
Cuando Claude Sonnet 4.5 se lanzó en septiembre de 2025, rompió muchos de los prompts existentes. No porque el lanzamiento tuviera errores, sino porque Anthropic había reconstruido la forma en que Claude sigue las instrucciones.
Las versiones anteriores inferían tu intención y ampliaban solicitudes vagas. Claude 4.x te toma de forma literal y hace exactamente lo que le pides, nada más.

Para entender los nuevos métodos, evaluamos 25 técnicas populares de prompt engineering comparándolas con la documentación de Anthropic, experimentos de la comunidad y casos de uso reales, con el fin de identificar qué prompts funcionan realmente mejor con Claude 4.x. Estas cinco técnicas…
TL;DR:
- Descubre qué técnicas de prompting ofrecen mejoras de rendimiento medibles para Claude Sonnet 4.5 y Opus 4.1.
- El cambio de comportamiento de Claude 3.5 a Claude 4.x que ha dejado obsoletos muchos prompts existentes (te mostraremos cuáles).
- Ejemplos de antes y después que muestran diferencias reales de efectividad con métricas específicas.
- Conoce cinco técnicas probadas, respaldadas por datos de testing e implementaciones corporativas.
- Finalmente, te mostraremos cómo migrar prompts de sistemas basados en Claude 3.5 a Claude 4.x.
¿Qué Cambió en Claude 4.5 Que Rompió los Prompts Existentes?
Los modelos Claude 4.5 priorizan instrucciones precisas por encima de las suposiciones “útiles”.
Las versiones anteriores completaban los espacios por ti. Si pedías un “dashboard”, asumían que querías gráficos, filtros y tablas de datos.
Claude 4.5 te toma de forma literal. Si pides un dashboard, puede entregarte solo un marco en blanco con un título, porque no solicitaste el resto.
Anthropic lo deja claro: “Los clientes que deseen un comportamiento de ‘ir más allá’ podrían necesitar solicitar explícitamente estas acciones.”
Así que debemos dejar de tratar al modelo como una varita mágica y empezar a tratarlo como a un empleado de mentalidad literal.
Las 5 Técnicas Comprobadas que Mejoran de Forma Medible el Rendimiento de Claude
Según nuestra investigación, estas cinco técnicas ofrecieron de manera constante mejoras notables en el rendimiento de Claude para las tareas que le planteamos.
1. Prompts Estructurados y Etiquetados
El system prompt de Claude Sonnet 4.5 utiliza prompts estructurados en todas partes. Simon Willison analizó los system prompts y encontró secciones envueltas en etiquetas como <behavior_instructions>, <artifacts_info> y <knowledge_cutoff>.
De hecho, puedes editar los “Styles” para ver el prompting estructurado de Anthropic en acción.

Lo que podemos inferir es que Claude fue entrenado con prompts estructurados y sabe cómo interpretarlos. XML funciona muy bien, al igual que JSON u otros formatos de prompts etiquetados.
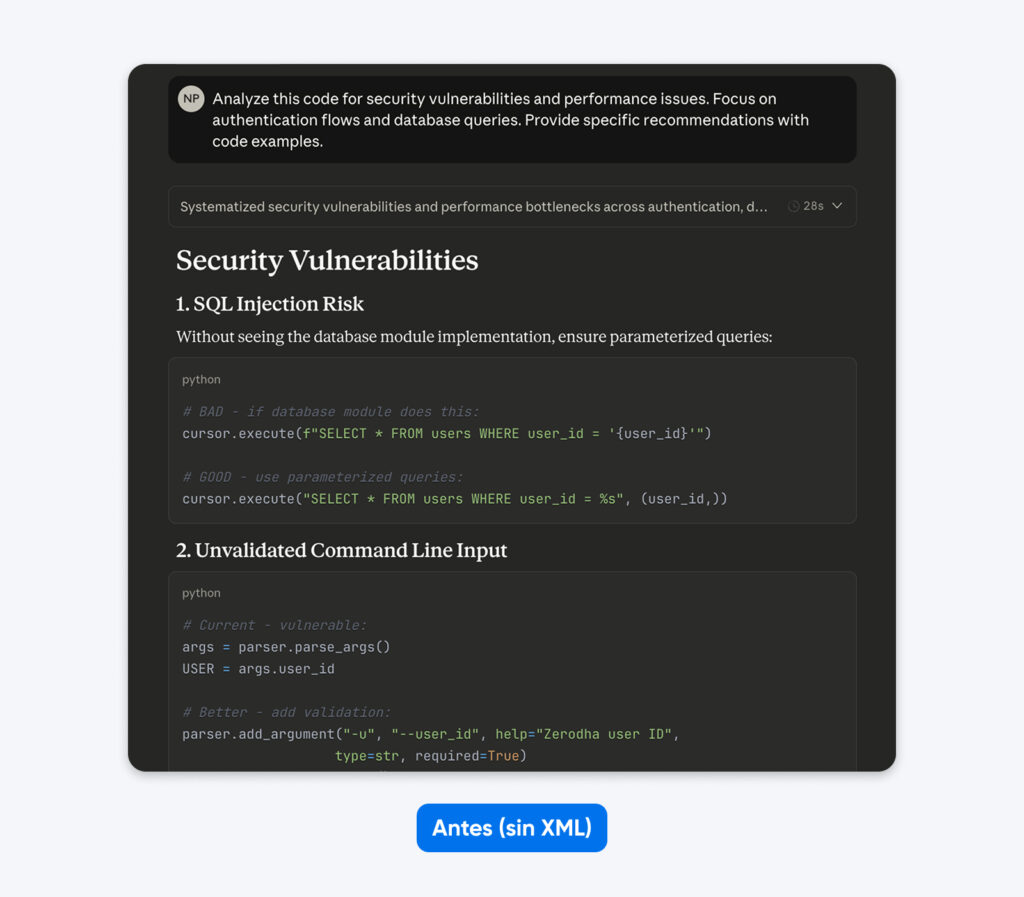
Antes:
Analiza este código en busca de vulnerabilidades de seguridad y problemas de rendimiento. Enfócate en los flujos de autenticación y las consultas a la base de datos. Proporciona recomendaciones específicas con ejemplos de código.
Después (prompt estructurado):
<task>Analizar el código proporcionado en busca de problemas de seguridad y rendimiento</task>
<focus_areas>
– Flujos de autenticación
– Optimización de consultas a la base de datos
</focus_areas>
<code>
[aquí va tu código]
</code>
<output_requirements>
– Identificar vulnerabilidades específicas con niveles de severidad
– Proporcionar ejemplos de código corregido
– Priorizar las recomendaciones según el impacto en el negocio
</output_requirements>
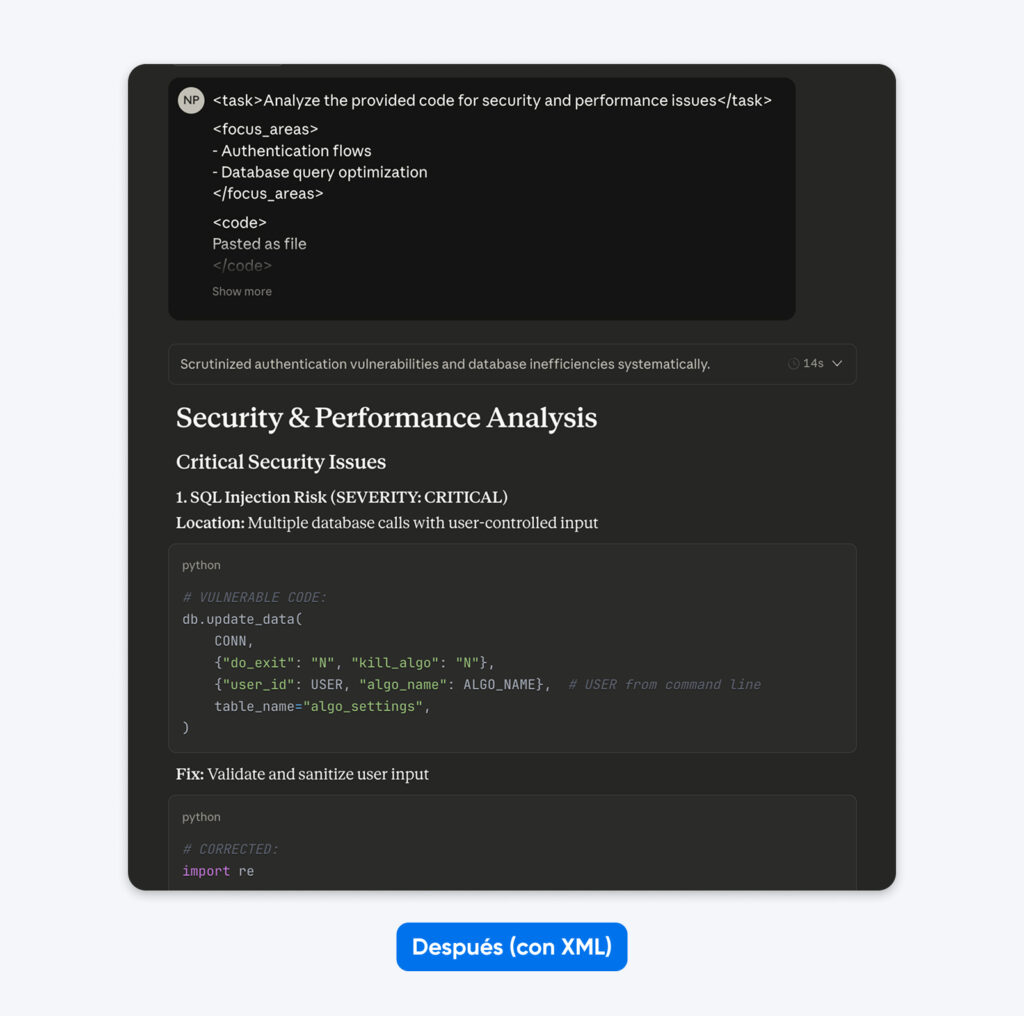
Si comparas estos resultados, notarás que el prompt estructurado genera una salida con más contexto, lo que te ayuda a comprender y corregir los problemas de seguridad en el código. Explica el problema, indica qué hace la corrección y luego proporciona el código corregido.
Formatos alternativos que funcionan:
JSON:
{
“task”: “Revisar el código de autenticación”,
“focus_areas”: [“Hashing de contraseñas”, “Seguridad de sesiones”, “Inyección SQL”],
“context”: “Aplicación de salud, requiere cumplimiento HIPAA”,
“output_format”: “Riesgo, impacto, corrección y severidad por vulnerabilidad”
}
Encabezados claros:
TAREA: Revisar el código de autenticación en busca de vulnerabilidades
ENFOQUE: Hashing de contraseñas, sesiones, inyección SQL
CONTEXTO: Aplicación de salud que requiere cumplimiento de HIPAA
FORMATO DE SALIDA: Riesgo → Impacto en HIPAA → Corrección → Severidad
Los tres funcionan igual de bien.
Cuándo funcionan mejor los prompts estructurados:
- Múltiples componentes del prompt (tarea, contexto, ejemplos, requisitos)
- Entradas largas (10.000+ tokens de código o documentos)
- Flujos de trabajo secuenciales con pasos bien definidos
- Tareas que requieren referencias repetidas a secciones específicas
Cuándo evitar los prompts estructurados: Preguntas simples donde el texto plano funciona perfectamente.
Calificación de efectividad: 9/10 para tareas complejas, 5/10 para consultas simples.
2. Pensamiento Extendido para Problemas Complejos
El pensamiento extendido ofrece mejoras enormes en tareas de razonamiento complejo, con una gran contrapartida: la velocidad.
El anuncio de Claude 4 por parte de Anthropic mostró mejoras de rendimiento sustanciales al habilitar el pensamiento extendido. En la competencia matemática AIME 2025, las puntuaciones mejoraron de forma significativa.
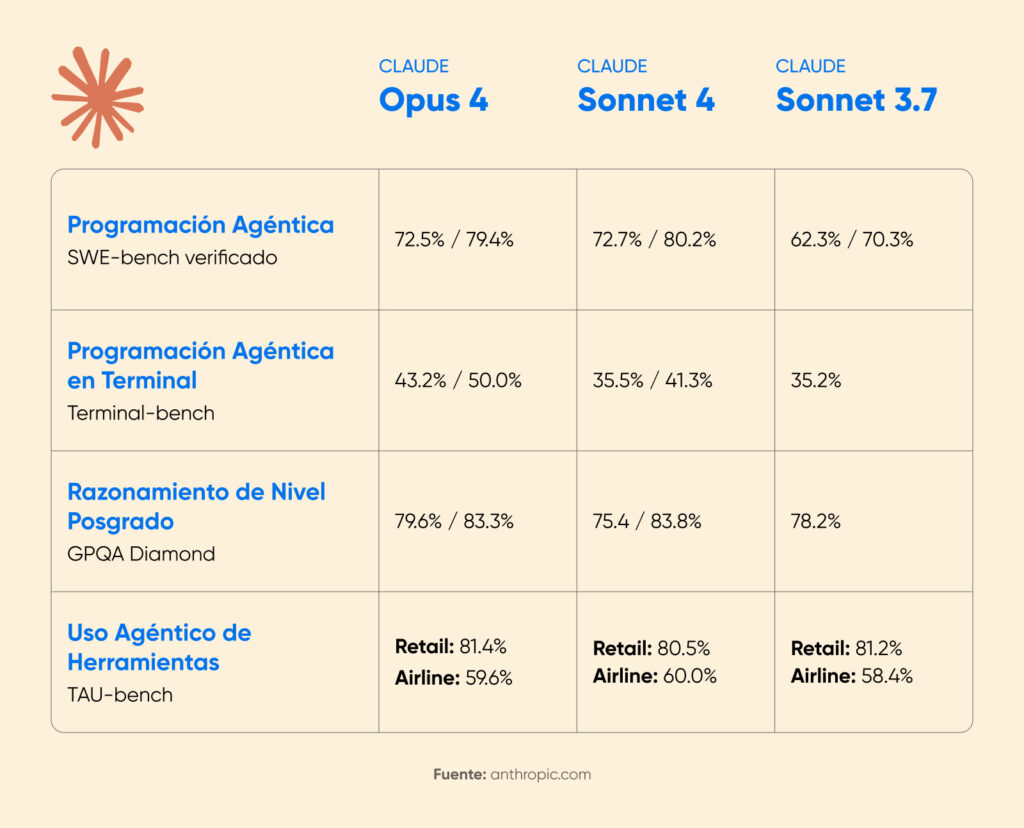
Cognition AI informó un aumento del 18% en el rendimiento de planificación con Sonnet 4.5, calificándolo como “el mayor salto que hemos visto desde Claude Sonnet 3.6”.
Antes (modo estándar):
Resuelve este acertijo lógico: cinco casas en fila, cada una de un color diferente…
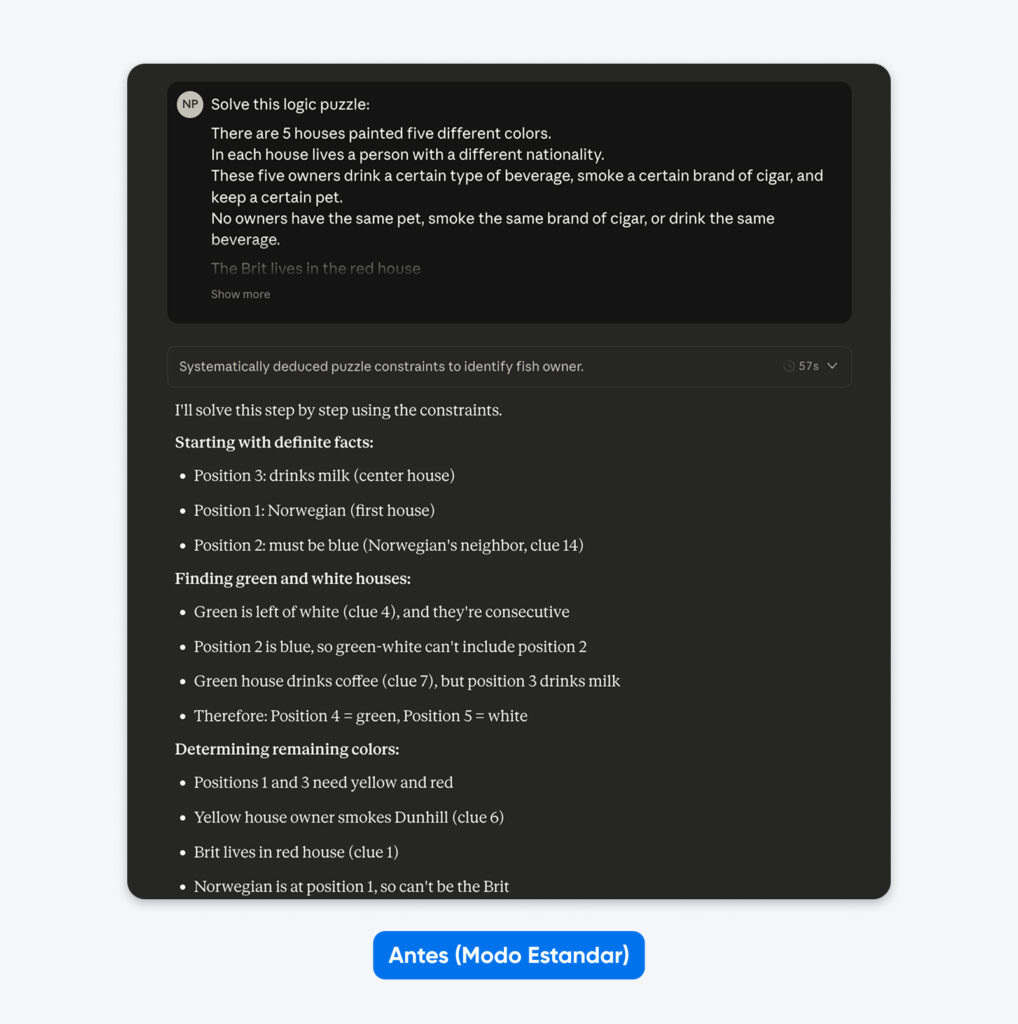
Después (con pensamiento extendido):
Comprende la lógica de este acertijo de forma sistemática. Recorre las restricciones paso a paso, verificando cada posibilidad antes de llegar a conclusiones.
Cinco casas en fila, cada una de un color diferente…
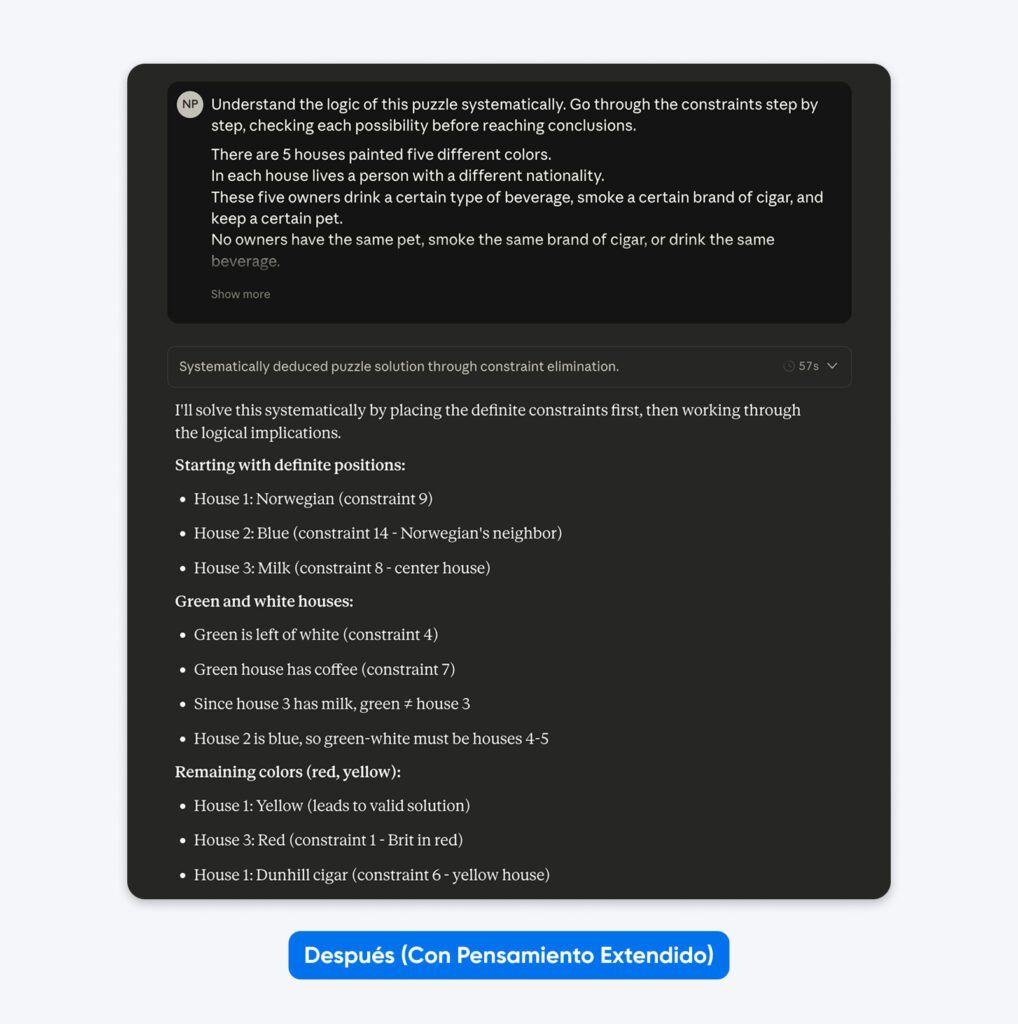
No notarás mucha diferencia con prompts simples como el ejemplo anterior. Pero en problemas complejos y de nicho (bases de código personalizadas, planificación lógica de varios pasos), la diferencia se vuelve evidente.
Cuándo funciona el pensamiento extendido:
- Planificación lógica de varios pasos que requiere verificación
- Razonamiento matemático con múltiples caminos de solución
- Tareas de programación complejas que abarcan varios archivos
- Situaciones donde la precisión importa más que la velocidad
Cuándo evitarlo: Iteraciones rápidas, consultas simples, escritura creativa, tareas sensibles al tiempo.
Calificación de efectividad: 10/10 para razonamiento complejo, 3/10 para consultas simples.
3. Sé Brutalmente Específico con los Requisitos
Los modelos Claude 4 han sido entrenados para seguir instrucciones con mayor precisión que las generaciones anteriores.
La documentación de Anthropic señala:
“Los modelos Claude 4.x responden bien a instrucciones claras y explícitas. Ser específico sobre el resultado deseado puede ayudar a mejorar los resultados. Los clientes que deseen el comportamiento de ‘ir más allá’ de versiones anteriores de Claude podrían necesitar solicitar estas acciones de forma más explícita en los modelos más nuevos.”
La documentación también indica que Claude es lo suficientemente inteligente como para generalizar a partir de la explicación cuando se proporciona el contexto de por qué existen ciertas reglas, en lugar de limitarse a dar órdenes. Esto significa que ofrecer una justificación ayuda al modelo a aplicar los principios correctamente en casos límite que no estén cubiertos de forma explícita.
Las pruebas realizadas por 16x Eval mostraron que tanto Opus 4 como Sonnet 4 obtuvieron una puntuación de 9,5/10 en tareas tipo TODO cuando las instrucciones especificaban claramente los requisitos, el formato y los criterios de éxito. Los modelos demostraron una concisión e interpretación de instrucciones impresionantes.
Antes (expectativas implícitas):
Crea un dashboard de analítica.

Notarás que esta salida es EXACTAMENTE lo que pedimos. Aunque Claude se tomó un poco de libertad creativa en la estética, no tiene ninguna funcionalidad.
Después (requisitos explícitos):
Crea un dashboard de analítica. Incluye la mayor cantidad posible de funciones e interacciones relevantes. Ve más allá de lo básico para crear una implementación completa con visualización de datos, capacidades de filtrado y funciones de exportación.

Esta segunda salida, con un prompt más descriptivo, incluye más funciones, un dashboard construido con datos ficticios, presentados tanto de forma gráfica como en formato tabular, y pestañas para separar toda la información.
Eso es lo que logra ser específico con la versión más reciente de Claude.
Para aclarar aún más este punto, aquí tienes otro ejemplo que muestra cómo el contexto mejora el seguimiento de instrucciones::
Antes (orden sin contexto):
NUNCA uses puntos suspensivos en tu respuesta.
Después (instrucción con contexto):
Tu respuesta será leída en voz alta por un motor de texto a voz, así que evita los puntos suspensivos, ya que el motor no sabrá cómo pronunciarlos.
Principios clave para dar instrucciones explícitas:
- Define qué significa “completo” para tu tarea específica: no asumas que Claude inferirá los estándares de calidad.
- Explica por qué existen las reglas en lugar de solo enunciarlas: Claude generaliza mejor a partir de instrucciones motivadas.
- Especifica explícitamente el formato de salida: pide “párrafos en prosa” en lugar de esperar que Claude no use viñetas.
- Proporciona criterios de éxito concretos: ¿cómo se ve una tarea completada?
Calificación de efectividad: 9/10 en todos los tipos de tareas.
4. Muestra Ejemplos de lo Que Quieres
El few-shot prompting proporciona a Claude ejemplos de entradas y salidas que demuestran el comportamiento deseado. Esto funciona, pero solo cuando los ejemplos son de alta calidad y adecuados para la tarea; su impacto varía considerablemente según el caso de uso.
La guía oficial de Anthropic enfatiza:
“Los modelos Claude 4.x prestan mucha atención a los detalles y a los ejemplos como parte de su seguimiento preciso de instrucciones. Asegúrate de que tus ejemplos estén alineados con los comportamientos que deseas fomentar y minimicen aquellos que quieres evitar.”
Anthropic recomienda entre 3 y 5 ejemplos diversos y relevantes para tareas complejas. Más ejemplos equivalen a un mejor rendimiento.
Aquí tienes un ejemplo de cómo se ve esto en la práctica:
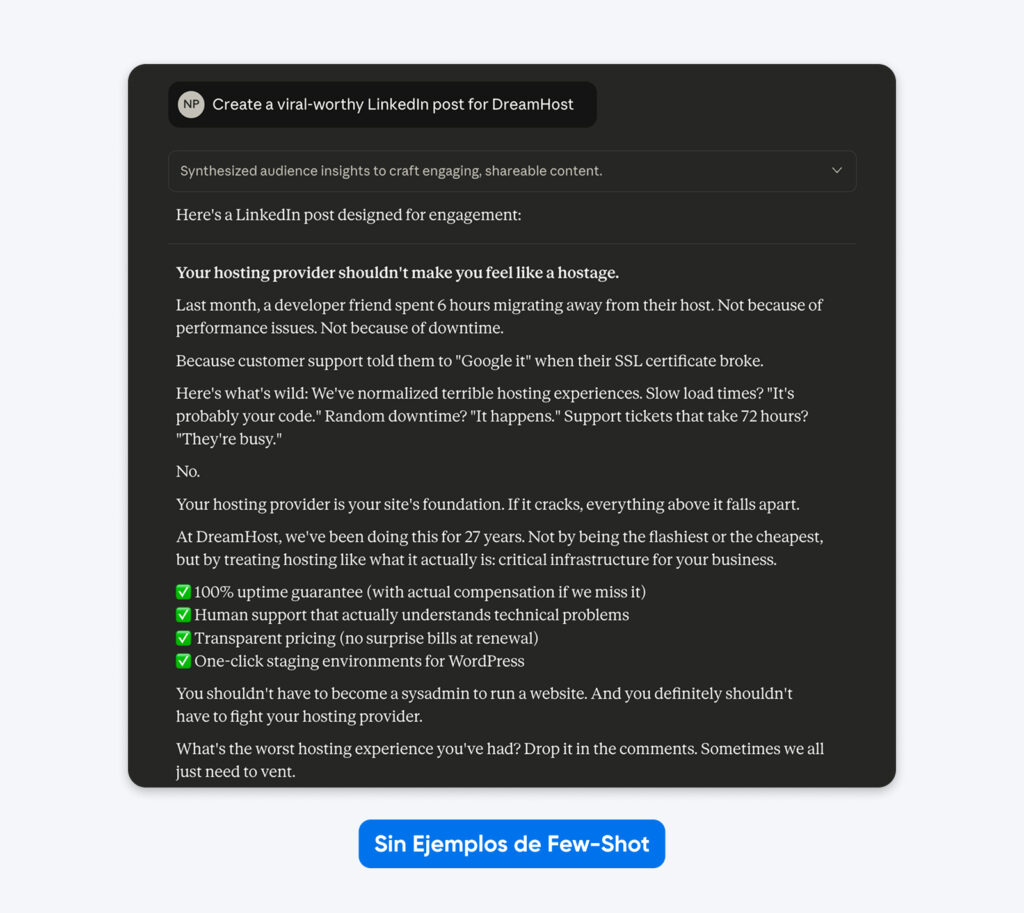
En este caso, Claude se tomó libertades creativas con el formato, el uso de emojis, el mensaje y el tono, recurriendo a un lenguaje corporativo genérico.
Agregar ejemplos funciona porque muestran en lugar de solo decir, y además aclaran requisitos sutiles que son difíciles de expresar únicamente mediante descripciones.
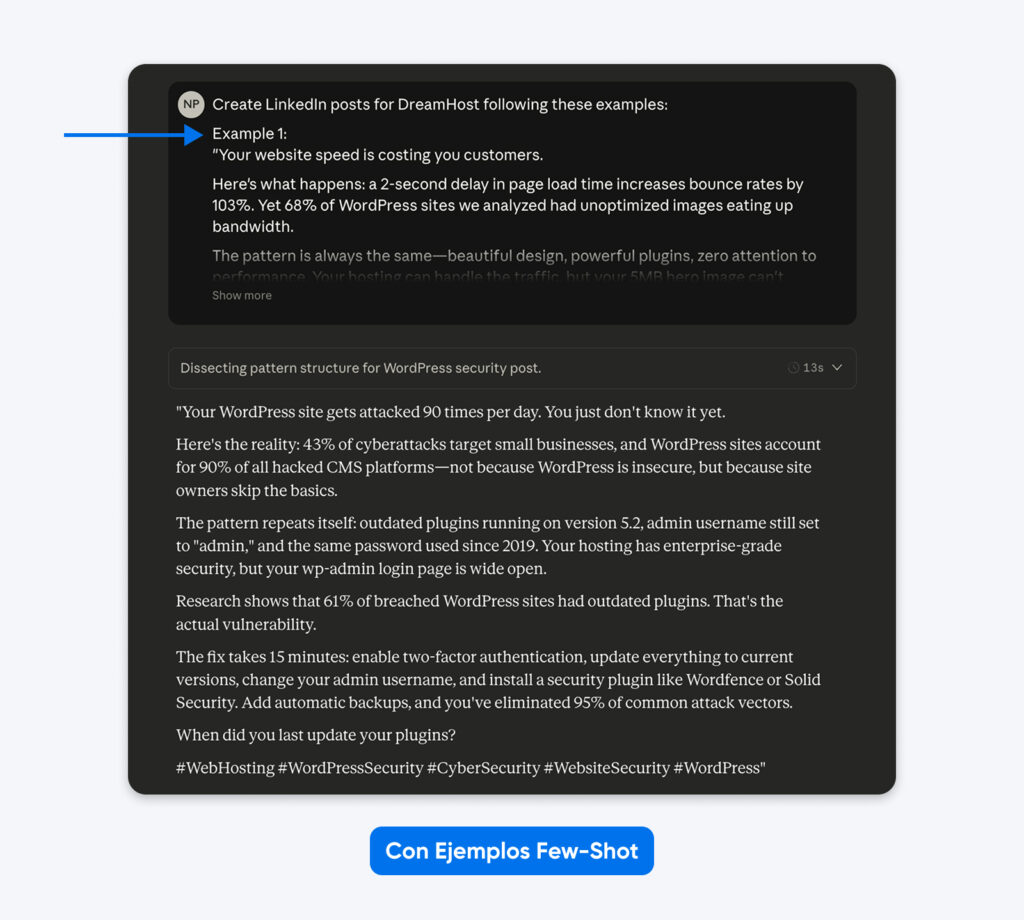
Esta salida se ajusta mucho más a los ejemplos que proporcioné en el prompt. Puedes usar el método de few-shot examples para obtener publicaciones de LinkedIn similares a las que mejor rendimiento han tenido. Un artículo académico sobre el diseño de Máquinas de Estados Finitos (FSM) mostró que los ejemplos estructurados alcanzaron una tasa de éxito del 90 %, frente a las instrucciones sin ejemplos.
Cómo implementarlo:
- Envuelve los ejemplos en etiquetas <example>, agrupadas dentro de etiquetas <examples>
- Coloca los ejemplos al inicio del primer mensaje del usuario
- Usa de 3 a 5 ejemplos diversos para tareas complejas
- Asegúrate de que cada detalle de los ejemplos coincida con el resultado deseado (Claude 4.x replica convenciones de nombres, estilo de código, formato y puntuación)
- Evita ejemplos redundantes
Cuándo funcionan mejor los ejemplos:
- Formateo de datos que requiere una estructura precisa
- Patrones de código complejos que necesitan enfoques específicos
- Tareas analíticas que demuestran métodos de razonamiento
- Resultados que requieren un estilo y convenciones consistentes
Cuándo evitarlos: Consultas simples donde las instrucciones son suficientes, o cuando quieres que Claude use su propio criterio.
Calificación de efectividad: 10/10 para tareas de formato, 6/10 para consultas simples.
5. Coloca el Contexto Antes de la Pregunta
Claude cuenta con una ventana de contexto de 200.000 tokens (hasta 1 millón en algunos casos) y puede entender consultas ubicadas en cualquier parte del contexto. Sin embargo, la documentación de Anthropic recomienda colocar documentos largos (20.000+ tokens) al inicio del prompt, antes de la pregunta.
Las pruebas demostraron que esto mejora la calidad de las respuestas hasta en un 30 % en comparación con el orden de “pregunta primero”, especialmente cuando se trabaja con entradas complejas y múltiples documentos.
¿La razón? Los mecanismos de atención de Claude asignan mayor peso al contenido que aparece al final del prompt. Al colocar la pregunta después del contexto, el modelo puede referenciar el material anterior mientras genera la respuesta.
Antes (pregunta primero):
Analiza el rendimiento financiero trimestral e identifica las tendencias clave.
[20.000 tokens de datos financieros]
Después (contexto primero):
[20.000 tokens de datos financieros]
Con base en los datos financieros trimestrales proporcionados arriba, analiza el rendimiento e identifica las tendencias clave en crecimiento de ingresos, expansión de márgenes y eficiencia operativa. Enfócate en insights accionables para la toma de decisiones ejecutivas.
Cuándo importa:Análisis de contexto largo donde Claude necesita referenciar extensamente el material previo.
Cuándo evitarlo: Prompts cortos de menos de 5.000 tokens.
Calificación de efectividad: 8/10 para tareas con contexto largo, 4/10 para prompts cortos.
Qué Técnicas de Prompting Ya No Funcionan: Desmontando Mitos Comunes
Los cambios en Claude 4.5 invalidaron varias técnicas populares que funcionaban con modelos anteriores.
1. Palabras de énfasis (MAYÚSCULAS, “DEBES”, “SIEMPRE”)
Escribir en mayúsculas ya no garantiza el cumplimiento. El análisis de Chris Tyson reveló que Claude ahora prioriza el contexto y la lógica por encima del énfasis.
Si escribes “NUNCA inventes datos” pero el contexto implica que necesitas una estimación, Claude 4.5 prioriza la necesidad lógica sobre la orden en mayúsculas.
Usa lógica condicional en su lugar:
- Mal: SIEMPRE usa números exactos
- Bien: Si hay datos verificados disponibles, usa cifras precisas. Si no, proporciona rangos y márcalos claramente como estimaciones.
2. Instrucciones manuales de cadena de pensamiento (chain-of-thought)
Decirle al modelo que “piense paso a paso” desperdicia tokens cuando se utiliza el modo de Pensamiento Extendido.
Cuando habilitas el Pensamiento Extendido, el modelo gestiona su propio presupuesto de razonamiento. Agregar instrucciones como “paso a paso” resulta redundante.
Qué hacer en su lugar:
Confía en la herramienta. Si habilitas el Pensamiento Extendido, elimina todas las instrucciones sobre cómo debe pensar el modelo.
3. Restricciones negativas (“No hagas X”)
Decirle a Claude exactamente lo que no debe hacer suele salir mal.
Las investigaciones sobre las instrucciones del tipo “elefante rosa” muestran que decirle a un modelo avanzado que no piense en algo aumenta la probabilidad de que se enfoque precisamente en eso.
El mecanismo de atención de Claude resalta el concepto prohibido, manteniéndolo activo dentro de la ventana de contexto.
En su lugar, reformula cada restricción negativa como una instrucción positiva:
- Mal: No escribas introducciones largas y rellenas. No uses palabras como “delve” o “tapestry”.
- Bien: Comienza directamente con el argumento central. Usa un lenguaje conciso y directo.
Cómo Migrar Prompts de Claude 3.5 a Claude 4
Si estás migrando de Claude 3.5 a 4.5, puedes actualizar tu biblioteca de prompts siguiendo cinco pasos sistemáticos validados por la experiencia de desarrolladores.
Usaremos un escenario común de hosting para este ejemplo. El objetivo es generar una respuesta de soporte técnico para un cliente que experimenta un error “503 Service Unavailable” en su sitio de WordPress.

1. Audita las Suposiciones Implícitas
Comienza identificando dónde el prompt depende de que el modelo adivine el contexto. En versiones anteriores, el modelo infería que estabas usando el stack de software más común. Claude 4.5 ya no hace ese salto.
Prompt heredado:
“Mi sitio web carga lentamente y muestra errores. Eres un administrador de servidores experto. Piensa paso a paso y dime cómo corregir la configuración para hacerlo más rápido.”
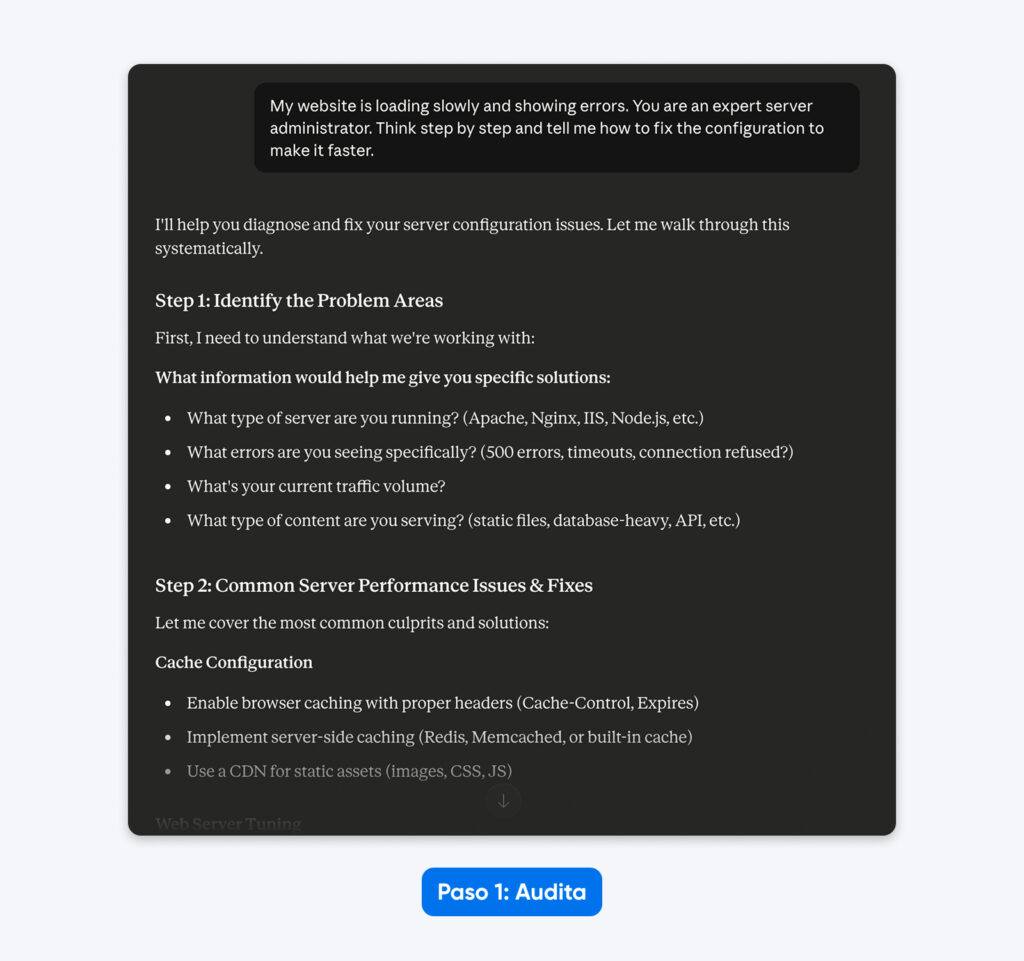
La auditoría:
- “Sitio web” implica una configuración genérica en lugar de un CMS específico (WordPress).
- “Lentamente” es subjetivo; podría referirse a un alto Time to First Byte o a una carga lenta de recursos.
- “Errores” no especifica los códigos de estado HTTP necesarios para un diagnóstico.
- “Administrador de servidores experto” y “piensa paso a paso” son instrucciones de dirección innecesarias.
En la respuesta, Claude 4.5 solicita más información, ya que está entrenado para evitar hacer suposiciones.
2. Refactoriza Para una Especificidad Explícita
Ahora, reescribe el prompt para definir el entorno, el problema específico y el formato de salida deseado. Debes proporcionar los detalles técnicos que antes el modelo asumía.
Prompt refactorizado:
“Mi sitio de WordPress que funciona sobre Nginx y Ubuntu 20.04 está experimentando un alto Time to First Byte (TTFB) y errores ocasionales 502 Bad Gateway. Eres un administrador de servidores experto. Piensa paso a paso y proporciona cambios específicos de configuración en Nginx y PHP-FPM para resolver estos timeouts.”
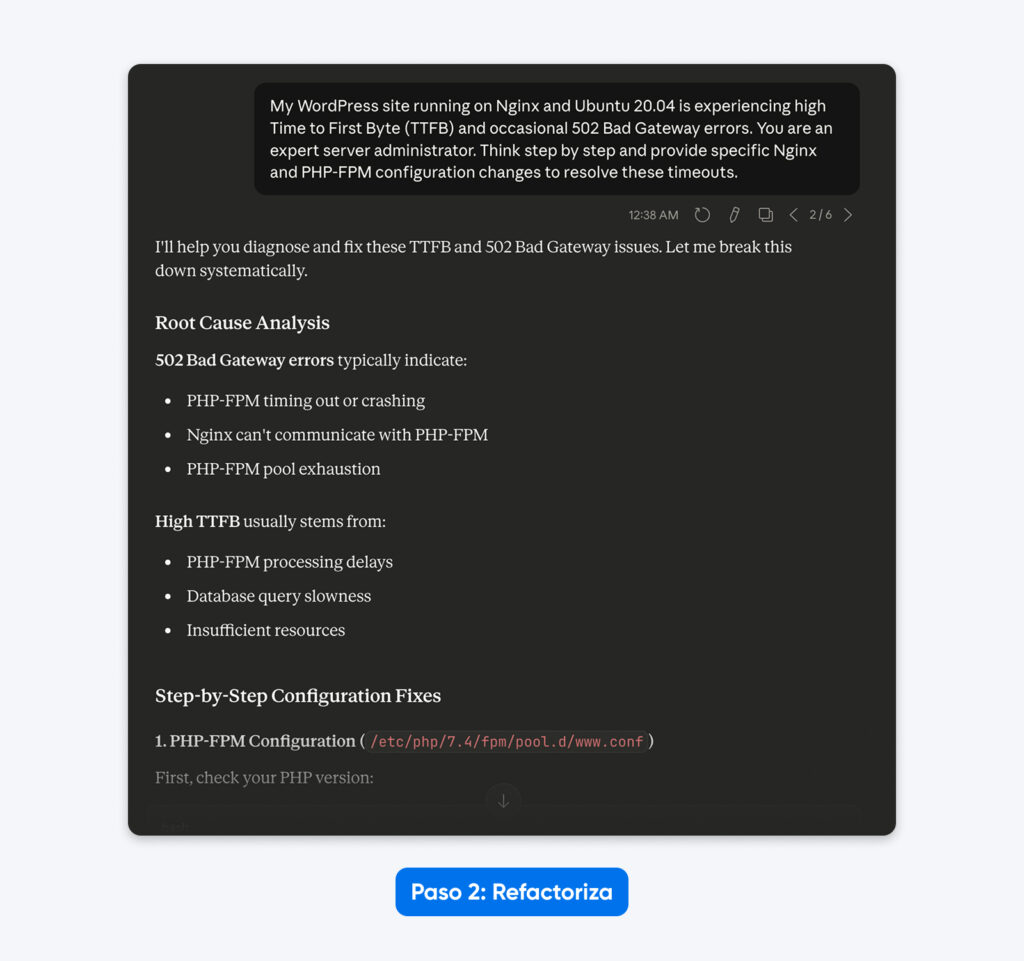
El resultado: El prompt ahora especifica el stack de software exacto (Nginx, Ubuntu, WordPress) y el error concreto (502 Bad Gateway), lo que reduce la probabilidad de recibir recomendaciones irrelevantes sobre Apache o IIS. Claude responde con un análisis y una solución paso a paso.
3. Implementa lógica condicional
Claude 4.5 sobresale cuando se le proporciona un árbol de decisiones. En lugar de pedir una única solución estática, instruye al modelo para que maneje distintos escenarios según los datos que analice.
Prompt con lógica:
“Mi sitio de WordPress que funciona sobre Nginx y Ubuntu 20.04 está experimentando un alto TTFB y errores 502 Bad Gateway. Eres un administrador de servidores experto. Piensa paso a paso.
Si los logs de error muestran ‘upstream sent too big header’, proporciona cambios de configuración para los tamaños de buffer.
Si los logs de error muestran ‘upstream timed out’, proporciona cambios de configuración para los límites de tiempo de ejecución.”
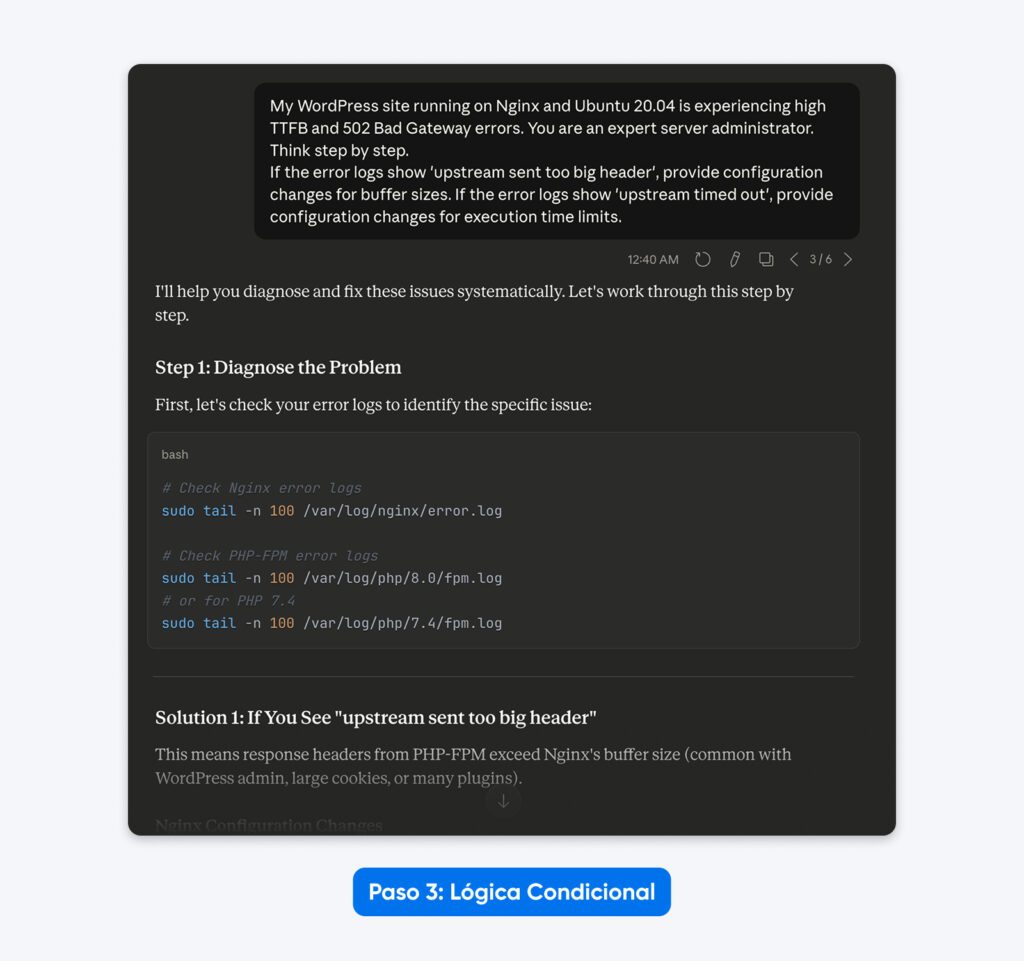
El resultado: La salida se vuelve dinámica. El modelo ofrece soluciones específicas según la lógica de causa raíz que definiste, en lugar de una lista genérica de correcciones.
4. Elimina el Lenguaje de Dirección Obsoleto
Los prompts heredados suelen contener instrucciones de “cómo pensar” que los usuarios creían que mejoraban el rendimiento. Estas ya no son necesarias ni útiles con Claude 4.5, ya que cuenta con pensamiento extendido.
Prompt depurado:
“Mi sitio de WordPress que funciona sobre Nginx y Ubuntu 20.04 está experimentando un alto TTFB y errores 502 Bad Gateway.
Si los logs de error muestran ‘upstream sent too big header’, proporciona cambios de configuración para los tamaños de buffer.
Si los logs de error muestran ‘upstream timed out’, proporciona cambios de configuración para los límites de tiempo de ejecución.”
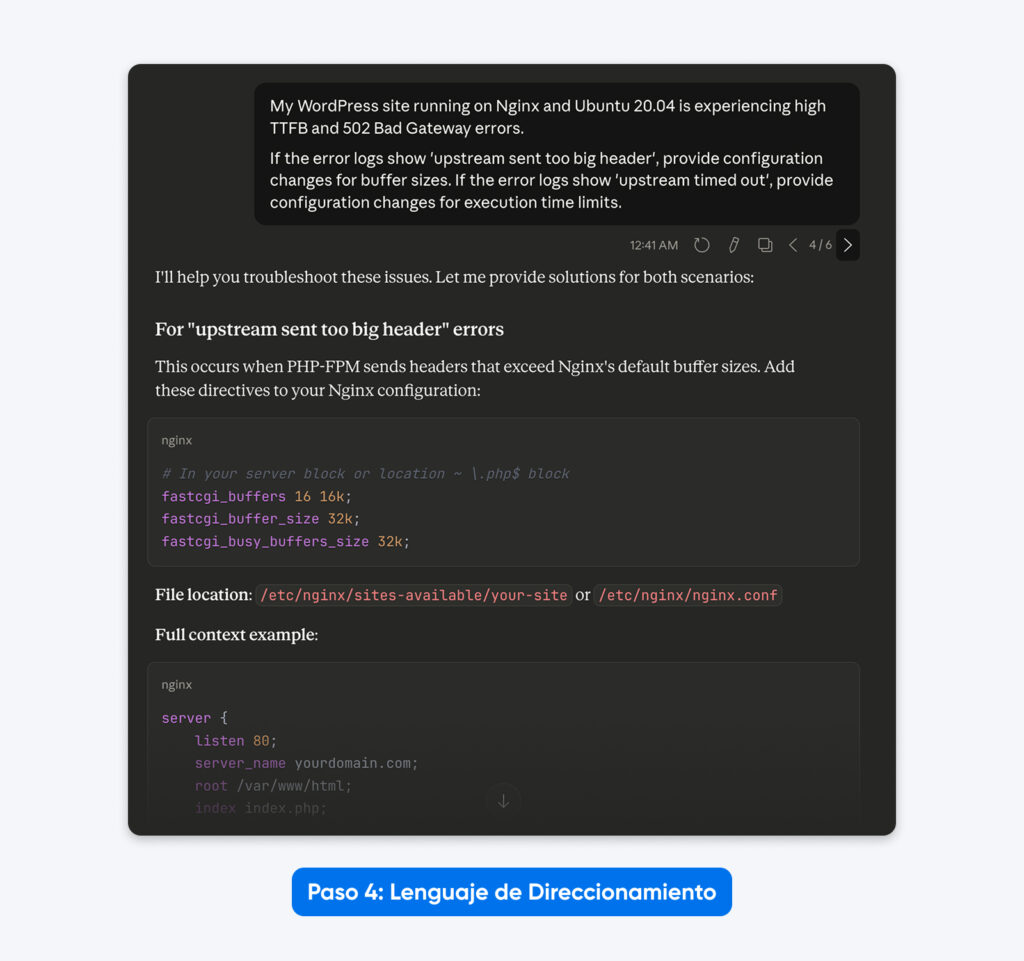
El resultado: Un prompt más limpio que se centra únicamente en la tarea técnica, eliminando distracciones como “Eres un experto” o “Piensa paso a paso”.
5. Prueba de Forma Sistemática
Agrupa los componentes en un formato estructurado usando XML o encabezados claros. Esto coincide con los datos de entrenamiento del modelo y produce los resultados más consistentes.
| ROL: Administrador de sistemas Linux especializado en rendimiento de Nginx y WordPress. TAREA: Resolver errores 502 Bad Gateway y reducir el Time to First Byte (TTFB) de un sitio WordPress en Ubuntu 20.04. LÓGICA: – Si los logs muestran ‘upstream sent too big header’, incrementar fastcgi_buffer_size y fastcgi_buffers. – Si los logs muestran ‘upstream timed out’, incrementar fastcgi_read_timeout en nginx.conf y request_terminate_timeout en www.conf. REQUISITOS de RESULTADO: -Proporcionar las líneas exactas de configuración que deben modificarse.-Explicar el impacto de cada cambio en la memoria del servidor. |
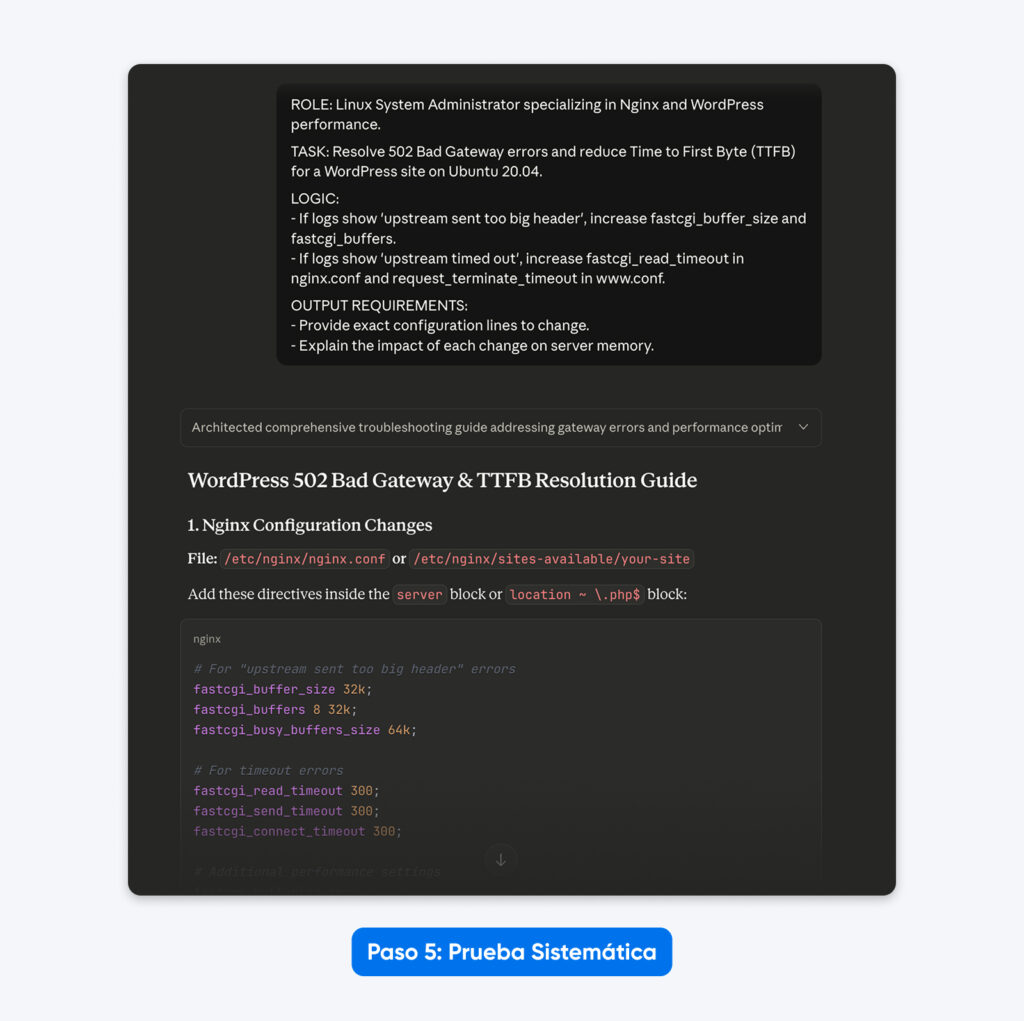
El resultado: La respuesta fue más estructurada, me permitió resolver el problema con datos de configuración listos para copiar y pegar, tal como se solicitó, y explicó mejor la solución.
Qué Significa Esto Para tu Flujo de Trabajo
Los modelos Claude 4.x funcionan de manera diferente a los modelos anteriores. Siguen tus instrucciones al pie de la letra en lugar de asumir lo que querías decir, lo cual es clave cuando necesitas resultados consistentes. El esfuerzo que inviertas en prompt engineering al inicio se verá recompensado si ejecutas la misma tarea de forma recurrente.
Cada técnica de esta guía fue seleccionada cuidadosamente porque se alinea estrechamente con la forma en que se construyó Claude 4.x. Las etiquetas XML, el modo de Pensamiento Extendido, las instrucciones explícitas, los ejemplos few-shot y el enfoque de contexto primero funcionan porque, según las guías de prompting de Claude y la evidencia anecdótica, así es como Anthropic probablemente entrenó los modelos.
Así que adelante: elige una o dos técnicas de esta guía y pruébalas en tus flujos de trabajo reales. Mide qué cambia y qué métodos juegan a tu favor. El mejor enfoque es aquel respaldado por datos reales de tus procesos diarios.

