
Se hai notato che il tuo illustratore preferito è improvvisamente scomparso da Instagram, o quel genitore amico che elimina silenziosamente ogni foto del proprio figlio da Facebook, non è frutto della tua immaginazione. Negli ultimi anni, le persone hanno rimosso contenuti dal web per preoccupazioni riguardo all’IA generativa.
Questo può assumere molteplici aspetti: artisti che ritirano i loro portafogli online dopo aver scoperto che modelli di IA riproducono dipinti nel loro stile, genitori che eliminano foto di famiglia per la paura che i volti dei loro bambini possano finire in un deepfake, o aziende che bloccano completamente l’accesso al loro sito web ai crawler di IA.
Secondo un’analisi dei clienti di DreamHost, abbiamo scoperto che circa 5.000 siti web totali che utilizzano i nostri servizi di hosting stanno attivamente bloccando alcuni o tutti i crawler AI.
In altre parole, esiste una preoccupazione reale e misurabile su come gli strumenti di IA accedano, comprendano e assimilino i contenuti che tutti noi mettiamo online.
Non è che queste preoccupazioni siano nuove.
Internet è stato sempre un luogo complicato per il consenso, la privacy e la proprietà. Ciò che è cambiato è che l’IA ha costretto tutti: creatori, famiglie e piccoli imprenditori, a confrontarsi finalmente con il poco controllo che hanno su ciò che pubblicano online.
Da DreamHost, abbiamo sempre creduto che il web aperto prosperi quando i creatori controllano ciò che condividono e come viene utilizzato. Il web funziona meglio quando la proprietà è nelle mani delle persone che lo hanno costruito — non solo delle piattaforme che ne traggono profitto.
E questo ci porta al cuore della questione. La vera domanda non è cosa può fare l’IA — è chi ha il diritto di decidere.
Il Vero Problema Etico Dell’IA Non È La Tecnologia — È La Perdita Di Scelta
L’IA non è il cattivo qui. La vera minaccia è il “paternalismo delle piattaforme,” ovvero le aziende che fanno scelte “etiche” per conto di tutti gli altri. Ad esempio, nel 2024, diversi importanti content delivery networks (CDNs) e fornitori di rete hanno iniziato a bloccare i crawler IA di default, affermando che il loro obiettivo era “proteggere i creatori.” Il risultato è stato che milioni di proprietari di siti si sono svegliati scoprendo che le decisioni riguardanti i loro contenuti erano già state prese per loro.
È come se il tuo padrone di casa chiudesse a chiave la tua porta per la tua sicurezza, ma senza darti le chiavi giuste. Quindi ciò che iniziava come una comodità si trasforma rapidamente in una perdita di autonomia. Quando i guardiani decidono cosa significhi “protezione”, l’autonomia individuale si riduce.
Il web aperto è stato costruito sull’innovazione senza permessi, il che significa che chiunque poteva creare, condividere e iterare senza chiedere approvazione. Gli intermediari che decidono quali bot o strumenti possono accedere ai contenuti potrebbero far regredire quella libertà di decenni.
Ecco perché DreamHost sostiene l’indipendenza dell’infrastruttura: quando ospiti il tuo contenuto, nessuno può riscrivere le tue regole. Possedere il tuo stack significa possedere le tue politiche, sia che tu accogli i crawler IA o li escluda completamente. L’etica non deriva dal codice; deriva dalla scelta.

“L’IA Richiede i Tuoi Dati” e Altri Miti
Allora, cosa impedisce ai creatori di riprendere il controllo? Spesso, la disinformazione, come questi miti diffusi sull’IA. Questi miti sono popolari perché l’uso dell’IA si è diffuso su internet e negli strumenti che usiamo ogni giorno.
Mito #1: “L’IA Ha Bisogno Dei Tuoi Dati Per Progressare”
Nessuno deve il proprio lavoro alle aziende di IA a scopo di lucro. Esistono modelli basati su licenza e consenso; per esempio, Adobe Firefly addestra contenuti su licenza con permesso e opere di dominio pubblico senza diritti d’autore. Il futuro dell’IA non deve dipendere dal furto. Può dipendere invece dal consenso.
Mito #2: “Se Decidi di Non Partecipare, Sparirai”
Scegliere di non partecipare potrebbe limitare la tua presenza nei sommari generati dall’IA o negli snippet di ricerca, ma non ti cancellerà dal web. Pensalo come scegliere di non partecipare a Google nel 2005. Perderesti visibilità, non rilevanza, soprattutto se il tuo pubblico continua a cercarti direttamente.
Potrebbe non essere pratico per chiunque dipenda dalla visibilità per far crescere la propria audience o base di clienti (anche se ancora non disponiamo di dati concreti su quanto traffico organico provenga effettivamente da GEO), per alcuni creatori, la visibilità non vale l’uso involontario. La chiave è che loro decidano.
Mito #3: “Lo Scraping IA È Proprio Come Funziona Internet”
Indicizzazione per la scoperta e appropriazione per la formazione non sono la stessa cosa.
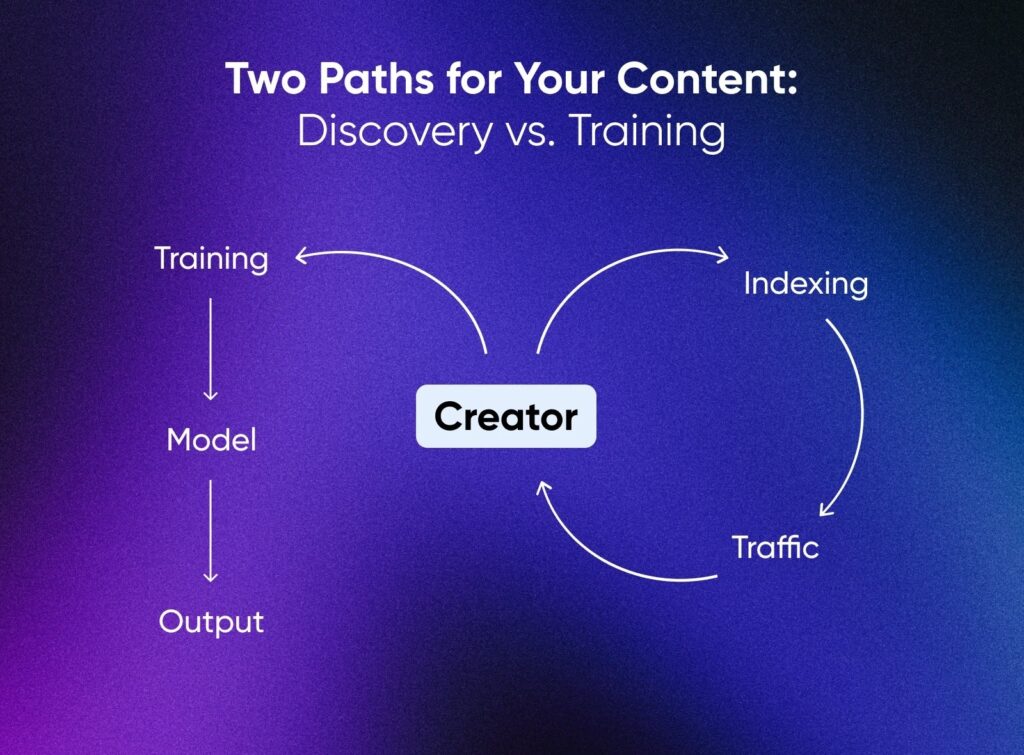
L’indicizzazione attira persone sul tuo sito. L’addestramento ti sostituisce con una copia statistica. Editori come Associated Press e Axel Springer stanno dimostrando che c’è una via di mezzo licenziando i loro contenuti per l’addestramento dei modelli con riconoscimento e compensazione.
Anche le buone intenzioni possono ritorcersi contro. La conclusione è che un’etica equilibrata richiede il consenso informato.
Rinunciare vs. Rimanere Aperti: I Veri Compromessi
Ogni posizione sull’IA — dalla completa apertura al rifiuto totale — comporta costi di opportunità reali. Decidere dove ti collochi dipende da ciò che apprezzi di più, dalla visibilità al controllo, dalla sostenibilità all’autonomia.
I dati interni di DreamHost mostrano che circa il 71,5% di tutto il traffico web proviene ora dai bot, non dagli esseri umani. Ciò significa che la maggior parte delle richieste che arrivano al tuo sito sono automatizzate: alcune benefiche (come l’indicizzazione della ricerca o il monitoraggio dell’uptime), altre meno. Gestire quali crawler permetti e quali blocchi è sostenibilità etica in azione.
Di seguito sono riportati quattro approcci comuni che i creatori adottano per l’accesso e la formazione AI e come ognuno impatta su diversi fattori di web aperto, così puoi visualizzare i compromessi prima di fissare la tua posizione.
| Completamente Aperto | Licenza Selettiva | Blocco Allenamento IA | Completamente Escluso dall’IA | |
| Visibilità e Portata | Massima; riassunti IA e motori di ricerca possono mostrare il tuo lavoro ovunque. | Moderata; esposizione limitata ai partner che licenziano i contenuti. | Bassa; escluso dai risultati IA ma ancora visibile nei motori di ricerca tradizionali. | Nessuna; bloccato sia dall’IA che da molti crawler di scoperta. |
| Controllo e Consenso | Minimo; le piattaforme decidono per te. | Alto; regolato da termini di licenza espliciti. | Forte; definisci i permessi tramite robots.txt e intestazioni HTTP. | Absoluto; tutto l’accesso automatizzato è proibito. |
| Attribuzione | Bassa; la maggior parte dei modelli di IA non cita le fonti. | Alta; attribuzione e royalties integrati nei contratti. | Media; i crawler conformi possono ancora citarti. | Nessuna; i contenuti non vengono mai menzionati. |
| Impatto Ambientale | Moderato; contribuisce all’addestramento di modelli su larga scala e al carico di indicizzazione. | Moderato; l’uso limitato e sotto licenza riduce la duplicazione di addestramento. | Moderato-basso; meno crawler pesanti, più traffico mirato. | Basso; minori richieste esterne e trasferimenti di dati. |
| Rischio di Abuso o Copia | Alto; stile o testo possono essere replicati liberamente. | Moderato; ricorso legale tramite termini di licenza. | Basso; i bot conformi sono scoraggiati, bot non autorizzati ancora possibili. | Molto basso; superficie minima da raschiare. |
Ogni percorso ha il suo valore. I piccoli imprenditori e i marketer dipendono spesso dalla visibilità per far crescere il loro pubblico, mentre illustratori, giornalisti ed educatori possono dare priorità alla proprietà e al consenso su tutto il resto. Il web prospera sulla diversità e la partecipazione etica all’IA dovrebbe riflettere questa varietà di obiettivi.
Non esiste una risposta universale giusta: solo compromessi informati che si allineano ai tuoi principi e al modo in cui guadagni online. La posizione giusta non è uguale per tutti, ma dovresti formulare la tua posizione in modo consapevole e sostenerla con l’azione. Qualunque sia il percorso che scegli, rendilo intenzionale.
Come Decidere La Tua Posizione Sull’IA
L’etica conta solo quando viene messa in pratica. Ecco come trasformare la teoria in azione e definire come l’IA interagisce con il tuo lavoro.
Passo 1: Definisci i Tuoi Obiettivi
Inizia classificando ciò che conta di più per te: visibilità, entrate, sostenibilità, controllo.
Una piccola impresa alla ricerca di visibilità può tollerare un utilizzo più ampio dell’IA, mentre un illustratore che tutela l’originalità potrebbe non farlo. Obiettivi diversi = confini diversi.

Fase 2: Analizza la Tua Impronta Digitale
Elenco dei luoghi dove risiede il tuo contenuto: siti WordPress, repository GitHub, social media, archiviazione cloud. Le piattaforme applicano le proprie politiche IA, quindi l’indipendenza nell’hosting ti dà la libertà di stabilire regole per sito invece di accettare le impostazioni predefinite generali stabilite dalle piattaforme che utilizzi (senza il tuo contributo).
Passo 3: Applica Controlli Tecnici
Utilizza il tuo file robots.txt per indicare ai bot IA come comportarsi:
User-agent: GPTBot |
Aggiungi intestazioni (come X-Robots-Tag: noai, noimageai) per maggiore chiarezza. Ricorda, la conformità è volontaria. Questi tag segnalano le tue intenzioni, ma non le impongono.
Passo 4: Pubblica Una Politica Trasparente Sull’IA
Crea una pagina semplice che esprima la tua posizione. Per esempio:
| “I sistemi IA non possono utilizzare questo contenuto per l’addestramento o la replicazione.” |
La trasparenza costruisce fiducia con i clienti e stabilisce confini chiari per l’utilizzo futuro.
Passo 5: Monitora e Adatta
Utilizza i log del server o l’analisi per monitorare il mix di bot. Controlla trimestralmente e aggiorna le tue regole man mano che emergono nuovi crawler.
Le Uniche Etiche Dell’IA Che Contano Sono Le Tue
L’IA non ha etica — le persone sì. Ciò che conta non è se hai bloccato ogni crawler o adottato ogni strumento; è che hai fatto quelle scelte intenzionalmente.
Il web è stato costruito sulla libertà di condividere, remixare, sperimentare e creare senza permessi. La vera etica digitale protegge quello stesso spirito di autodeterminazione.
Sei passato dalla paura al controllo, dall’incertezza alla proprietà. Noi di DreamHost crediamo che possedere la tua presenza digitale non sia solo una mossa intelligente per il business, ma anche il modo per mantenere la tua etica in un mondo governato dagli algoritmi.
Il web aperto rimane tuo, se scegli di possederlo.

