
Wanneer Claude Sonnet 4.5 gelanceerd werd in september 2025, brak het veel van de bestaande prompts. Niet omdat de release buggy was. Maar omdat Anthropic had herbouwd hoe Claude instructies volgt.
Eerdere versies zouden je bedoeling afleiden en uitbreiden op vage verzoeken. Claude 4.x neemt je letterlijk en doet precies wat je vraagt, niets meer.

Om de nieuwe methoden te begrijpen hebben we 25 populaire prompt engineering technieken geëvalueerd tegen Anthropic’s documenten, gemeenschapsexperimenten en daadwerkelijke implementaties om te ontdekken welke prompts daadwerkelijk beter werken met Claude 4.x. Deze vijf technieken
Wat Is Er Veranderd In Claude 4.5 Dat Bestaande Prompts Kapot Maakte?
Claude 4.5 modellen geven prioriteit aan precieze instructies boven “behulpzaam” raden.
De vorige versies vulden de leemtes voor je in. Als je om een “dashboard” vroeg, gingen ze ervan uit dat je grafieken, filters en datatabellen wilde.
Claude 4.5 neemt je letterlijk. Als je om een dashboard vraagt, kan het je een leeg kader met een titel geven omdat je niet om de rest hebt gevraagd.
Anthropic stelt duidelijk: “Klanten die het ‘buitengewone’ gedrag wensen, moeten deze gedragingen misschien explicieter aanvragen.”
Dus, we moeten stoppen met het behandelen van het model als een toverstaf en beginnen met het behandelen ervan als een letterlijke werknemer.
Geen ontwerpvaardigheden. Geen bouwers. Geen gedoe. Alleen resultaten.
Begin Nu
De 5 Bewezen Technieken Die Claude’s Prestaties Meetbaar Verbeteren
Op basis van ons onderzoek leverden deze vijf technieken consequent merkbare verbeteringen op in de prestaties van Claude voor de taken die we erop afvuurden.
1. Gestuctureerde En Gelabelde Prompts
Het systeemprompt van Claude Sonnet 4.5 gebruikt overal gestructureerde prompts. Simon Willison heeft de systeemprompts onderzocht en vond secties omhuld met tags zoals <behavior_instructions>, <artifacts_info> en <knowledge_cutoff>.
In feite kun je “Styles” bewerken om Anthropic’s gestructureerde prompting in actie te zien.
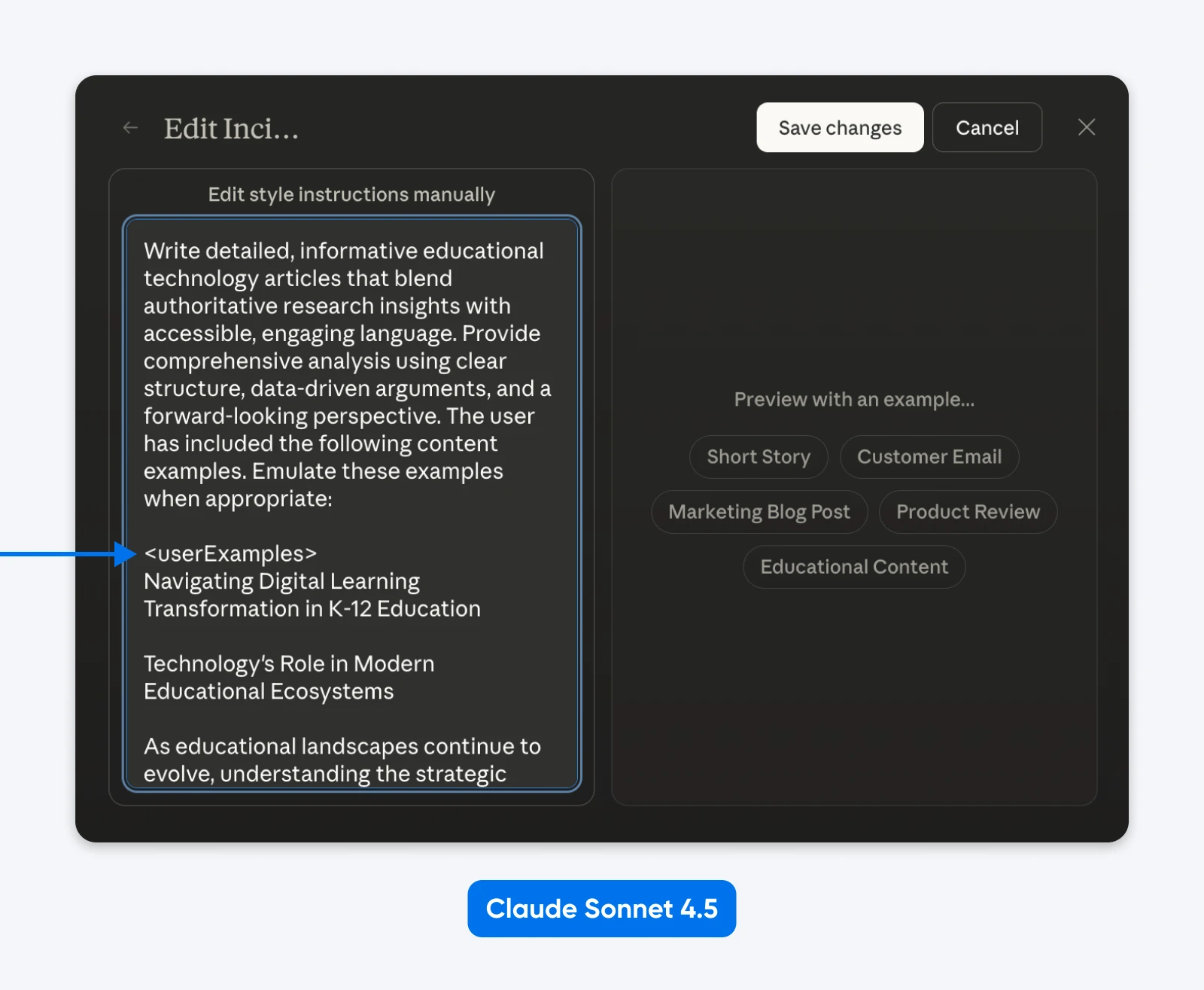
Wat we kunnen afleiden is dat Claude getraind is op gestructureerde prompts en weet hoe ze te verwerken. XML werkt uitstekend, net als JSON of andere gelabelde prompts.
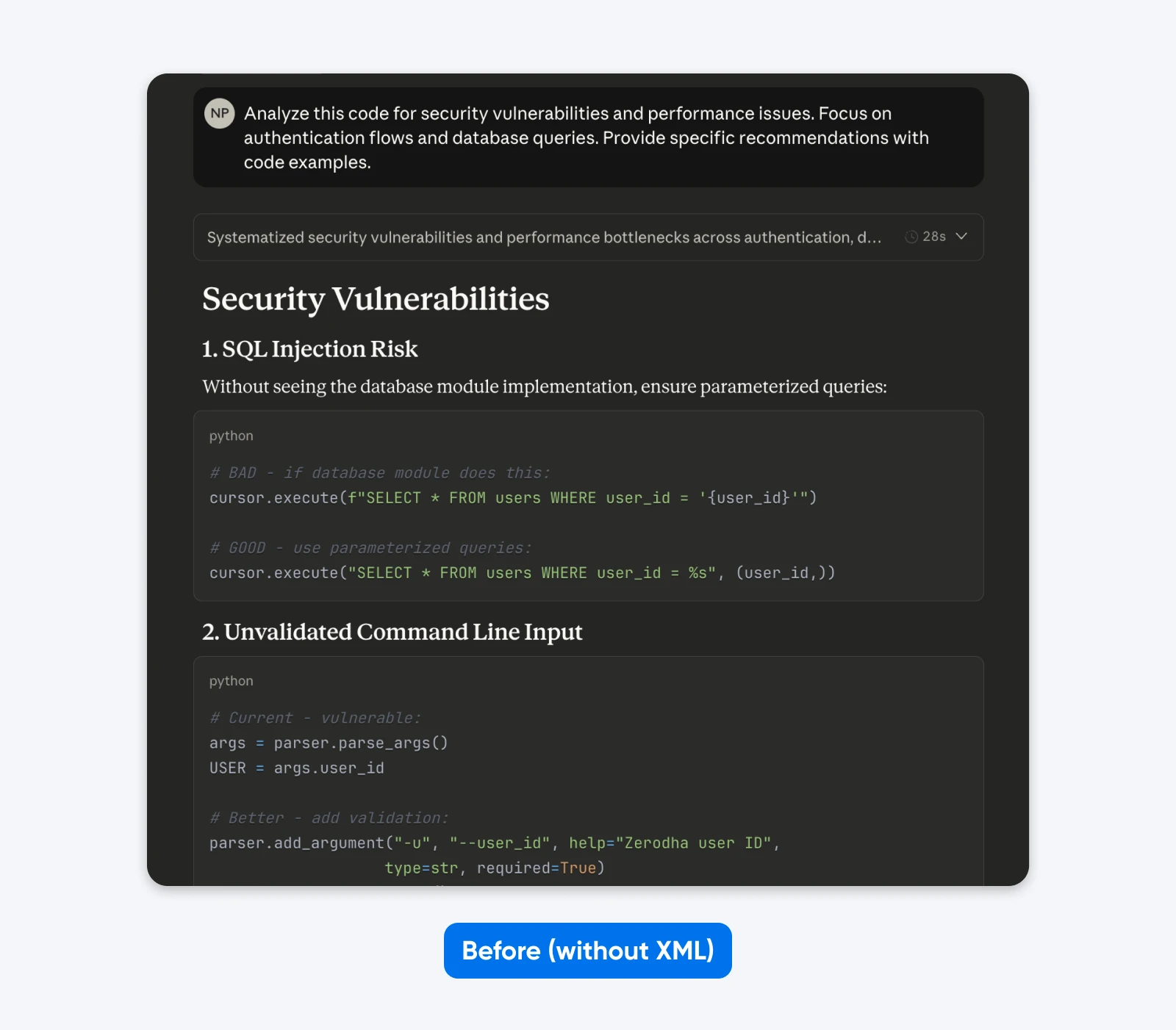
Voor:
Analyseer deze code op beveiligingskwetsbaarheden en prestatieproblemen. Focus op authenticatiestromen en databasequery’s. Geef specifieke aanbevelingen met codevoorbeelden.
Na (gestructureerde prompt):
<task>Analyseer de verstrekte code op beveiligings- en prestatieproblemen</task>
<focus_areas>
– Authenticatiestromen
– Database query optimalisatie
</focus_areas>
<code>
[je code hier]
</code>
<output_requirements>
– Identificeer specifieke kwetsbaarheden met ernstbeoordelingen
– Geef gecorrigeerde codevoorbeelden
– Prioriteer aanbevelingen op basis van bedrijfsimpact
</output_requirements>
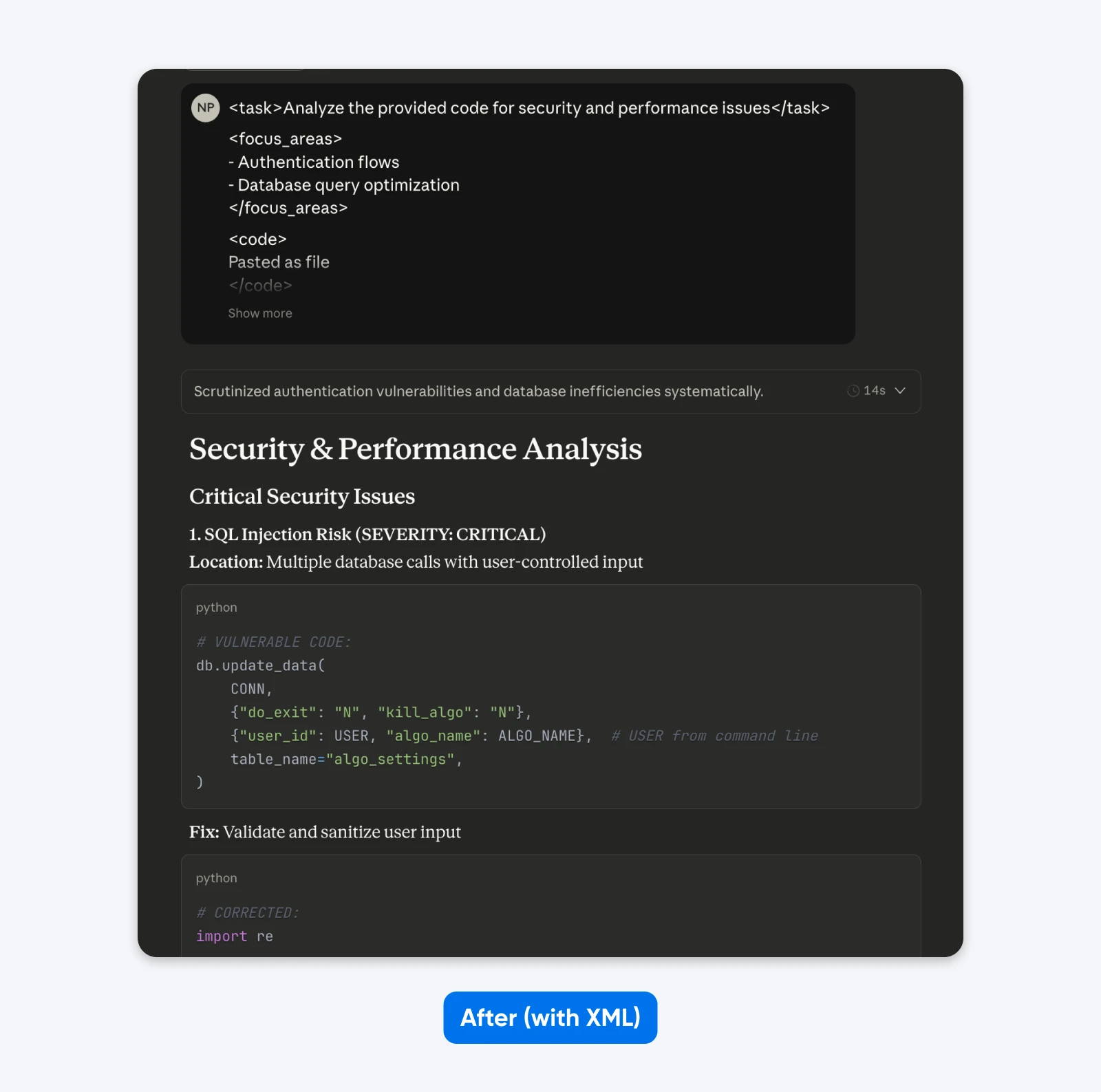
Als je deze resultaten vergelijkt, zul je merken dat de gestructureerde prompt een uitvoer geeft met meer context om je te helpen de beveiligingsproblemen in de code te begrijpen en op te lossen. Het legt het probleem uit, vertelt wat de oplossing doet en geeft vervolgens de code voor de oplossing.
Alternatieve Indelingen Die Werken:
JSON:
{
"task": "Verifieer authenticatiecode",
"focus_areas": ["Wachtwoord hashing", "Sessiebeveiliging", "SQL-injectie"],
"context": "Gezondheidszorg app, HIPAA vereist",
"output_format": "Risico, impact, oplossing, ernst per kwetsbaarheid"
}
Lege Koppen:
TAKE: Controleer authenticatiecode op kwetsbaarheden
FOCUS: Wachtwoordhashing, sessies, SQL-injectie
CONTEXT: Gezondheidszorg-app die HIPAA-naleving vereist
UITVOERFORMAAT: Risico → HIPAA-impact → Oplossing → Ernst
Alle drie werken even goed.
Wanneer gestructureerde prompts het beste werken:
- Meerdere promptcomponenten (taak, context, voorbeelden, vereisten)
- Lange invoer (10,000+ tokens van code of documenten)
- Sequentiële workflows met duidelijke stappen
- Taken die herhaalde verwijzing naar specifieke secties vereisen
Wanneer gestructureerde prompts over te slaan: Eenvoudige vragen waarbij gewone tekst prima werkt.
Effectiviteitsbeoordeling: 9/10 voor complexe taken, 5/10 voor eenvoudige vragen.
2. Uitgebreid Denken Voor Complexe Problemen
Extended Thinking levert enorme verbeteringen op complexe redeneertaken met één groot nadeel: snelheid.
Aankondiging van Anthropic’s Claude 4 toonde aanzienlijke prestatieverbeteringen met ingeschakeld uitgebreid denken. Bij de wiskundecompetitie AIME 2025 verbeterden de scores aanzienlijk.
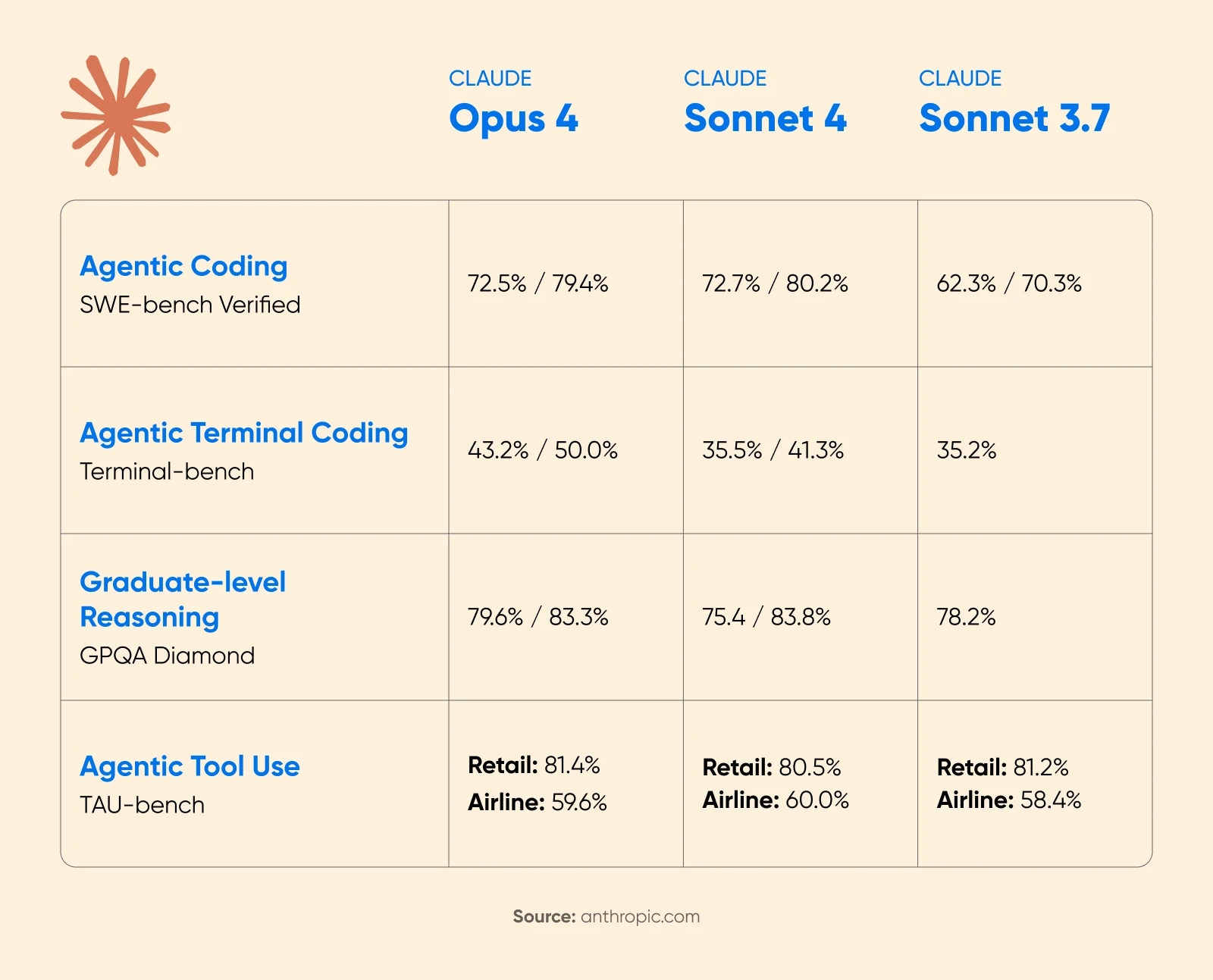
Cognition AI meldde een toename van 18% in planningsprestaties met Sonnet 4.5, en noemde het “de grootste sprong die we hebben gezien sinds Claude Sonnet 3.6.”
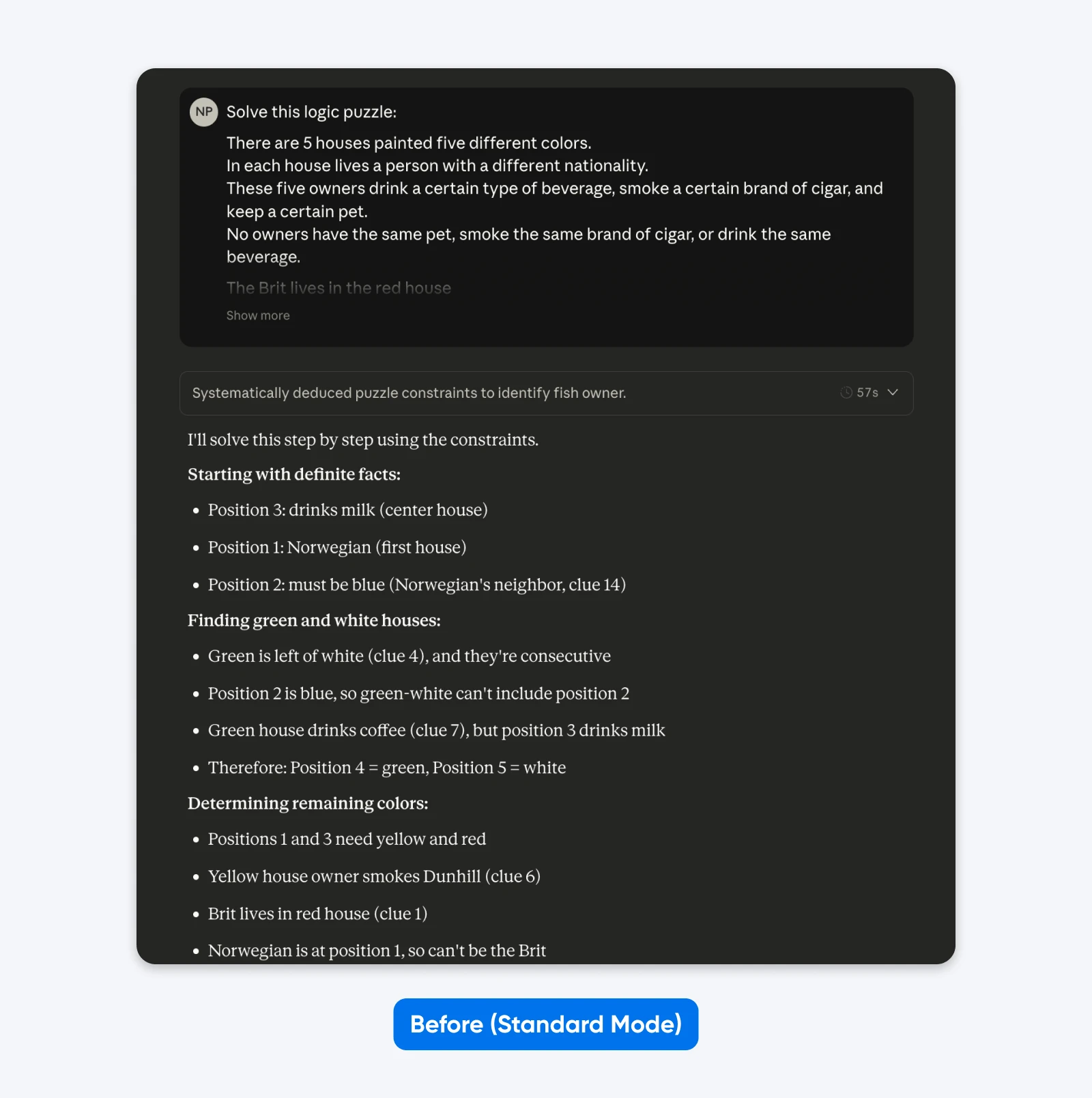
Voor (Standaardmodus):
Los deze logische puzzel op: Vijf huizen op een rij, elk in een andere kleur…
Na (Met Uitgebreid Denken):
Begrijp de logica van deze puzzel systematisch. Doorloop de beperkingen stap voor stap, controleer elke mogelijkheid voordat je conclusies trekt.
Vijf huizen op een rij, elk in een andere kleur…
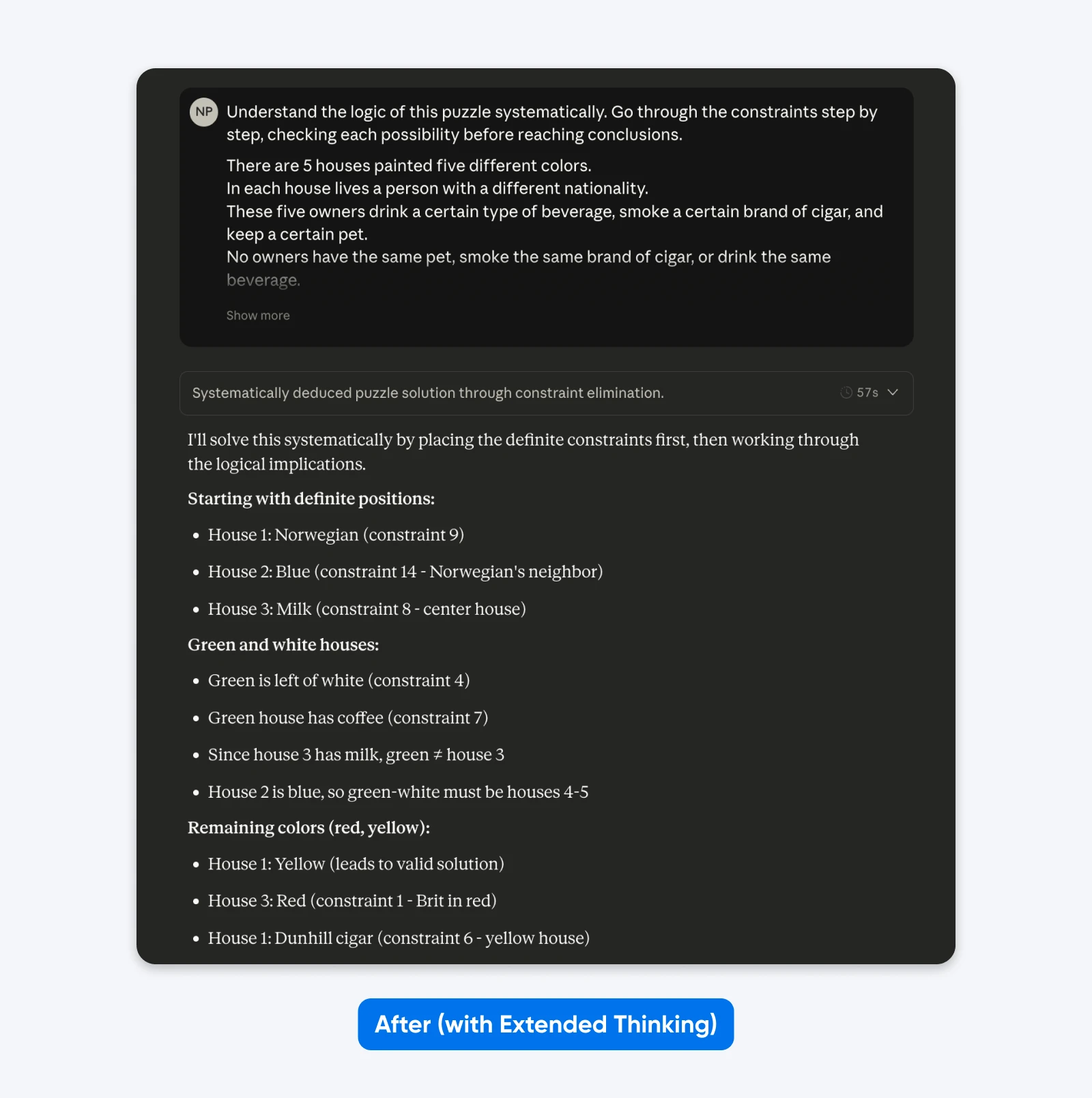
Je zult niet veel verschil zien bij eenvoudige opdrachten zoals hierboven. Maar bij complexe, specifieke problemen (aangepaste codebases, meerstaps logische planning), wordt het verschil duidelijk.
Wanneer uitgebreide dingen werken:
- Meerfasige logische planning die verificatie vereist
- Wiskundige redenering met meerdere oplossingspaden
- Complexe codeertaken over meerdere bestanden
- Situaties waar juistheid belangrijker is dan snelheid
Wanneer Over te Slaan: Snelle iteraties, eenvoudige vragen, creatief schrijven, tijdgevoelige taken
Effectiviteitsbeoordeling: 10/10 voor complexe redeneringen, 3/10 voor eenvoudige vragen.
3. Wees Brutaal Specifiek Over Vereisten
Claude 4-modellen zijn getraind voor nauwkeuriger instructievolging dan eerdere generaties.
De documentatie van Anthropic zegt:
“Claude 4.x modellen reageren goed op duidelijke, expliciete instructies. Specifiek zijn over de gewenste uitkomst kan helpen om de resultaten te verbeteren. Klanten die het ‘boven en buiten’ gedrag van eerdere Claude modellen wensen, moeten deze gedragingen wellicht explicieter aanvragen bij nieuwere modellen.”
De documentatie merkt ook op dat Claude slim genoeg is om te generaliseren vanuit de uitleg wanneer je context geeft voor waarom regels bestaan in plaats van alleen bevelen te geven. Dit betekent dat het geven van een reden het model helpt om principes correct toe te passen in randgevallen die niet expliciet zijn gedekt.
Testen door 16x Eval toonden aan dat zowel Opus 4 als Sonnet 4 een score van 9,5/10 behaalden op TODO-taken toen de instructies duidelijk de vereisten, het formaat en de succescriteria specificeerden. De modellen toonden indrukwekkende beknopte en instructievolgende capaciteiten.
Voor (Impliciete Verwachtingen):
Maak een analytics-dashboard.
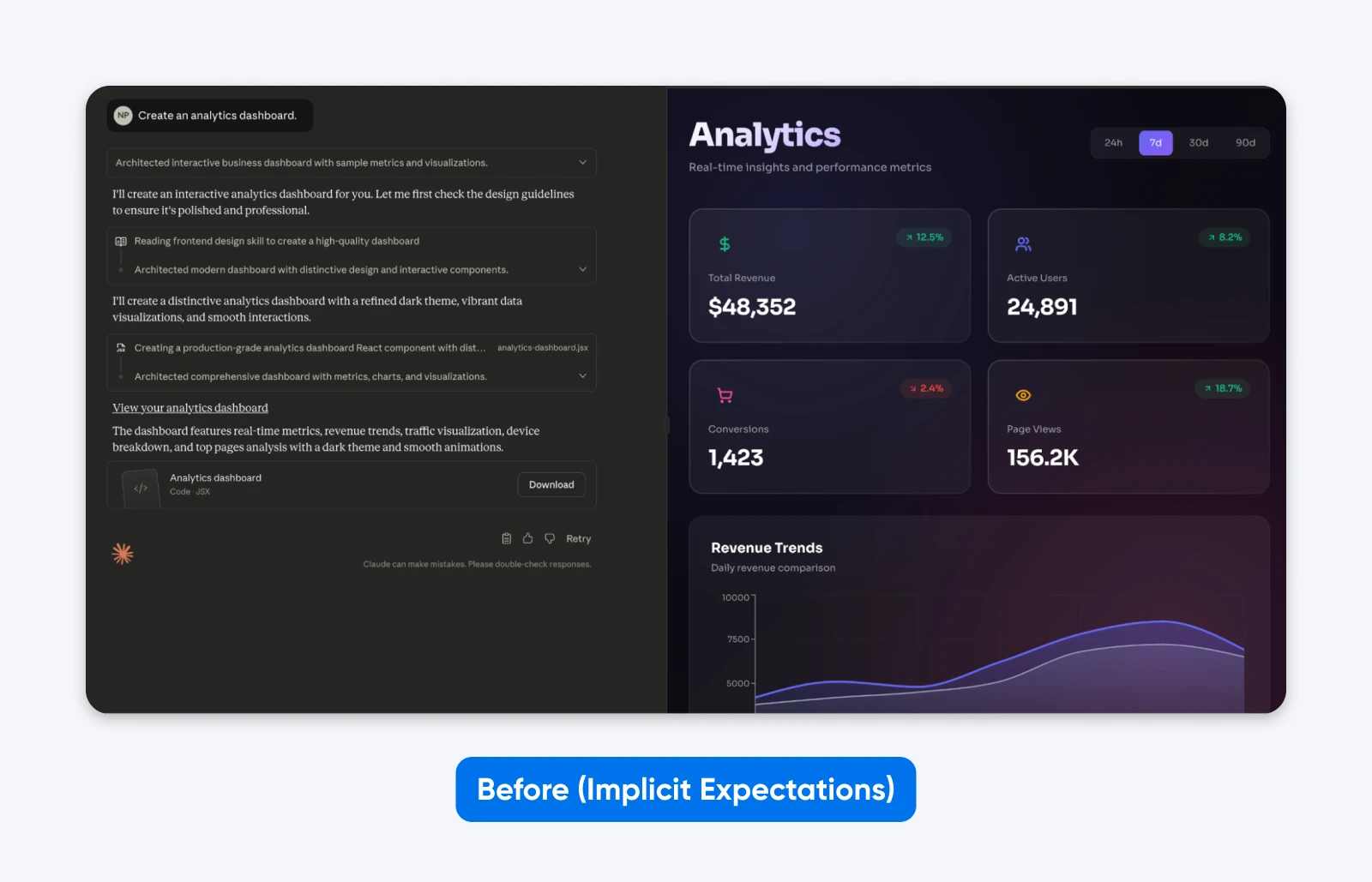
Je zult merken dat deze output PRECIES is wat we vroegen. Hoewel Claude een beetje creatieve vrijheid nam in de esthetiek, heeft het geen functionaliteit.
Na (expliciete vereisten):
Maak een analyse-dashboard. Voeg zoveel mogelijk relevante functies en interacties toe. Ga verder dan de basis om een volledig uitgeruste implementatie te creëren met gegevensvisualisatie, filtermogelijkheden en exportfuncties.
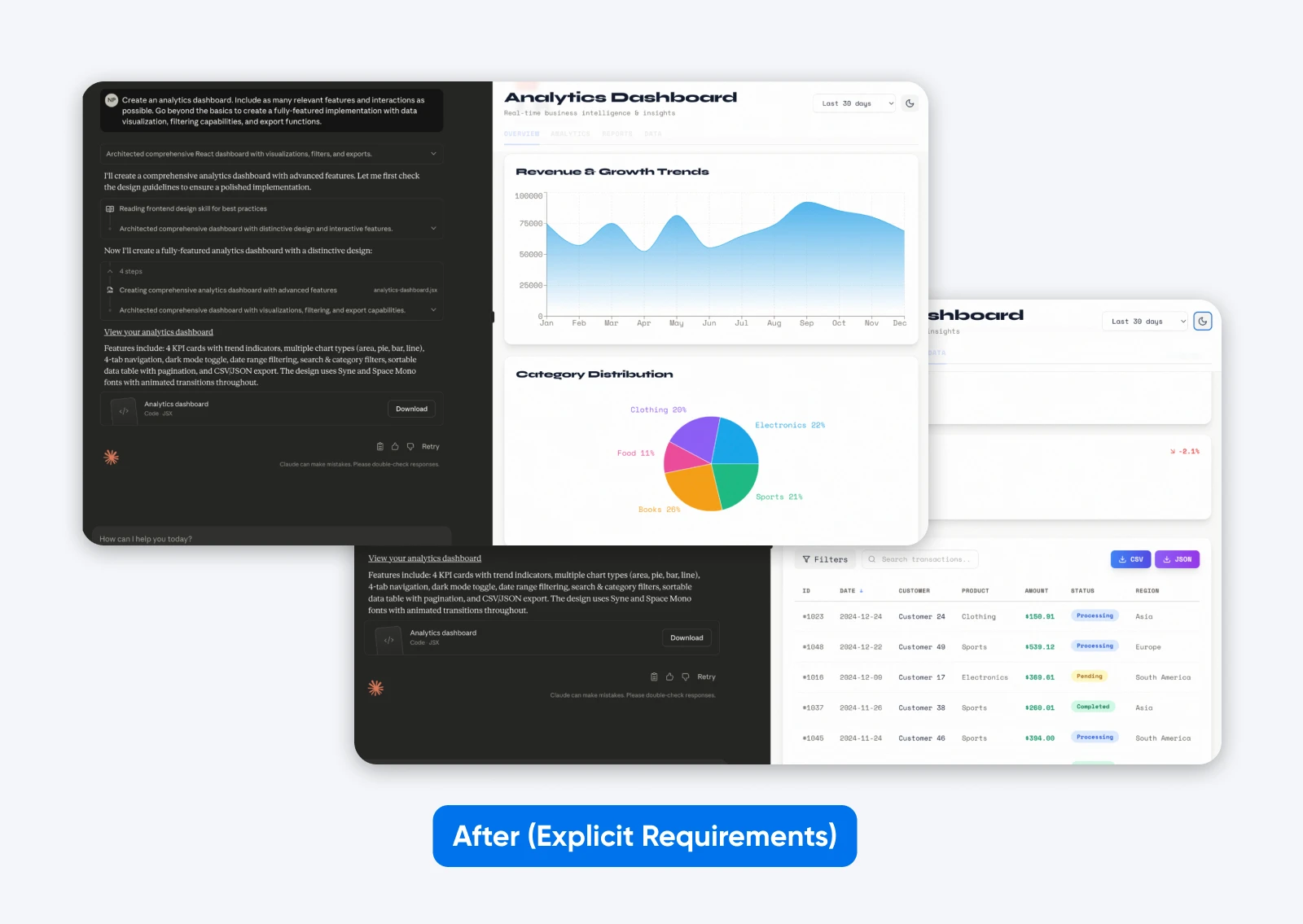
Deze tweede output met een meer beschrijvende prompt heeft meer functies, een dashboard gebaseerd op enkele dummygegevens, die zowel grafisch als in tabelvorm worden gepresenteerd, en het heeft tabbladen om alle gegevens te scheiden.
Dat is wat specifiek zijn doet met de nieuwste Claude.
Om dit punt nog verder te verduidelijken, hier is nog een voorbeeld dat laat zien hoe context instructievolgen verbetert:
Voor (commando zonder context):
Gebruik NOOIT weglatingstekens in je antwoord.
Na (instructie gemotiveerd door context):
Je antwoord wordt hardop voorgelezen door een tekst-naar-spraak-engine, dus vermijd weglatingstekens omdat de engine niet zal weten hoe deze uit te spreken.
Belangrijkste principes voor expliciete instructies:
- Definieer wat “uitgebreid” betekent voor jouw specifieke taak: Ga er niet van uit dat Claude kwaliteitsnormen zal afleiden.
- Leg uit waarom regels bestaan in plaats van ze alleen maar te vermelden: Claude generaliseert beter vanuit gemotiveerde instructies.
- Specificeer het uitvoerformaat expliciet: Vraag om “proza paragrafen” in plaats van te hopen dat Claude niet standaard naar opsommingstekens gaat.
- Geef concrete succes criteria: Hoe ziet de voltooiing van de taak eruit?
Effectiviteitsbeoordeling: 9/10 voor alle soorten taken.
4. Geef Voorbeelden Van Wat Je Wilt
Weinig-shot-prompting voorziet Claude van voorbeeldinputs en -outputs die het gewenste gedrag demonstreren. Dit werkt, maar alleen wanneer de voorbeelden van hoge kwaliteit en taakgeschikt zijn, en de impact verschilt sterk per gebruikssituatie.
De officiële richtlijnen van Anthropic benadrukken:
“Claude 4.x-modellen letten nauwkeurig op details en voorbeelden als onderdeel van hun precieze instructievolging. Zorg ervoor dat je voorbeelden overeenkomen met gedragingen die je wilt aanmoedigen en minimaliseer gedragingen die je wilt vermijden.”
Anthropic raadt aan 3-5 diverse, relevante voorbeelden voor complexe taken. Meer voorbeelden betekent betere prestaties.
Hier is een voorbeeld van hoe dat er in de praktijk uitziet:
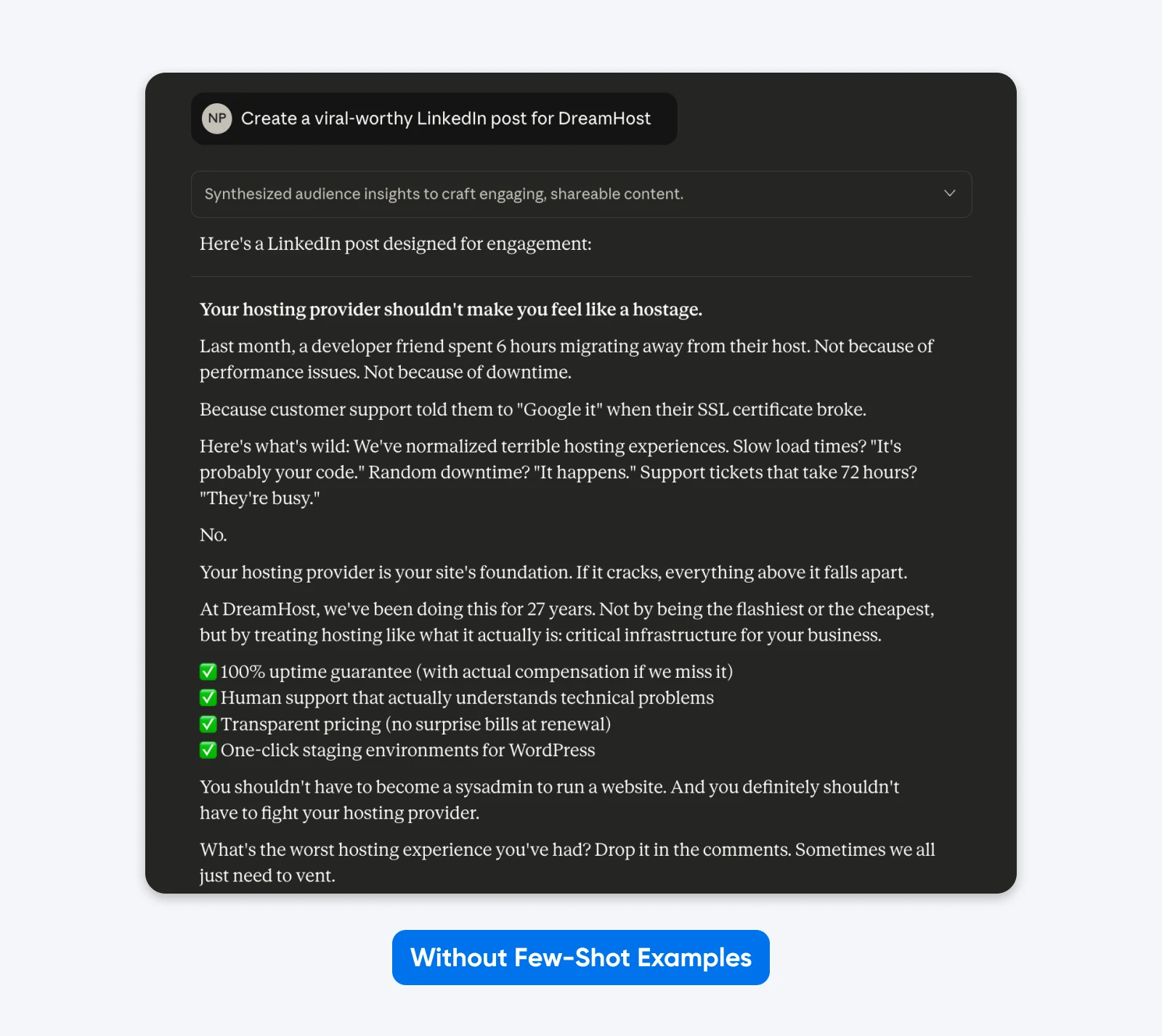
Hier nam Claude creatieve vrijheid met de indeling, emoji-gebruik, berichtgeving en toon. Algemene bedrijfstaal
Het toevoegen van voorbeelden werkt omdat ze laten zien in plaats van vertellen, terwijl ze de subtiele vereisten verduidelijken die moeilijk alleen via beschrijving uit te drukken zijn.
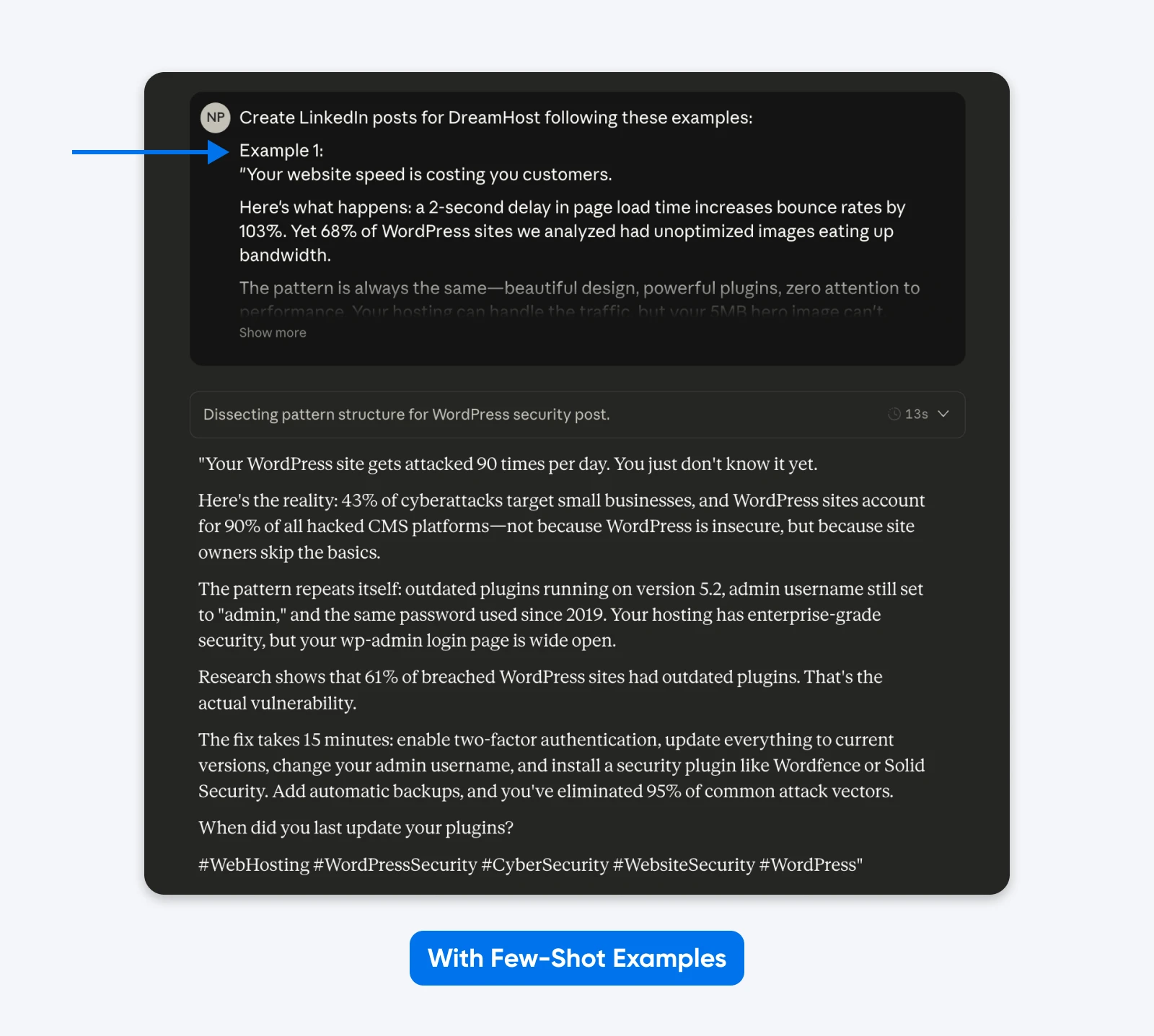
Deze output sluit nauwer aan bij de voorbeelden die ik in de opdracht heb gegeven. Je kunt de methode van voorbeelden met weinig schoten gebruiken om LinkedIn posts te krijgen zoals je best presterende berichten. Een academische paper over Finite State Machine (FSM) ontwerp toonde aan dat gestructureerde voorbeelden een succespercentage van 90% bereikten in vergelijking met instructies zonder voorbeelden.
Hoe Te Implementeren:
- Plaats voorbeelden in <example> tags, gegroepeerd in <examples> tags
- Plaats voorbeelden vroeg in het eerste gebruikersbericht
- Gebruik 3-5 diverse voorbeelden voor complexe taken
- Laat elk detail in voorbeelden overeenkomen met de gewenste uitvoer (Claude 4.x kopieert naamconventies, code-stijl, opmaak, interpunctie)
- Vermijd overbodige voorbeelden
Wanneer Voorbeelden Het Beste Werken:
- Gegevensindeling vereist nauwkeurige structuur
- Complexe programmeerpatronen die specifieke benaderingen vereisen
- Analytische taken die redeneermethoden demonstreren
- Output die consistente stijl en conventies vereist
Wanneer Over Te Slaan: Eenvoudige vragen waar instructies volstaan, of wanneer je wilt dat Claude zijn eigen oordeel gebruikt.
Effectiviteitsbeoordeling: 10/10 voor opmaaktaken, 6/10 voor eenvoudige vragen.
5. Plaats Context Voor Je Vraag
Claude heeft een contextvenster van 200,000 tokens (tot 1 miljoen in sommige gevallen) en kan vragen begrijpen die overal in de context worden geplaatst. Maar Anthropic’s documentatie raadt aan om lange documenten (20,000+ tokens) bovenaan de prompts te plaatsen, voor vragen.
Het testen toonde aan dat dit de responskwaliteit met tot 30% verbetert in vergelijking met query-eerst volgorde, vooral bij complexe, multi-document invoer.
Waarom? De aandachtsmechanismen van Claude geven meer gewicht aan inhoud aan het einde van opdrachten. Door de vraag na de context te plaatsen, kan het model naar eerder materiaal verwijzen tijdens het genereren van antwoorden.
Vooraf (query-eerst):
Analyseer de kwartaal financiële prestaties en identificeer de belangrijkste trends.
[20,000 tokens of financial data]
Na (context-eerst):
[20.000 tokens van financiële gegevens]
Op basis van de bovenstaande kwartaal financiële gegevens, analyseer de prestaties en identificeer de belangrijkste trends in omzetgroei, marge-uitbreiding en operationele efficiëntie. Focus op bruikbare inzichten voor besluitvorming op uitvoerend niveau.
Wanneer Dit Belangrijk Is: Lange-contextanalyse waarbij Claude uitgebreid moet verwijzen naar eerder materiaal.
Wanneer Over te Slaan: Korte prompts onder 5.000 tokens.
Effectiviteitsbeoordeling: 8/10 voor taken met een lange context, 4/10 voor korte opdrachten.
Welke Prompting Technieken Werken Niet Meer: Ontkrachten Van Veelvoorkomende Mythes
De wijzigingen in Claude 4.5 hebben verschillende populaire technieken die werkten met eerdere modellen ongeldig gemaakt.
1. Nadruk Leggen Op Woorden (ALLE HOOFDLETTERS, “MOET”, “ALTIJD”)
Schrijven in volledig hoofdletters garandeert niet langer naleving. Chris Tysons analyse ontdekte dat Claude nu context en logica boven nadruk prioriteert.
Als je “NOOIT gegevens verzinnen” schrijft, maar de context impliceert dat je een schatting nodig hebt, geeft Claude 4.5 prioriteit aan de logische behoefte boven je hoofdletteropdracht.
Gebruik in plaats daarvan conditionele logica:
- Slecht: Gebruik ALTIJD exacte getallen!
- Goed: Als geverifieerde gegevens beschikbaar zijn, gebruik dan precieze cijfers. Zo niet, geef dan bereiken en label ze als schattingen.
2. Handleiding Ketting-van-Gedachten Instructies
Het model vertellen om “stap voor stap te denken” verspilt tokens bij het gebruik van de Uitgebreide Denkmodus.
Wanneer je Uitgebreid Denken inschakelt, beheert het model zijn eigen redeneerbudget. Je eigen “stap-voor-stap” instructies toevoegen is overbodig.
Wat Je In Plaats Daarvan Kunt Doen:
Vertrouw op het hulpmiddel. Als je Uitgebreid Denken inschakelt, verwijder dan alle instructies over hoe te denken.
3. Negatieve Beperkingen (“Doe X Niet”)
Claude precies vertellen wat hij niet moet doen werkt vaak averechts.
Onderzoek naar “Pink Elephant” instructies toont aan dat het vertellen aan een geavanceerd model om niet aan iets te denken de kans vergroot dat het zich erop zal focussen.
Claude’s aandachtsmechanisme benadrukt het verboden concept, waardoor het actief blijft in het contextvenster.
Herformuleer in plaats daarvan elk negatief als een positieve opdracht:
- Slecht: Schrijf geen lange, wollige inleidingen. Gebruik geen woorden zoals “verdiepen” of “tapijtwerk.”
- Goed: Begin direct met het kernargument. Gebruik beknopt, krachtig taalgebruik.
Hoe Migreren Van Claude 3.5 Naar Claude 4?
Als je migreert van Claude 3.5 naar 4.5, kun je je promptbibliotheek migreren door vijf systematische stappen te volgen die gevalideerd zijn door de ervaring van ontwikkelaars.
We zullen een gangbaar hosting scenario gebruiken voor dit voorbeeld. Het doel is om een technische ondersteuningsreactie te genereren voor een klant die een “503 Service Unavailable” fout op hun WordPress site ervaart.

1. Controleer Impliciete Aannames
Begin met identificeren waar de opdracht vertrouwt op het model om de context te raden. In oudere versies zou het model aannemen dat je de meest voorkomende softwarestack gebruikt. Claude 4.5 zal die aanname niet maken.
Legacy Prompt:
“Mijn website laadt langzaam en toont fouten. Je bent een expert serverbeheerder. Denk stap voor stap en vertel me hoe ik de configuratie kan aanpassen om het sneller te maken.”
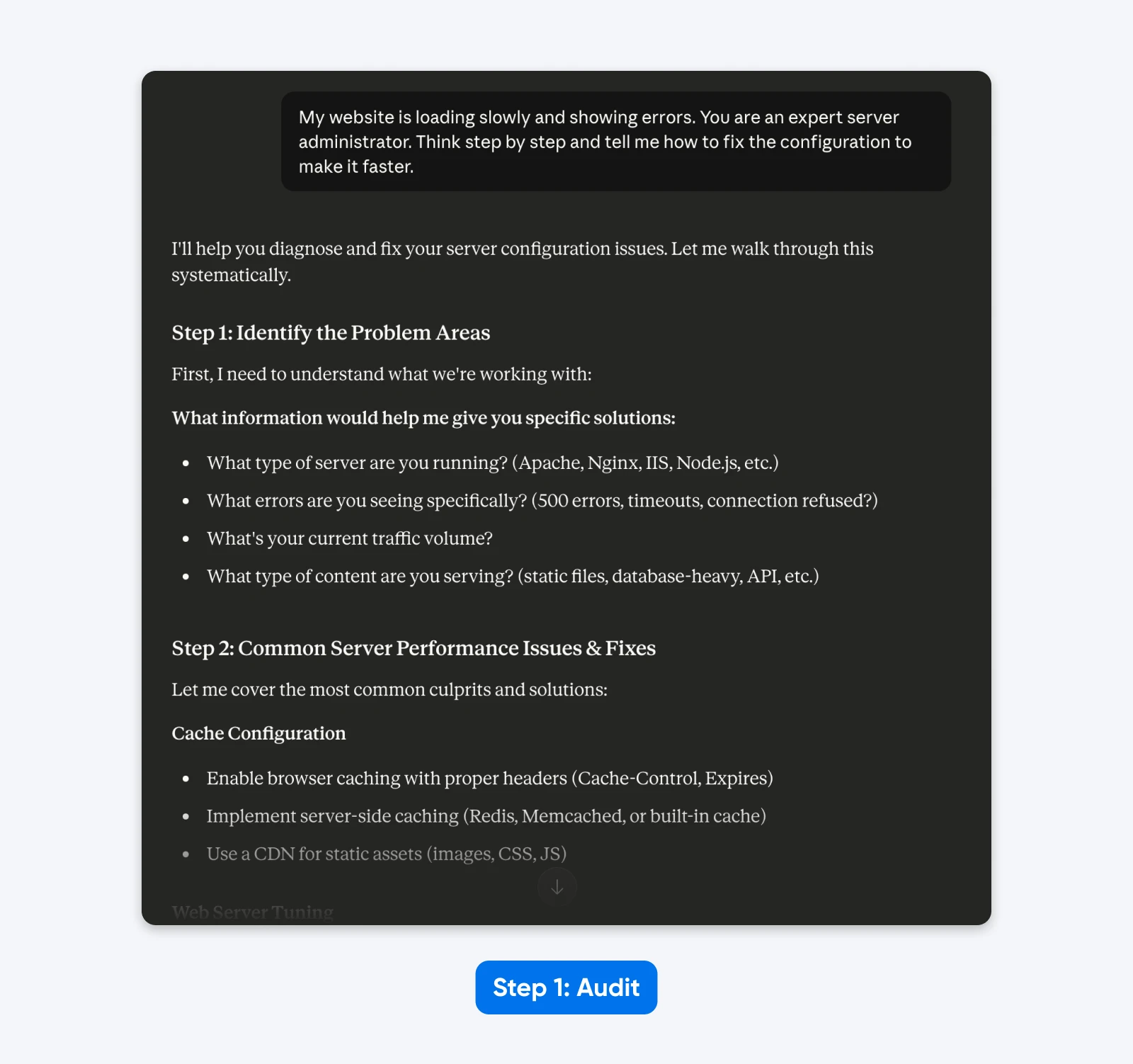
De Audit:
- “Website” impliceert een algemene opzet in plaats van een specifiek CMS (WordPress).
- “Langzaam” is subjectief; het kan wijzen op een hoge Time to First Byte of trage rendering van assets.
- “Fouten” mist de specifieke HTTP-statuscodes die nodig zijn voor diagnose.
- “Expert serverbeheerder” en “Denk stap voor stap” zijn overbodige stuurinstructies.
In de reactie vraagt Claude 4.5 om meer informatie omdat het getraind is om aannames te vermijden.
2. Herschrijf Voor Expliciete Specificiteit
Nu, herschrijf de opdracht om de omgeving, het specifieke probleem en het gewenste uitvoerformaat te definiëren. Je moet de technische details leveren die het model eerder heeft geraden.
Herschreven Opdracht:
“Mijn WordPress-site draait op Nginx en Ubuntu 20.04 en ondervindt een hoge Time to First Byte (TTFB) en af en toe 502 Bad Gateway-fouten. Je bent een expert serverbeheerder. Denk stap voor stap en geef specifieke Nginx en PHP-FPM configuratiewijzigingen om deze timeouts op te lossen.”

Het Resultaat: De aanwijzing specificeert nu de exacte softwarestack (Nginx, Ubuntu, WordPress) en de specifieke fout (502 Bad Gateway), waardoor de kans op irrelevant advies over Apache of IIS verkleind wordt. En Claude reageert met een analyse en een stapsgewijze oplossing.
3. Implementeer Conditionele Logica
Claude 4.5 blinkt uit bij het gebruik van een beslissingsboom. In plaats van te vragen om een enkele statische oplossing, geef je het model opdracht om verschillende scenario’s te behandelen op basis van de geanalyseerde gegevens.
Logica In Prompt:
“Mijn WordPress-site draait op Nginx en Ubuntu 20.04 en ervaart hoge TTFB en 502 Bad Gateway fouten. Je bent een expert serverbeheerder. Denk stap voor stap.
Als de foutenlogboeken ‘upstream verzond te grote header’ tonen, geef dan configuratiewijzigingen voor buffergroottes. Als de foutenlogboeken ‘upstream timed out’ tonen, geef dan configuratiewijzigingen voor uitvoeringstijdlimieten.”
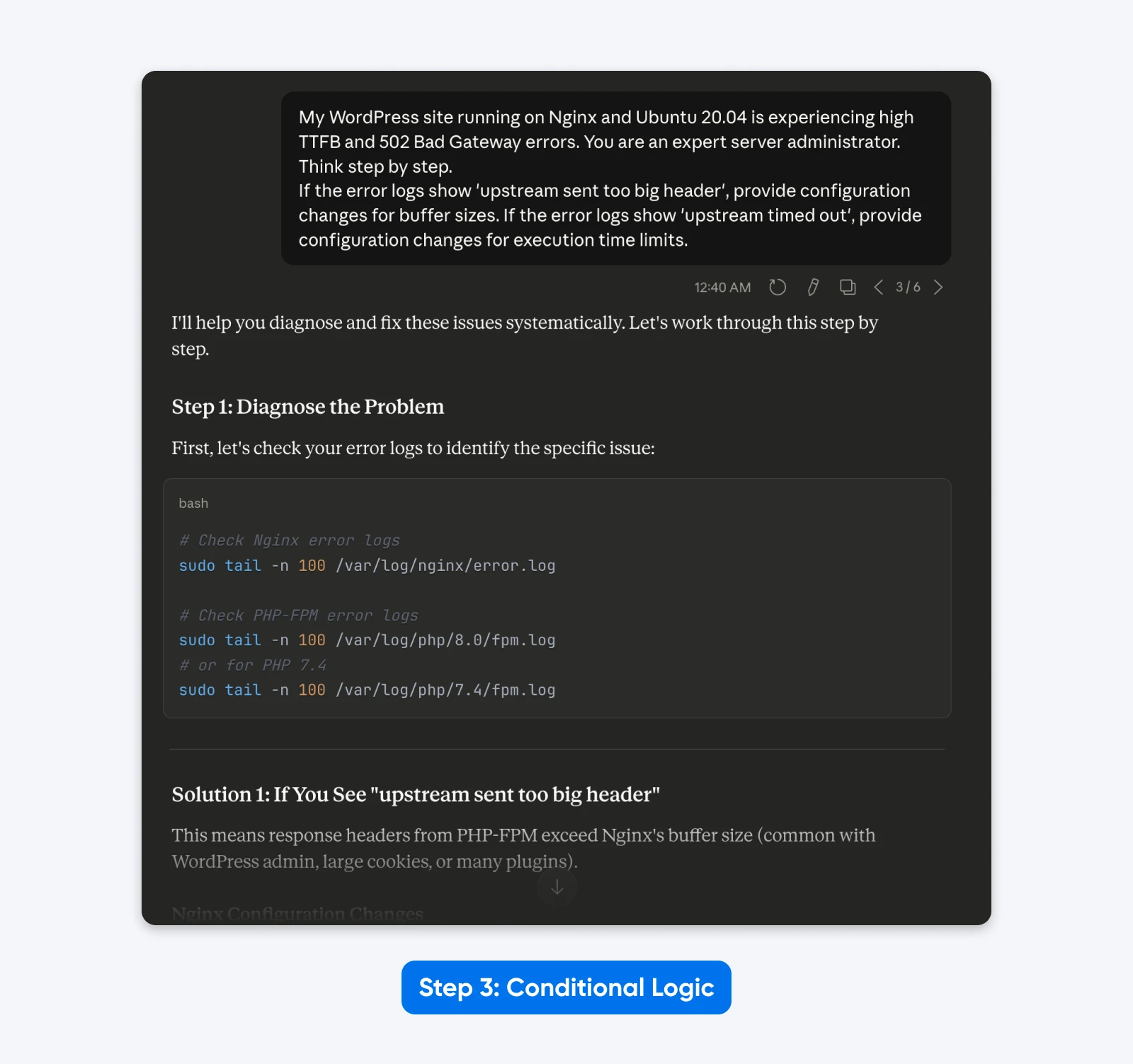
Het Resultaat: De output wordt dynamisch. Het model biedt gerichte oplossingen op basis van de specifieke logica van de hoofdoorzaak die je hebt gedefinieerd, in plaats van een algemene lijst met oplossingen.
4. Verwijder Verouderde Stuurtaal
Oude prompts bevatten vaak denkinstructies waarvan gebruikers geloofden dat ze de prestaties verbeterden. Deze zijn overbodig en overbodig met Claude 4.5 omdat het uitgebreid nadenken heeft.
Opgeschoonde Opdracht:
“Mijn WordPress-site draait op Nginx en Ubuntu 20.04 en ervaart hoge TTFB en 502 Bad Gateway fouten.
Als de foutenlogboeken ‘upstream sent too big header’ tonen, geef configuratiewijzigingen voor buffergroottes. Als de foutenlogboeken ‘upstream timed out’ tonen, geef configuratiewijzigingen voor uitvoeringstijdlimieten.”
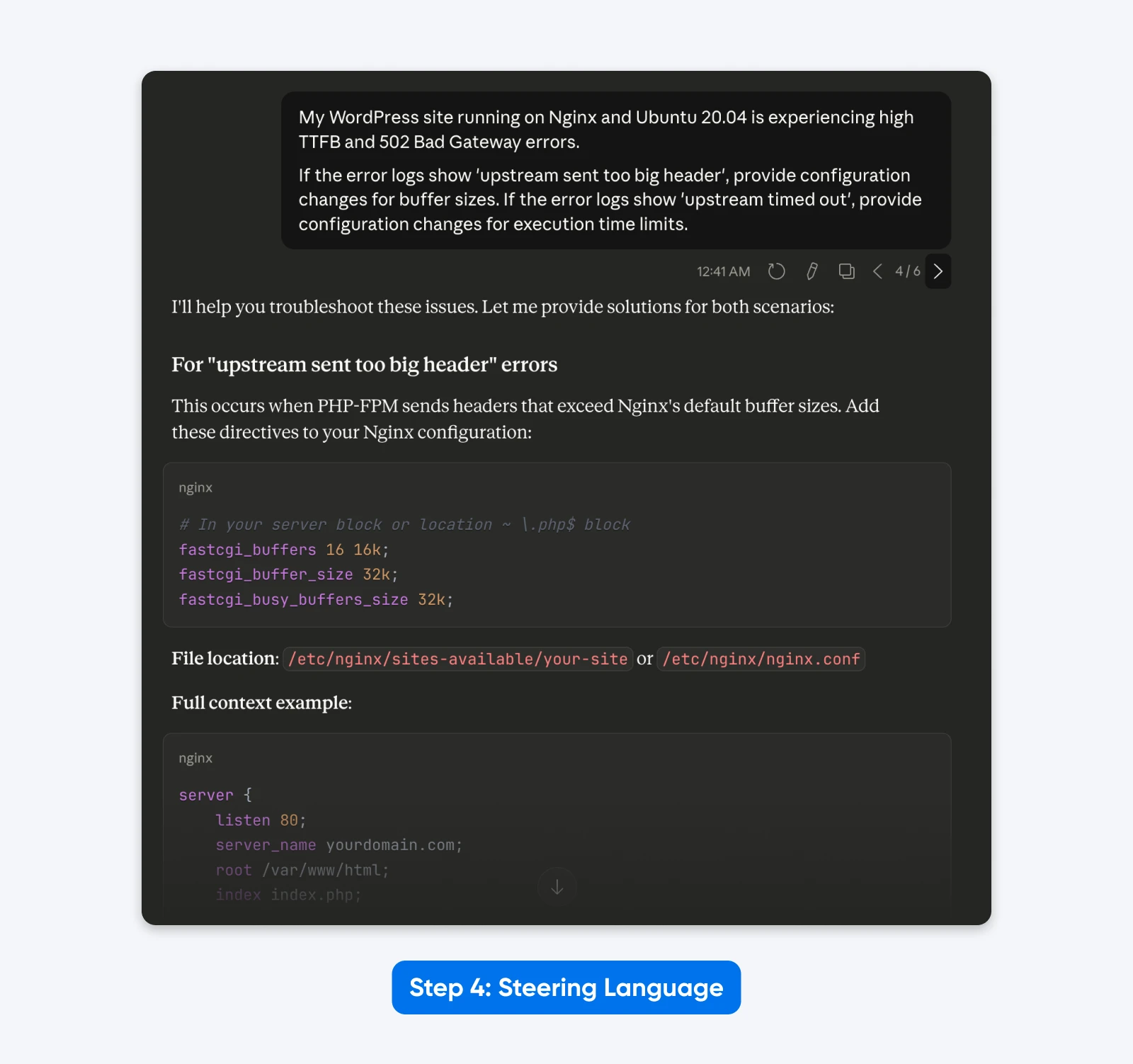
Het Resultaat: Een beknopte prompt die zich puur richt op de technische taak, zonder de afleiding van “Je bent een expert” en “Denk stap voor stap.”
5. Test Systematisch
Zet de componenten samen in een gestructureerd formaat met behulp van XML of duidelijke koppen. Dit komt overeen met de trainingsgegevens van het model en levert de meest consistente resultaten op.
ROL: Linux-systeembeheerder gespecialiseerd in Nginx en WordPress-prestaties.
TAAK: Los 502 Bad Gateway-fouten op en verminder de Time to First Byte (TTFB) voor een WordPress-site op Ubuntu 20.04.
LOGICA:
- Als logboeken 'upstream sent too big header' tonen, verhoog dan fastcgi_buffer_size en fastcgi_buffers.
- Als logboeken 'upstream timed out' tonen, verhoog dan fastcgi_read_timeout in nginx.conf en request_terminate_timeout in www.conf.
OUTPUTVEREISTEN:
- Geef exacte configuratieregels om te wijzigen.
- Leg de impact van elke verandering op het servergeheugen uit.
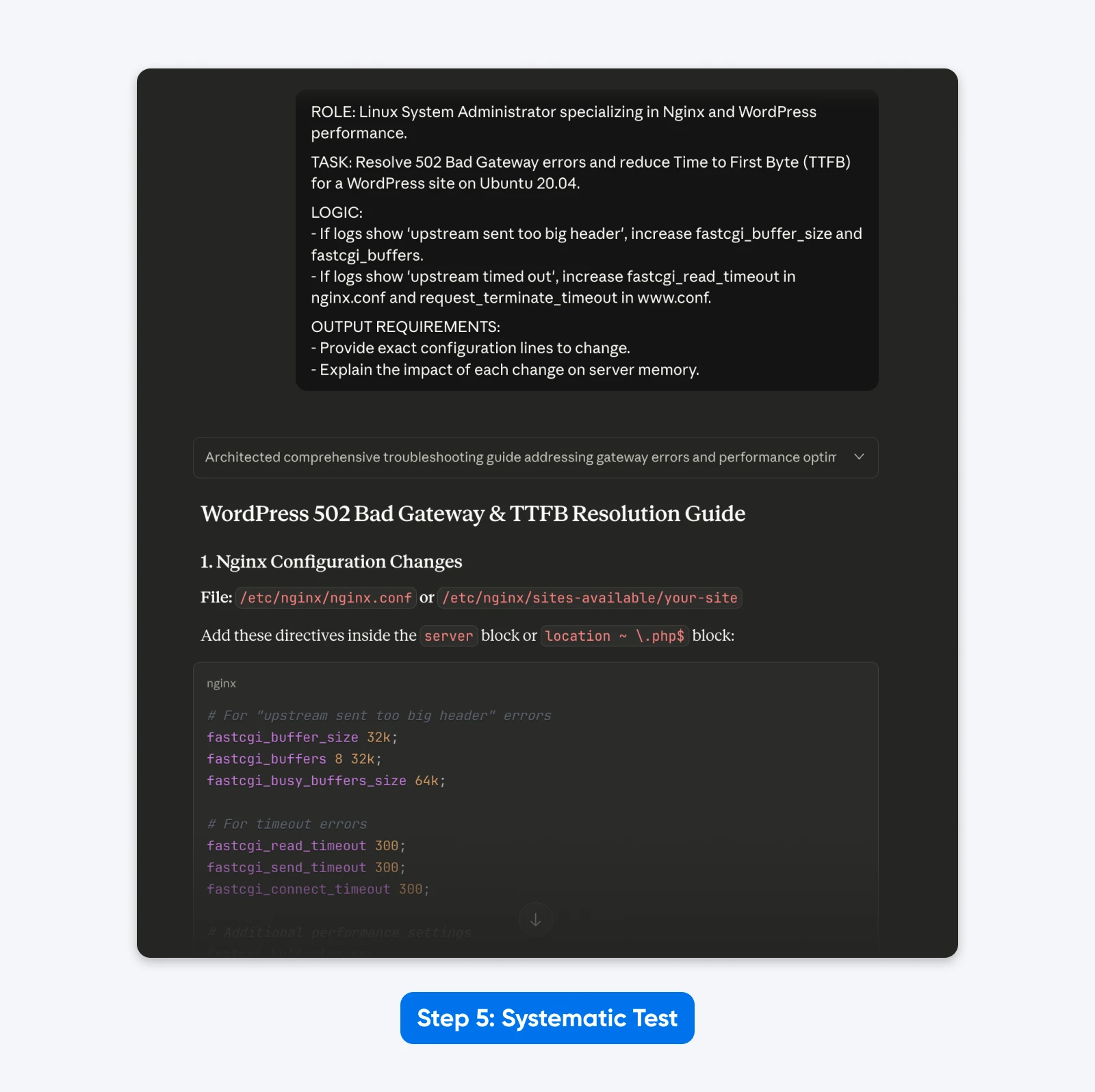
Het Resultaat: De reactie was gestructureerder, stelde me in staat het probleem op te lossen met kopieerbare configuratiebestandgegevens zoals gevraagd en legde de oplossing beter uit.
Wat Dit Betekent Voor Je Werkproces
Claude 4.x modellen werken anders dan eerdere modellen. Ze volgen je exacte instructies in plaats van te aannemen wat je bedoelde, wat helpt wanneer je consistente resultaten nodig hebt. De moeite die je aan het begin besteedt aan prompt engineering zal zich terugbetalen als je dezelfde taak herhaaldelijk uitvoert.
Elke techniek in deze handleiding is zorgvuldig uitgekozen omdat deze nauw aansluit bij hoe Claude 4.x is opgebouwd. XML-tags, Uitgebreide Denkmodus, expliciete instructies, enkele voorbeelden en een context-eerste benadering werken omdat, gebaseerd op de aanwijzingengidsen van Claude en anekdotisch bewijs, dat waarschijnlijk is hoe Anthropic de modellen heeft getraind.
Dus ga je gang, kies één of twee technieken uit deze gids en test ze op je eigenlijke workflows. Meet wat verandert en welke methoden in je voordeel werken. De beste aanpak is degene die wordt ondersteund door echte gegevens uit je eigen dagelijkse workflows.

