
Kiedy Claude Sonnet 4.5 został uruchomiony we wrześniu 2025 roku, spowodował problemy z wieloma istniejącymi komendami. Nie dlatego, że wersja była błędna. Ale ponieważ Anthropic przebudował sposób, w jaki Claude wykonuje instrukcje.
Wcześniejsze wersje domyślały się twoich intencji i rozszerzały niejasne prośby. Claude 4.x traktuje cię dosłownie i robi dokładnie to, o co prosisz, nic więcej.

Aby zrozumieć nowe metody, oceniliśmy 25 popularnych technik inżynierii wstępnej względem dokumentacji Anthropic, eksperymentów społeczności i rzeczywistego wdrażania, aby odkryć, które wskazówki faktycznie lepiej działają z Claude 4.x. Te pięć technik
Co Zmieniło Się W Claude 4.5, Że Zepsuło Istniejące Wskazówki?
Modele Claude 4.5 priorytetyzują precyzyjne instrukcje nad „pomocne” zgadywanie.
Poprzednie wersje wypełniałyby luki za ciebie. Jeśli poprosiłeś o „panel sterowania,” zakładano, że chcesz wykresy, filtry i tabele danych.
Claude 4.5 traktuje cię dosłownie. Jeśli poprosisz o panel sterowania, może dać ci pustą ramkę z tytułem, ponieważ nie poprosiłeś o resztę.
Anthropic wyraźnie stwierdza: „Klienci, którzy oczekują zachowań 'ponad standard’, mogą musieć bardziej wyraźnie zażądać tych zachowań.”
Więc musimy przestać traktować model jak magiczną różdżkę i zacząć traktować go jak dosłownie myślącego pracownika.
Bez umiejętności projektowania. Bez kreatorów. Bez kłopotów. Tylko rezultaty.
Rozpocznij
5 Sprawdzonych Technik, Które Zmierzalnie Poprawiają Wydajność Claude’a
Na podstawie naszych badań, te pięć technik przyniosło konsekwentnie zauważalne ulepszenia w wydajności Claude w zadaniach, które przed nim postawiliśmy.
1. Strukturyzowane I Oznaczone Komunikaty
System Claude Sonnet 4.5 używa strukturalnych poleceń wszędzie. Simon Willison przeanalizował systemowe polecenia i znalazł sekcje otoczone tagami jak <behavior_instructions>, <artifacts_info> oraz <knowledge_cutoff>.
Tak naprawdę, możesz edytować „Styles”, aby zobaczyć strukturalne polecenia Anthropic w działaniu.
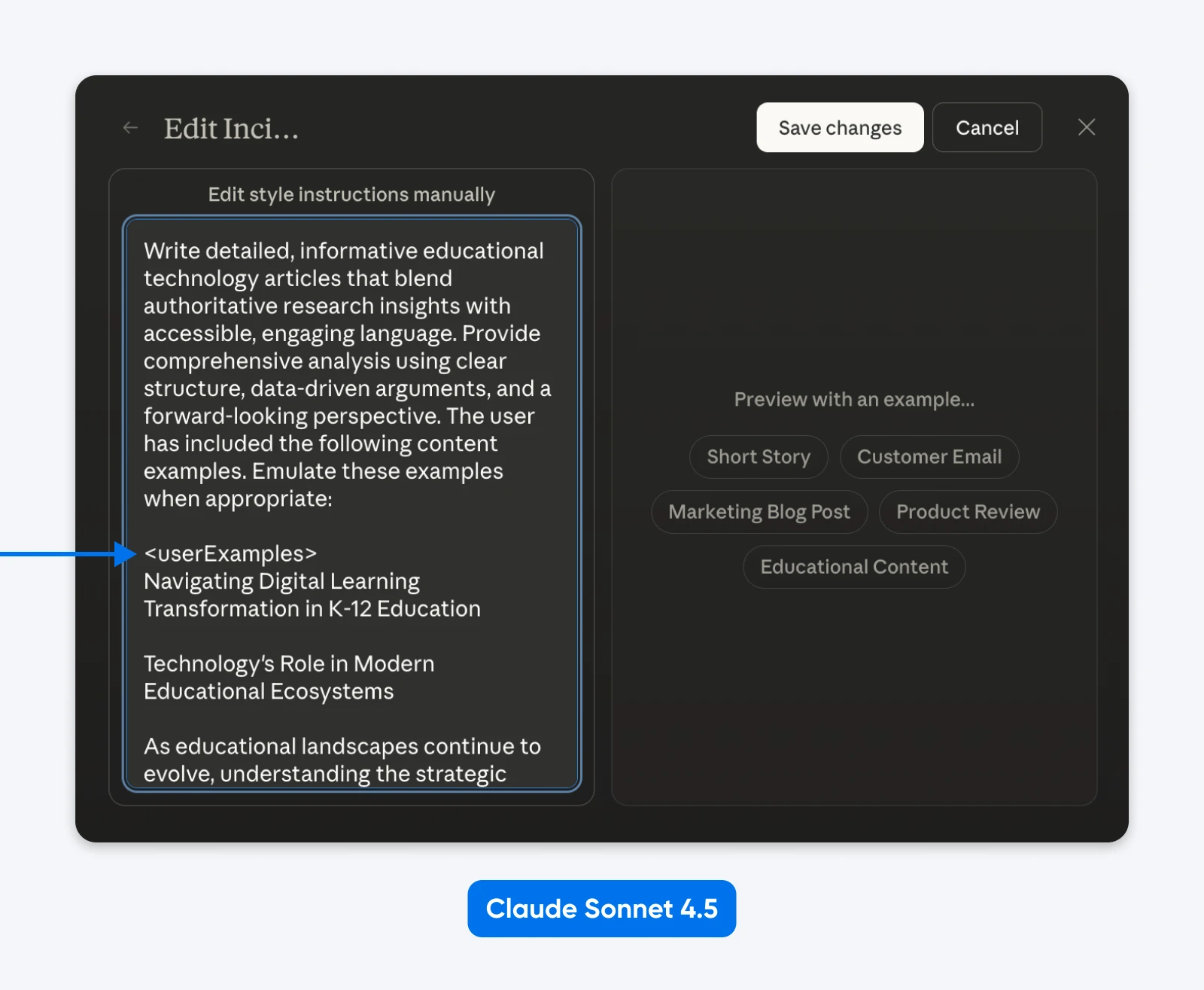
Co możemy wywnioskować, to to, że Claude został przeszkolony na strukturalnych poleceniach i wie, jak je analizować. XML działa świetnie, tak samo jak JSON lub inne oznaczone polecenia.
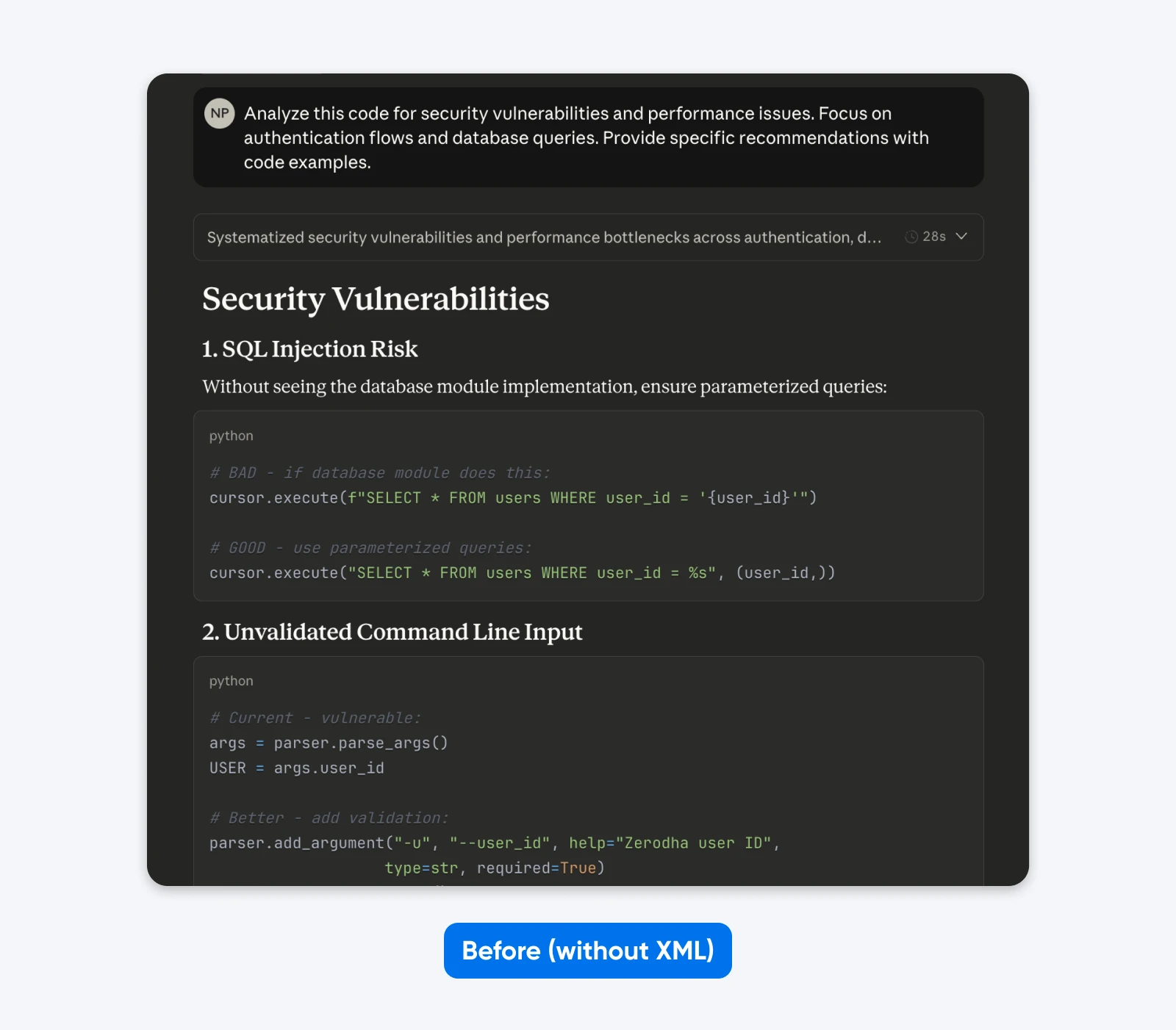
Przed:
Przeanalizuj ten kod pod kątem podatności na zagrożenia bezpieczeństwa oraz problemów z wydajnością. Skoncentruj się na przepływach uwierzytelniania i zapytaniach do bazy danych. Podaj konkretne rekomendacje wraz z przykładami kodu.
Po (ustrukturyzowany monit):
<task>Przeanalizuj dostarczony kod pod kątem bezpieczeństwa i wydajności</task>
<focus_areas>
– Przepływy uwierzytelniania
– Optymalizacja zapytań do bazy danych
</focus_areas>
<code>
[twój kod tutaj]
</code>
<output_requirements>
– Identyfikuj konkretne podatności wraz z oceną ich powagi
– Podaj przykłady poprawionego kodu
– Priorytetyzuj rekomendacje według wpływu na biznes
</output_requirements>
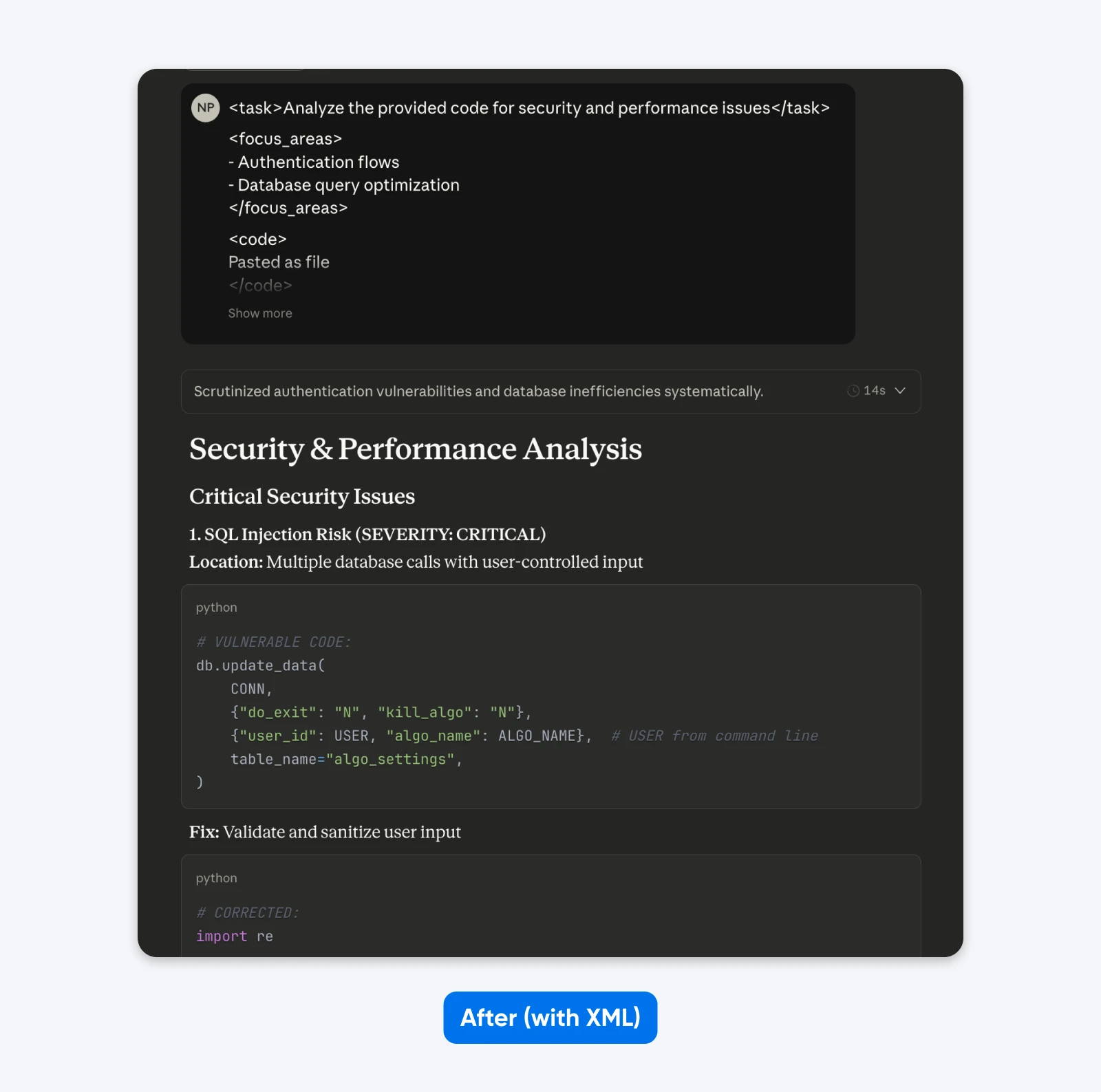
Jeśli porównasz te wyniki, zauważysz, że sformułowanie strukturalne daje wynik z większym kontekstem, aby pomóc ci zrozumieć i naprawić problemy z bezpieczeństwem w kodzie. Wyjaśnia problem, mówi, co robi naprawa, a następnie dostarcza kod naprawczy.
Alternatywne Formaty, Które Działają:
JSON:
{
"task": "Przejrzyj kod uwierzytelniania",
"focus_areas": ["Hashowanie haseł", "Bezpieczeństwo sesji", "Iniekcja SQL"],
"context": "Aplikacja medyczna, wymagane HIPAA",
"output_format": "Ryzyko, wpływ, naprawa, powaga na podatność"
}
Wyczyść Nagłówki:
ZADANIE: Przegląd kodu uwierzytelniania pod kątem podatności
SKUPIENIE: Hashowanie haseł, sesje, iniekcja SQL
KONTEKST: Aplikacja zdrowotna wymagająca zgodności z HIPAA
FORMAT WYJŚCIOWY: Ryzyko → Wpływ na HIPAA → Naprawa → Waga
Wszystkie trzy działają równie dobrze.
Kiedy strukturyzowane polecenia działają najlepiej:
- Różne komponenty polecenia (zadanie, kontekst, przykłady, wymagania)
- Długie wejścia (10 000+ tokenów kodu lub dokumentów)
- Sekwencyjne przepływy pracy z wyraźnymi etapami
- Zadania wymagające wielokrotnego odwoływania się do konkretnych sekcji
Kiedy pominąć strukturyzowane monity: Proste pytania, gdzie zwykły tekst wystarcza.
Ocena efektywności: 9/10 dla zadań złożonych, 5/10 dla prostych zapytań.
2. Rozszerzone Myślenie Dla Skomplikowanych Problemów
Rozszerzone myślenie przynosi ogromne korzyści w skomplikowanych zadaniach wymagających rozumowania, jednak ma jedną główną wadę: prędkość.
Ogłoszenie Anthropic Claude 4 wykazało znaczne wzrosty wydajności, gdy włączone było rozszerzone myślenie. Na zawodach matematycznych AIME 2025, wyniki znacznie się poprawiły.
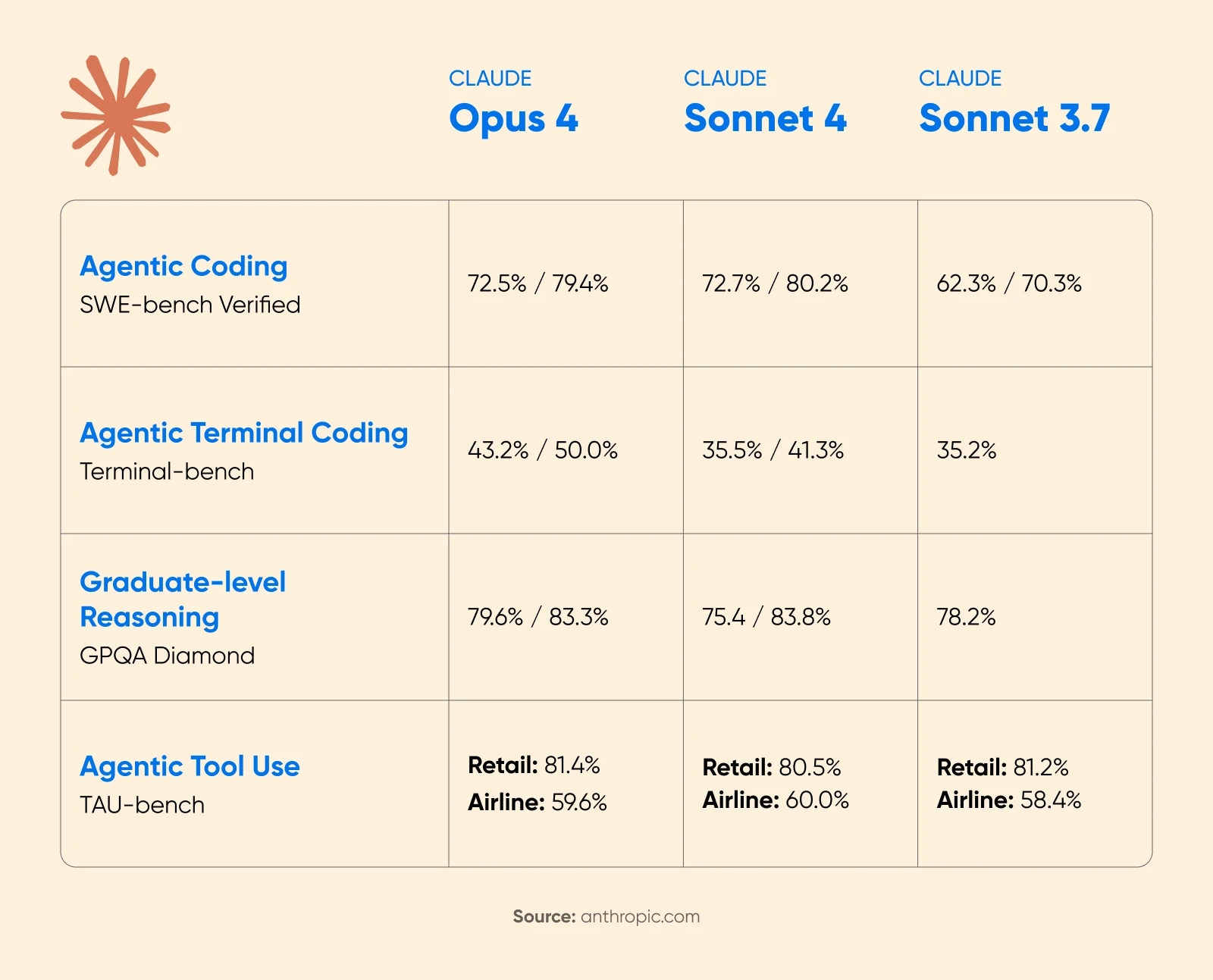
Cognition AI zgłosiła 18% wzrost wydajności planowania z Sonnet 4.5, nazywając to „największym skokiem, jaki widzieliśmy od czasu Claude Sonnet 3.6”.
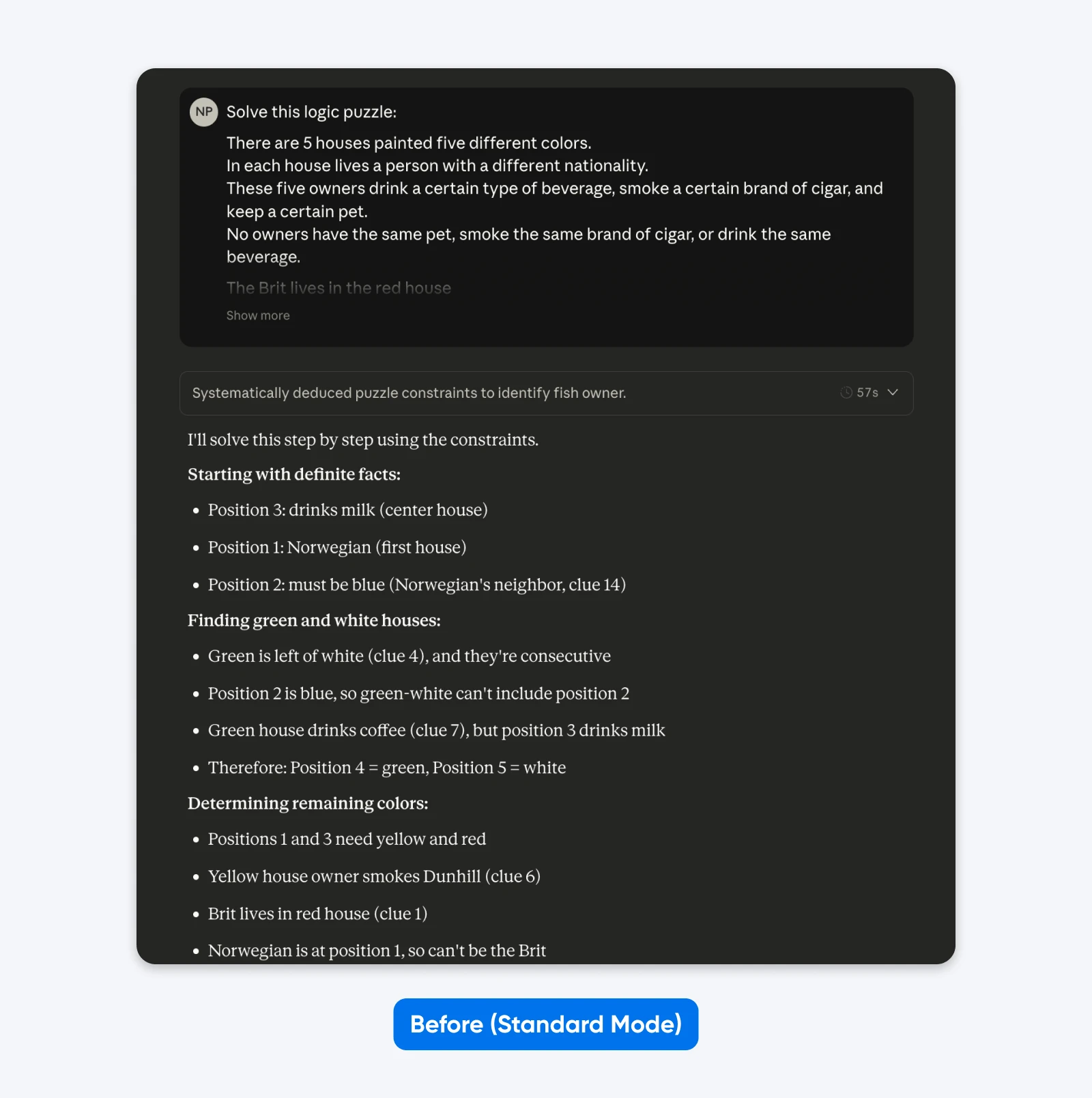
Przed (Standardowy Tryb):
Rozwiąż tę łamigłówkę logiczną: Pięć domów w rzędzie, każdy w innym kolorze…
After (with Extended Thinking):
Zrozum systematycznie logikę tej łamigłówki. Przeanalizuj ograniczenia krok po kroku, sprawdzając każdą możliwość zanim wyciągniesz wnioski.
Pięć domów w rzędzie, każdy w innym kolorze…
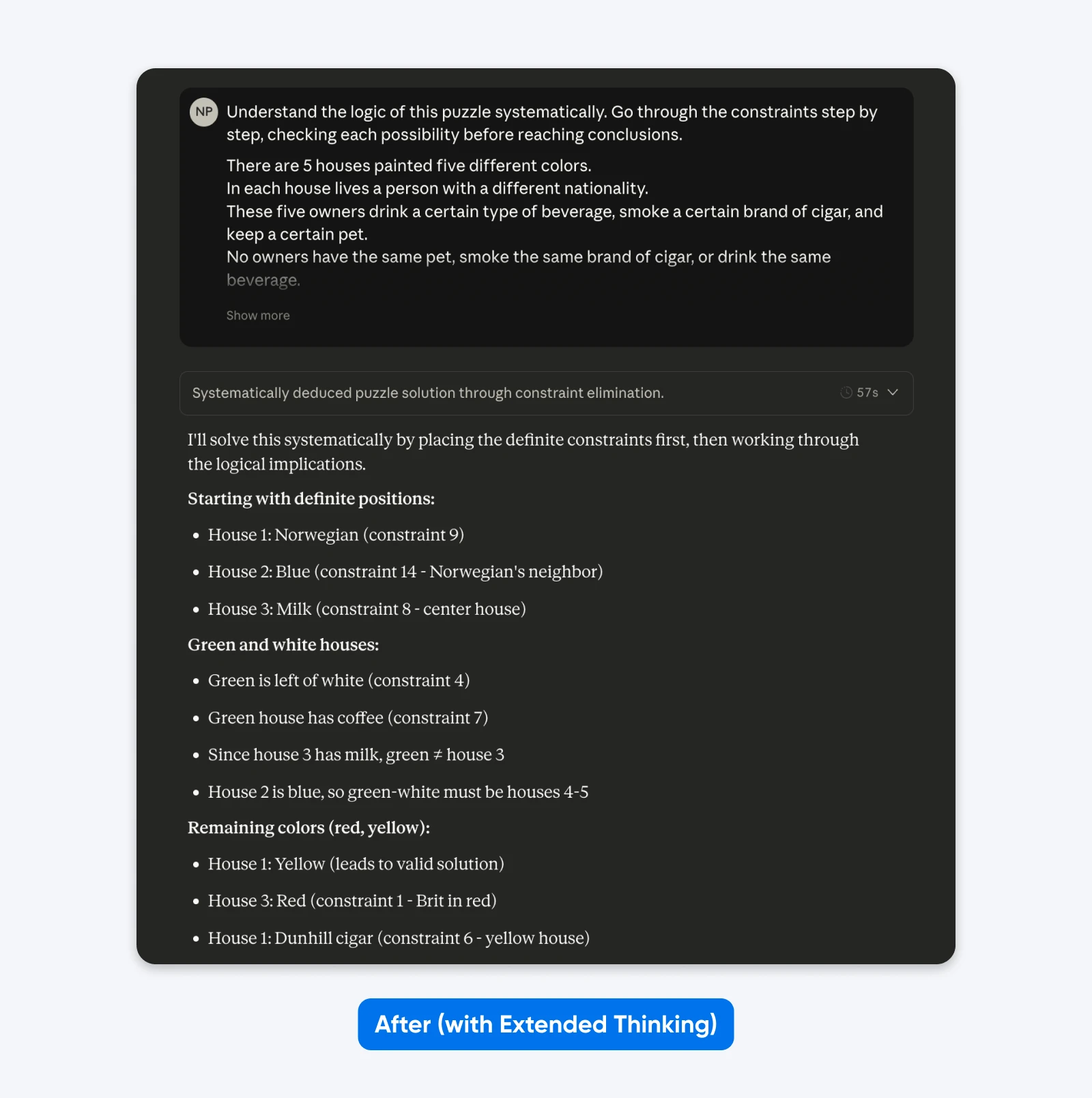
Nie zauważysz dużej różnicy przy prostych poleceniach, jak to powyżej. Jednak przy skomplikowanych, niszowych problemach (niestandardowe bazy kodów, wieloetapowe planowanie logiczne) różnica staje się wyraźna.
Kiedy rozszerzone rozwiązanie działa:
- Wieloetapowe planowanie logiczne wymagające weryfikacji
- Rozumowanie matematyczne z wieloma ścieżkami rozwiązania
- Złożone zadania programistyczne obejmujące wiele plików
- Sytuacje, gdzie poprawność jest ważniejsza niż szybkość
Kiedy Pominąć: Szybkie iteracje, proste zapytania, pisanie kreatywne, zadania związane z czasem
Ocena skuteczności: 10/10 dla skomplikowanych rozumowań, 3/10 dla prostych zapytań.
3. Bądź Bezpośredni W Kwestii Wymagań
Modele Claude 4 zostały przeszkolone do precyzyjniejszego wykonywania instrukcji niż poprzednie generacje.
Dokumentacja Anthropic mówi:
„Modele Claude 4.x dobrze reagują na jasne, wyraźne instrukcje. Bycie konkretnym co do oczekiwanego wyniku może pomóc w uzyskaniu lepszych rezultatów. Klienci, którzy oczekują zachowań 'ponad standard’ od poprzednich modeli Claude, mogą musieć bardziej wyraźnie żądać tych zachowań w nowszych modelach.”
Dokumentacja również zauważa, że Claude jest na tyle inteligentny, aby generalizować z wyjaśnień, gdy dostarczasz kontekstu dla istnienia reguł, zamiast po prostu wydawać polecenia. Oznacza to, że dostarczenie uzasadnienia pomaga modelowi poprawnie stosować zasady w przypadkach brzegowych, które nie są wyraźnie omówione.
Testy przeprowadzone przez 16x Eval wykazały, że zarówno Opus 4, jak i Sonnet 4 uzyskały ocenę 9,5/10 w zadaniach TODO, gdy instrukcje jasno określały wymagania, format i kryteria sukcesu. Modele wykazały imponującą zwięzłość i zdolności do przestrzegania instrukcji.
Przed (niejawne oczekiwania):
Stwórz panel sterowania analityką.
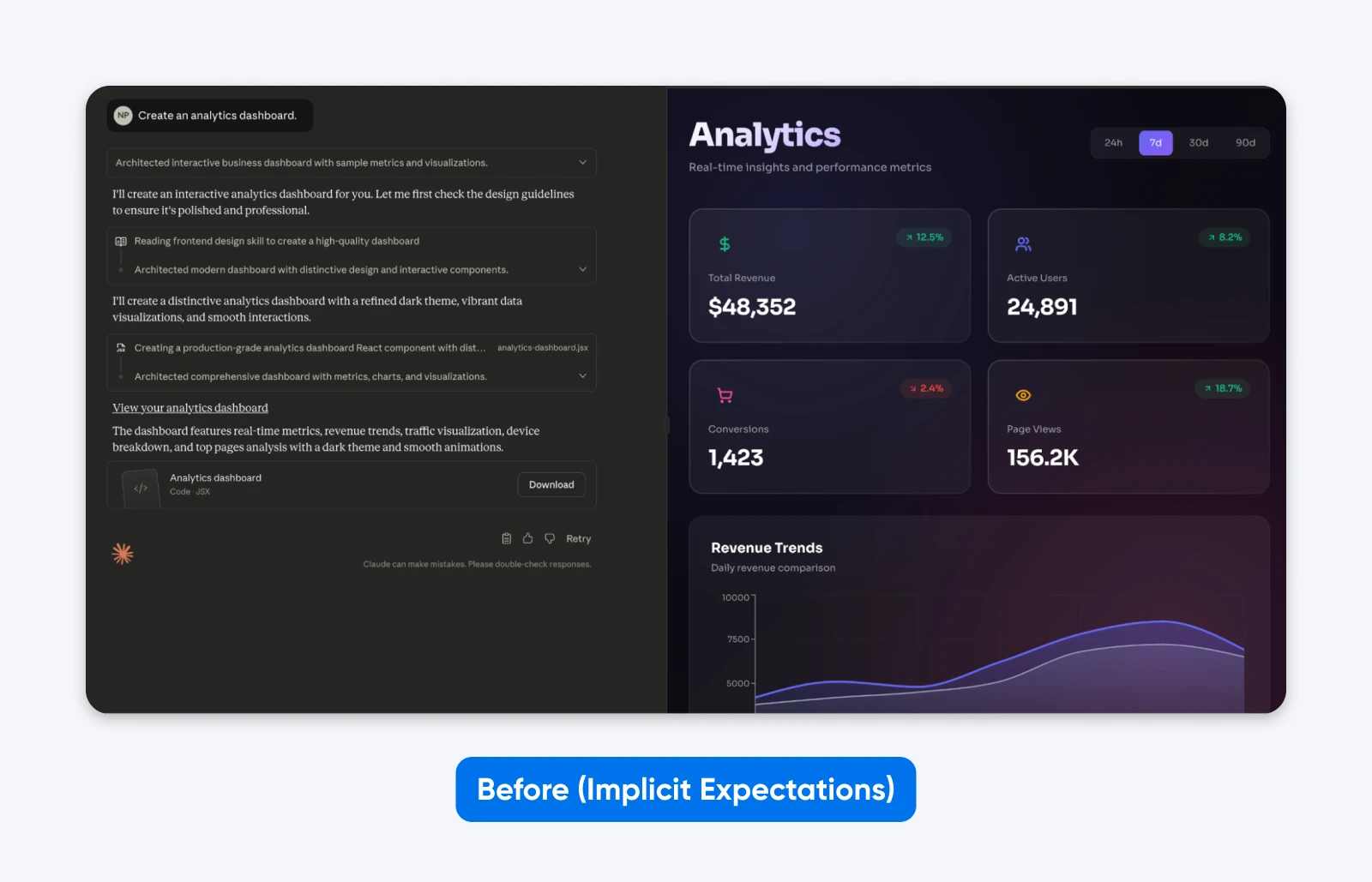
Zauważysz, że ten wynik jest DOKŁADNIE taki, jakiego oczekiwaliśmy. Chociaż Claude pozwolił sobie na odrobinę swobody w estetyce, to nie wpływa to na funkcjonalność.
Po (wymagania szczegółowe):
Utwórz panel sterowania analityki. Dołącz jak najwięcej odpowiednich funkcji i interakcji. Przejdź poza podstawy, aby stworzyć pełnoprawną implementację z wizualizacją danych, możliwościami filtrowania i funkcjami eksportu.
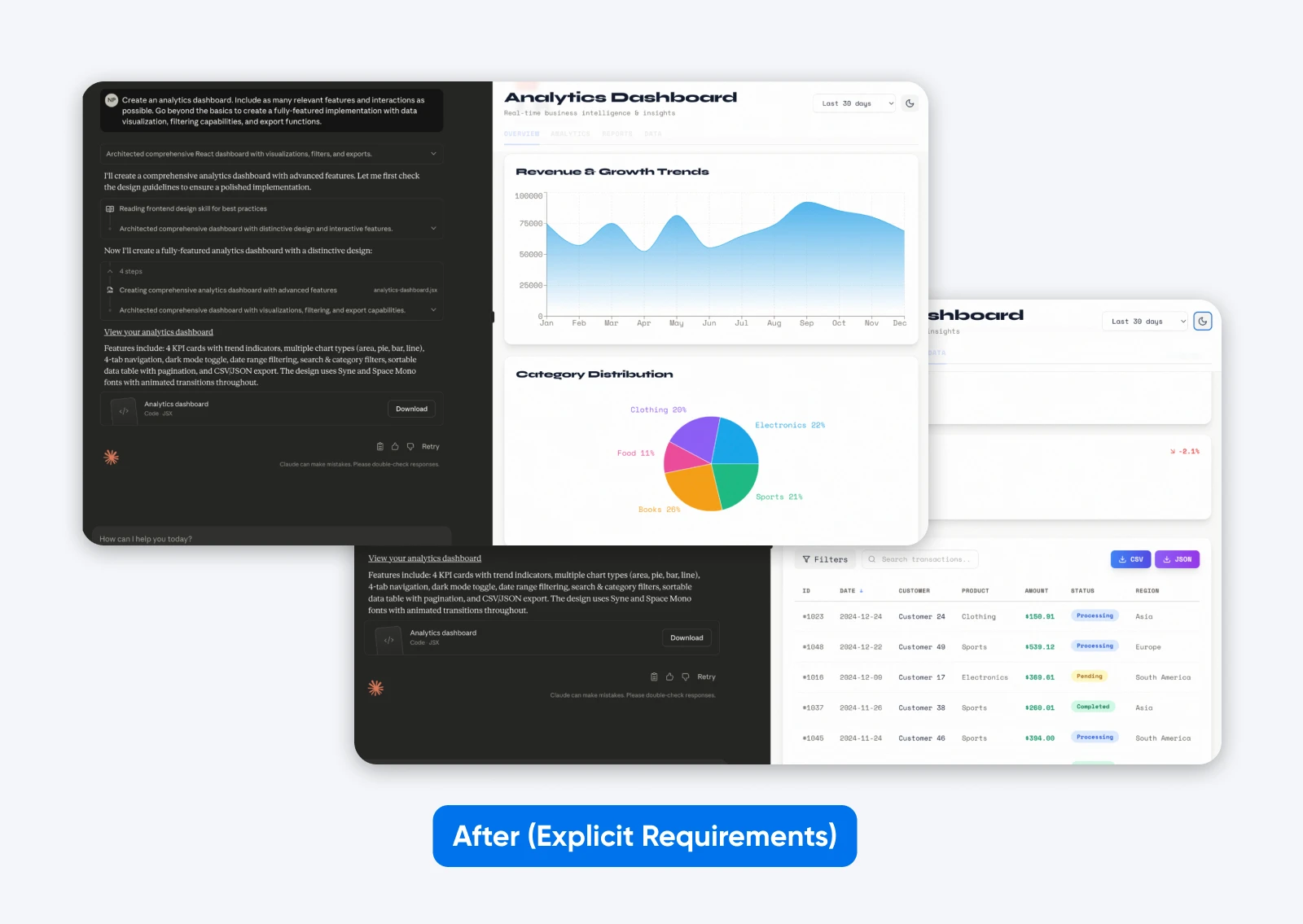
Ten drugi wynik z bardziej szczegółowym opisem ma więcej funkcji, panel sterowania oparty na przykładowych danych, które są prezentowane zarówno graficznie, jak i w formie tabelarycznej, oraz zawiera zakładki do oddzielania wszystkich danych.
To właśnie daje specyfika najnowszego Claude’a.
Aby jeszcze bardziej wyjaśnić tę kwestię, oto kolejny przykład pokazujący, jak kontekst poprawia przestrzeganie instrukcji:
Przed (komenda bez kontekstu):
NIGDY nie używaj wielokropka w swojej odpowiedzi.
Po (instrukcja motywowana kontekstem):
Twoja odpowiedź będzie odczytywana przez syntezator mowy, dlatego unikaj używania wielokropków, ponieważ syntezator nie będzie wiedział, jak je wymówić.
Podstawowe zasady dotyczące jasnych instrukcji:
- Zdefiniuj, co oznacza „kompleksowe” dla Twojego konkretnego zadania: Nie zakładaj, że Claude wywnioskuje standardy jakości.
- Wyjaśnij, dlaczego istnieją zasady, zamiast po prostu je wymieniać: Claude lepiej generalizuje z motywowanych instrukcji.
- Wyraźnie określ format wynikowy: Poproś o „akapity prozy” zamiast liczyć na to, że Claude nie zastosuje domyślnie punktów.
- Podaj konkretne kryteria sukcesu: Jak wygląda zakończenie zadania?
Ocena efektywności: 9/10 we wszystkich typach zadań.
4. Pokaż Przykłady Tego, Czego Chcesz
Stymulowanie za pomocą kilku przykładów dostarcza Claude przykładowe wejścia i wyjścia, demonstrujące pożądane zachowanie. To działa, ale tylko gdy przykłady są wysokiej jakości i odpowiednie do zadania, a wpływ znacznie różni się w zależności od przypadku użycia.
Oficjalne wskazówki Anthropic podkreślają:
„Modele Claude 4.x zwracają szczególną uwagę na detale oraz przykłady jako część ścisłego przestrzegania instrukcji. Upewnij się, że Twoje przykłady są zgodne z zachowaniami, które chcesz promować, i minimalizują te, których chcesz unikać.”
Anthropic rekomenduje 3-5 różnorodnych, istotnych przykładów dla skomplikowanych zadań. Więcej przykładów równa się lepszej wydajności.
Oto przykład tego, jak to wygląda w praktyce:
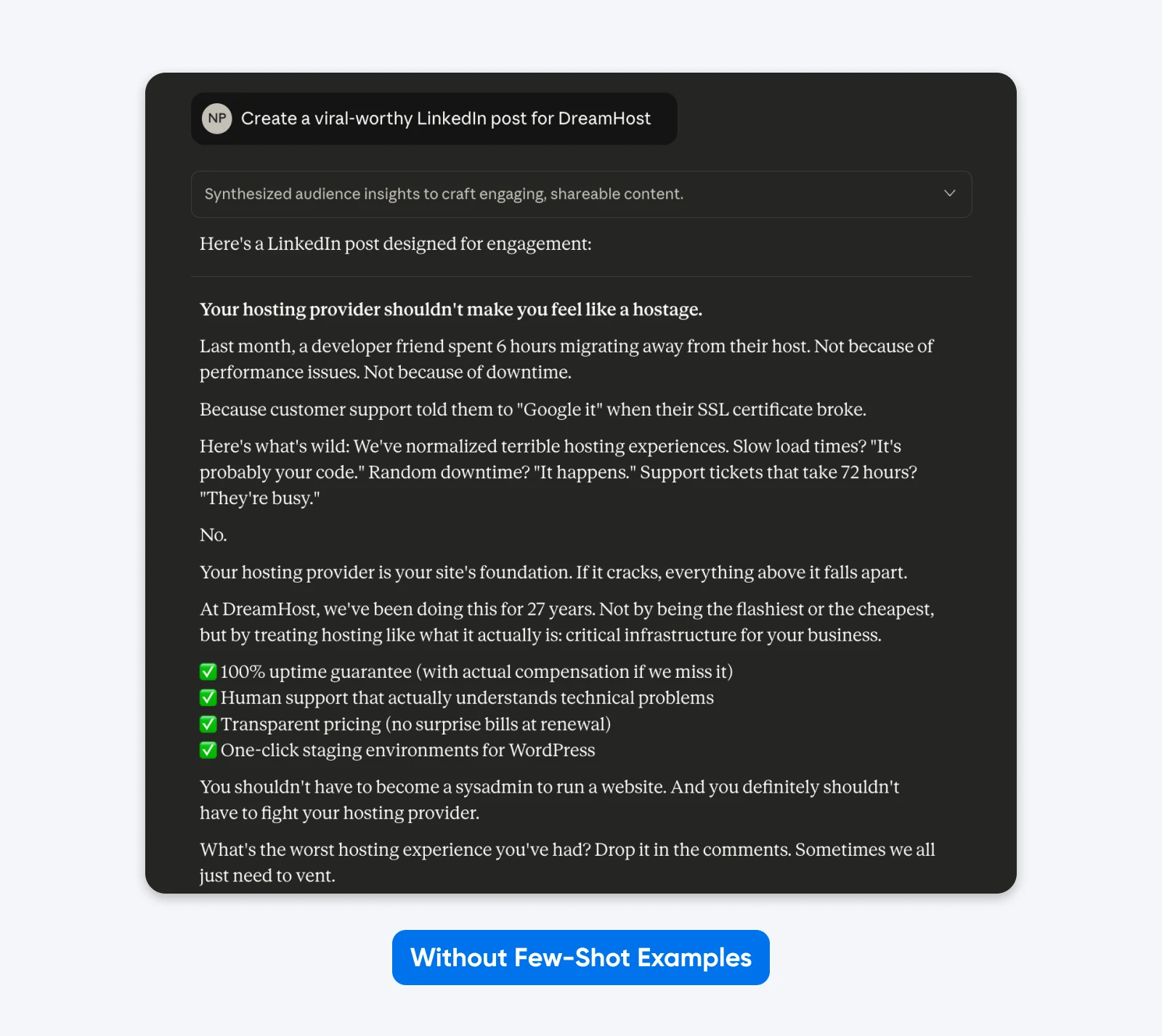
Tutaj Claude pozwolił sobie na kreatywne podejście do formatu, użycia emoji, treści i tonu. Ogólny korporacyjny język
Dodawanie przykładów działa, ponieważ pokazują one zamiast opowiadać, jednocześnie wyjaśniając subtelne wymagania, które trudno wyrazić tylko poprzez opis.
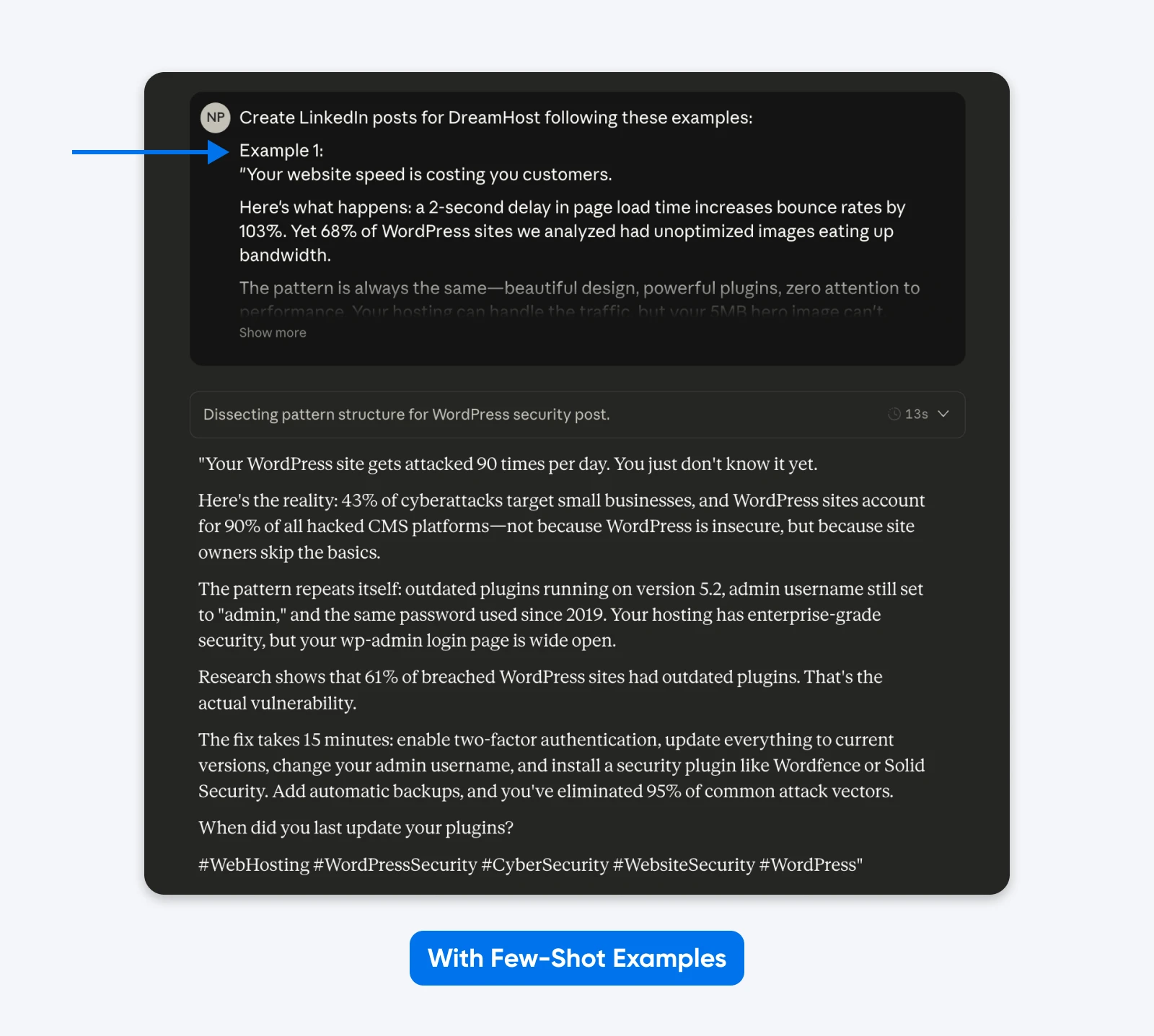
Ten wynik przylega ściślej do przykładów, które podałem w poleceniu. Możesz użyć metody przykładów z kilku prób, aby uzyskać posty na LinkedIn podobne do twoich najlepiej działających. Akademicka praca na temat projektowania maszyny stanów skończonych (FSM) wykazała, że strukturalne przykłady osiągnęły 90% wskaźnik sukcesu w porównaniu z instrukcjami bez przykładów.
Jak Zaimplementować:
- Owijaj przykłady w tagi <example>, grupowane w tagach <examples>
- Umieszczaj przykłady wcześnie w pierwszej wiadomości użytkownika
- Użyj 3-5 różnorodnych przykładów dla złożonych zadań
- Dopasuj każdy szczegół w przykładach do oczekiwanego wyniku (Claude 4.x replikuje konwencje nazewnictwa, styl kodowania, formatowanie, interpunkcję)
- Unikaj nadmiarowych przykładów
Kiedy Przykłady Działają Najlepiej:
- Formatowanie danych wymagające precyzyjnej struktury
- Złożone wzorce kodowania wymagające specyficznych podejść
- Zadania analityczne demonstrujące metody rozumowania
- Wynik wymagający konsekwentnego stylu i konwencji
Kiedy pominąć: Proste zapytania, gdy wystarczą instrukcje, lub gdy chcesz, aby Claude działał według własnego uznania.
Ocena Efektywności: 10/10 za formatowanie zadań, 6/10 za proste zapytania.
5. Umieść Kontekst Przed Pytaniem
Claude ma okno kontekstowe 200 000 tokenów (w niektórych przypadkach do 1 miliona) i rozumie zapytania umieszczone gdziekolwiek w kontekście. Jednak dokumentacja Anthropic zaleca umieszczanie długich dokumentów (20 000+ tokenów) na początku wskazówek, przed zapytaniami.
Testy wykazały, że poprawia to jakość odpowiedzi nawet o 30% w porównaniu z porządkowaniem zapytania jako pierwszego, szczególnie przy skomplikowanych wejściach z wielu dokumentów.
Dlaczego? Mechanizmy uwagi Claude’a przywiązują większą wagę do treści znajdujących się na końcu poleceń. Umieszczenie pytania po kontekście pozwala modelowi odwoływać się do wcześniejszego materiału podczas generowania odpowiedzi.
Przed (najpierw zapytanie):
Analizuj kwartalne wyniki finansowe i identyfikuj kluczowe trendy.
[20,000 tokenów danych finansowych]
Po (kontekst na pierwszym miejscu):
[20 000 tokenów danych finansowych]
Na podstawie kwartalnych danych finansowych przedstawionych powyżej, przeanalizuj wyniki i zidentyfikuj kluczowe trendy w wzroście przychodów, zwiększeniu marży oraz efektywności operacyjnej. Skup się na praktycznych wnioskach dla podejmowania decyzji przez kierownictwo.
Kiedy to ma znaczenie: Analiza długiego kontekstu, gdzie Claude musi szeroko odnosić się do wcześniejszych materiałów.
Kiedy Pominąć: Krótkie polecenia poniżej 5,000 tokenów.
Ocena efektywności: 8/10 dla zadań o długim kontekście, 4/10 dla krótkich poleceń.
Jakie Techniki Pobudzania Już Nie Działają: Obalanie Popularnych Mitów
Zmiany w Claude 4.5 unieważniły kilka popularnych technik, które działały z wcześniejszymi modelami.
1. Słowa Pisane Wielkimi Literami (ALL CAPS, “MUST,” “ALWAYS”)
Pisanie wielkimi literami już nie gwarantuje zgodności. Analiza Chrisa Tysona wykazała, że Claude obecnie przywiązuje większą wagę do kontekstu i logiki niż do nacisku.
Jeśli napiszesz „NIGDY nie zmyślaj danych”, ale kontekst sugeruje potrzebę szacunku, Claude 4.5 stawia na pierwszym miejscu logiczną potrzebę ponad twoje polecenie pisane wielkimi literami.
Użyj logiki warunkowej zamiast tego:
- Nieprawidłowo: ZAWSZE używaj dokładnych liczb!
- Prawidłowo: Jeśli dostępne są zweryfikowane dane, używaj precyzyjnych liczb. Jeśli nie, podawaj zakresy i oznacz je jako szacunki.
2. Instrukcje Ręcznego Łańcucha Myślenia
Mówienie modelowi, aby „myślał krok po kroku” marnuje tokeny, gdy używa się trybu Rozszerzonego Myślenia.
Kiedy włączysz Rozszerzone Myślenie, model zarządza własnym budżetem rozumowania. Dodawanie własnych instrukcji „krok po kroku” jest zbędne.
Co zrobić zamiast tego:
Zaufaj narzędziu. Jeśli włączysz Rozszerzone Myślenie, usuń wszystkie instrukcje dotyczące sposobu myślenia.
3. Ograniczenia Negatywne („Nie Rób X”)
Mówienie Claude’owi dokładnie, czego nie robić, często przynosi odwrotny skutek.
Badania nad instrukcjami dotyczącymi „Różowego Słonia” pokazują, że mówienie zaawansowanemu modelowi, aby nie myślał o czymś, zwiększa prawdopodobieństwo, że skupi się na tym.
Mechanizm uwagi Claude’a podkreśla zakazane pojęcie, utrzymując je aktywne w oknie kontekstowym.
Zamiast tego, przekształć każdą negację w pozytywne polecenie:
- Złe: Nie pisz długich, rozwlekłych wstępów. Nie używaj słów takich jak „wgłębiać się” czy „kalejdoskop.”
- Dobre: Zacznij bezpośrednio od głównego argumentu. Używaj zwięzłego, trafnego języka.
Jak Migrować Wpisy Z Claude 3.5 Do Claude 4?
Jeśli migrujesz z Claude 3.5 do 4.5, możesz przenieść swoją bibliotekę promptów, postępując według pięciu systematycznych kroków zweryfikowanych przez doświadczenie programistów.
W tym przykładzie skorzystamy z typowego scenariusza hostingu. Celem jest wygenerowanie odpowiedzi wsparcia technicznego dla klienta, który napotyka błąd „503 Service Unavailable” na swojej stronie WordPress.

1. Audyt Domniemanych Założeń
Zacznij od ustalenia, gdzie wskazówka polega na zgadywaniu kontekstu przez model. W starszych wersjach model zakładał, że używasz najpopularniejszego stosu oprogramowania. Claude 4.5 nie zrobi już tego skoku.
Stary Prompt:
„Moja strona ładuje się powoli i wyświetla błędy. Jesteś ekspertem od administracji serwerami. Pomyśl krok po kroku i powiedz mi, jak poprawić konfigurację, aby była szybsza.”
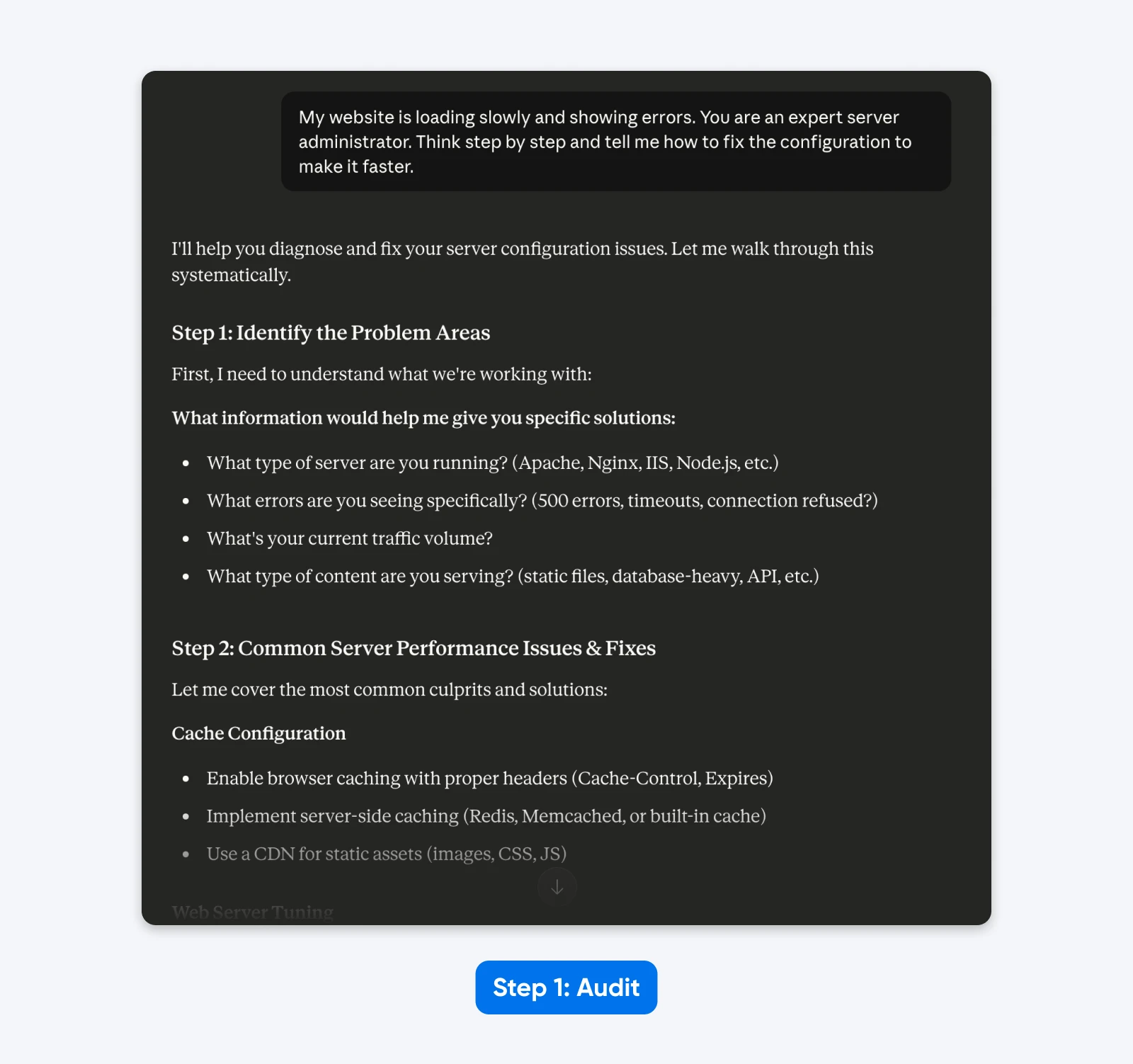
Audyty:
- „Strona internetowa” oznacza ogólne ustawienie, a nie konkretny CMS (WordPress).
- „Powoli” jest określeniem subiektywnym; może oznaczać wysoki czas do pierwszego bajta lub wolne renderowanie zasobów.
- „Błędy” nie zawierają konkretnych kodów statusu HTTP potrzebnych do diagnozy.
- „Ekspert administratora serwera” i „Myśl krok po kroku” są zbędnymi instrukcjami kierowania.
W odpowiedzi, Claude 4.5 prosi o więcej informacji, ponieważ jest szkolony, aby unikać robienia założeń.
2. Refaktoryzacja Dla Wyraźnej Specyficzności
Teraz przepisz polecenie, aby określić środowisko, konkretny problem i pożądany format wyjściowy. Musisz dostarczyć szczegóły techniczne, które model wcześniej zgadł.
Przerobione Zadanie:
„Moja strona WordPress działająca na Nginx i Ubuntu 20.04 doświadcza wysokiego czasu do pierwszego bajtu (TTFB) oraz sporadycznych błędów 502 Bad Gateway. Jesteś ekspertem od administracji serwerami. Myśl krok po kroku i podaj konkretne zmiany w konfiguracji Nginx i PHP-FPM, aby rozwiązać te problemy z przekroczeniem czasu.”

Wynik: W poleceniu teraz określono dokładnie stos oprogramowania (Nginx, Ubuntu, WordPress) oraz konkretny błąd (502 Bad Gateway), co zmniejsza ryzyko otrzymania nieistotnych rad dotyczących Apache lub IIS. A Claude odpowiada analizą i rozwiązaniem krok po kroku.
3. Zaimplementuj Logikę Warunkową
Claude 4.5 doskonale radzi sobie z drzewem decyzyjnym. Zamiast prosić o jedno statyczne rozwiązanie, zleć modelowi obsługę różnych scenariuszy w oparciu o analizowane dane.
Wskazówka Z Logiką:
„Moja strona WordPress działająca na Nginx i Ubuntu 20.04 doświadcza wysokiego TTFB oraz błędów 502 Bad Gateway. Jesteś ekspertem od serwerów. Myśl krok po kroku.
Jeśli dzienniki błędów pokazują 'upstream sent too big header’, podaj zmiany konfiguracji dla rozmiarów buforów. Jeśli dzienniki błędów pokazują 'upstream timed out’, podaj zmiany konfiguracji dla limitów czasu wykonania.”
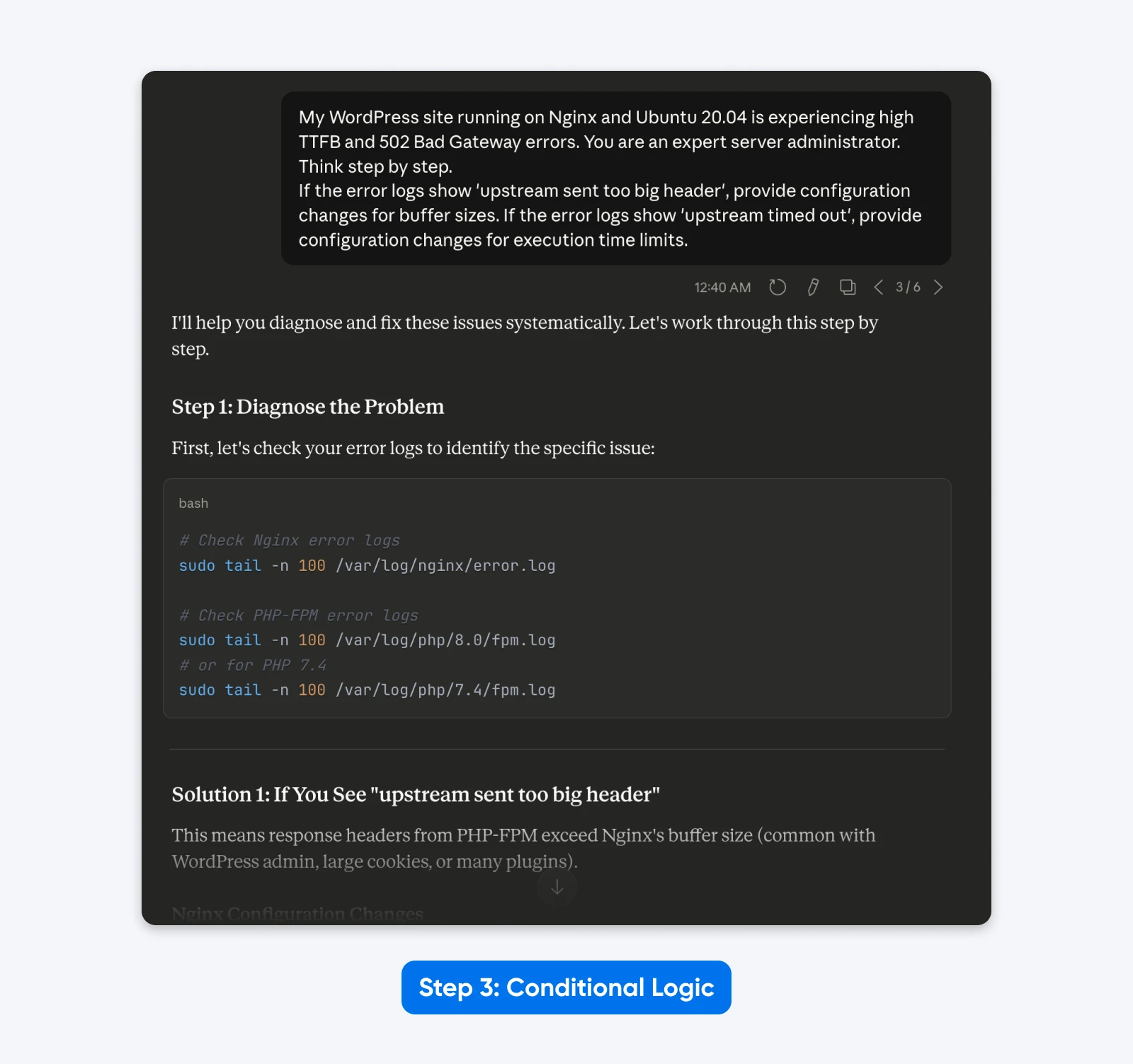
Rezultat: Wynik staje się dynamiczny. Model dostarcza spersonalizowane rozwiązania oparte na określonej przez ciebie logice przyczyny podstawowej, zamiast ogólnego zestawu poprawek.
4. Usuń Przestarzały Język Sterowania
Stare wskazówki często zawierają instrukcje myślenia, które użytkownicy uważali za poprawiające wydajność. Są one zbędne i nadmiarowe w przypadku Claude 4.5, ponieważ posiada on rozszerzone myślenie.
Wyczyszczony Monit:
„Moja strona WordPress działająca na Nginx i Ubuntu 20.04 doświadcza wysokiego TTFB oraz błędów 502 Bad Gateway.
Jeżeli dzienniki błędów pokazują 'upstream sent too big header’, podaj zmiany konfiguracji dla rozmiarów buforów. Jeśli dzienniki błędów pokazują 'upstream timed out’, podaj zmiany konfiguracji dla limitów czasu wykonania.”
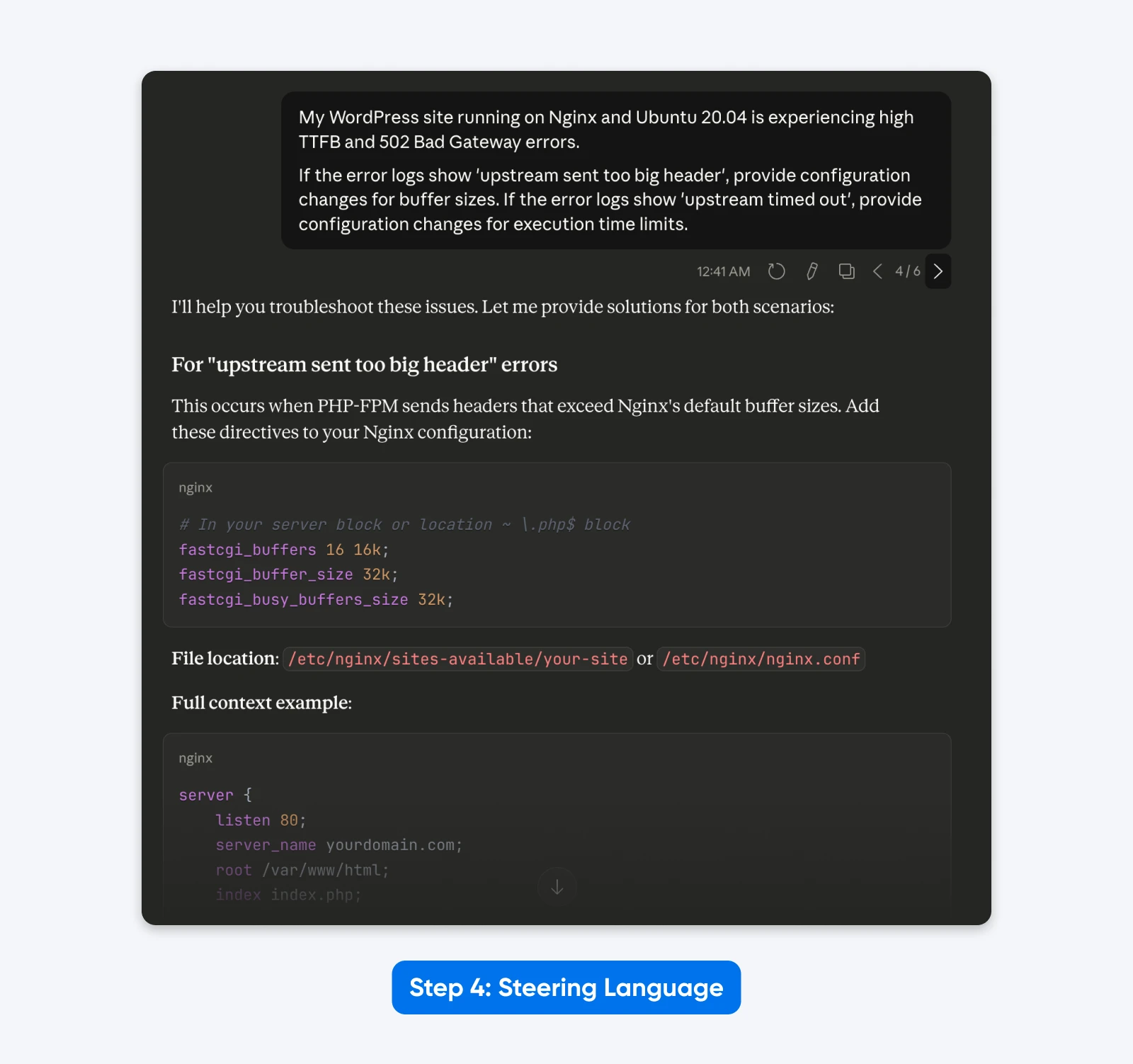
Rezultat: Szczuplejsze polecenie koncentrujące się wyłącznie na zadaniu technicznym, eliminujące rozpraszające elementy takie jak „Jesteś ekspertem” i „Myśl krok po kroku”.
5. Testuj Systematycznie
Zmontuj komponenty w uporządkowany format za pomocą XML lub czytelnych nagłówków. To odpowiada danym treningowym modelu i zapewnia najbardziej spójne wyniki.
ROLA: Administrator systemu Linux specjalizujący się w wydajności Nginx i WordPress.
ZADANIE: Rozwiąż błędy 502 Bad Gateway i zredukuj czas do pierwszego bajtu (TTFB) dla strony WordPress na Ubuntu 20.04.
LOGIKA:
- Jeśli dzienniki pokazują "upstream sent too big header", zwiększ fastcgi_buffer_size i fastcgi_buffers.
- Jeśli dzienniki pokazują "upstream timed out", zwiększ fastcgi_read_timeout w nginx.conf i request_terminate_timeout w www.conf.
WYMAGANIA WYJŚCIOWE:
- Podaj dokładne linie konfiguracji do zmiany.
- Wyjaśnij wpływ każdej zmiany na pamięć serwera.
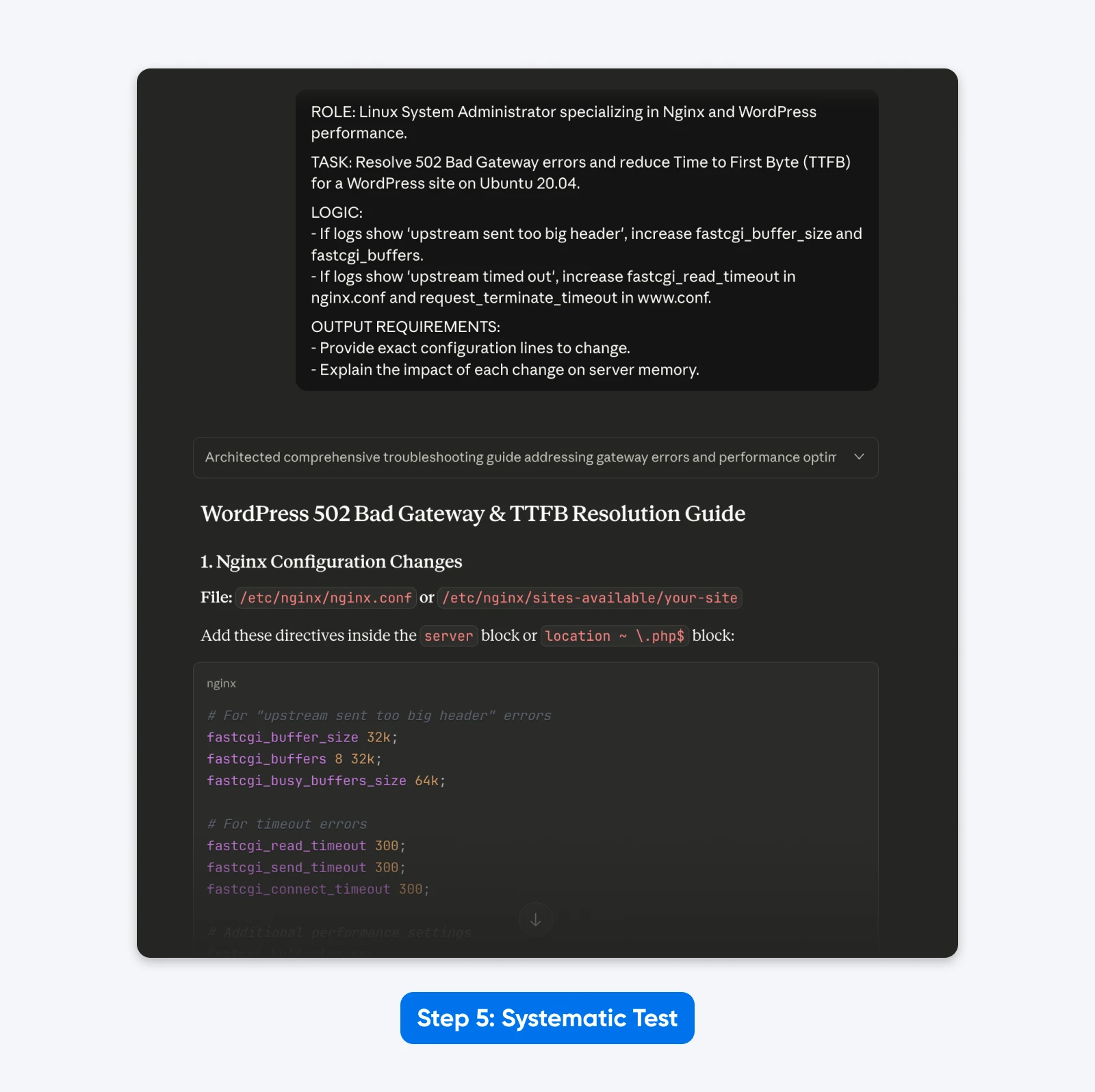
Wynik: Odpowiedź była bardziej uporządkowana, pozwoliła mi rozwiązać problem z danymi konfiguracyjnymi, które można skopiować i wkleić, jak żądano, oraz lepiej wyjaśniła rozwiązanie.
Co To Oznacza Dla Twojego Procesu Pracy
Modele Claude 4.x działają inaczej niż wcześniejsze modele. Postępują zgodnie z Twoimi dokładnymi instrukcjami, zamiast zakładać, co miałeś na myśli, co pomaga, gdy potrzebujesz spójnych wyników. Wysiłek, który włożysz na początku w inżynierię poleceń, opłaci się, jeśli będziesz powtarzać to samo zadanie wielokrotnie.
Każda technika w tym przewodniku została starannie wybrana, ponieważ jest ściśle związana z tym, jak zbudowano Claude 4.x. Tagi XML, tryb Rozszerzonego Myślenia, wyraźne instrukcje, przykłady na kilka strzałów i podejście oparte na kontekście działają, ponieważ, na podstawie przewodników Claude’a do tworzenia monitów i dowodów anegdotycznych, prawdopodobnie tak Anthropic trenowało modele.
Więc śmiało, wybierz jedną lub dwie techniki z tego przewodnika i przetestuj je na swoich rzeczywistych procesach pracy. Zmierz, co się zmienia i które metody działają na Twoją korzyść. Najlepsze podejście to takie, które jest poparte rzeczywistymi danymi z Twoich codziennych procesów pracy.

