
Si tu as remarqué que ton illustrateur préféré a soudainement disparu d’Instagram, ou ce parent ami qui efface discrètement toutes les photos de son enfant de Facebook, tu ne l’imagines pas. Ces dernières années, des personnes ont retiré du contenu du web en raison de préoccupations concernant l’IA générative.
Cela peut se manifester de différentes manières : des artistes retirant leurs portfolios en ligne après avoir découvert des modèles d’IA crachant des peintures dans leur propre style, des parents supprimant des photos de famille de peur que les visages de leurs enfants ne finissent dans un deepfake, ou des entreprises bloquant entièrement l’accès de leur site web aux robots d’IA.
D’après une analyse des clients de DreamHost, nous avons constaté que environ 5 000 sites web au total utilisant nos services d’hébergement bloquent activement certains ou tous les robots d’indexation IA.
En d’autres termes, il existe une préoccupation réelle et mesurable sur la manière dont les outils IA accèdent, comprennent et ingèrent le contenu que nous mettons tous en ligne.
Ce n’est pas que ces soucis soient nouveaux.
Internet a toujours été un lieu compliqué pour le consentement, la confidentialité et la propriété. Ce qui a changé, c’est que l’IA a obligé tout le monde : créateurs, familles et propriétaires de petites entreprises, à enfin affronter à quel point ils ont peu de contrôle sur ce qu’ils mettent en ligne.
Chez DreamHost, nous avons toujours cru que le web ouvert prospère lorsque les créateurs contrôlent ce qu’ils partagent et comment cela est utilisé. Le web fonctionne mieux lorsque la propriété est entre les mains des personnes qui l’ont construit — et non juste des plateformes qui en tirent profit.
Et cela nous amène au cœur du sujet. La vraie question n’est pas ce que l’IA peut faire — c’est qui a le droit de décider.
Le Véritable Problème Éthique De L’IA N’est Pas La Technologie — C’est La Perte De Choix
L’IA n’est pas le méchant ici. La véritable menace est le « paternalisme des plateformes », ou les entreprises qui prennent des décisions “éthiques” au nom de tout le monde. Par exemple, en 2024, plusieurs grands réseaux de distribution de contenu (CDNs) et fournisseurs de réseau ont commencé à bloquer par défaut les robots d’indexation IA, affirmant que leur objectif était de “protéger les créateurs.” Le résultat a été que des millions de propriétaires de sites se sont réveillés pour découvrir que des décisions concernant leur contenu avaient déjà été prises pour eux.
C’est comme si ton propriétaire fermait ta porte à clé pour ta sécurité, mais sans te donner les bonnes clés. Ce qui a commencé comme une commodité se transforme rapidement en une perte d’autonomie. Lorsque les gardiens décident à quoi ressemble la “protection”, l’autonomie individuelle diminue.
Le web ouvert a été construit sur l’innovation sans permission, signifiant que n’importe qui pouvait créer, partager et itérer sans demander d’approbation. Les intermédiaires décidant quels bots ou outils peuvent accéder au contenu peuvent remonter cette liberté de plusieurs décennies.
C’est pourquoi DreamHost plaide pour l’indépendance de l’infrastructure : quand tu héberges ton propre contenu, personne ne peut réécrire tes règles. Posséder ton stack signifie posséder tes politiques, que tu accueilles des robots d’indexation IA ou que tu les exclues totalement. L’éthique ne vient pas du code ; elle vient du choix.

« L’IA a besoin de tes données » et autres mythes
Alors, qu’est-ce qui empêche les créateurs de reprendre le contrôle ? Souvent, c’est la désinformation, comme ces mythes répandus autour de l’IA. Ces mythes sont populaires parce que l’utilisation de l’IA s’est répandue sur internet et les outils que nous utilisons tous les jours.
Mythe #1 : « L’IA a besoin de tes données pour progresser »
Personne ne doit son travail aux entreprises d’IA à but lucratif. Des modèles sous licence et basés sur le consentement existent ; par exemple, Adobe Firefly forme du contenu sous licence avec permission et des œuvres du domaine public sans droit d’auteur. L’avenir de l’IA ne doit pas dépendre du vol. Il peut reposer sur le consentement à la place.
Mythe #2 : « Si Tu Désactives, Tu Disparaîtras »
Se désinscrire pourrait limiter ta présence dans les résumés générés par IA ou les extraits de recherche, mais cela ne t’effacera pas du web. Pense à cela comme se désinscrire de Google en 2005. Tu perdrais de la portée, mais pas de pertinence, surtout si ton public te cherche encore directement.
Bien que cela puisse ne pas être pratique pour ceux qui dépendent de la portée pour développer leur audience ou leur base de clients (bien que nous n’ayons toujours pas de données précises sur le trafic organique qui provient réellement de GEO), pour certains créateurs, la visibilité ne justifie pas l’utilisation involontaire. L’essentiel est que eux décident.
Mythe #3 : « Le Scraping IA Est Tout Simplement Le Fonctionnement D’Internet »
L’indexation pour la découverte et l’appropriation pour la formation ne sont pas la même chose.
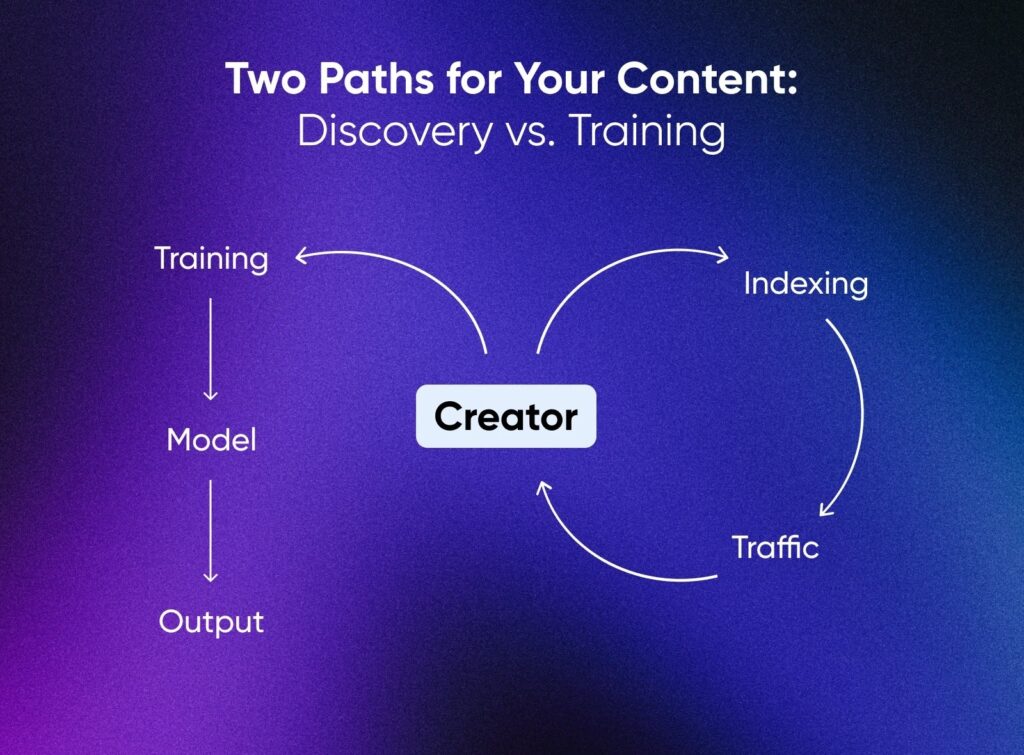
L’indexation attire les visiteurs sur ton site. La formation te remplace par une copie statistique. Des éditeurs comme l’Associated Press et Axel Springer prouvent qu’il y a un juste milieu en licenciant leur contenu pour la formation de modèles avec crédit et compensation.
Même les bonnes intentions peuvent se retourner contre toi. En fin de compte, une éthique équilibrée nécessite un consentement éclairé.
Se Désengager vs. Rester Ouvert : Les Véritables Compromis
Chaque position vis-à-vis de l’IA — de la pleine ouverture à l’exclusion totale — comporte des coûts d’opportunité réels. Décider de ta position dépend de ce que tu valorises le plus, de la visibilité au contrôle, en passant par la durabilité et l’autonomie.
Les données internes de DreamHost montrent que 71,5% de tout le trafic web provient maintenant des bots, et non des humains. Cela signifie que la plupart des requêtes qui atteignent ton site sont automatisées : certaines sont bénéfiques (comme l’indexation de recherche ou la surveillance de disponibilité), d’autres moins. Gérer quels robots d’indexation tu autorises et lesquels tu bloques, c’est mettre en pratique une durabilité éthique.
Ci-dessous, quatre approches courantes que les créateurs adoptent pour l’accès et la formation à l’IA et comment chacune impacte différents facteurs du web ouvert, afin que tu puisses visualiser les compromis avant de fixer ta position.
| Totalement Ouvert | Licence Sélective | Blocage de l’Entraînement IA | Complètement Exclu de l’IA | |
| Visibilité et Portée | La plus haute; les résumés IA et les moteurs de recherche peuvent diffuser votre travail partout. | Modérée; l’exposition est limitée aux partenaires qui achètent des licences de contenu. | Faible; exclu des résultats IA mais toujours présent dans les recherches traditionnelles. | Aucune; bloqué à la fois par l’IA et de nombreux robots d’exploration. |
| Contrôle et Consentement | Minime; les plateformes décident pour toi. | Élevé; régi par des termes de licence explicites. | Forte; tu définis les permissions via robots.txt et les en-têtes HTTP. | Absolu; tout accès automatisé est interdit. |
| Attribution | Faible; la plupart des modèles IA ne citent pas les sources. | Élevée; l’attribution et les royalties sont intégrées dans les contrats. | Moyenne; les robots conformes peuvent encore te créditer. | Aucune; le contenu n’est jamais référencé. |
| Impact Environnemental | Modéré; contribue à l’entraînement général des modèles et à la charge d’indexation. | Modéré; l’utilisation sous licence limitée réduit l’entraînement en double. | Modérément faible; moins de robots lourds, plus de trafic ciblé. | Faible; le moins de requêtes externes et de transferts de données. |
| Risque de Mauvais Usage ou de Copie | Élevé; le style ou le texte peuvent être librement répliqués. | Modéré; recours légal via les termes de licence. | Faible; les robots conformes sont dissuadés, les robots voyous restent possibles. | Très faible; peu de surface pour le grattage. |
Chaque chemin a ses mérites. Les marketeurs et les petits entrepreneurs dépendent souvent de la visibilité pour agrandir leur audience, tandis que les illustrateurs, journalistes et éducateurs peuvent donner la priorité à la propriété et au consentement avant tout. Le web prospère grâce à la diversité, et la participation éthique à l’IA devrait refléter cette diversité d’objectifs.
Il n’y a pas de réponse universellement correcte : seulement des compromis éclairés qui s’alignent avec tes principes et ta façon de gagner ta vie en ligne. La bonne posture n’est pas universelle, mais tu devrais la former consciemment et la soutenir par des actions. Quel que soit le chemin que tu choisis, fais-le intentionnellement.
Comment Déterminer Ta Position Sur L’IA
L’éthique n’est importante que lorsqu’elle est mise en pratique. Voici comment transformer la théorie en action et définir comment l’IA interagit avec ton travail.
Étape 1 : Clarifie Tes Objectifs
Commence par classer ce qui compte le plus pour toi : visibilité, revenus, durabilité, contrôle.
Une petite entreprise cherchant à étendre sa portée peut tolérer une utilisation plus large de l’IA, tandis qu’un illustrateur protégeant son originalité pourrait ne pas le faire. Différents objectifs = différentes limites.

Étape 2 : Audit De Ton Empreinte Numérique
Liste où réside ton contenu : sites WordPress, dépôts GitHub, réseaux sociaux, stockage en cloud. Les plateformes appliquent leurs propres politiques d’IA, donc l’indépendance de l’hébergement te permet de définir des règles par site au lieu d’accepter les paramètres par défaut globaux imposés par les plateformes que tu utilises (sans ton intervention).
Étape 3 : Appliquer Les Contrôles Techniques
Utilise ton fichier robots.txt pour indiquer aux robots IA comment se comporter :
User-agent: GPTBot |
Ajoute des en-têtes (comme X-Robots-Tag: noai, noimageai) pour plus de clarté. Souviens-toi, la conformité est volontaire. Ces balises indiquent tes souhaits, mais ne les imposent pas.
Étape 4 : Publier Une Politique IA Transparente
Crée une page simple indiquant ta position. Par exemple :
| “Les systèmes d’IA ne peuvent pas utiliser ce contenu pour l’entraînement ou la réplication.” |
La transparence crée la confiance avec les clients et établit des limites claires pour une utilisation future.
Étape 5 : Surveille et Adapte
Utilise les logs de serveur ou les analytics pour suivre ton mix de robots. Examine cela trimestriellement et mets à jour tes règles au fur et à mesure que de nouveaux robots d’indexation apparaissent.
Les Seules Éthiques IA Qui Comptent Sont Les Tiennes
L’IA n’a pas d’éthique — les personnes en ont. Ce qui importe, ce n’est pas si tu as bloqué chaque robot d’indexation ou utilisé chaque outil ; c’est que tu aies fait ces choix intentionnellement.
Le web a été construit sur la liberté de partager, de remixer, d’expérimenter et de construire sans autorisation. La véritable éthique numérique protège ce même esprit d’autodétermination.
Tu es passé de la peur au contrôle, de l’incertitude à la propriété. Chez DreamHost, nous pensons que posséder ta présence numérique n’est pas seulement une bonne affaire, c’est aussi comment tu préserves tes principes dans un monde dirigé par les algorithmes.
Le web ouvert reste à toi, si tu choisis de le posséder.

