
Als je hebt gemerkt dat je favoriete illustrator plotseling van Instagram is verdwenen, of die ene ouder-vriend die stilletjes elke foto van hun kind van Facebook verwijdert, beeld je het je niet in. In de afgelopen jaren hebben mensen content van het web verwijderd vanwege zorgen over generatieve AI.
Dat kan eruitzien als veel verschillende dingen: artiesten die hun portfolio’s offline halen nadat ze AI-modellen ontdekken die schilderijen uitspuwen in hun eigen stijl, ouders die familiefoto’s verwijderen uit angst dat de gezichten van hun kinderen in een deepfake terecht kunnen komen, of bedrijven die AI-webcrawlers volledig blokkeren van toegang tot hun website.
Op basis van een analyse van DreamHost-klanten hebben we gevonden dat ongeveer 5,000 totale websites die onze hostingdiensten gebruikenactief sommige of alle AI webcrawlers blokkeren.
Met andere woorden, er is een echte en meetbare zorg over hoe AI-tools toegang krijgen tot, begrijpen en de inhoud die we allemaal online plaatsen verwerken.
Het is niet dat deze zorgen nieuw zijn.
Het internet is altijd een rommelige plek geweest voor toestemming, privacy en eigendom. Wat veranderd is, is dat AI iedereen, van makers tot gezinnen en kleine ondernemers, heeft gedwongen om eindelijk onder ogen te zien hoe weinig controle ze hebben over wat ze online zetten.
Bij DreamHost hebben we altijd geloofd dat het open web floreert wanneer makers bepalen wat ze delen en hoe het wordt gebruikt. Het web functioneert het beste wanneer het eigendom ligt bij de mensen die het hebben gebouwd — niet alleen bij de platforms die er winst uit halen.
En dat brengt ons bij de kern van de zaak. De echte vraag is niet wat AI kan doen — het gaat erom wie mag beslissen.
Het Echte AI-Ethiek Probleem Is Niet De Technologie — Het Is Het Verlies Van Keuze
AI is hier niet de schurk. De echte bedreiging is het “platformpaternalisme”, oftewel bedrijven die “ethische” keuzes maken namens iedereen. Bijvoorbeeld, in 2024 begonnen verschillende grote content delivery-netwerken (CDN’s) en netwerkleveranciers standaard AI webcrawlers te blokkeren, met als bewering dat ze “creators wilden beschermen.” Het resultaat was dat miljoenen site-eigenaren wakker werden om te ontdekken dat er al voor hen beslissingen waren genomen over hun content.
Het is alsof je huisbaas je deur op slot doet voor jouw veiligheid, maar zonder je de juiste sleutels te geven. Wat begon als een gemak, verandert snel in een verlies van zelfstandigheid. Wanneer poortwachters bepalen hoe “bescherming” eruitziet, krimpt de individuele autonomie.
Het open web is gebaseerd op innovatie zonder toestemming, wat betekent dat iedereen kon creëren, delen en itereren zonder om goedkeuring te vragen. Bemiddelaars die bepalen welke bots of tools toegang krijgen tot inhoud, kunnen die vrijheid met decennia terugdraaien.
Daarom pleit DreamHost voor infrastructuur onafhankelijkheid: wanneer je je eigen inhoud host, kan niemand jouw regels herschrijven. Je stack bezitten betekent je beleid bezitten, of je nu AI webcrawlers verwelkomt of ze volledig buitensluit. De ethiek komt niet uit code; het komt uit keuze.

“AI Heeft Je Gegevens Nodig” en Andere Mythes
Wat weerhoudt makers ervan om de controle terug te krijgen? Vaak is het desinformatie, zoals deze wijdverbreide mythen rondom AI. Deze mythen zijn populair omdat het gebruik van AI zich heeft verspreid over het internet en de hulpmiddelen die we dagelijks gebruiken.
Mythe #1: “AI Heeft Jouw Gegevens Nodig Om Vooruit Te Komen”
Niemand is verplicht om hun werk aan commerciële AI-bedrijven te geven. Er bestaan gelicenseerde en op toestemming gebaseerde modellen; bijvoorbeeld, Adobe Firefly traint gelicenseerde inhoud met toestemming en werken van het publieke domein zonder auteursrecht. De toekomst van AI hoeft niet afhankelijk te zijn van stelen. Het kan afhankelijk zijn van toestemming in plaats daarvan.
Mythe #2: “Als Je Je Uitschrijft, Zul Je Verdwenen Zijn”
Afzien kan je zichtbaarheid in door AI gegenereerde samenvattingen of zoekfragmenten beperken, maar het zal je niet van het web verwijderen. Denk eraan alsof je in 2005 afziet van Google. Je verliest bereik, niet relevantie, vooral als je publiek je nog steeds rechtstreeks zoekt.
Hoewel het misschien niet praktisch is voor iedereen die afhankelijk is van bereik om hun publiek of klantenbestand te laten groeien (hoewel we nog steeds geen goede gegevens hebben over hoeveel organisch verkeer daadwerkelijk afkomstig is van GEO), is voor sommige makers zichtbaarheid het niet waard als het onvrijwillig gebruik inhoudt. Het belangrijkste is dat zij zelf mogen beslissen.
Mythe #3: “AI Scraping Is Gewoon Hoe Het Internet Werkt”
Indexeren voor ontdekking en toe-eigenen voor training zijn niet hetzelfde.
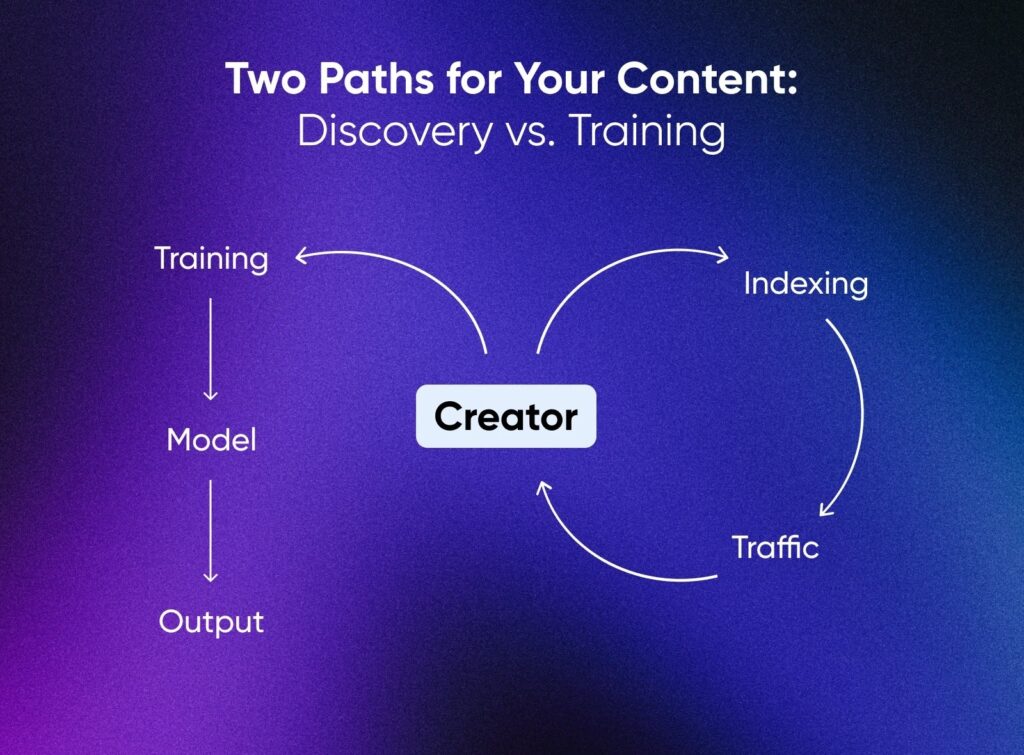
Indexeren trekt mensen naar je site. Training vervangt je door een statistische kopie. Uitgevers zoals de Associated Press en Axel Springer bewijzen dat er een middenweg is door hun inhoud te licenseren voor modeltraining met erkenning en compensatie.
Zelfs goede bedoelingen kunnen averechts werken. De kern van de zaak is dat evenwichtige ethiek geïnformeerde toestemming vereist.
Uitzetten vs. Openblijven: De Echte Afwegingen
Elke AI-houding — van volledige openheid tot totale afwijzing — brengt echte opportuniteitskosten met zich mee. Waar je staat hangt af van wat je het belangrijkst vindt, van zichtbaarheid tot controle tot duurzaamheid tot autonomie.
DreamHost’s interne gegevens tonen aan dat ongeveer 71,5% van al het webverkeer nu afkomstig is van bots en niet van mensen. Dat betekent dat de meeste verzoeken aan je site geautomatiseerd zijn: sommige zijn nuttig (zoals zoekindexering of uptime monitoring), andere minder. Het beheren van welke webcrawlers je toestaat en welke je blokkeert, is ethische duurzaamheid in actie.
Hieronder staan vier gangbare benaderingen die makers gebruiken voor AI-toegang en -training en hoe elk verschillende factoren van het open web beïnvloedt, zodat je de compromissen kunt zien voordat je je positie vastlegt.
| Volledig Open | Selectieve Licentieverlening | Blokkeer AI Training | Volledig Uitgesloten van AI | |
| Zichtbaarheid en Bereik | Hoog; AI-samenvattingen en zoekmachines kunnen je werk overal tonen. | Gemiddeld; blootstelling beperkt tot partners die inhoud licenseren. | Laag; uitgesloten van AI-resultaten maar nog steeds zichtbaar in traditionele zoekopdrachten. | Geen; geblokkeerd voor zowel AI als veel ontdekkingscrawlers. |
| Controle en Toestemming | Minimaal; platformen beslissen voor jou. | Hoog; gereguleerd door expliciete licentievoorwaarden. | Sterk; je bepaalt toestemmingen via robots.txt en HTTP headers. | Absoluut; alle geautomatiseerde toegang is verboden. |
| Toewijzing | Laag; de meeste AI-modellen vermelden geen bronnen. | Hoog; attributie en royalty’s ingebouwd in contracten. | Middelmatig; conforme crawlers kunnen je nog steeds crediteren. | Geen; inhoud wordt nooit gerefereerd. |
| Milieu-Impact | Gemiddeld; draagt bij aan brede modeltraining en indexbelasting. | Gemiddeld; beperkt, gelicentieerd gebruik vermindert dubbele training. | Gemiddeld-laag; minder zware crawlers, meer gericht verkeer. | Laag; minste externe verzoeken en datatransfers. |
| Risico op Misbruik of Kopiëren | Hoog; stijl of tekst kan vrijelijk worden gerepliceerd. | Gemiddeld; juridische verhaal via licentievoorwaarden. | Laag; conforme bots worden afgeschrikt, schurkachtige bots nog steeds mogelijk. | Heel laag; minimaal oppervlak om te schrapen. |
Elk pad heeft zijn waarde. Marketeers en kleine ondernemers zijn vaak afhankelijk van zichtbaarheid om hun publiek te laten groeien, terwijl illustratoren, journalisten en opvoeders eigendom en toestemming boven alles kunnen stellen. Het web bloeit op diversiteit, en ethische deelname aan AI zou die diversiteit aan doelen moeten weerspiegelen.
Er is geen universeel juist antwoord: alleen geïnformeerde compromissen die passen bij je principes en hoe je online je brood verdient. De juiste houding is niet voor iedereen hetzelfde, maar je zou je standpunt bewust moeten vormen en het ondersteunen met actie. Welk pad je ook kiest, doe het met opzet.
Hoe Bepaal Je Jouw AI-positie
Ethiek is alleen van belang wanneer het wordt toegepast. Hier is hoe je theorie omzet in actie en definieert hoe AI interageert met je werk.
Stap 1: Verduidelijk Je Doelen
Begin met het rangschikken van wat voor jou het belangrijkst is: zichtbaarheid, inkomsten, duurzaamheid, controle.
Een klein bedrijf dat bereik nastreeft, kan een bredere toepassing van AI tolereren, terwijl een illustrator die originaliteit bewaakt dat misschien niet doet. Verschillende doelen = verschillende grenzen.

Stap 2: Controleer Je Digitale Voetafdruk
Lijst waar je inhoud zich bevindt: WordPress-sites, GitHub-repos, sociale media, cloudopslag. Platforms passen hun eigen AI-beleid toe, dus hostingonafhankelijkheid geeft je de vrijheid om regels per site in te stellen in plaats van de algemene standaarden te accepteren die door de platforms worden ingesteld (zonder jouw inbreng).
Stap 3: Technische Controles Toepassen
Gebruik je robots.txt-bestand om AI-bots te instrueren hoe ze zich moeten gedragen:
User-agent: GPTBot |
Voeg headers toe (zoals X-Robots-Tag: noai, noimageai) voor extra duidelijkheid. Onthoud wel, naleving is vrijwillig. Deze tags geven je wensen aan, maar dwingen ze niet af.
Stap 4: Publiceer Een Transparant AI-beleid
Maak een eenvoudige pagina waarin je je positie aangeeft. Bijvoorbeeld:
| “AI-systemen mogen deze inhoud niet gebruiken voor training of replicatie.” |
Transparantie bouwt vertrouwen op met klanten en stelt duidelijke grenzen voor toekomstig gebruik.
Stap 5: Monitoren En Aanpassen
Gebruik serverlogboeken of analytics om je mix van bots bij te houden. Bekijk ze elk kwartaal en werk je regels bij als er nieuwe webcrawlers verschijnen.
De Enige AI Ethiek Die Ertoe Doen Zijn Die Van Jou
AI heeft geen ethiek — mensen wel. Wat er toe doet, is niet of je elke crawler geblokkeerd hebt of elk hulpmiddel omarmd hebt; het gaat erom dat je die keuzes bewust hebt gemaakt.
Het web is gebouwd op de vrijheid om te delen, te remixen, te experimenteren en te bouwen zonder toestemming. Echte digitale ethiek beschermt diezelfde geest van zelfbeschikking.
Je bent overgestapt van angst naar controle, van onzekerheid naar eigenaarschap. Bij DreamHost geloven we dat het bezitten van je digitale aanwezigheid niet alleen slim zakendoen is, maar ook hoe je je ethiek behoudt in een wereld die wordt beheerst door algoritmen.
Het open web blijft van jou, als je ervoor kiest om het te bezitten.

