
Moja babcia zarządzała arkuszami inwentaryzacyjnymi dla firmy tekstylnej przez 40 lat. Oblicza skomplikowane rabaty w głowie szybciej niż większość ludzi z kalkulatorami, ale nie ma żadnego doświadczenia w programowaniu.
Kiedy zaproponowałem wspólne budowanie aplikacji do śledzenia ogrodu z wykorzystaniem SI, jej sceptycyzm był niemal natychmiastowy.
Po dwóch godzinach miała działającą aplikację internetową, dopóki nie poprosiliśmy o jedną rzecz więcej, a aplikacja się zepsuła. To bardzo częsta historia o kodowaniu na wyczucie.
Teraz mam strukturę, która pozwala zrozumieć, co faktycznie oferuje kodowanie vibe w porównaniu do tego, co obiecuje, więc możesz spojrzeć poza marketingowy szum i faktycznie wykorzystać produkt.
Po pierwsze, czym jest Vibe Coding?
Vibe coding to tworzenie oprogramowania poprzez opisywanie, czego chcesz w prostym języku angielskim i pozwolenie SI na napisanie kodu za ciebie.
Były dyrektor AI firmy Tesla i współzałożyciel OpenAI, Andrej Karpathy, wymyślił ten termin w lutym 2025 roku, kiedy to napisał na Twitterze: „Jest nowy rodzaj kodowania, który nazywam 'kodowaniem na wibracje’, gdzie całkowicie poddajesz się wibracjom, przyjmujesz eksponenty i zapominasz, że kod w ogóle istnieje.”
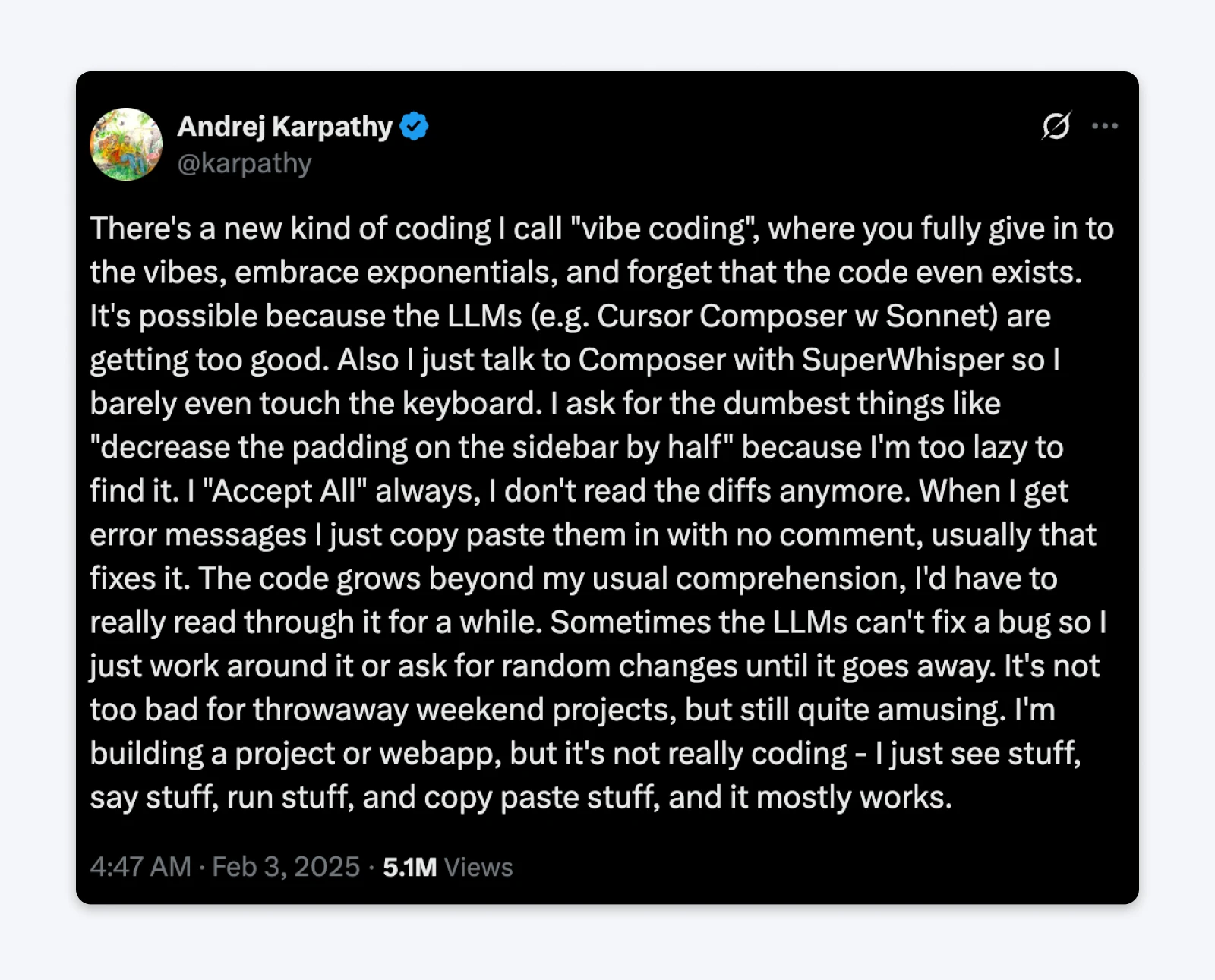
Post zyskał ponad 5 milionów wyświetleń, uchwycił podejście do rozwoju, które już rozprzestrzeniało się w społeczności technologicznej.
Zamiast uczyć się języków programowania i mierzyć się ze składnią, po prostu mówisz SI, co chcesz zbudować. SI generuje kod. Stajesz się menedżerem produktu, a nie programistą, skupiając się na tym, co aplikacja powinna robić, zamiast na tym, jak to działa.
Dlaczego Teraz Ma Znaczenie Kodowanie Vibe?
87% firm boryka się z brakami kadrowymi lub spodziewa się ich w ciągu najbliższych kilku lat, według McKinsey.
Narzędzia do kodowania SI takie jak Bolt.new, Lovable, Replit Agent i Cursor obiecują rozwiązanie tego problemu poprzez zwiększenie produktywności obecnych programistów oraz umożliwienie osobom niebędącym deweloperami szybkiego testowania swoich pomysłów.
Liczby potwierdzają szum:
- W marcu 2025 roku Y Combinator ujawnił, że 25% ich zimowej grupy 2025 miało 95% kodu wygenerowanego przez SI.
- W kwietniu 2025 roku dyrektor generalny Microsoftu, Satya Nadella, ujawnił, że 20–30% kodu zostało napisane przez SI.
- Czwarta część startupów w obecnej grupie YC ma kod prawie w całości wygenerowany przez SI.
- Dyrektor generalny Google, Sundar Pichai, podał podobne dane, stwierdzając, że ponad 25% kodu Google jest generowane przez SI.
Przeszliśmy od podstawowego autouzupełniania do pisania całych aplikacji przy minimalnym wkładzie ludzkim.
Ale te same funkcje, które czynią programowanie vibe dostępnym, takie jak wprowadzanie w języku naturalnym, autonomiczne generowanie kodu i automatyczne zarządzanie złożonością, stwarzają poważne problemy, gdy Twoja aplikacja musi wyjść poza pierwszą wersję.
Co Możesz Naprawdę Zbudować z Kodowaniem Vibe?
Kiedy możesz faktycznie budować przy użyciu kodowania vibe zależy od trzech rzeczy:
- Jak skomplikowana musi być twoja aplikacja
- Czy potrafisz rozpoznać zły kod i luki w zabezpieczeniach
- Czy wiesz, kiedy przestać dodawać funkcjonalności
Jeśli wymagania twojej aplikacji są proste, potrafisz zidentyfikować braki techniczne i oprzeć się dodawaniu niepotrzebnych funkcjonalności, vibe coding może pomóc ci szybko osiągnąć funkcjonalne rezultaty.
Jednak w miarę wzrostu złożoności lub gdy musisz budować aplikacje produkcyjne, profesjonalna recenzja i planowanie architektury stają się niezbędne.
Doświadczenie mojej babci w budowaniu aplikacji do śledzenia ogrodu pokazało dokładnie, gdzie są te granice.
Co Się Wydarzyło W Pierwszej Godzinie? Proste Instrukcje Zadziałały
Jest przynajmniej kilkanaście platform kodowania o klimacie SI, takich jak Bolt, Lovable, OpenAI Code, Claude Code, Google Opal, itp.
Zaczęliśmy od rozszerzenia OpenAI Codex w VS Code, ponieważ już miałem subskrypcję, ale poleciłbym zacząć od Bolt.new, Lovable lub Vercel dla bardziej wizualnego doświadczenia podczas kodowania.
Nasza pierwsza propozycja: „Stwórz aplikację do śledzenia ogrodu, gdzie będę mógł zapisać, co zasadziłem, kiedy to zasadziłem i ile zebrałem. Zawrzyj sposób na sprawdzenie, które rośliny sprawdziły się najlepiej w każdym sezonie.”
Ten monit zadziałał, ponieważ zawierał trzy kluczowe elementy:
- Jasna struktura danych (nazwa rośliny, data sadzenia, ilość zbiorów, sezon)
- Zdefiniowany wynik (porównanie wydajności według sezonu)
- Konkretny kontekst zastosowania (monitorowanie prywatnego ogrodu)
W ciągu kilku minut, Codex wygenerował kompletną aplikację. Posiadała bazę danych SQLite z tabelami dla roślin, sadzonek i zbiorów, punkty końcowe API REST dla operacji CRUD, frontend w Pythonie z tabelami danych i formularzami wprowadzania oraz podstawowe style CSS.
Domyślnie zawierało nawet dane demo.
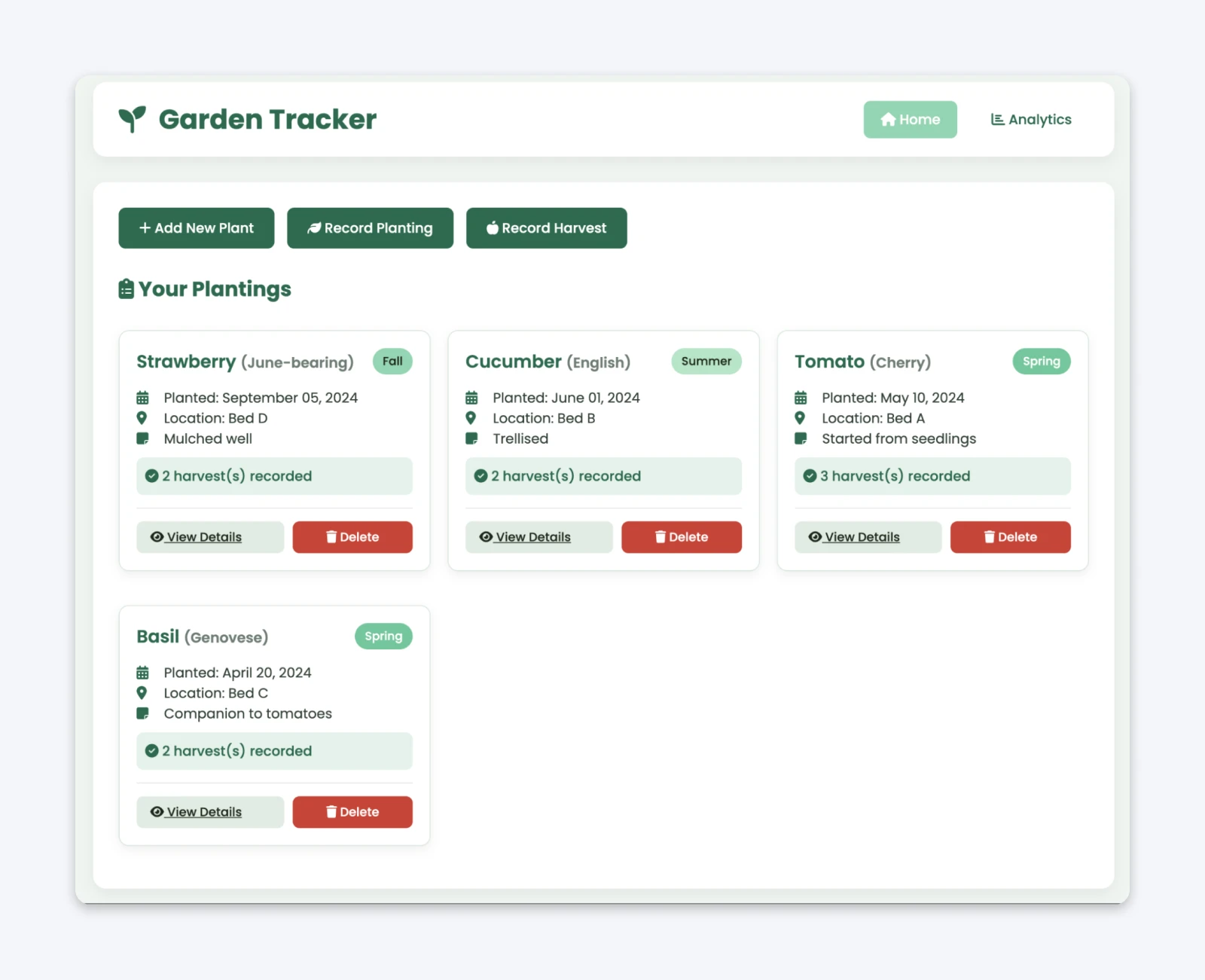
Webowa aplikacja wyglądała dobrze. To supermoc i jednocześnie największe niebezpieczeństwo kodowania na wyczucie. Ale zanim to omówię, pozwól, że wyjaśnię, co tak naprawdę dzieje się za kulisami myślenia Codex. Bawiłem się aplikacją, zrozumiałem, co mamy i czego jeszcze potrzebujemy.
Co Działo Się Za Interfejsem
Wygenerowany kod podjął decyzje architektoniczne dla aplikacji jednoużytkownikowej. Schemat bazy danych mógł łatwo obsłużyć nowe wpisy. API stosowało konwencje RESTful. Komponenty frontendowe były logicznie oddzielone.
Jednak zauważyłem, że domyślnie nie uwzględniono kluczowych kwestii bezpieczeństwa. Brak było walidacji danych wejściowych, warstwy autentykacji, limitowania częstotliwości zapytań, uwzględnienia podatności na ataki SQL Injection oraz szyfrowania.
Architektura agenta SI zakładała zaufanego pojedynczego użytkownika w kontrolowanym środowisku.
Biorąc pod uwagę, że był to projekt dla mojej babci i dla nikogo więcej, te pominięcia są do zaakceptowania. Jednak dla każdego, kto rozważa kodowanie z wykorzystaniem vibe do stworzenia wieloużytkownikowej aplikacji internetowej, są to kluczowe zagrożenia bezpieczeństwa, których po prostu nie można ignorować.
Często widzę dyskusje na ten temat na Reddit lub PostStatus: deweloperzy skutecznie rozwijają kod generowany przez SI, ponieważ identyfikują te luki i wdrażają odpowiednie warstwy zabezpieczeń. Użytkownicy nietechniczni widzą działającą aplikację i zakładają, że jest gotowa do produkcji.
Co Wydarzyło Się W Drugiej Godzinie? Przejawienie Rozszerzania Funkcjonalności
Aplikacja działała zgodnie z przeznaczeniem, a ten przełomowy moment pomógł mojej babci zbudować pewność siebie. Moja babcia zaczęła myśleć o ulepszeniach. Tutaj stają się widoczne ograniczenia kodowania vibe.
Próbowaliśmy funkcjonalności na prośbę: „Dodaj możliwość przesyłania zdjęć każdej rośliny, abym mógł zobaczyć, jak wyglądała na różnych etapach wzrostu.”
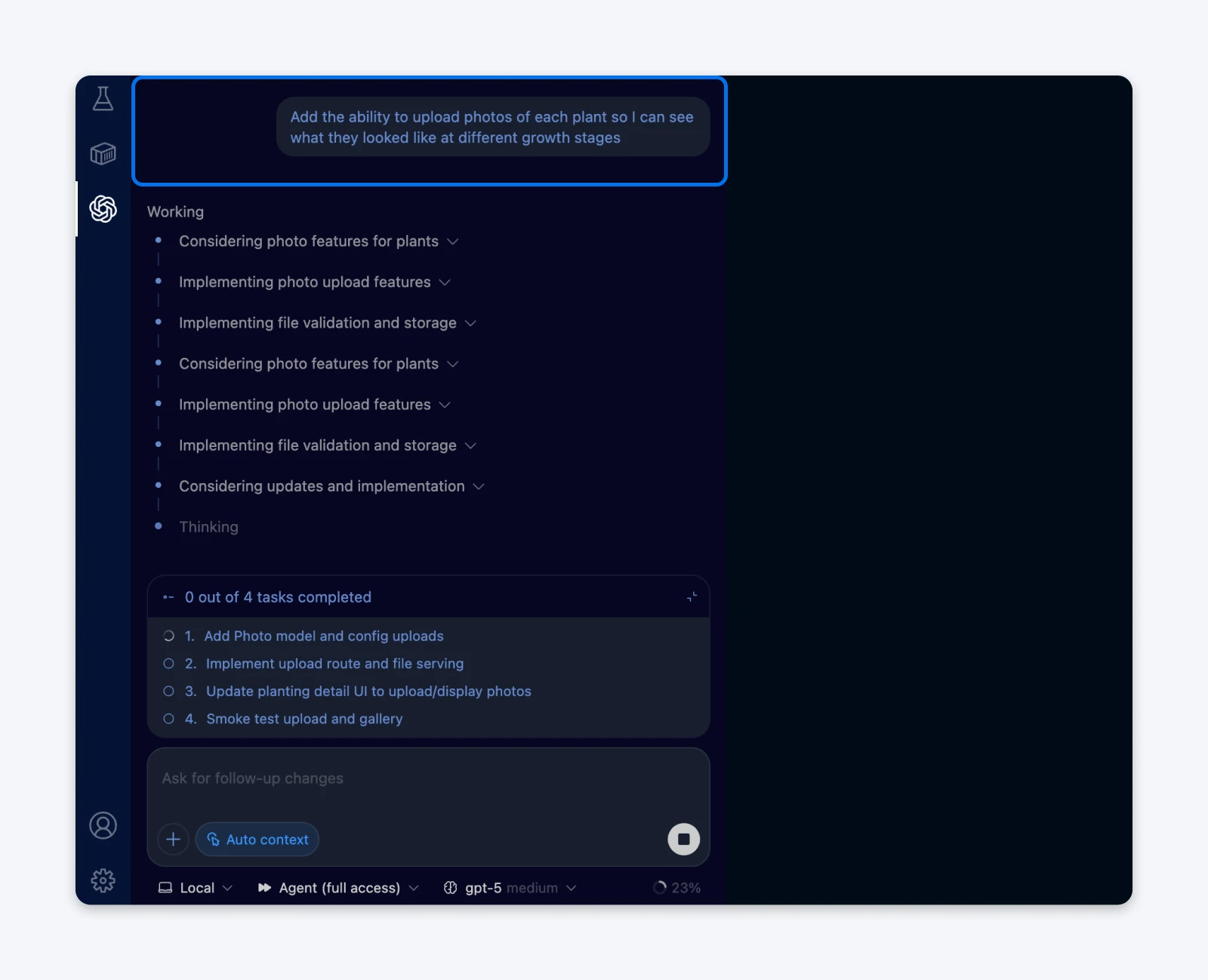
Ta pozornie prosta prośba wywołała kaskadę architektonicznej złożoności.
Zmiany schematu bazy danych i modułu aplikacji wymagane:
- Nowa tabela zdjęć z kolumnami: id, plant_id (klucz obcy), photo_url, upload_date, growth_stage
- Definicja relacji między roślinami a zdjęciami (relacja jeden-do-wielu)
- Strategia migracji istniejących danych
Potrzebne modyfikacje backendu:
- Punkt końcowy przesyłania plików z obsługą formularza wieloczęściowego
- Rozwiązanie do przechowywania plików (lokalny system plików vs. magazyn w chmurze)
- Nowe punkty końcowe API do operacji CRUD na zdjęciach
- Aktualizacja istniejących punktów końcowych roślin w celu dołączenia danych zdjęciowych
Zmiany Wymagane Na Frontendzie:
- Komponent wczytywania plików z funkcją przeciągania i upuszczania
- Funkcjonalność podglądu obrazów
- Wyświetlanie galerii zdjęć dla każdej rośliny
- Aktualizacja istniejących kart roślin o miniaturki
- Stany ładowania podczas postępu przesyłania
OpenAI Codex podjął próbę wykonania wszystkiego jednocześnie. Najnowszy model GPT5-Codex-High był w stanie to osiągnąć w ciągu ~5 minut od wprowadzenia polecenia.
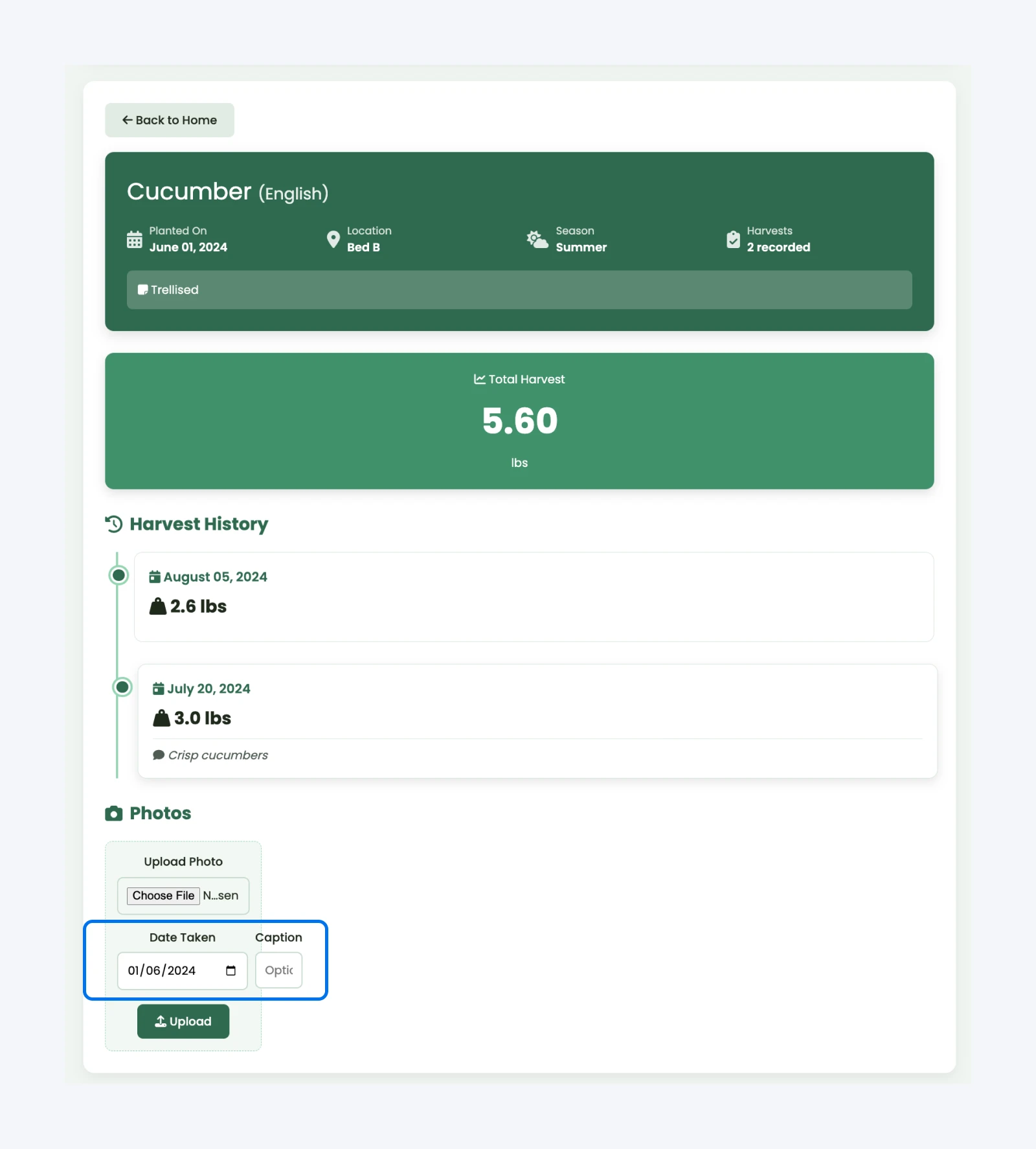
Problem polega na tym, że stworzyło to błędny i niezabezpieczony kod. Oto co się popsuło:
- Zmieniła się pierwotna struktura tabeli rośliny
- Składniki frontendu odnoszące się do starego schematu przestały działać
- Pojawiły się konflikty CSS między nowymi komponentami zdjęć a istniejącym interfejsem użytkownika (widoczne na zrzucie ekranu)
A potem pojawił się problem nadmiernego inżynierowania: Codex wygenerował złożony system z niepotrzebnym przetwarzaniem obrazu i danymi pobranymi dla każdego zdjęcia, itd.
Każda próba naprawy wprowadzała nowe problemy. Aktualizuj schemat bazy danych, psuj API. Napraw API, psuj frontend. Rozwiąż problemy z frontem, odkryj nowe błędy backendu. Kod, który działał idealnie przy 200 liniach kodu, teraz rozciąga się na 1500 linii z powiązanymi zależnościami.
Pułapka Architektury Nieprzystosowanej Do Rozszerzeń
Architektura aplikacji została zoptymalizowana wyłącznie dla tego, o co prosiliśmy w pierwszej godzinie. Przy programowaniu z wibracjami musisz być bardzo konkretny, a to jest trudne dla osób, które nie są programistami.
Nie wiedziałbyś, co oznacza rozszerzalna architektura, gdyby zaimplementowała ją SI.
Jeśli masz już gotową prostą aplikację, a potem potrzebujesz ją rozbudować, brak elastycznej architektury oznaczałby konieczność napisania kodu od nowa dla SI.
Założenia architektoniczne od pierwszej godziny:
- Pojedynczy projekt tabeli (rozsądny dla prostych danych)
- Bezpośrednie zapytania API do bazy danych (szybkie dla operacji z dużą ilością odczytów)
- Zagnieżdżone definicje komponentów (akceptowalne dla małych interfejsów użytkownika)
- Brak rozdzielenia logiki biznesowej i dostępu do danych (odpowiednie dla prostych operacji CRUD)
Dlaczego te założenia stały się ograniczeniami:
- Jednotablicowy projekt uniemożliwiał odpowiednie modelowanie relacyjne danych dla zdjęć
- Bezpośrednie zapytania wymagały całkowitego przepisania przy zmianie schematu
- Komponenty wbudowane powodowały, że zmiany przenosiły się na całą bazę kodu
- Brak warstwy logiki biznesowej oznaczał, że każda funkcja bezpośrednio oddziaływała na bazę danych
Minęliśmy punkt bez powrotu. Zbyt wiele kodu powstało, aby go porzucić. Każda próba naprawy pochłaniała więcej tokenów, starając się uratować architekturę, która nie mogła wspierać nowych wymagań.
Co Wydarzyło Się W Trzeciej Godzinie? Wyczerpanie Tokenów I Ledwo Funkcjonujący Kod
Po tym, jak funkcja przesyłania zdjęć zaczęła działać, próbowaliśmy wprowadzić dodatkowe ulepszenia.
- „Dodaj kategorie dla typów roślin (warzywa, zioła, kwiaty)”
- „Pokaż rekomendacje sadzenia w zależności od pory roku”
- „Pozwól mi oznaczyć rośliny jako ulubione”
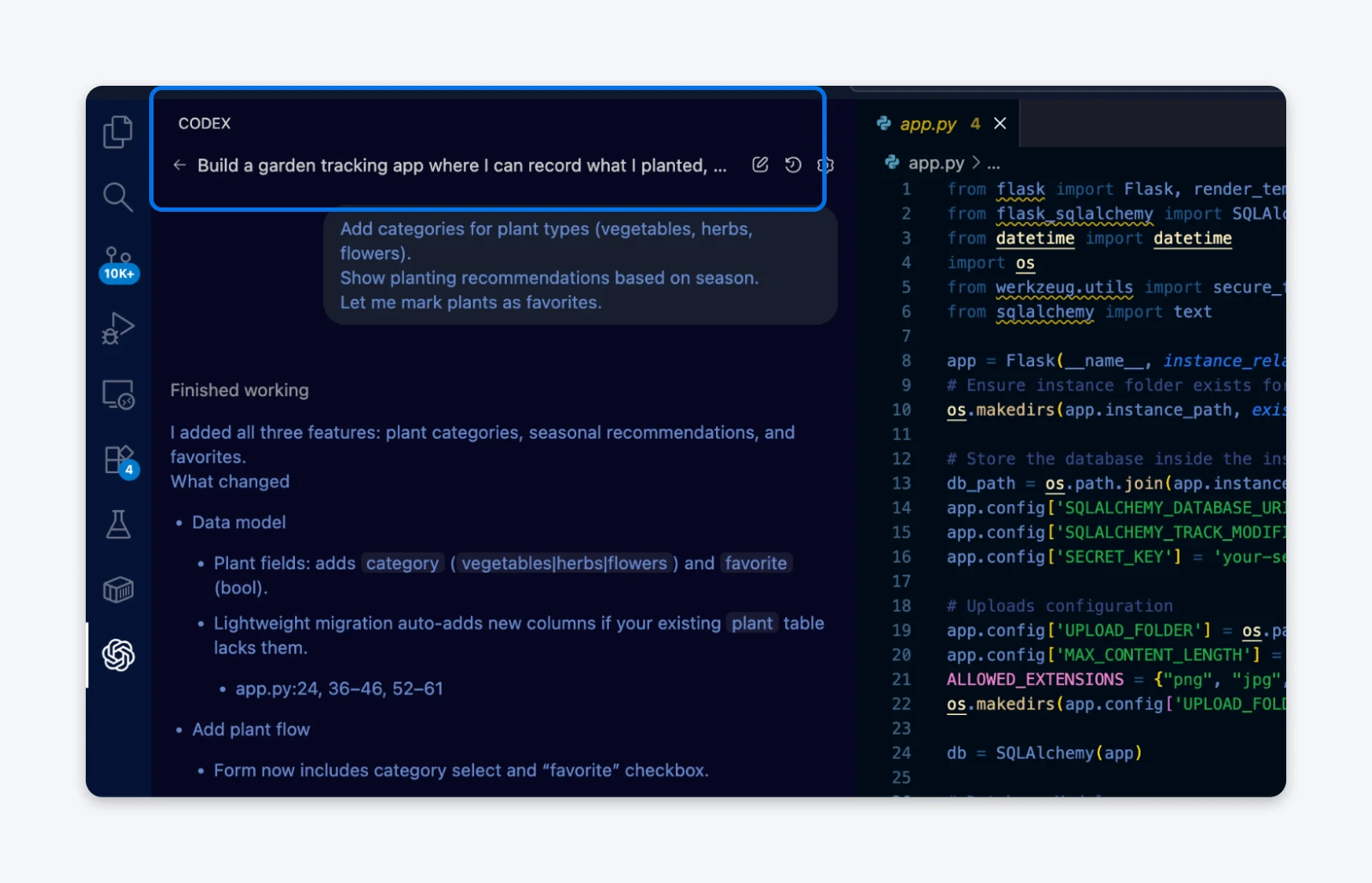
Każde zapytanie podążało za tym samym wzorcem: Codex próbował dokładnie wdrożyć rozwiązania dla pozornie prostych zadań, wprowadzał zmiany powodujące błędy, tworzył przekombinowane rozwiązania i zużywał tysiące tokenów, próbując naprawić wynikające błędy.
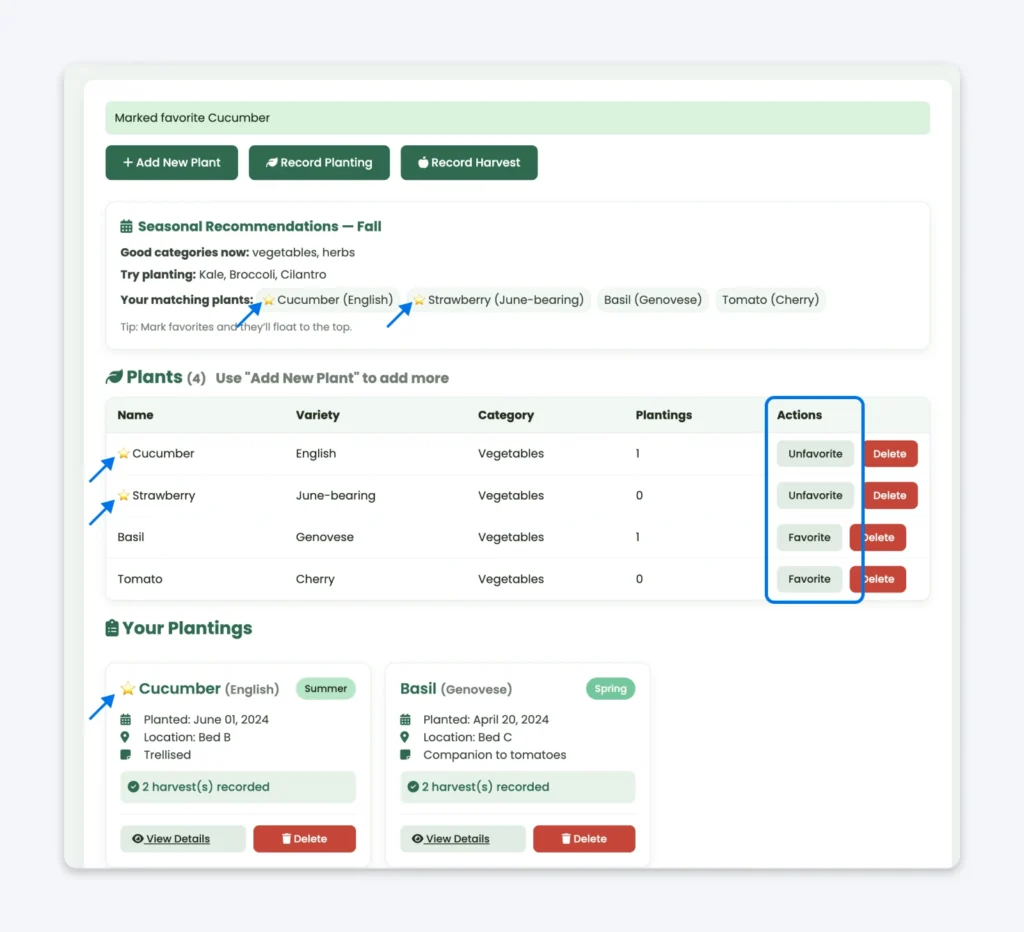
Aplikacja działa świetnie, a moja babcia była zadowolona z wyniku.
Jako programista jednak wyraźnie widziałem, że jesteśmy na ostatniej prostej pod względem kodu. Jeszcze kilka funkcji i aplikacja byłaby bałaganem.

za pośrednictwem Imgflip
Dlaczego Jest To Tak Powszechny Problem?
Agenci programujący to po prostu duże modele językowe „stymulowane” do generowania kodu.
Więc mają wszystkie problemy, które dotyczą regularnych dużych modeli językowych, w tym:
- Nieokreślanie jasnych oczekiwań
- Wymyślanie losowych wywołań funkcji (halucynacje)
- Pisanie skomplikowanego kodu do prostych zadań
Ponadto, w miarę jak historia czatu się rozrasta, agenci kodujący osiągają swoje limity okna kontekstowego.
- Pierwotne decyzje architektoniczne i ich uzasadnienie
- Kolejne modyfikacje i ich wzajemne zależności
- Aktualne błędy i ich podstawowe przyczyny
- Pożądana funkcjonalność dla nowych funkcji
Każde nowe polecenie było interpretowane oddzielnie, bez pełnego zrozumienia historii architektury. SI proponowało rozwiązania, które miały sens dla poszczególnych funkcji, ale stwarzały systemowe konflikty, gdy były integrowane z istniejącym kodem.
Ten przewodnik na Reddicie podkreśla: „Gdy rozmowa stanie się bardzo duża, po prostu otwórz nową. Okno kontekstowe SI jest ograniczone. Jeśli rozmowa będzie bardzo duża, zapomni wszystko, co było wcześniej, zapomni wszelkich wzorców i projektów, i zacznie produkować złe wyniki.”
Ale otwieranie nowego czatu oznaczało utratę całego kontekstu dotyczącego tego, co istniało. Zapewnienie tego kontekstu zajmowało tokeny. Nawet z „streszczonym” kontekstem wciąż brakuje nam ważnych szczegółów, jeśli chodzi o kod.
Zmagaliśmy Się Z Problemem Aplikacji TEA Na Mniejszą Skalę
Aplikacja TEA zademonstrowała ten dokładny wzorzec awarii na skalę produkcyjną. Uruchomiona w 2023 roku jako platforma bezpieczeństwa kobiet, szybko zyskała 1,6 miliona użytkowników.
Następnie, w lipcu 2025 roku, nastąpiła katastrofalna awaria:
- Naruszenie: Badacze ds. bezpieczeństwa odkryli niezabezpieczony bucket Firebase przechowujący 72,000 zdjęć użytkowników, w tym 13,000 zdjęć do weryfikacji i dokumentów tożsamości. Druga baza danych ujawniła 1,1 miliona prywatnych wiadomości.
- Niepowodzenia techniczne: Klucze API zakodowane na stałe w kodzie źródłowym, bucket Firebase publicznie dostępny bez autoryzacji, brak ochron przed wykonaniem i brak warstwy przeglądu bezpieczeństwa. Eksperci powiązali te podatności z praktykami kodowania na wibracje, gdzie prędkość funkcji przysłoniła architekturę bezpieczeństwa.
- Wynik: Anonimowy użytkownik 4chan odkrył i udostępnił narzędzia do pobierania. Pozwy zbiorowe złożone w ciągu 48 godzin. Platforma została zamknięta. Średni koszt naruszenia: 4,88 miliona dolarów.
Poraszka TEA ma taki sam wzorzec, jakiego doświadczyliśmy na tak małą skalę, co sprawia, że zastanawiam się, dlaczego ludzie nie weryfikują kodu generowanego przez SI.
Mieliśmy początkową implementację, która działała dobrze; jednak dodatki funkcjonalności skomplikowały architekturę, kwestie bezpieczeństwa zostały przeoczone dla nowych funkcji, a systemowe podatności pozostały nieświadomie otwarte na wykorzystanie.
Jak Pracować Z Kodem, Nie Napotykając Tych Samych Problemów Co My
Jeśli nie jesteś programistą, nie da się całkowicie uniknąć problemów. Istnieją jednak sposoby, aby zminimalizować problemy.
1. Zacznij Od Bezwzględnego Minimalizmu Funkcjonalności
Określ absolutne minimum funkcjonalności przed napisaniem pierwszego polecenia, ale zawsze oprzyj się pokusie dodawania funkcji w trakcie początkowego rozwoju.
Skuteczne ramy zasięgu:
- Wypisz wszystkie wymagane funkcjonalności
- Zidentyfikuj 3–5 funkcjonalności, które potwierdzają twoją główną hipotezę
- Buduj tylko te funkcjonalności w pierwszej wersji
- Wydaj, potwierdź i iteruj
Nie dawaj poleceń typu „Zbuduj mi tę całą funkcję”. AI zacznie halucynować i wyprodukuje okropny kod. Podziel każdą funkcję na co najmniej 3–5 kolejnych żądań.
Jeśli nie możesz zidentyfikować minimalnego zestawu funkcji, użyj opcji „Tryb planowania” lub „Tryb czatu” dostępnych w większości narzędzi do kodowania AI.
To pozwala ci powiedzieć agentowi, czego chcesz w naturalnym języku i umożliwia AI rozkładanie aplikacji na pojedyncze funkcje lub pliki.
2. Zatwierdź W Git Po Każdej Działającej Funkcjonalności
Dla osoby, która nie jest programistą, kontrola wersji może brzmieć skomplikowanie, ale jest to niezbędne narzędzie. Git to narzędzie do kontroli wersji, które tworzy punkty przywracania, gdy dodanie nowych funkcji zakłóca funkcjonowanie istniejących.
Przepływ pracy Git dla kodowania vibe:
- Zainicjuj repozytorium przed pierwszym monitem
- Zatwierdź po początkowej działającej wersji
- Utwórz nową gałąź dla każdego dodatku funkcji
- Zatwierdzaj często podczas rozwijania funkcji
- Przetestuj dokładnie przed scaleniem z główną gałęzią
Możesz poprosić wybranego agenta programistycznego, aby zrobił to za ciebie, jeśli nie czujesz się komfortowo z komendami Git.
3. Projektowanie Rozszerzeń W Początkowych Monitach
Twoja pierwsza komenda definiuje bazę kodu. Proste polecenia pozwolą ci uzyskać działającą aplikację, dopóki nie zaczniesz prosić o nowe funkcje.
Zamiast tego poproś o elastyczną architekturę już na początku.
- Nieskuteczna Pierwsza Komenda: „Zbuduj aplikację do śledzenia ogrodu, gdzie będę mógł zapisywać co zasadziłem i co zebrałem.”
- Skuteczna Pierwsza Komenda: „Zbuduj aplikację do śledzenia ogrodu z rozszerzalnym schematem bazy danych, który może pomieścić przyszłe funkcje. Użyj modułowej architektury, gdzie komponenty frontendowe, punkty końcowe API i dostęp do bazy danych są oddzielone. Dołącz jasną dokumentację schematu i struktury API dla przyszłych modyfikacji.”
To początkowo zwiększa zużycie tokenów. Jednakże, gdy zaczniesz dodawać nowe funkcje, SI nie będzie musiała marnować tokenów na refaktoryzację starego kodu, aby dostosować się do żądań.
4. Wybieraj Narzędzia Na Podstawie Stabilności Architektonicznej
- Bolt.new, Replit agent, i Lovable: Doskonałe do jednosesyjnych prototypów i łatwej instalacji. Słabe przy dodawaniu funkcji wielosesyjnych. Architektura staje się coraz bardziej krucha przy każdej modyfikacji.
- Claude/OpenAI/Gemini coding agents: Czasami przydatne przy skomplikowanym kodowaniu, ale mogą wydawać się bardziej skomplikowane w porównaniu z wizualnymi aplikacjami internetowymi, które widzieliśmy wcześniej.
- DreamHost Liftoff: Świetne jako fundament WordPressa z udowodnionymi wzorcami rozszerzalności. Architektura WordPressa jest zaprojektowana z myślą o modyfikacji i dodawaniu wtyczek. Rozwiązuje to problem nieelastycznej architektury, zaczynając od sprawdzonej, elastycznej podstawy.
5. Wprowadź Zabezpieczenia Od Pierwszej Godziny
Podobnie jak w przypadku rozszerzalności, chcesz integrować bezpieczeństwo już od pierwszego momentu. Dlatego, wraz z prośbą o rozszerzalną, modułową architekturę, chcesz również dodać komponenty zorientowane na bezpieczeństwo do początkowego polecenia.
Oto przykład, jak dodałbym zabezpieczenia w pierwszym poleceniu: „Zbuduj aplikację do śledzenia ogrodu z hashowaniem haseł bcrypt, walidacją wszystkich pól, parametryzowanymi zapytaniami SQL w celu zapobiegania atakom iniekcji, ograniczeniem liczby zapytań do wszystkich punktów końcowych API oraz sekretami przechowywanymi w zmiennych środowiskowych, które nigdy nie są ujawniane w kodzie frontend.”
Jeśli tworzysz aplikację skierowaną do klienta, oto kilka rzeczy, które warto mieć na uwadze:
- Nigdy nie ufaj danym klienta—waliduj i oczyszczaj po stronie serwera
- Przechowuj tajemnice w zmiennych środowiskowych
- Weryfikuj uprawnienia do każdej akcji
- Używaj ogólnych komunikatów błędów—szczegółowe logi tylko dla programistów
- Wprowadź kontrolę właścicielską, aby zapobiec nieautoryzowanemu dostępowi do danych
- Ochrona API za pomocą limitów szybkości
Zrozumienie jak działa generatywna SI pomaga ci rozpoznać, kiedy SI formułuje założenia bezpieczeństwa, które tworzą podatności.
6. Wiedz, Kiedy Zacząć Od Nowa a Kiedy Kontynuować
Rozpoznaj znaki, że kontynuowanie spowoduje zmarnowanie tokenów.
Zacznij od nowa, gdy:
- Zużycie tokenów przekracza 300k bez działających funkcji
- Każda poprawka wprowadza dwa nowe błędy
- Modyfikacje architektoniczne psują wiele istniejących funkcji
- Historia czatu przekracza 30 wymian
- Nie możesz wyjaśnić obecnej architektury bazy kodu
Kontynuuj, gdy:
- Nowe funkcjonalności integrują się płynnie z istniejącym kodem
- Naprawy błędów rozwiązują problemy bez skutków ubocznych
- Zużycie tokenów mieści się w budżetach
- Architektura pozostaje zrozumiała
Kiedy SI popełni błąd i pójdzie w złym kierunku, powrót, zmiana polecenia i ponowne wysłanie będzie dużo lepszym rozwiązaniem niż dokończenie tego bezużytecznego kodu.
7. Przegląd Z Analizą Bezpieczeństwa AI
Po zbudowaniu podstawowej funkcjonalności, skopiuj całą bazę kodów do Gemini 2.5 Pro w celu kompleksowej analizy zabezpieczeń. Preferuję ten model językowy z powodu jego dużej ilości kontekstu wynoszącej dwa miliony tokenów, dzięki czemu możesz przenieść całą bazę kodów do niego.
Monit przeglądu bezpieczeństwa: „Zachowaj się jak ekspert ds. bezpieczeństwa. Przeanalizuj tę kompletną bazę kodów pod kątem podatności. Zidentyfikuj ryzyko iniekcji SQL, podatności XSS, słabości uwierzytelniania, wady autoryzacji, narażenie poświadczeń oraz wszelkie problemy z pierwszej dziesiątki OWASP. Podaj konkretne lokalizacje kodu i rekomendacje dotyczące napraw.”
To jest przybliżenie profesjonalnego przeglądu bezpieczeństwa za ułamek ceny.
Jest niewystarczające do wdrożenia produkcyjnego, ale identyfikuje katastrofalne wady w prototypach, zanim dotrą do użytkowników.
Kiedy Kodowanie Vibe Ma Sens Biznesowy?
Nie musisz całkowicie rezygnować z kodowania wibracji tylko dlatego, że obecnie nie jest w stanie tworzyć skomplikowanych aplikacji. Oto kilka przypadków, kiedy uważam, że prototyp lub aplikacja zakodowana wibracjami faktycznie ma sens.
- Szybka Weryfikacja Koncepcji: Buduj prototypy w ciągu godzin, aby testować zainteresowanie rynku. Średni koszt weryfikacji spadł z 15 000–100 000+ do poniżej 500. Użyj kodowania wibracji, aby odpowiedzieć na pytanie: „Czy klienci chcą tego na tyle, aby z tego korzystać?”
- Automatyzacja Procesów Wewnętrznych: Zapewnij narzędzia dla swojego zespołu, gdzie kontrolujesz dostęp i akceptujesz wyższą tolerancję na ryzyko, ponieważ promień wybuchu pozostaje ograniczony. Wewnętrzne narzędzia mogą ewoluować w kierunku bezpieczeństwa, zamiast wymagać go od pierwszego dnia.
- Specyfikacja Przed Rozwojem: Zrozum wymagania przed zatrudnieniem programistów, aby zmniejszyć kosztowne nieporozumienia. Prototypy skodowane wibracjami służą jako interaktywne dokumenty wymagań.
- MVP Dla Zbierania Funduszy: Demonstruj funkcjonalność inwestorom, będąc przejrzystym co do dojrzałości technicznej. Wiele startupów używa MVP skodowanych wibracjami, aby zabezpieczyć początkowe finansowanie, a następnie właściwie odbudować z profesjonalnymi zespołami.
Kiedy Rozwój Zawodowy Staje Się Obowiązkowy
Aplikacje obsługujące klientów, które przetwarzają jakiekolwiek dane użytkowników, wymagają profesjonalnego przeglądu bezpieczeństwa. Koszt błędnej implementacji zabezpieczeń przewyższa wszelkie oszczędności wynikające z pisania kodu na luzie.
Niektóre przypadki, w których potrzebujesz profesjonalnej weryfikacji to:
- Autentykacja wielu użytkowników
- Przetwarzanie płatności
- Przechowywanie danych osobowych
- Publiczne wdrożenia
- Sytuacje wymagające zgodności z przepisami (takie jak GDPR, CCPA, HIPAA)
CEO Microsoftu ujawnił, że 30% kodu firmy jest obecnie generowane przez SI. Google podało podobne dane. Obie firmy utrzymują rozbudowane procesy przeglądu bezpieczeństwa, automatyczne testowanie i nadzór ludzki.
Wdrożenie produkcyjne wymaga podobnych zabezpieczeń niezależnie od metody generowania kodu.
Zrozumienie, czy SI zastąpi programistów, pomaga ustalić realistyczne oczekiwania co do tego, co możesz bezpiecznie budować i wdrażać samodzielnie. Odkryj najlepsze internetowe zasoby do nauki programowania, aby zniwelować różnicę między prototypami a systemami gotowymi do produkcji.
Najczęstsze Pytania O Vibe Coding
Czym jest vibe coding i czym różni się od tradycyjnego programowania?
Vibe coding to proces tworzenia aplikacji poprzez opisywanie wymagań w prostym języku angielskim dla SI, która generuje kod za Ciebie. W przeciwieństwie do tradycyjnego programowania, które wymaga znajomości języków programowania, vibe coding przesuwa uwagę na zarządzanie produktem i intencje, a nie na ręczne kodowanie.
Czy osoby niebędące programistami mogą tworzyć gotowe aplikacje za pomocą vibe coding?
Chociaż programowanie vibe pozwala osobom niebędącym programistami na szybkie tworzenie prototypów funkcjonalnych aplikacji, większość kodu generowanego przez SI nie ma wystarczającego zabezpieczenia i niezawodności potrzebnej do wdrożenia produkcyjnego. Mimo to, prototypy stworzone metodą vibe są świetne do weryfikacji koncepcji.
Jakie są największe ryzyka związane z użyciem kodu generowanego przez SI do tworzenia aplikacji?
Najważniejsze ryzyka obejmują wady bezpieczeństwa (takie jak brak walidacji, uwierzytelnienia, limitowania częstotliwości i ochrony przed atakami SQL injection), nieelastyczną architekturę oraz narastanie funkcji, które prowadzą do kruchych lub uszkodzonych systemów. Naruszenie aplikacji TEA jest przykładem szybkiego rozwoju bez odpowiedniego przeglądu bezpieczeństwa, co skutkowało katastrofalnymi konsekwencjami.
Kiedy ma sens używanie vibe coding w rzeczywistych projektach biznesowych?
Kodowanie z wykorzystaniem Vibe jest idealne do szybkiego prototypowania, narzędzi wewnętrznych, specyfikacji przedrozwojowej (zbierania wymagań) i MVP do pozyskiwania funduszy. Jednak w przypadku aplikacji skierowanych do klientów lub przetwarzających wrażliwe dane, zawsze warto inwestować w profesjonalny rozwój i przeglądy bezpieczeństwa.
Podsumowanie: Poznaj Swoje Architektoniczne Ograniczenia
Moja babcia prowadzi swój uproszczony rejestrator ogrodu do użytku osobistego. Dodała również funkcjonalne analizy (przycisk na pasku nawigacyjnym wcześniej nigdzie nie prowadził), aby zobaczyć, jak jej ogród się sprawuje.
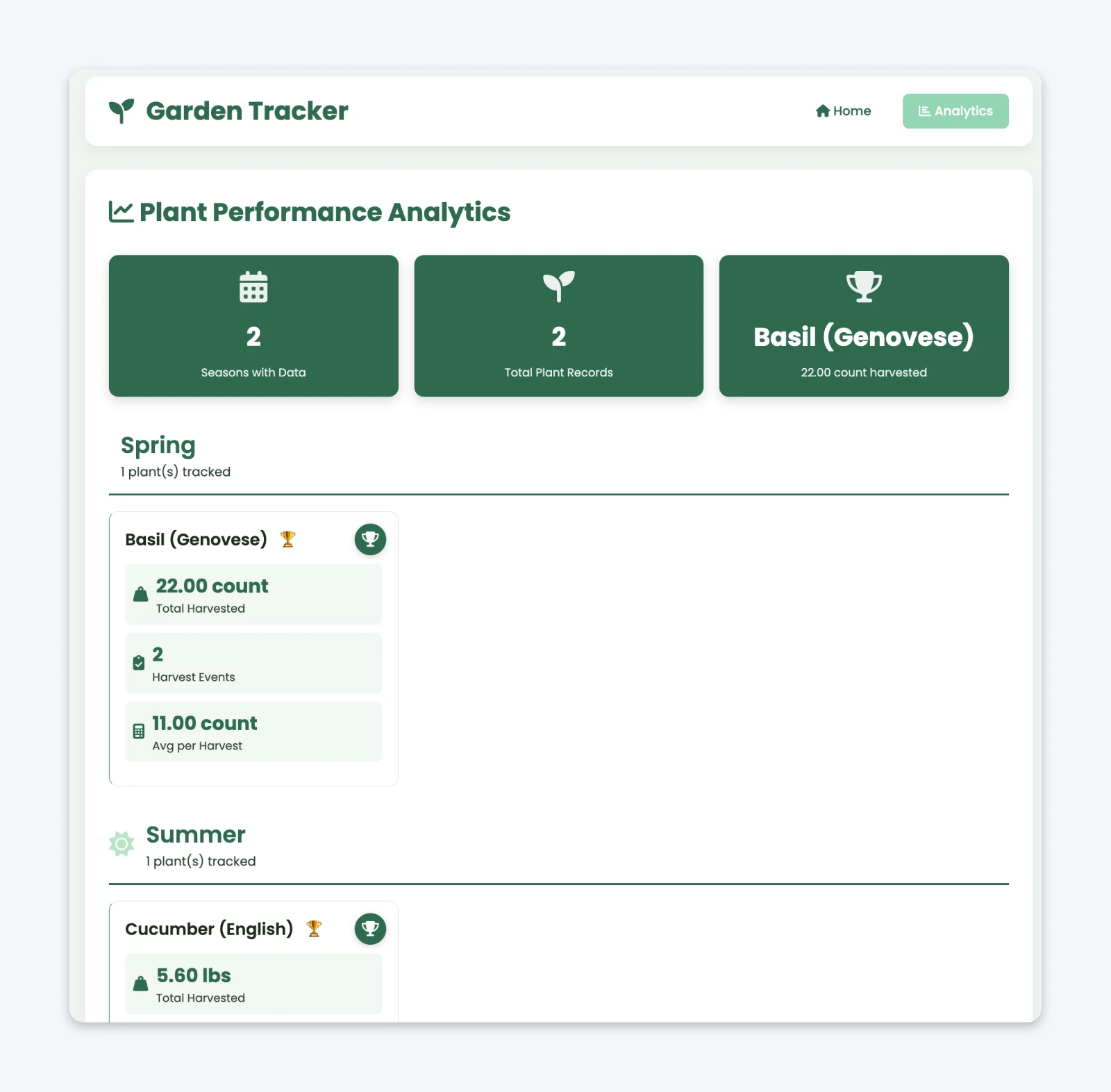
To działa jako aplikacja dla pojedynczego użytkownika. Jeśli tworzysz platformę dla wielu klientów, możesz nadal tworzyć prototypy, MVP itp. zakodowane wibracjami, aby rozpocząć prace. Ale poleganie wyłącznie na kodowaniu wibracji bez zrozumienia, co się dzieje, to po prostu powtarzanie historii aplikacji TEA.
Vibe coding demokratyzuje tworzenie oprogramowania, wprowadzając jednocześnie nowe obowiązki. Możesz zbudować aplikacje w 30 minut. Jednak musisz zrozumieć ograniczenia architektoniczne, implikacje bezpieczeństwa oraz wzorce zużycia tokenów przed udostępnieniem ich użytkownikom.
Przyszłość należy do budowniczych, którzy rozumieją lukę między prototypem a produkcją.
Gotowy do zbudowania swojej pierwszej aplikacji internetowej? Zacznij od DreamHost Liftoff dla kodowania z napędem WordPress, które obejmuje rozszerzalną architekturę, zarządzany hosting, infrastrukturę bezpieczeństwa i sprawdzoną skalowalność od pierwszego dnia. Buduj szybko. Rozszerzaj bezpiecznie. Miej własność nad swoim kodem.

Piękne Strony Internetowe, Zaprojektowane Od Zera
Wyróżnij się w tłumie dzięki nowoczesnej stronie WordPress, która jest w 100% unikalna dla Ciebie.
Zobacz więcej