
Wenn Du festgestellt hast, dass Dein Lieblingsillustrator plötzlich von Instagram verschwunden ist, oder dass ein befreundeter Elternteil leise jedes Foto ihres Kindes von Facebook löscht, bildest Du Dir das nicht ein. In den letzten Jahren haben Menschen Inhalte aus dem Netz entfernt, aus Sorge über generative KI.
Das kann viele verschiedene Formen annehmen: Künstler, die ihre Portfolios offline nehmen, nachdem sie entdeckt haben, dass KI-Modelle Gemälde in ihrem eigenen Stil ausspucken, Eltern, die Familienfotos löschen, aus Angst, dass die Gesichter ihrer Kinder in einem Deepfake landen könnten, oder Unternehmen, die den Zugang von KI-Crawlern zu ihrer Website komplett blockieren.
Aufgrund einer Analyse von DreamHost-Kunden haben wir festgestellt, dass ungefähr 5.000 Websites, die unsere Hosting-Dienste nutzen, aktiv einige oder alle AI-Webcrawler blockieren.
Mit anderen Worten, es gibt eine echte und messbare Besorgnis darüber, wie KI-Tools auf die Inhalte, die wir alle online stellen, zugreifen, sie verstehen und verarbeiten.
Es ist nicht so, dass diese Sorgen neu sind.
Das Internet war schon immer ein unübersichtlicher Ort für Zustimmung, Privatsphäre und Eigentum. Was sich geändert hat, ist, dass KI jeden dazu gezwungen hat: Schöpfer, Familien und kleine Geschäftsinhaber gleichermaßen, sich endlich damit auseinanderzusetzen, wie wenig Kontrolle sie darüber haben, was sie online stellen.
Bei DreamHost haben wir schon immer geglaubt, dass das offene Web gedeiht, wenn die Schöpfer kontrollieren, was sie teilen und wie es verwendet wird. Das Web funktioniert am besten, wenn das Eigentum bei den Menschen liegt, die es aufgebaut haben — nicht nur bei den Plattformen, die davon profitieren.
Und das bringt uns zum Kern der Sache. Die eigentliche Frage ist nicht, was KI tun kann — es ist, wer entscheiden darf.
Das eigentliche Problem der KI-Ethik ist nicht die Technologie – es ist der Verlust der Wahlmöglichkeit
KI ist hier nicht der Bösewicht. Die eigentliche Bedrohung ist der „Plattform-Paternalismus“, also Unternehmen, die im Namen aller anderen „ethische“ Entscheidungen treffen. Zum Beispiel haben im Jahr 2024 mehrere große Content-Delivery-Netzwerke (CDNs) und Netzwerkanbieter standardmäßig begonnen, AI-Crawler zu blockieren, mit der Begründung, sie wollten „Kreative schützen“. Das Ergebnis war, dass Millionen von Website-Betreibern aufwachten und feststellten, dass Entscheidungen über ihre Inhalte bereits für sie getroffen worden waren.
Es ist so, als würde dein Vermieter deine Tür zum Schutz deiner Sicherheit abschließen, aber ohne dir die richtigen Schlüssel zu geben. Was als Bequemlichkeit begann, verwandelt sich schnell in einen Verlust an Selbstbestimmung. Wenn Torwächter entscheiden, wie „Schutz“ aussehen soll, schrumpft die individuelle Autonomie.
Das offene Netz wurde auf der Grundlage von innovationsfreier Genehmigung aufgebaut, was bedeutet, dass jeder erstellen, teilen und weiterentwickeln konnte, ohne um Erlaubnis zu bitten. Vermittler, die entscheiden, welche Bots oder Tools auf Inhalte zugreifen können, könnten diese Freiheit um Jahrzehnte zurückdrehen.
Deshalb setzt sich DreamHost für Infrastrukturunabhängigkeit ein: Wenn Du Deinen eigenen Inhalt hostest, kann niemand Deine Regeln neu schreiben. Deinen Stack zu besitzen bedeutet, Deine Richtlinien zu besitzen, egal ob Du AI-Crawler willkommen heißt oder sie vollständig ausschließt. Die Ethik kommt nicht aus dem Code; sie ergibt sich aus der Wahl.

„KI Benötigt Deine Daten“ Und Andere Mythen
Was hält Kreative davon ab, die Kontrolle zurückzugewinnen? Oft sind es Fehlinformationen, wie diese verbreiteten Mythen rund um AI. Diese Mythen sind populär, weil der Einsatz von AI im Internet und den Werkzeugen, die wir täglich verwenden, stark zugenommen hat.
Mythos #1: „KI Benötigt Deine Daten, Um Fortzuschreiten“
Niemand schuldet gewinnorientierten KI-Unternehmen ihre Arbeit. Lizenzierte und einwilligungsbasierte Modelle existieren; zum Beispiel trainiert Adobe Firefly lizenzierte Inhalte mit Erlaubnis und öffentliche Werke ohne Urheberrechte. Die Zukunft der KI muss nicht auf Diebstahl basieren. Sie kann stattdessen auf Zustimmung basieren.
Mythos #2: „Wenn Du Dich Abmeldest, Wirst Du Verschwinden“
Sich abzumelden kann deine Sichtbarkeit in von KI generierten Zusammenfassungen oder Such-Snippets einschränken, aber es wird dich nicht aus dem Web löschen. Denke daran, wie es wäre, sich 2005 von Google abzumelden. Du würdest Reichweite verlieren, nicht Relevanz, besonders wenn dein Publikum dich weiterhin direkt sucht.
Es mag zwar nicht praktisch für jeden sein, der auf Reichweite angewiesen ist, um sein Publikum oder Kundenstamm zu vergrößern (obwohl wir immer noch keine genauen Daten darüber haben, wie viel organischer Traffic tatsächlich von GEO kommt), für einige Schöpfer ist Sichtbarkeit nicht den unfreiwilligen Einsatz wert. Der Schlüssel ist, dass sie entscheiden dürfen.
Mythos #3: „AI-Scraping ist einfach, wie das Internet funktioniert“
Indizierung zur Entdeckung und Aneignung zum Training sind nicht dasselbe.
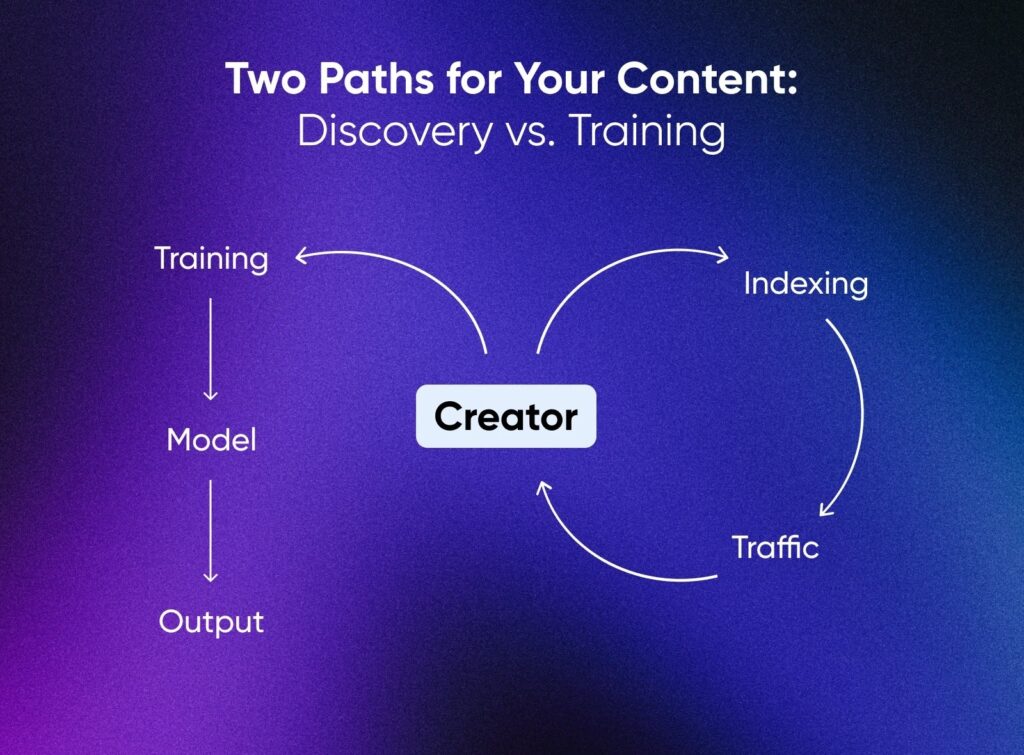
Indizierung bringt Menschen auf deine Seite. Training ersetzt dich durch eine statistische Kopie. Verlage wie die Associated Press und Axel Springer beweisen, dass es einen Mittelweg gibt, indem sie ihre Inhalte für das Modelltraining lizenzieren mit Anerkennung und Vergütung.
Auch gute Absichten können nach hinten losgehen. Letztendlich erfordern ausgeglichene Ethik eine informierte Zustimmung.
Sich Abmelden vs. Offen Bleiben: Die Wahren Kompromisse
Jede KI-Haltung – von vollständiger Offenheit bis zum totalen Opt-out – bringt echte Opportunitätskosten mit sich. Wo du stehst, hängt davon ab, was dir am wichtigsten ist, von Sichtbarkeit über Kontrolle bis hin zu Nachhaltigkeit und Autonomie.
DreamHosts interne Daten zeigen, dass etwa 71,5% des gesamten Web-Traffics mittlerweile von Bots und nicht von Menschen stammen. Das bedeutet, dass die meisten Anfragen an deine Website automatisiert sind: einige davon sind nützlich (wie Suchindexierung oder Überwachung der Betriebszeit), andere weniger. Das Verwalten, welche Crawler Du zulässt und welche Du blockierst, ist ein Ausdruck ethischer Nachhaltigkeit.
Unten sind vier gängige Ansätze, die Ersteller beim Zugriff auf KI und Training verwenden und wie jeder davon verschiedene Faktoren des offenen Webs beeinflusst, damit Du die Kompromisse visualisieren kannst, bevor Du Deine Position festlegst.
| Vollständig Offen | Selektive Lizenzierung | Blockiere KI-Training | Vollständig Aus KI Optiert | |
| Sichtbarkeit und Reichweite | Am höchsten; KI-Zusammenfassungen und Suchmaschinen können deine Arbeit überall zeigen. | Mäßig; die Exposition ist auf Partner beschränkt, die Inhalte lizenzieren. | Niedrig; aus KI-Ergebnissen ausgeschlossen, aber noch in traditionellen Suchen sichtbar. | Keine; sowohl von KI als auch von vielen Entdeckungs-Crawlern blockiert. |
| Kontrolle und Zustimmung | Minimal; Plattformen entscheiden für dich. | Hoch; durch explizite Lizenzbedingungen geregelt. | Stark; du definierst Berechtigungen über robots.txt und HTTP-Header. | Absolut; jeglicher automatisierter Zugriff ist verboten. |
| Attribution | Niedrig; die meisten KI-Modelle zitieren keine Quellen. | Hoch; Zuschreibung und Lizenzen sind in Verträgen festgelegt. | Mittel; konforme Crawler können dich dennoch nennen. | Keine; Inhalte werden nie referenziert. |
| Umweltauswirkung | Mäßig; trägt zur breiten Modellbildung und Indexierungslast bei. | Mäßig; begrenzte, lizenzierte Nutzung reduziert doppeltes Training. | Mäßig-niedrig; weniger schwere Crawler, gezielterer Verkehr. | Niedrig; die geringsten externen Anfragen und Datentransfers. |
| Risiko von Missbrauch oder Kopieren | Hoch; Stil oder Text können frei repliziert werden. | Mäßig; rechtliche Schritte über Lizenzbedingungen möglich. | Niedrig; konforme Bots werden abgeschreckt, rogue Bots dennoch möglich. | Sehr niedrig; minimale Oberfläche zum Scrapen. |
Jeder Weg hat seine Berechtigung. Vermarkter und Kleinunternehmer sind oft auf Sichtbarkeit angewiesen, um ihr Publikum zu vergrößern, während Illustratoren, Journalisten und Lehrer vielleicht Eigentum und Zustimmung über alles stellen. Das Web lebt von Vielfalt, und die ethische Beteiligung an KI sollte diese Vielfalt an Zielen widerspiegeln.
Es gibt keine universell richtige Antwort: nur informierte Kompromisse, die mit deinen Prinzipien und deiner Art, online Geld zu verdienen, übereinstimmen. Die richtige Haltung ist nicht für alle gleich, aber du solltest deine Haltung bewusst wählen und sie mit Handlungen untermauern. Welchen Weg du auch wählst, mache ihn bewusst.
Wie Du Deine KI-Position Bestimmst
Ethik zählt nur, wenn sie praktiziert wird. Hier ist, wie Du Theorie in Aktion umsetzen und definieren kannst, wie AI mit Deiner Arbeit interagiert.
Schritt 1: Kläre Deine Ziele
Beginne damit, das zu bewerten, was für Dich am wichtigsten ist: Sichtbarkeit, Einnahmen, Nachhaltigkeit, Kontrolle.
Ein kleines Unternehmen, das Reichweite anstrebt, kann einen breiteren Einsatz von KI tolerieren, während ein Illustrator, der Originalität bewahren möchte, dies möglicherweise nicht tut. Unterschiedliche Ziele = unterschiedliche Grenzen.

Schritt 2: Überprüfe Deinen Digitalen Fußabdruck
Liste, wo deine Inhalte gespeichert sind: WordPress-Seiten, GitHub Repos, soziale Medien, Cloud-Speicher. Plattformen wenden ihre eigenen KI-Richtlinien an, daher bietet das unabhängige Hosting die Freiheit, Regeln pro Seite festzulegen, anstatt pauschale Standardeinstellungen der genutzten Plattformen zu akzeptieren (ohne deine Mitwirkung).
Schritt 3: Technische Kontrollen Anwenden
Verwende deine robots.txt-Datei, um AI-Bots das Verhalten zu signalisieren:
User-agent: GPTBot |
Füge Header hinzu (wie X-Robots-Tag: noai, noimageai) für zusätzliche Klarheit. Denke daran, die Einhaltung ist freiwillig. Diese Tags signalisieren deine Wünsche, setzen sie jedoch nicht durch.
Schritt 4: Veröffentliche Eine Transparente AI-Richtlinie
Erstelle eine einfache Seite, die Deine Position darlegt. Zum Beispiel:
| „KI-Systeme dürfen diese Inhalte nicht zum Trainieren oder Replizieren verwenden.“ |
Transparenz schafft Vertrauen bei den Kunden und setzt klare Grenzen für die zukünftige Nutzung.
Schritt 5: Überwachen und Anpassen
Verwende Serverprotokolle oder Analysen, um Deinen Bot-Mix zu verfolgen. Überprüfe dies vierteljährlich und aktualisiere Deine Regeln, wenn neue Crawler auftauchen.
Die Einzigen KI-Ethikrichtlinien, Die Zählen, Sind Deine Eigenen
KI hat keine Ethik — Menschen haben sie. Es kommt nicht darauf an, ob Du jeden Crawler blockiert oder jedes Tool genutzt hast; es geht darum, dass Du diese Entscheidungen bewusst getroffen hast.
Das Web wurde auf der Freiheit aufgebaut, zu teilen, zu remixen, zu experimentieren und ohne Erlaubnis zu bauen. Wahre digitale Ethik schützt genau diesen Geist der Selbstbestimmung.
Du bist von Angst zu Kontrolle und von Unsicherheit zu Besitz übergegangen. Bei DreamHost glauben wir, dass das Besitzen Deiner digitalen Präsenz nicht nur kluges Geschäft ist, sondern auch, wie Du Deine Ethik in einer von Algorithmen beherrschten Welt bewahrst.
Das offene Web bleibt deins, wenn du dich entscheidest, es zu besitzen.

