat.
Also los, wähle eine oder zwei Techniken aus diesem Leitfaden und teste sie in Deinen tatsächlichen Arbeitsabläufen. Beobachte, was sich verändert und welche Methoden zu Deinem Vorteil arbeiten. Der beste Ansatz ist der, der durch echte Daten aus Deinen täglichen Arbeitsabläufen unterstützt wird.

