
Quando o Claude Sonnet 4.5 foi lançado em Setembro de 2025, ele quebrou muitos dos prompts existentes. Não porque o lançamento estava com defeitos. Mas porque a Anthropic reconstruiu como o Claude segue instruções.
Versões anteriores inferiam sua intenção e expandiam solicitações vagas. Claude 4.x leva você ao pé da letra e faz exatamente o que você pede, nada mais.

Para entender os novos métodos, avaliamos 25 técnicas populares de engenharia de prompts contra os documentos da Anthropic, experimentos da comunidade e implantações reais para descobrir quais prompts realmente funcionam melhor com Claude 4.x. Essas cinco técnicas
O Que Mudou no Claude 4.5 Que Comprometeu Prompts Existentes?
Modelos Claude 4.5 priorizam instruções precisas em vez de “adivinhações” úteis.
As versões anteriores preenchiam os espaços para você. Se você pedisse um “Painel de controle,” eles assumiam que você queria gráficos, filtros e tabelas de dados.
Claude 4.5 leva você ao pé da letra. Se você pedir um painel de controle, ele pode te dar uma moldura vazia com um título porque você não pediu o resto.
Anthropic declara claramente: “Os clientes que desejam o comportamento ‘além do esperado’ podem precisar solicitar explicitamente esses comportamentos.”
Então, precisamos parar de tratar o modelo como uma varinha mágica e começar a tratá-lo como um funcionário ao pé da letra.
Sem habilidades de design. Sem construtores. Sem complicações. Apenas resultados.
Começar Agora
As 5 Técnicas Comprovadas Que Melhoram Significativamente o Desempenho do Claude
Baseado em nossa pesquisa, estas cinco técnicas entregaram consistentemente melhorias notáveis no desempenho de Claude para as tarefas que lhe atribuímos.
1. Prompts Estruturados e Rotulados
O prompt de sistema do Claude Sonnet 4.5 utiliza prompts estruturados em todos os lugares. Simon Willison investigou os prompts do sistema e encontrou seções envolvidas em tags como <behavior_instructions>, <artifacts_info> e <knowledge_cutoff>.
Na verdade, você poderia editar “Styles” para ver a estrutura de prompts da Anthropic em ação.
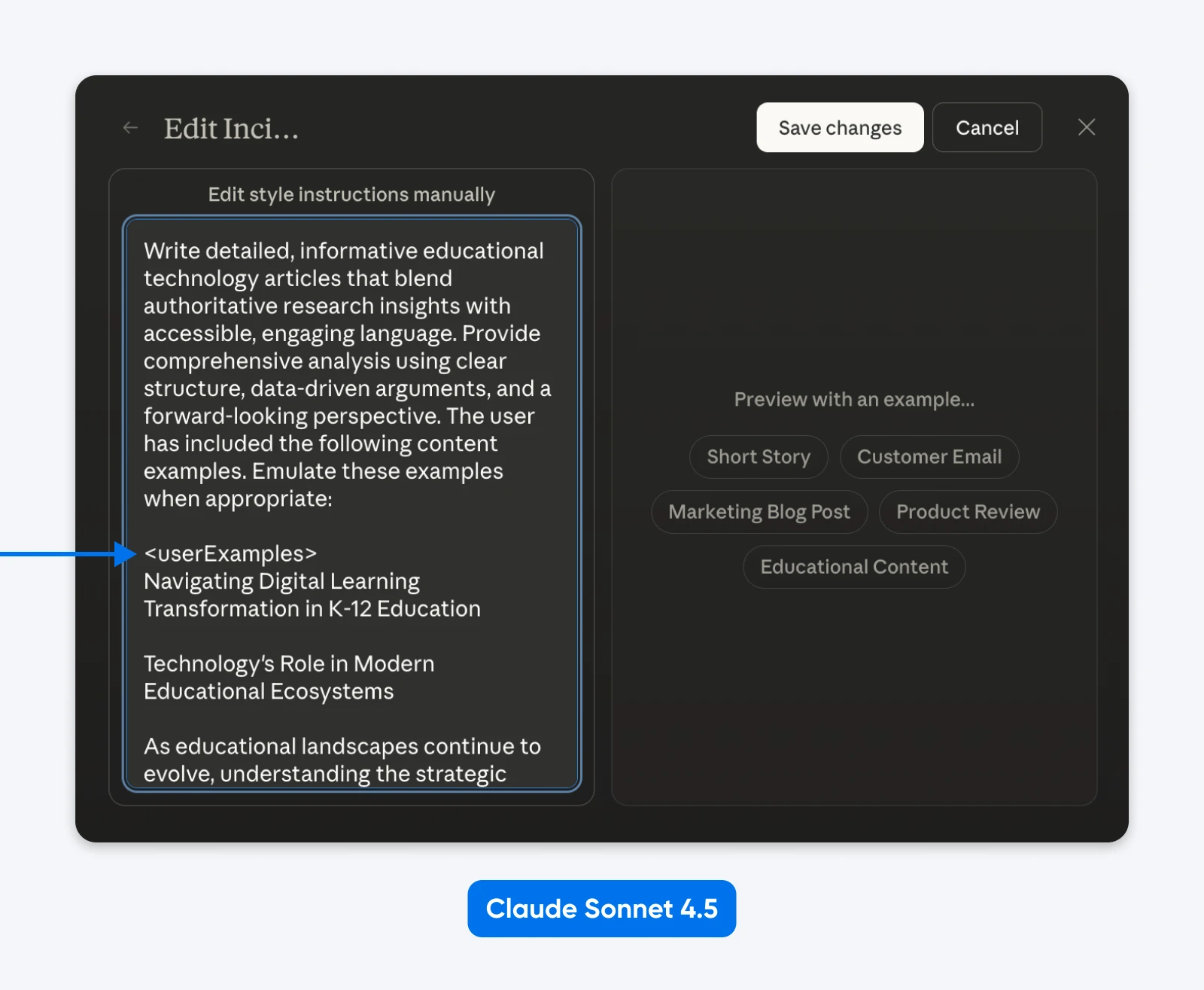
O que podemos inferir é que Claude foi treinado em prompts estruturados e sabe como interpretá-los. XML funciona muito bem, assim como JSON ou outros prompts rotulados.
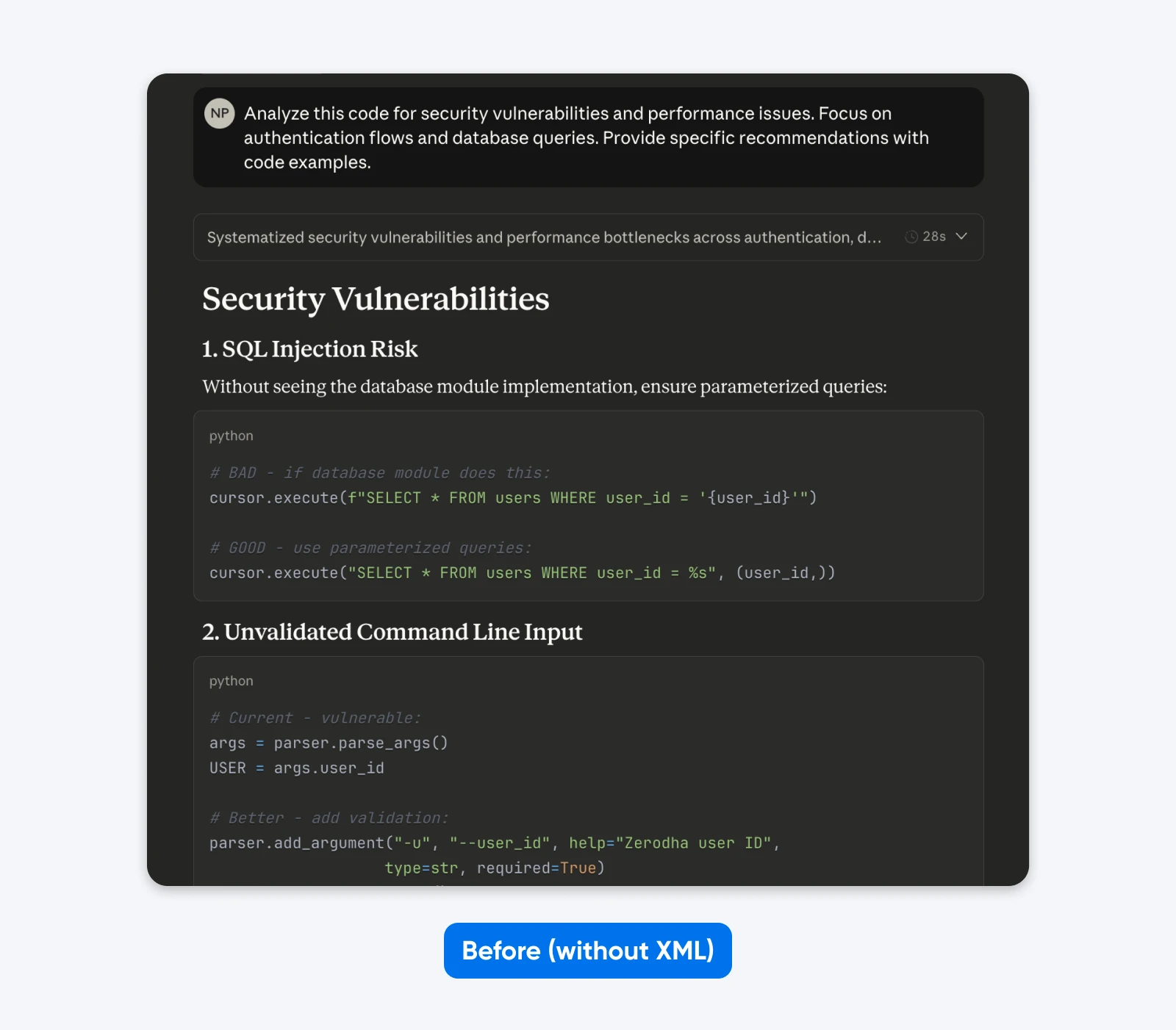
Antes:
Analisar este código para vulnerabilidades de segurança e problemas de desempenho. Concentre-se nos fluxos de autenticação e nas consultas ao banco de dados. Forneça recomendações específicas com exemplos de código.
Após (prompt estruturado):
<task>Analise o código fornecido para questões de segurança e desempenho</task>
<focus_areas>
– Fluxos de autenticação
– Otimização de consultas de banco de dados
</focus_areas>
<code>
[seu código aqui]
</code>
<output_requirements>
– Identificar vulnerabilidades específicas com classificações de gravidade
– Fornecer exemplos de código corrigidos
– Priorizar recomendações pelo impacto nos negócios
</output_requirements>
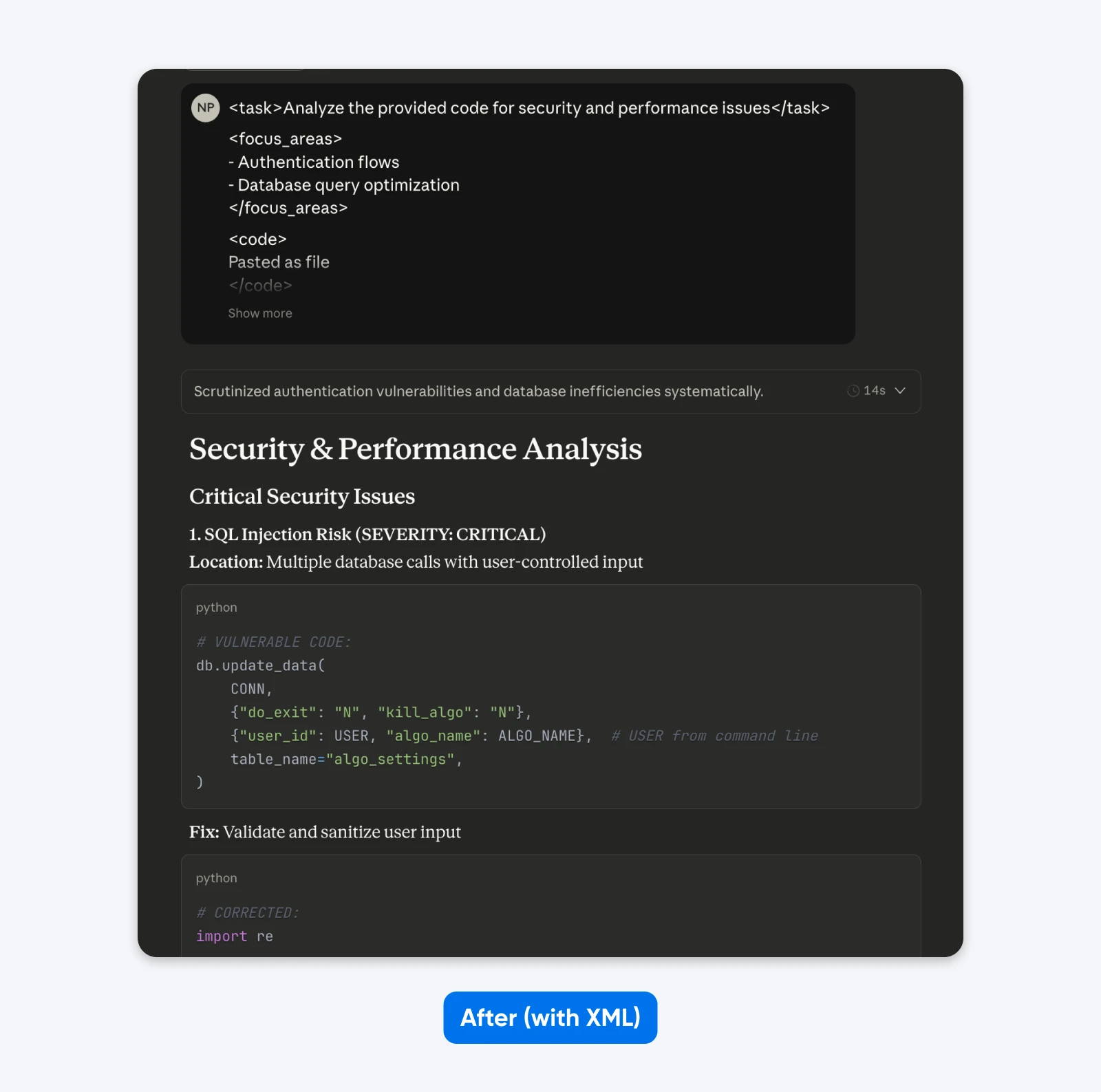
Se comparares estas saídas, notarás que a solicitação estruturada fornece uma saída com mais contexto para te ajudar a entender e resolver os problemas de segurança no código. Ela explica o problema, indica o que a correção faz e, em seguida, fornece a correção do código.
Formatos Alternativos Que Funcionam:
JSON:
{
"task": "Revisar código de autenticação",
"focus_areas": ["Hash de senha", "Segurança de sessão", "Injeção de SQL"],
"context": "Aplicativo de saúde, HIPAA necessário",
"output_format": "Risco, impacto, correção, severidade por vulnerabilidade"
}
Cabeçalhos Claros:
TAREFA: Revisar o código de autenticação para vulnerabilidades
FOCO: Hash de senha, sessões, injeção SQL
CONTEXTO: Aplicativo de saúde que requer conformidade com HIPAA
FORMATO DE SAÍDA: Risco → Impacto HIPAA → Correção → Severidade
Todos os três funcionam igualmente bem.
Quando os prompts estruturados funcionam melhor:
- Vários componentes de prompt (tarefa, contexto, exemplos, requisitos)
- Entradas longas (mais de 10.000 tokens de código ou documentos)
- Fluxos de trabalho sequenciais com etapas distintas
- Tarefas que requerem referência repetida a seções específicas
Quando ignorar os prompts estruturados: Perguntas simples onde o texto plano funciona bem.
Avaliação de Eficiência: 9/10 para tarefas complexas, 5/10 para consultas simples.
2. Pensamento Ampliado para Problemas Complexos
O Pensamento Estendido oferece melhorias significativas em tarefas de raciocínio complexo com um grande compromisso: a velocidade.
Anúncio do Claude 4 da Anthropic mostrou ganhos de desempenho substanciais com o pensamento estendido ativado. Na competição de matemática AIME 2025, as pontuações melhoraram significativamente.
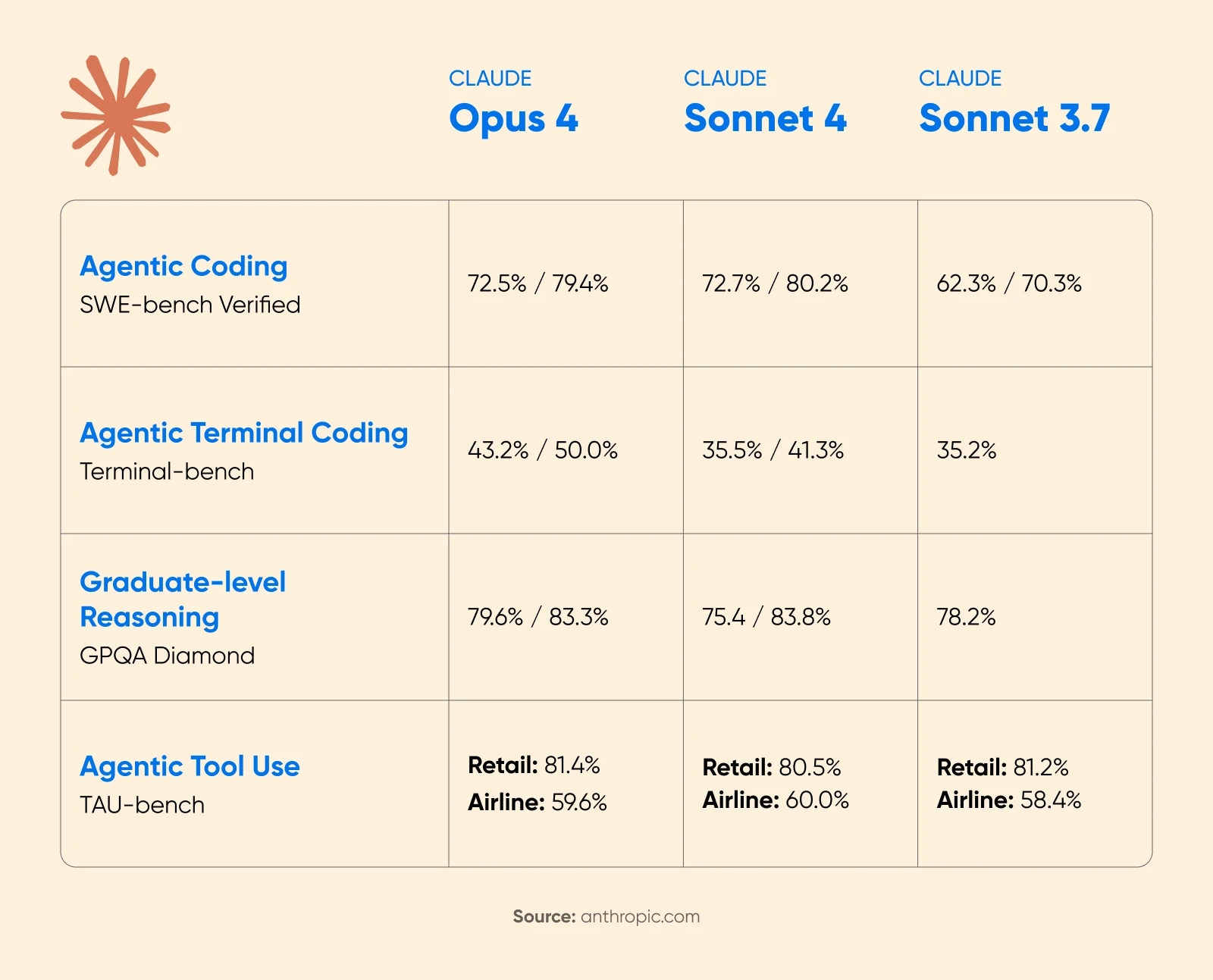
A Cognition AI relatou um aumento de 18% no desempenho de planejamento com o Sonnet 4.5, chamando-o de “o maior salto que vimos desde o Claude Sonnet 3.6.”
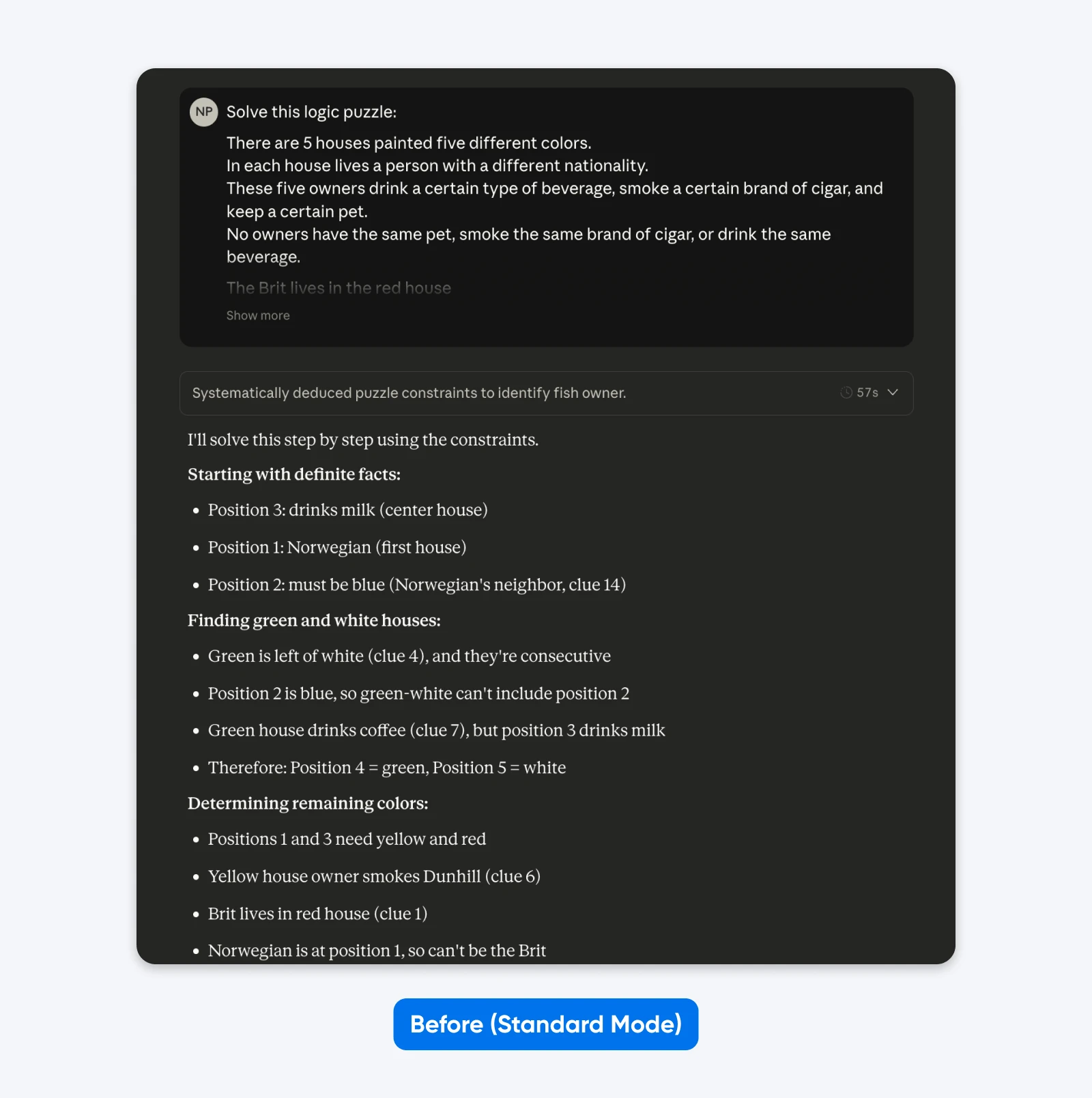
Antes (Modo Padrão):
Resolva este quebra-cabeça lógico: Cinco casas em uma fileira, cada uma de uma cor diferente…
Depois (Com Raciocínio Estendido):
Entenda a lógica deste quebra-cabeça de forma sistemática. Percorra as restrições passo a passo, verificando cada possibilidade antes de chegar a conclusões.
Cinco casas em uma fila, cada uma de uma cor diferente…
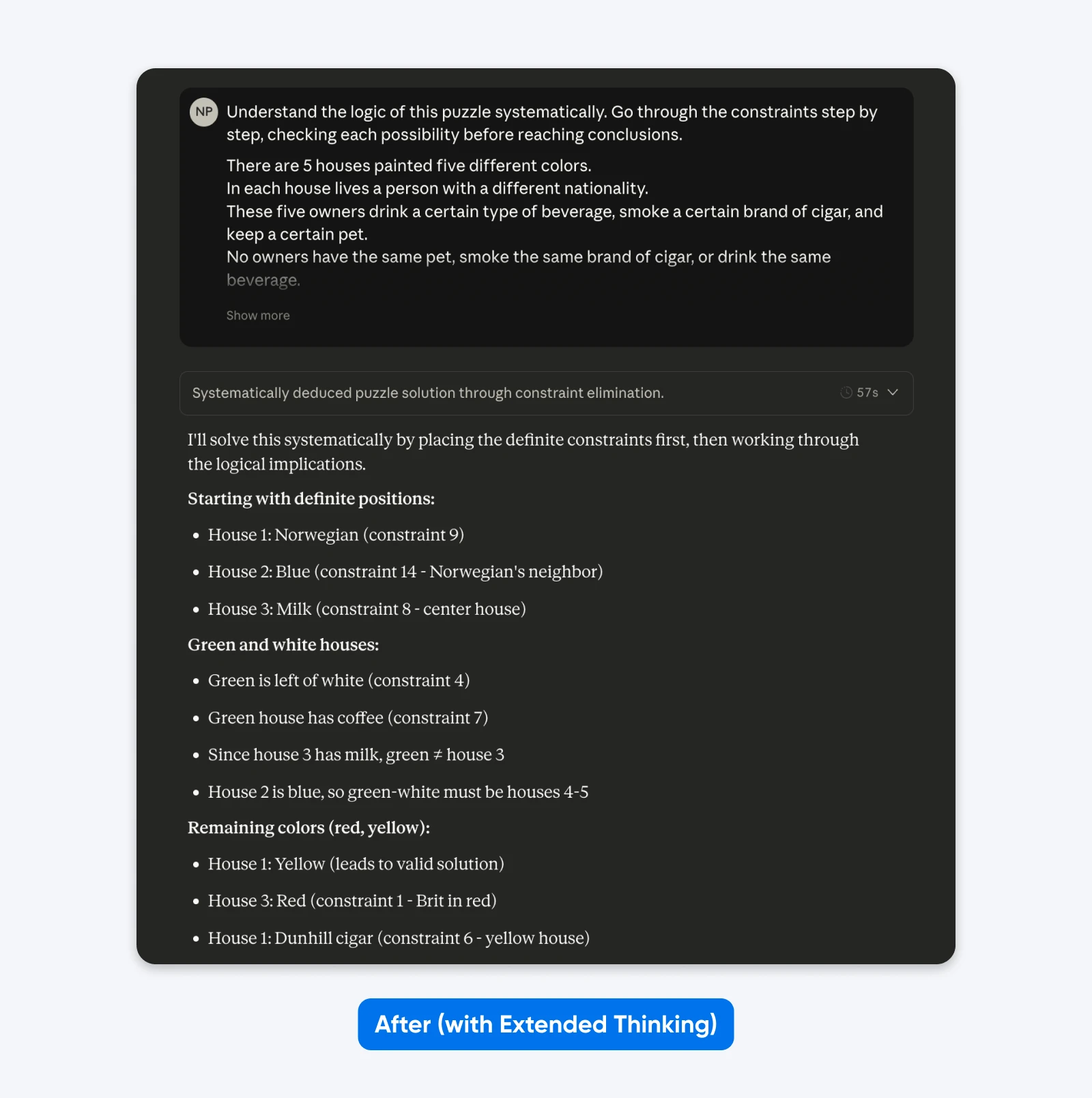
Você não verá muita diferença com prompts simples como o acima. Mas para problemas complexos e específicos (bases de código personalizadas, planejamento lógico de múltiplas etapas), a diferença se torna clara.
Quando a coisa estendida funciona:
- Planejamento lógico em várias etapas que requer verificação
- Raciocínio matemático com múltiplos caminhos de solução
- Tarefas complexas de programação envolvendo múltiplos arquivos
- Situações onde a correção é mais importante que a velocidade
Quando Pular: Iterações rápidas, consultas simples, escrita criativa, tarefas sensíveis ao tempo
Classificação de Efetividade: 10/10 para raciocínio complexo, 3/10 para consultas simples.
3. Seja Brutalmente Específico Sobre os Requisitos
Os modelos Claude 4 foram treinados para seguir instruções com mais precisão do que as gerações anteriores.
A documentação da Anthropic diz:
“Os modelos Claude 4.x respondem bem a instruções claras e explícitas. Ser específico sobre o resultado desejado pode ajudar a melhorar os resultados. Os clientes que desejam comportamentos ‘além do esperado’ dos modelos anteriores de Claude podem precisar solicitar esses comportamentos de forma mais explícita nos modelos mais recentes.”
A documentação também observa que Claude é inteligente o suficiente para generalizar a partir da explicação quando você fornece o contexto de por que as regras existem, em vez de apenas declarar comandos. Isso significa que fornecer uma justificativa ajuda o modelo a aplicar princípios corretamente em casos de borda não explicitamente abordados.
Os testes realizados pela 16x Eval mostraram que tanto o Opus 4 quanto o Sonnet 4 alcançaram 9,5/10 em tarefas TODO quando as instruções especificavam claramente os requisitos, o formato e os critérios de sucesso. Os modelos demonstraram impressionante concisão e capacidade de seguir instruções.
Antes (expectativas implícitas):
Criar um painel de controle de análise.
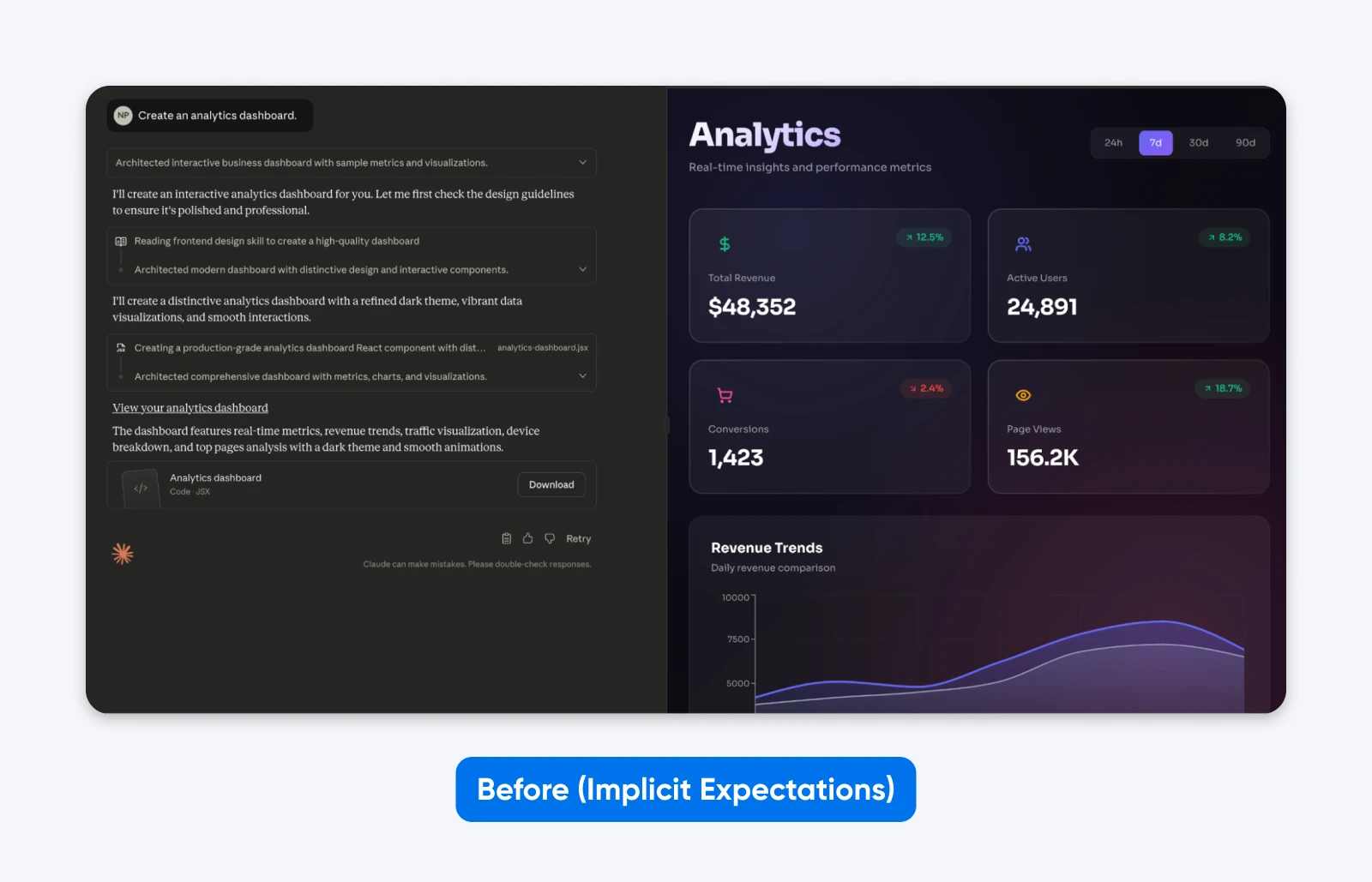
Você notará que este resultado é EXATAMENTE o que pedimos. Embora Claude tenha tomado um pouco de liberdade criativa na estética, isso não tem funcionalidade.
Após (requisitos explícitos):
Crie um painel de controle de análise. Inclua o máximo de funcionalidades e interações relevantes possível. Vá além do básico para criar uma implementação completa com visualização de dados, capacidades de filtragem e funções de exportação.
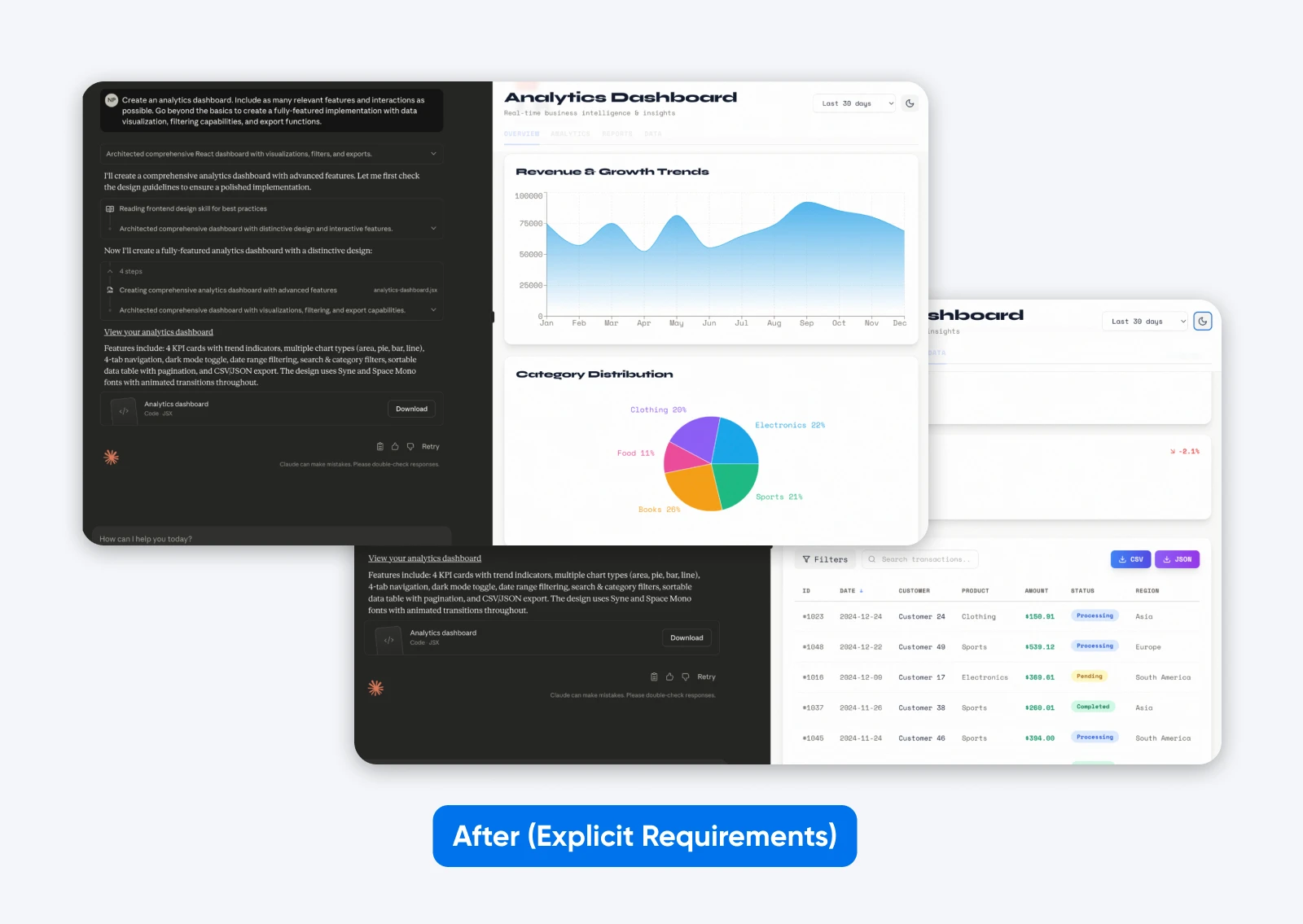
Esta segunda saída com um prompt mais descritivo possui mais funcionalidades, um painel de controle baseado em alguns dados fictícios, que são apresentados tanto graficamente quanto em formato tabular, e possui abas para separar todos os dados.
É isso que ser específico faz com o mais recente Claude.
Para esclarecer ainda mais esse ponto, aqui está outro exemplo mostrando como o contexto melhora a execução de instruções:
Antes (comando sem contexto):
NUNCA use reticências na sua resposta.
Após (instrução motivada por contexto):
Sua resposta será lida em voz alta por um motor de texto para fala, então evite reticências, pois o motor não saberá como pronunciá-las.
Princípios chave para instruções explícitas:
- Defina o que “abrangente” significa para a sua tarefa específica: Não assuma que Claude inferirá padrões de qualidade.
- Explique por que as regras existem em vez de apenas declará-las: Claude generaliza melhor a partir de instruções motivadas.
- Especifique explicitamente o formato de saída: Solicite “parágrafos em prosa” em vez de esperar que Claude não use pontos como padrão.
- Forneça critérios concretos de sucesso: Como a conclusão da tarefa se parece?
Classificação de Eficácia: 9/10 em todos os tipos de tarefas.
4. Mostre Exemplos do Que Você Quer
O prompting de poucos exemplos fornece ao Claude entradas e saídas de exemplo demonstrando o comportamento desejado. Isso funciona, mas apenas quando os exemplos são de alta qualidade e apropriados para a tarefa, e o impacto varia drasticamente conforme o caso de uso.
O guia oficial da Anthropic enfatiza:
“Os modelos Claude 4.x prestam muita atenção aos detalhes e exemplos como parte de sua instrução precisa. Garanta que seus exemplos estejam alinhados com comportamentos que você deseja incentivar e minimizem comportamentos que você deseja evitar.”
A Anthropic recomenda 3-5 exemplos diversos e relevantes para tarefas complexas. Mais exemplos equivale a melhor desempenho.
Aqui está um exemplo de como isso funciona na prática:
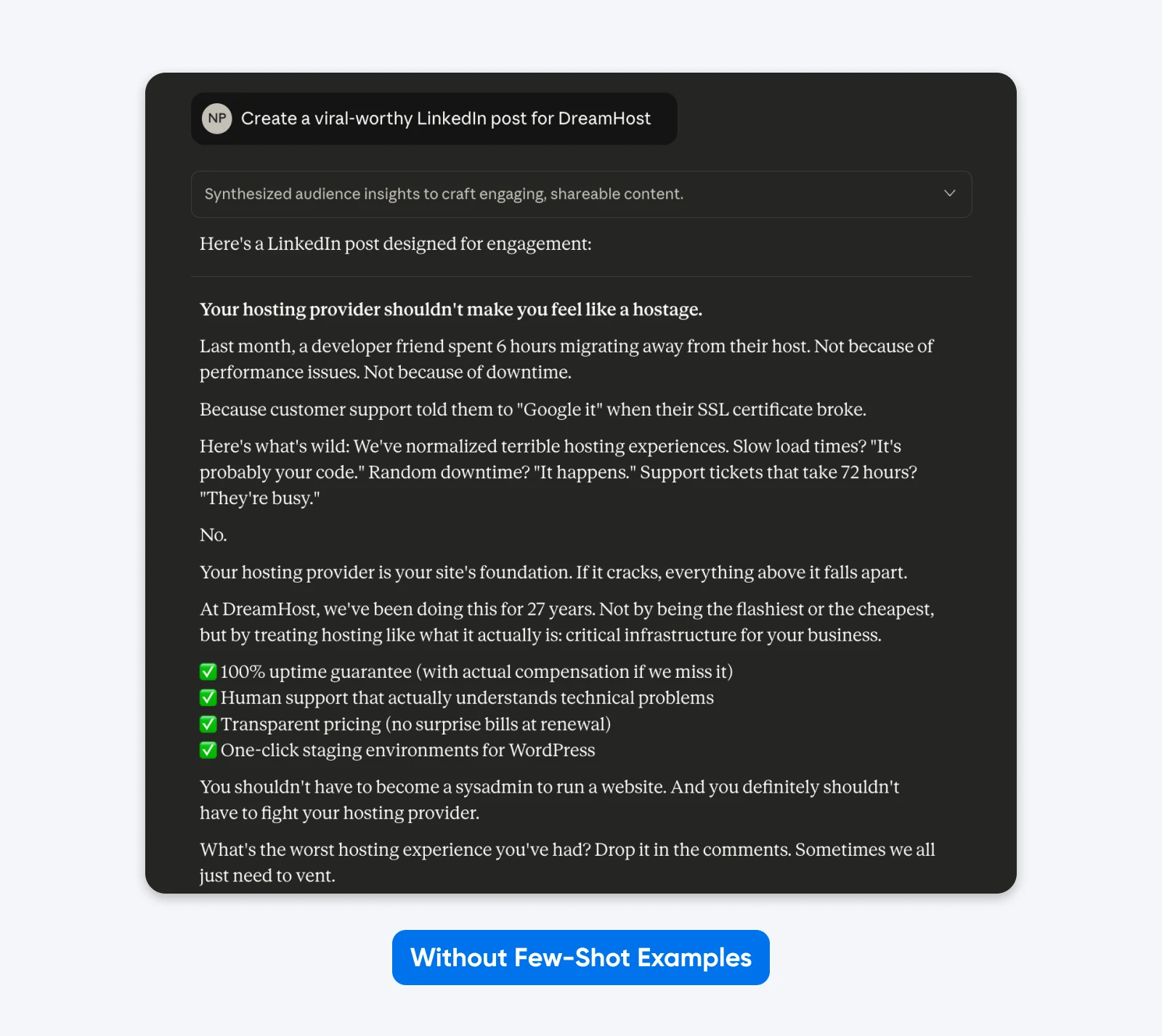
Aqui, Claude usou a liberdade criativa com o formato, uso de emojis, mensagens e tom. Linguagem corporativa genérica
Adicionar exemplos funciona porque eles mostram em vez de apenas contar, enquanto esclarecem os requisitos sutis que são difíceis de expressar apenas por meio de descrições.
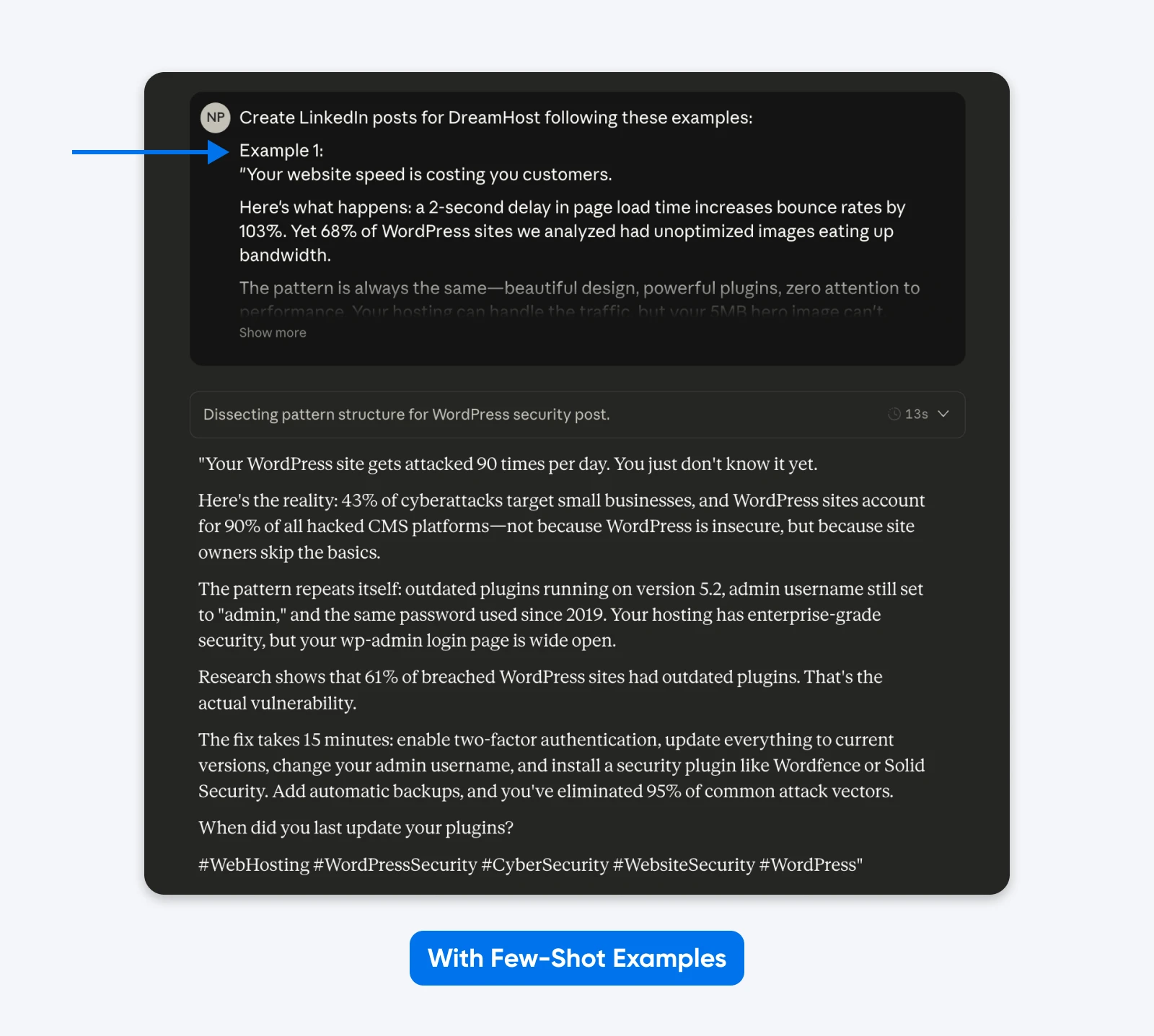
Esta saída adere mais de perto aos exemplos que forneci no prompt. Você pode usar o método de exemplos de poucos tiros para obter publicações no LinkedIn como as suas mais bem-sucedidas. Um artigo acadêmico sobre Projeto de Máquina de Estados Finitos (FSM) mostrou que exemplos estruturados alcançaram uma taxa de sucesso de 90% em comparação com instruções sem exemplos.
Como Implementar:
- Envolver exemplos em tags <example>, agrupados em tags <examples>
- Colocar exemplos no início da primeira mensagem do usuário
- Usar 3-5 exemplos diversos para tarefas complexas
- Combinar todos os detalhes nos exemplos com o resultado desejado (Claude 4.x replica convenções de nomenclatura, estilo de código, formatação, pontuação)
- Evitar exemplos redundantes
Quando os Exemplos Funcionam Melhor:
- Formatação de dados que requer estrutura precisa
- Padrões de codificação complexos que necessitam de abordagens específicas
- Tarefas analíticas demonstrando métodos de raciocínio
- Saída exigindo estilo e convenções consistentes
Quando Pular: Consultas simples onde instruções são suficientes, ou quando deseja que Claude use seu próprio julgamento.
Classificação de eficácia: 10/10 para tarefas de formatação, 6/10 para consultas simples.
5. Coloque Contexto Antes da Sua Pergunta
Claude possui uma janela de contexto de 200.000 tokens (chegando a 1 milhão em alguns casos) e pode compreender consultas colocadas em qualquer lugar do contexto. No entanto, a documentação da Anthropic recomenda colocar documentos longos (mais de 20.000 tokens) no topo dos prompts, antes das consultas.
Os testes mostraram que isso melhora a qualidade da resposta em até 30% em comparação com a ordenação inicial por consulta, especialmente com entradas complexas e multi-documentos.
Por que? Os mecanismos de atenção do Claude dão mais peso ao conteúdo no final dos prompts. Colocar a pergunta após o contexto permite que o modelo referencie material anterior ao gerar respostas.
Antes (Consulta Primeiro):
Analisar o desempenho financeiro trimestral e identificar as principais tendências.
[20.000 tokens de dados financeiros]
Após (contexto primeiro):
[20,000 tokens de dados financeiros]
Com base nos dados financeiros trimestrais fornecidos acima, analise o desempenho e identifique as principais tendências no crescimento da receita, expansão da margem e eficiência operacional. Foque em insights práticos para a tomada de decisão executiva.
Quando Isso Importa: Análise de longo contexto onde Claude precisa referenciar material anterior extensivamente.
Quando Pular: Comandos curtos com menos de 5.000 tokens.
Classificação de eficácia: 8/10 para tarefas de longo contexto, 4/10 para solicitações curtas.
Técnicas de Instrução que Não Funcionam Mais: Desmascarando Mitos Comuns
As alterações no Claude 4.5 invalidaram várias técnicas populares que funcionavam com modelos anteriores.
1. Palavras de Ênfase (TODAS EM MAIÚSCULAS, “OBRIGATÓRIO”, “SEMPRE”)
Escrever em letras maiúsculas não garante mais conformidade. A análise de Chris Tyson descobriu que Claude agora prioriza contexto e lógica em vez de ênfase.
Se você escrever “NUNCA fabrique dados”, mas o contexto sugerir que você precisa de uma estimativa, Claude 4.5 prioriza a necessidade lógica em detrimento do seu comando em maiúsculas.
Utilize lógica condicional em vez disso:
- Bad: SEMPRE use números exatos!
- Good: Se dados verificados estiverem disponíveis, use números precisos. Caso contrário, forneça intervalos e marque-os como estimativas.
2. Instruções Manuais do Encadeamento de Pensamento
Dizer ao modelo para “pensar passo a passo” desperdiça tokens quando se usa o modo de Pensamento Estendido.
Quando você ativa o Pensamento Estendido, o modelo gerencia seu próprio orçamento de raciocínio. Adicionar suas próprias instruções “passo a passo” é redundante.
O Que Fazer Em Vez Disso:
Confie na ferramenta. Se você ativar o Pensamento Estendido, remova todas as instruções sobre como pensar.
3. Restrições Negativas (“Não Faça X”)
Dizer exatamente ao Claude o que não fazer muitas vezes dá errado.
Pesquisa sobre instruções “Pink Elephant” mostra que dizer a um modelo avançado para não pensar em algo aumenta a probabilidade de ele se concentrar nisso.
O mecanismo de atenção do Claude destaca o conceito proibido, mantendo-o ativo na janela de contexto.
Em vez disso, reformule cada negativo como um comando positivo:
- Ruim: Não escreva introduções longas e cheias de floreios. Não utilize palavras como “explorar” ou “tapeçaria.”
- Bom: Comece diretamente com o argumento central. Use uma linguagem concisa e impactante.
Como Migrar Prompts do Claude 3.5 para o Claude 4?
Se você está migrando do Claude 3.5 para o 4.5, você pode migrar sua biblioteca de comandos seguindo cinco passos sistemáticos validados pela experiência do desenvolvedor.
Nós utilizaremos um cenário comum de hospedagem para este exemplo. O objetivo é gerar uma resposta de suporte técnico para um cliente que está enfrentando um erro “503 Service Unavailable” em seu site WordPress.

1. Auditar Suposições Implícitas
Comece identificando onde o prompt depende do modelo para adivinhar o contexto. Nas versões mais antigas, o modelo inferia que você estava usando o conjunto de softwares mais comum. Claude 4.5 não fará essa suposição.
Prompt Antigo:
“Meu site está carregando lentamente e apresentando erros. Você é um administrador de servidor especialista. Pense passo a passo e me diga como corrigir a configuração para torná-lo mais rápido.”
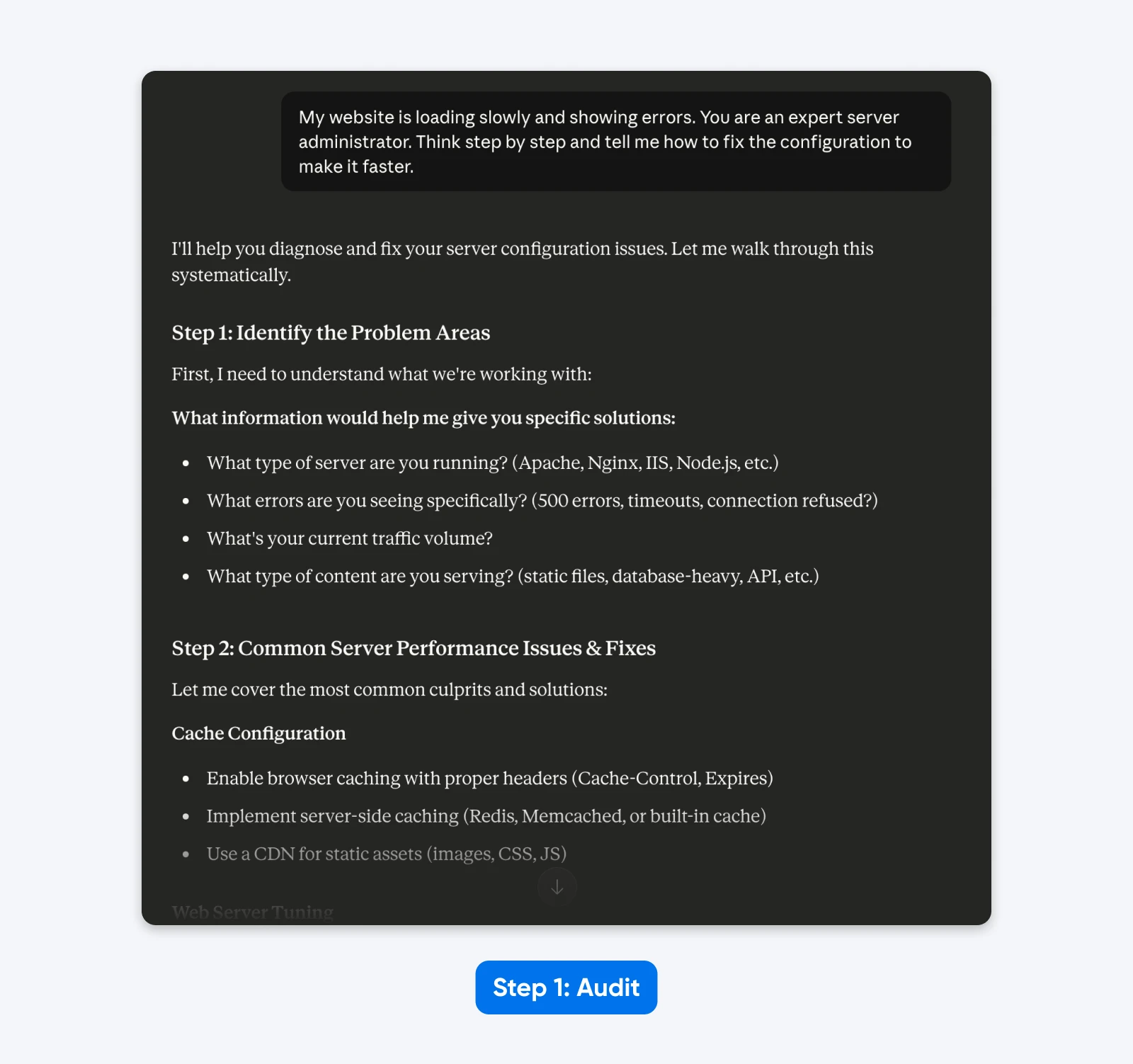
A Auditoria:
- “Website” implica uma configuração genérica, ao invés de um CMS específico (WordPress).
- “Lentamente” é subjetivo; pode significar alto Tempo para o Primeiro Byte ou renderização lenta de ativos.
- “Erros” não apresentam os códigos de status HTTP específicos necessários para diagnóstico.
- “Administrador de servidores especialista” e “Pense passo a passo” são instruções de direcionamento desnecessárias.
Na resposta, Claude 4.5 pede mais informações, pois é treinado para evitar fazer suposições.
2. Refatorar para Especificidade Explícita
Agora, reescreva o prompt para definir o ambiente, o problema específico e o formato de saída desejado. Você deve fornecer os detalhes técnicos que o modelo anteriormente adivinhou.
Prompt Refatorado:
“Meu site WordPress rodando em Nginx e Ubuntu 20.04 está enfrentando um alto Tempo para o Primeiro Byte (TTFB) e erros ocasionais de 502 Bad Gateway. Você é um administrador de servidor especialista. Pense passo a passo e forneça mudanças específicas na configuração do Nginx e PHP-FPM para resolver esses tempos de espera.”

O Resultado: O prompt agora especifica exatamente a pilha de software (Nginx, Ubuntu, WordPress) e o erro específico (502 Bad Gateway), reduzindo a chance de conselhos irrelevantes sobre Apache ou IIS. E Claude responde com uma análise e uma solução passo a passo.
3. Implemente Lógica Condicional
O Claude 4.5 se destaca quando recebe uma árvore de decisão. Em vez de solicitar uma única solução estática, instrua o modelo a lidar com diferentes cenários com base nos dados analisados.
Prompt com Lógica:
“Meu site WordPress funcionando no Nginx e Ubuntu 20.04 está enfrentando altos TTFB e erros 502 Bad Gateway. Você é um administrador de servidor experiente. Pense passo a passo.
Se os registros de erro mostrarem ‘upstream sent too big header’, forneça mudanças de configuração para os tamanhos de buffer. Se os registros de erro mostrarem ‘upstream timed out’, forneça mudanças de configuração para os limites de tempo de execução.”
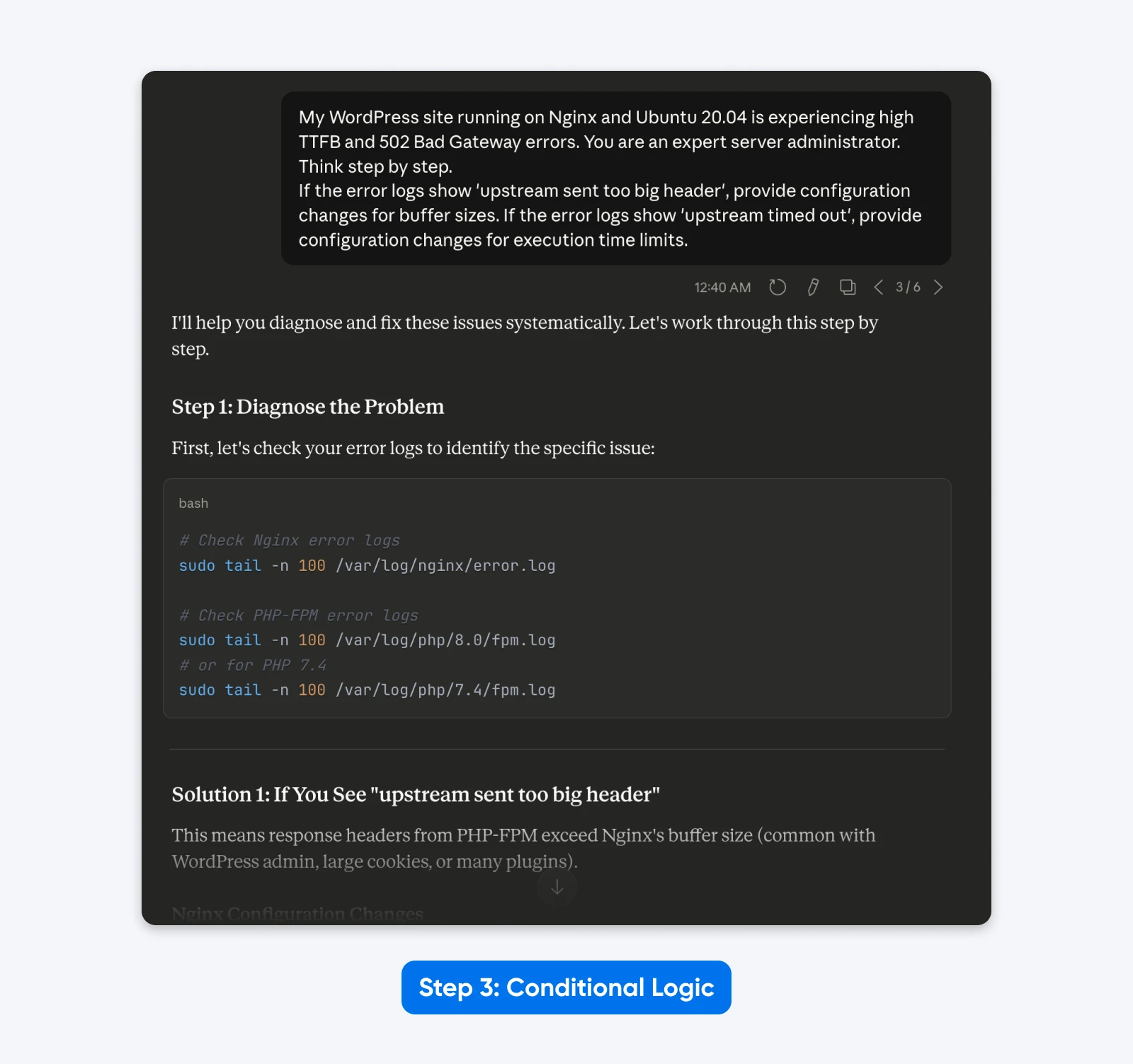
O Resultado: A saída torna-se dinâmica. O modelo oferece soluções específicas baseadas na lógica de causa raiz que você definiu, ao invés de uma lista genérica de correções.
4. Remover Linguagem de Direção Desatualizada
Prompts legados frequentemente contêm instruções de pensamento que os usuários acreditavam melhorar o desempenho. Estas são desnecessárias e redundantes com o Claude 4.5, pois ele possui pensamento estendido.
Prompt Limpo:
“Meu site WordPress rodando em Nginx e Ubuntu 20.04 está enfrentando altos TTFB e erros de 502 Bad Gateway.
Se os registros de erro mostrarem ‘upstream sent too big header’, forneça mudanças de configuração para os tamanhos de buffer. Se os registros de erro mostrarem ‘upstream timed out’, forneça mudanças de configuração para os limites de tempo de execução.”
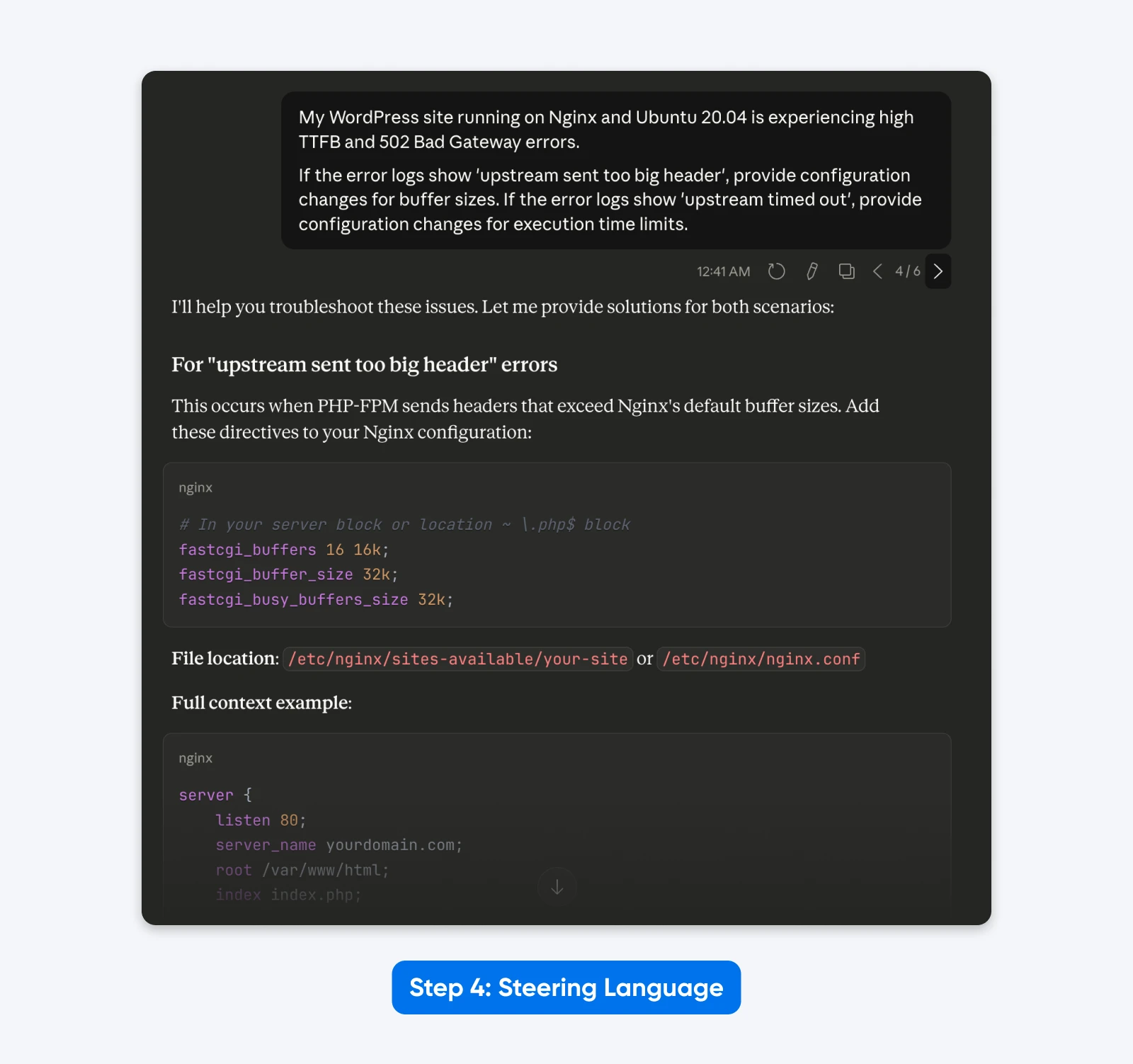
O Resultado: Um prompt mais enxuto que se concentra puramente na tarefa técnica, eliminando a distração de “Você é um especialista” e “Pense passo a passo”.
5. Teste Sistematicamente
Monte os componentes em um formato estruturado usando XML ou cabeçalhos claros. Isso corresponde aos dados de treinamento do modelo e produz os resultados mais consistentes.
PAPEL: Administrador de Sistema Linux especializado em desempenho do Nginx e WordPress.
TAREFA: Resolver erros 502 Bad Gateway e reduzir o Tempo para o Primeiro Byte (TTFB) para um site WordPress no Ubuntu 20.04.
LÓGICA:
- Se os registros mostrarem 'upstream sent too big header', aumente fastcgi_buffer_size e fastcgi_buffers.
- Se os registros mostrarem 'upstream timed out', aumente fastcgi_read_timeout no nginx.conf e request_terminate_timeout no www.conf.
REQUISITOS DE SAÍDA:
- Forneça as linhas exatas de configuração a serem alteradas.
- Explique o impacto de cada mudança na memória do servidor.
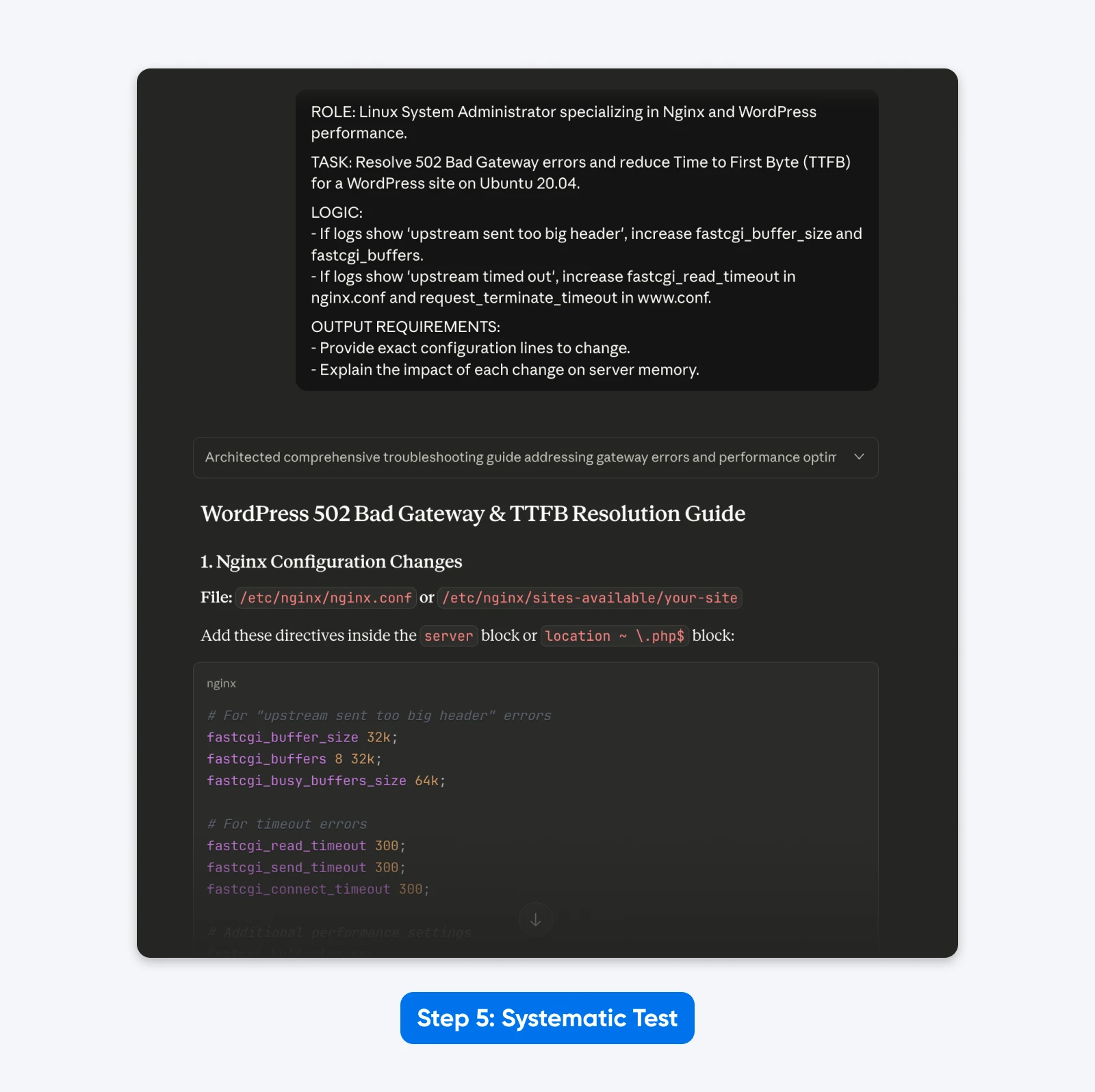
O Resultado: A resposta foi mais estruturada, permitiu-me resolver o problema com dados de arquivo de configuração que podem ser copiados e colados conforme solicitado e explicou a solução melhor.
O Que Isso Significa Para O Seu Fluxo de Trabalho
Os modelos Claude 4.x funcionam de forma diferente dos modelos anteriores. Eles seguem suas instruções exatas em vez de assumir o que você quis dizer, o que ajuda quando você precisa de resultados consistentes. O esforço que você dedica à engenharia de prompts no início compensará se você executar a mesma tarefa repetidamente.
Cada técnica neste guia foi cuidadosamente selecionada porque está alinhada com a forma como o Claude 4.x foi construído. Tags XML, modo de Pensamento Estendido, instruções explícitas, exemplos de poucas tentativas e uma abordagem que prioriza o contexto funcionam porque, com base nos guias de estímulos do Claude e evidências anedóticas, é provável que seja assim que a Anthropic treinou os modelos.
Então vá em frente, escolha uma ou duas técnicas deste guia e teste-as nos seus fluxos de trabalho reais. Meça o que muda e quais métodos funcionam a seu favor. A melhor abordagem é aquela respaldada por dados reais dos seus próprios fluxos de trabalho diários.

